[GitHub Global] Translate Vibe Coding 零基础教程/30 经验技巧/04 Vibe Coding 幻觉和死循环处理.md to zh-TW
This commit is contained in:
committed by
 GitHub
GitHub
parent
9a849caf02
commit
8feadff343
@@ -0,0 +1,610 @@
|
||||
# Vibe Coding 幻覺和死循環處理
|
||||
|
||||
> 如何讓失控的 AI 重回正軌
|
||||
|
||||
|
||||
|
||||
你好,我是魚皮。
|
||||
|
||||
在前面的文章裡,我們講了如何和 AI 高效對話,如何管理上下文。但即使你做得再好,也難免會遇到 AI 罷工的情況 —— 它開始胡說八道、陷入死循環、或者固執地堅持錯誤的方案。
|
||||
|
||||
這種情況在 Vibe Coding 中很常見,我們稱之為 AI 幻覺(AI Hallucination)。下面我會教你如何識別和修復這些問題,讓失控的 AI 重回正軌。
|
||||
|
||||
|
||||
|
||||
|
||||
## 一、什麼是 AI 幻覺?
|
||||
|
||||
在講解決方法之前,我們先要理解什麼是 AI 幻覺。
|
||||
|
||||
|
||||
|
||||
### AI 幻覺的定義
|
||||
|
||||
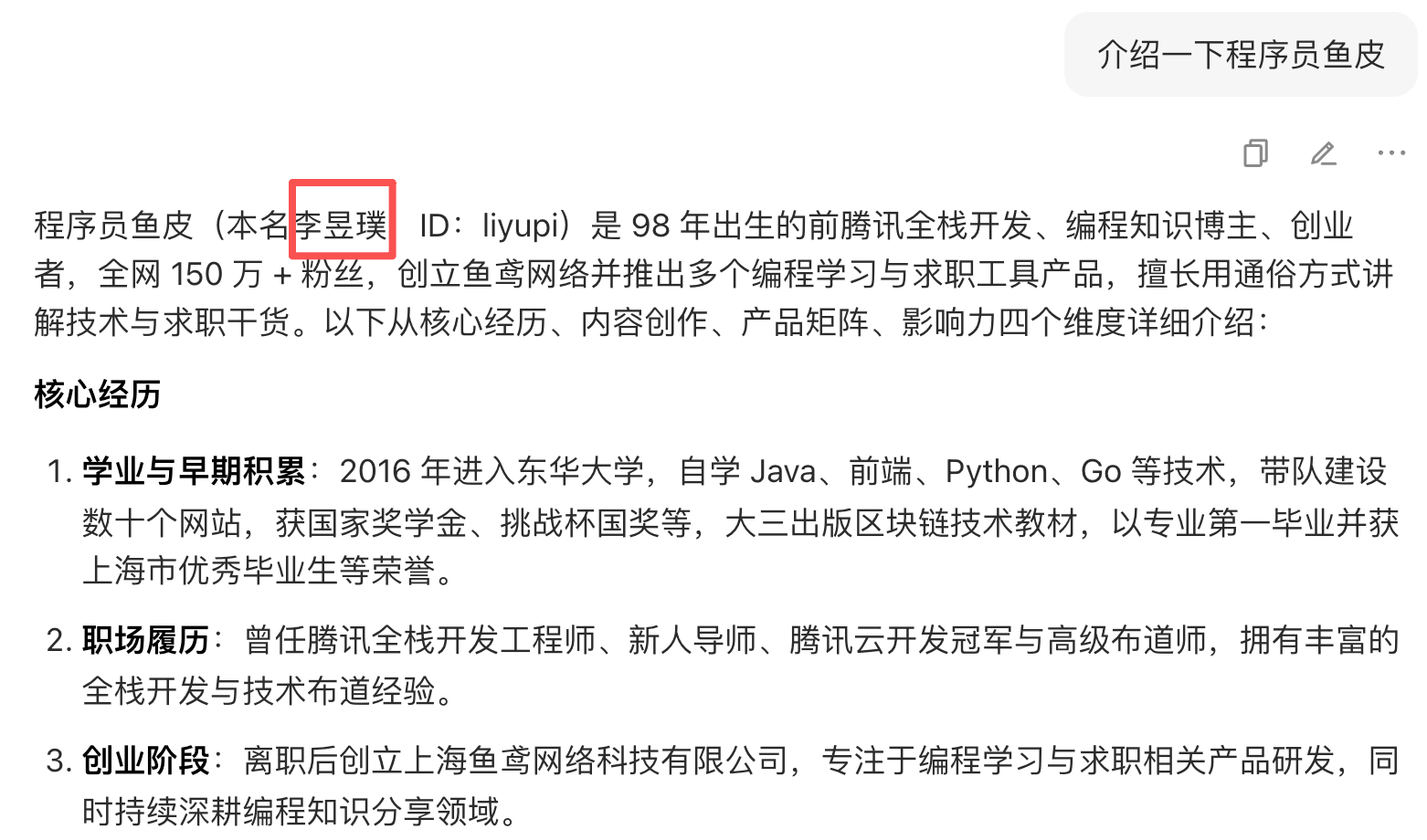
AI 幻覺指的是 AI 生成的內容看起來很有道理,但實際上是錯誤的、不存在的,或者不符合事實的。
|
||||
|
||||
