[GitHub Global] Translate Vibe Coding 零基础教程/50 产品变现/网站数据保护实践.md to zh-TW
This commit is contained in:
committed by
 GitHub
GitHub
parent
7b09ff5cb9
commit
363352940e
@@ -0,0 +1,98 @@
|
||||
# 網站資料保護實踐
|
||||
|
||||
> 保護你的資料,防止被惡意爬取
|
||||
|
||||
大家好,我是程式設計師魚皮。前兩天模擬面試一位社招兩年的老哥,由於他的表現不錯,我就臨時起意,跟他交流一下我們最近遇到的業務場景問題。問題如下:
|
||||
|
||||
最近我們不是做了個 [程式設計師刷題網站 - 面試鴨](https://mianshiya.com/) 嘛,有很多壞人盯上了我們網站,想把我們 10,000 多道面試題、300 多個面試題庫的資料都用爬蟲抓下來。那我們應該如何防止這種爬蟲行為?比如怎麼識別出這些非法爬取資料的使用者並且自動封號?
|
||||
|
||||
整個問題的交流過程大家可以看影片學習:https://www.bilibili.com/video/BV1b142187Tb
|
||||
|
||||
下面我就直接把防止爬蟲的方法彙總分享給大家,總共有整整 10 種方法!最後一個方法很獨特~
|
||||
|
||||
## 如何防止網站被爬蟲?
|
||||
|
||||
#### 1、使用協議條款
|
||||
robots.txt 是一個放置在網站根目錄下的檔案,用於告訴搜尋引擎的爬蟲哪些部分不希望被抓取。
|
||||
|
||||
舉個例子,可以在 robots.txt 檔案中新增如下規則來禁止特定目錄或檔案被抓取:
|
||||
|
||||
```
|
||||
User-agent: *
|
||||
Disallow: /private/
|
||||
Disallow: /important/
|
||||
```
|
||||
|
||||
雖然大多數合規的爬蟲會遵守這些規則,但惡意爬蟲可能會忽視它,所以,僅憑 robots.txt 不能完全阻止所有爬蟲。但它是防護的第一步,起到一個宣告和威懾的作用。
|
||||
|
||||
可以在網站的服務條款或使用協議中明確禁止爬蟲抓取資料,並將違反這些條款的行為視為違法,如果網站內容被惡意爬蟲抓取並造成了損害,robots.txt 可以作為違反這些條款的證據之一。
|
||||
|
||||
#### 2、限制資料獲取條件
|
||||
比起直接暴露所有資料,可以要求使用者登入或提供 API 金鑰才能存取特定資料。還可以為關鍵內容設定身份驗證機制,比如使用 OAuth 2.0 或 JWT(JSON Web Tokens),確保只有授權使用者能夠存取敏感資料,有效阻止未經授權的爬蟲獲取資料。
|
||||
|
||||
#### 3、統計存取頻率和封禁
|
||||
|
||||
可以利用快取工具如 Redis 分散式快取或 Caffeine 本地快取來記錄每個 IP 或客戶端的請求次數,並設定閾值限制單個 IP 地址的存取頻率。當檢測到異常流量時,系統可以自動封禁該 IP 地址,或者採取其他的策略。
|
||||
|
||||
需要注意的是,雖然 Map 也能夠統計請求頻率,但是由於請求是不斷累加的,佔用的記憶體也會持續增長,所以不建議使用 Map 這種無法自動釋放資源的資料結構。如果一定要使用記憶體進行請求頻率統計,可以使用 Caffeine 這種具有資料淘汰機制的快取技術。
|
||||
|
||||
#### 4、多級處理策略
|
||||
|
||||
為了防止 「誤傷」,比起直接對非法爬蟲的客戶端進行封號,可以設定一個更靈活的多級處理策略來應對爬蟲。比如,當檢測到異常流量時,先發出警告;如果爬蟲行為繼續存在,則採取更嚴厲的措施,如暫時封禁 IP 地址;如果解封後繼續爬蟲,再進行永久封禁等處罰。
|
||||
|
||||
具體的處理策略可以根據實際情況來定制,也不建議搞的太複雜,別因此加重了系統的負擔。
|
||||
|
||||
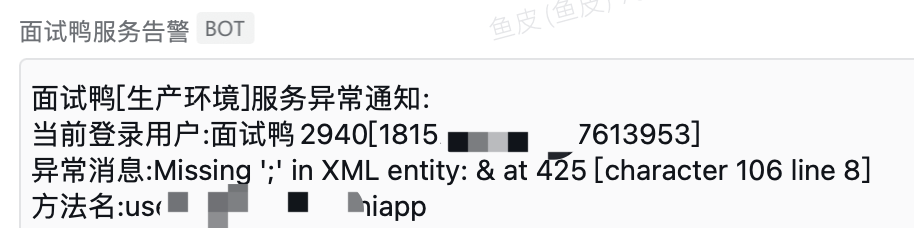
#### 5、自動告警 + 人工介入
|
||||
可以實現自動告警能力,比如在檢測到異常流量或爬蟲行為時,系統能自動發出企業微信訊息通知。然後網站的管理員就可以及時介入,對爬蟲的請求進行進一步分析和處理。
|
||||
|
||||
這點之前也給大家分享過,不止是針對爬蟲,企業的線上系統最好接入全方面的告警,比如介面錯誤、CPU / 記憶體佔用率過高之類的。
|
||||
|
||||
|
||||
|
||||
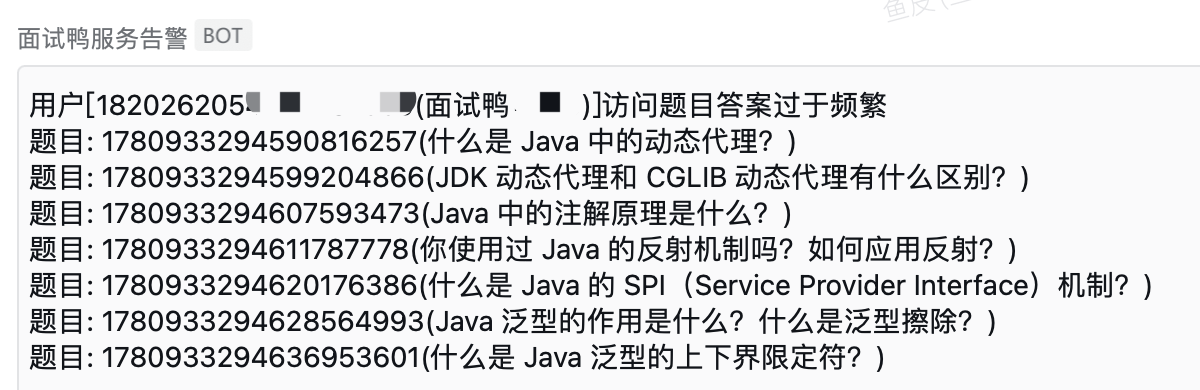
#### 6、爬蟲行為分析
|
||||
|
||||
非法爬蟲和正常使用者的行為一般是有區別的,爬蟲往往遵循特定的存取模式。比如正常使用者每道題目都要看一會兒、看的時間也不一樣,而爬蟲一般是按照固定的順序、固定的頻率來獲取題目,很明顯就能識別出來。
|
||||
|
||||
比如下面這種情況,有可能就是爬蟲:
|
||||
|
||||
|
||||
|
||||
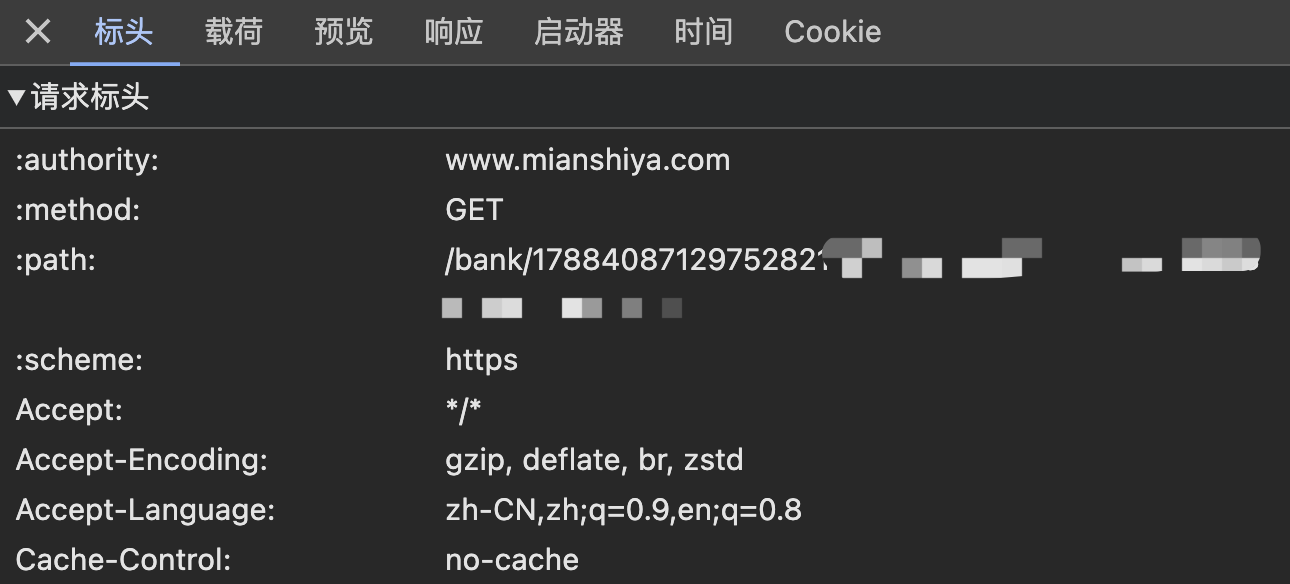
#### 7、請求頭檢測
|
||||
每個傳送到伺服器的請求都有請求頭資訊,可以通過檢查請求頭中的 User-Agent 和 Referer 等標識符,對爬蟲請求進行攔截。
|
||||
|
||||
當然,這招只能防防菜鳥,因為請求頭是可以很輕鬆地偽造的,只要通過瀏覽器自帶的網路控制台獲取到響應正常的請求頭資訊,就可以繞過檢測了。
|
||||
|
||||
|
||||
|
||||
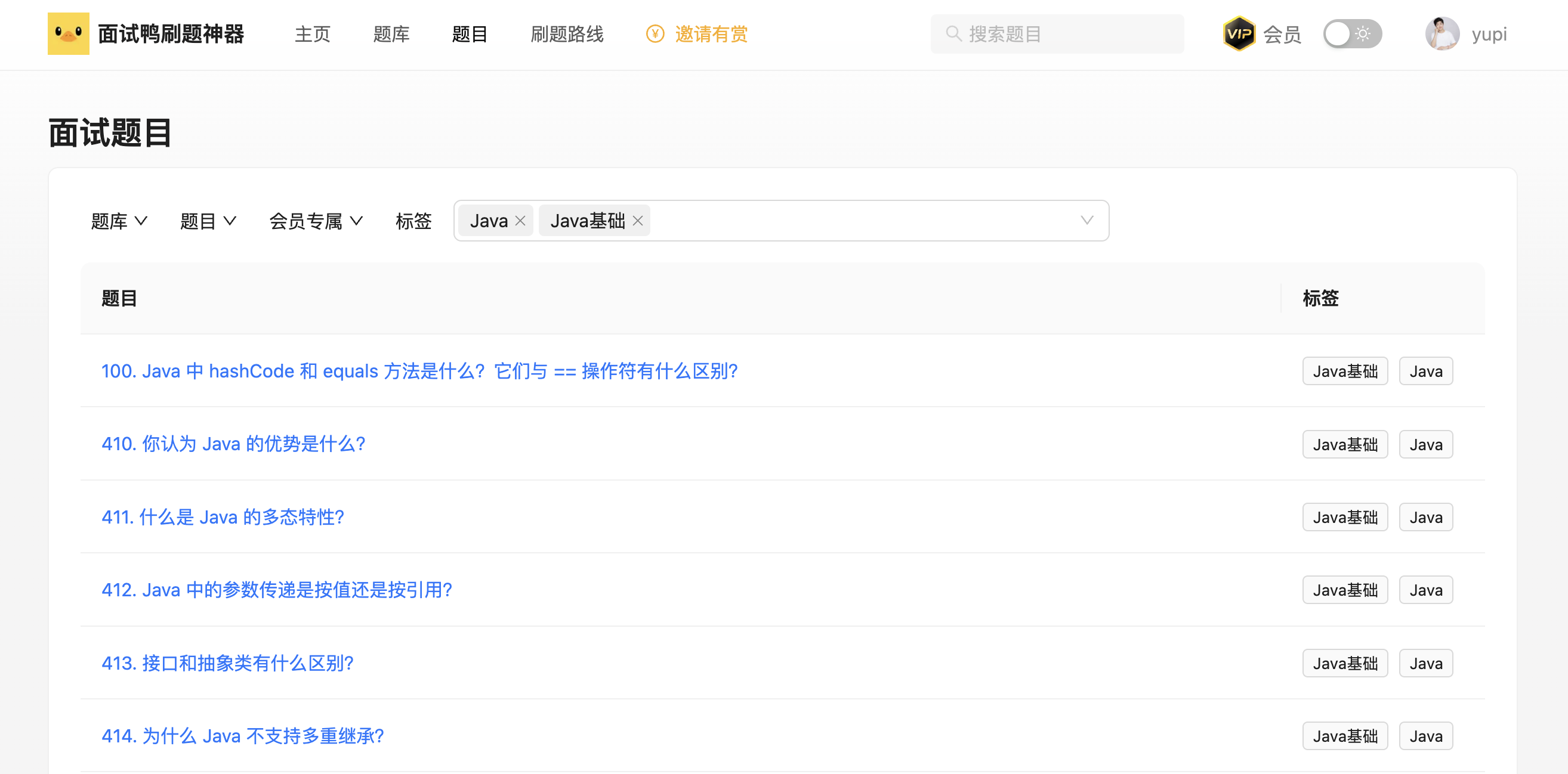
#### 8、自主公開資料
|
||||
|
||||
記得大學上資訊安全課的時候,學到一個知識點:防止網路攻擊的一種方法是,讓攻擊者的成本大於實際的收益。比如密碼 10 分鐘有效,破解密碼要花 15 分鐘,就不會有人去破解。
|
||||
|
||||
用到爬蟲場景上,我們的做法是,不做任何限制,直接讓所有人不登入也能檢視到我們網站的題目資料!而且還提供了題目的各種篩選功能、收藏功能。大多數同學只是為了自己學習,這樣一來,就沒有必要花時間去爬資料了~
|
||||
|
||||
|
||||
|
||||
#### 9、溯源技術
|
||||
雖然題目都是公開的,但有些我們專門請大廠大佬們來寫的優質題解是僅會員可見的。如果有使用者使用爬蟲抓取了這部分資料,可就要小心了!一般來說,只要你在一個網站登入了,就一定會有存取記錄,如果你洩露了網站登入後才可見的內容、尤其是付費內容,網站管理員一定有辦法追溯到你是誰。
|
||||
|
||||
比較常用的溯源技術就是浮水印、盲浮水印等。對於我們的面試鴨,本身就是通過微信登入的,而且如果你是會員,肯定還有支付記錄。這些技術不僅幫助標記資料源,還可以在資料被濫用時追蹤其來源,從而增強資料的保護。
|
||||
|
||||
#### 10、科普法律
|
||||
|
||||
除了上面這些方法外,還可以通過接入反爬服務、接入驗證碼、增加動態時間戳等方式進一步限制爬蟲。但是要記住,爬蟲是沒有辦法完美防禦的!因為你無法限制真實的使用者,攻擊者完全可以模擬真實使用者的存取方式來獲取你的網站資料,比如找 10 個使用者,每人獲取幾百題。
|
||||
|
||||
所以我的最後一個方法是 —— 科普法律。可以在網站上發布明確的法律聲明,告知使用者未經授權的抓取行為是違法的,可以對爬蟲行為起到一定的威懾作用。並且還通過發布影片和文章的方式,讓廣大程式設計師朋友們提高法律意識。爬蟲是有一定風險的,自己學習倒沒問題,但是千萬別給人家的網站造成壓力了,搞不好就有破壞電腦系統的嫌疑了!
|
||||
|
||||

|
||||
|
||||
## 推薦資源
|
||||
|
||||
1)魚皮 AI 導航網站:[AI 資源大全、最新 AI 資訊、免費 AI 教程](https://ai.codefather.cn)
|
||||
|
||||
2)程式設計導航學習圈:[學習路線、程式設計教程、實戰專案、求職寶典、交流答疑](https://www.codefather.cn)
|
||||
|
||||
3)程式設計師面試八股文:[實習/校招/社招高頻考點、企業真題解析](https://www.mianshiya.com)
|
||||
|
||||
4)程式設計師寫履歷神器:[專業模板、豐富例句、直通面試](https://www.laoyujianli.com)
|
||||
|
||||
5)1 對 1 模擬面試:[實習/校招/社招面試拿 Offer 必備](https://ai.mianshiya.com)
|
||||
Reference in New Issue
Block a user