比如下面這段對話,我的本名可不是這個……
|
||||
|
||||
|
||||
|
||||
在編程場景中,AI 幻覺通常表現為:
|
||||
|
||||
- 編造不存在的 API 或函數
|
||||
- 給出看似合理但實際無法運行的代碼
|
||||
- 堅持使用已經被證明錯誤的方案
|
||||
- 混淆不同技術棧的用法
|
||||
|
||||
舉個例子,你問 AI:React 中如何獲取組件的 DOM 節點?
|
||||
|
||||
AI 可能會告訴你用 `this.getDOMNode()`。
|
||||
|
||||
這個方法聽起來很合理,但實際上在現代 React 中並不存在,正確的做法是用 `useRef`。
|
||||
|
||||
|
||||
|
||||
|
||||
### 為什麼會產生幻覺?
|
||||
|
||||
AI 產生幻覺的原因有幾個:
|
||||
|
||||
1. 訓練數據的局限:AI 的知識來自訓練數據,如果數據中有錯誤或過時的資訊,AI 就會學到錯誤的知識。
|
||||
|
||||
2. 上下文混淆:當對話太長或資訊太雜時,AI 可能會混淆不同的上下文。
|
||||
|
||||
3. 過度自信:AI 被訓練成要給出 「確定」 的答案,即使它不確定,也會表現得很自信。
|
||||
|
||||
4. 模式匹配錯誤:AI 可能會把相似但不同的概念混在一起。
|
||||
|
||||
理解了這些原因,我們就能更好地應對幻覺問題。
|
||||
|
||||
|
||||
|
||||
### 擴展知識 - AI 幻覺的常見類型
|
||||
|
||||
在 Vibe Coding 中,AI 幻覺主要有這幾種類型:
|
||||
|
||||
1. API 幻覺:編造不存在的函數、方法或屬性
|
||||
|
||||
2. 語法幻覺:混淆不同語言或框架的語法
|
||||
|
||||
3. 邏輯幻覺:代碼邏輯看起來對,但實際上問題
|
||||
|
||||
4. 版本幻覺:使用已廢棄的 API 或過時的寫法
|
||||
|
||||
5. 依賴幻覺:引用不存在的庫或錯誤的包名
|
||||
|
||||
了解這些類型,能幫你快速識別問題。
|
||||
|
||||
|
||||
|
||||
## 二、AI 陷入死循環的表現
|
||||
|
||||
除了幻覺,AI 還有一個常見問題:陷入死循環。
|
||||
|
||||
|
||||
|
||||
### 什麼是死循環?
|
||||
|
||||
死循環指的是 AI 反覆嘗試同一個錯誤的方案,無法自己跳出來。
|
||||
|
||||
典型的表現是:
|
||||
|
||||
- 第一次:AI 給你一段代碼,但有 bug。
|
||||
- 第二次:你告訴它有問題,它改了一下,但還是同樣的問題。
|
||||
- 第三次:你再次指出問題,它又改了一下,但還是在同一個地方打轉。
|
||||
- 第四次:你開始懷疑人生……
|
||||
|
||||
這就是死循環,AI 被困在了一個錯誤的思路裡,無法自己走出來。不僅浪費時間,還白白浪費了大量 tokens。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
### 死循環的常見場景
|
||||
|
||||
死循環經常出現在這些場景:
|
||||
|
||||
1. 複雜的狀態管理:AI 在處理複雜的狀態更新時容易混亂
|
||||
|
||||
2. 非同步操作:涉及 Promise、async/await 時容易出錯
|
||||
|
||||
3. 類型系統:TypeScript 的複雜類型定義容易讓 AI 困惑
|
||||
|
||||
4. 性能優化:AI 可能會陷入 「優化 => 出錯 => 回退 => 再優化」 的循環
|
||||
|
||||
5. 跨文件修改:修改多個文件時容易顧此失彼,尤其是項目文件較多的時候
|
||||
|
||||
|
||||
|
||||
### 怎麼識別死循環?
|
||||
|
||||
我個人識別死循環的一些信號:
|
||||
|
||||
- AI 連續 3 次給出的方案本質上是一樣的
|
||||
- 每次修改只是換了個寫法,但核心問題沒解決
|
||||
- AI 開始道歉,並說 「讓我重新嘗試」
|
||||
- 你發現自己在重複說同樣的問題
|
||||
|
||||
一旦發現這些信號,就要立刻打斷,不要繼續下去。
|
||||
|
||||
|
||||
|
||||
|
||||
## 三、如何切斷上下文並重新開始
|
||||
|
||||
當 AI 陷入死循環或產生嚴重幻覺時,最有效的方法就是切斷上下文,重新開始。
|
||||
|
||||
|
||||
|
||||
|
||||
### 為什麼要切斷上下文?
|
||||
|
||||
繼續在混亂的上下文中對話,就像在泥潭裡越陷越深。AI 會被之前的錯誤資訊影響,很難給出正確的答案。
|
||||
|
||||
切斷上下文相當於給 AI 一個重啟的機會,讓它從乾淨的狀態開始。
|
||||
|
||||
|
||||
|
||||
|
||||
### 切斷的正確方法
|
||||
|
||||
不要直接開一個空白對話就開始問問題。正確的方法是:
|
||||
|
||||
1)總結當前的問題
|
||||
|
||||
在新對話開始前,先整理一下:
|
||||
- 你想實現什麼功能
|
||||
- 已經嘗試了哪些方案
|
||||
- 遇到了什麼具體問題
|
||||
- 當前的代碼狀態
|
||||
|
||||
|
||||
|
||||
2)開始新對話
|
||||
|
||||
在新對話中,先提供完整的上下文:
|
||||
|
||||
```markdown
|
||||
我在開發一個博客系統,技術棧是 Next.js 16 + TypeScript + Supabase。
|
||||
我想實現文章的自動保存功能,但遇到了問題。
|
||||
我嘗試過用 useEffect 監聽內容變化,但會導致頻繁保存。我也試過用 debounce,但有時候會丟失數據。
|
||||
這是我當前的代碼:【貼上相關代碼】
|
||||
請幫我分析問題並給出解決方案。
|
||||
```
|
||||
|
||||
|
||||
|
||||
3)明確要求不同的思路
|
||||
|
||||
告訴 AI 之前的方案不行,要換個思路:
|
||||
|
||||
```markdown
|
||||
之前的方案都有問題,請給我一個完全不同的實現思路。
|
||||
```
|
||||
|
||||
這樣 AI 就不會重複之前的錯誤。
|
||||
|
||||
或者先利用其他的 AI 模型給出不同的方案,再直接把方案貼給 AI 讓它執行。
|
||||
|
||||
|
||||
|
||||
|
||||
### 什麼時候應該切斷?
|
||||
|
||||
不是所有問題都需要切斷上下文。如果只是小問題,在當前對話中糾正就行。但如果遇到這些情況,就要果斷切斷:
|
||||
|
||||
- 對話輪數太多了(超過 20 輪),上下文已經很長,繼續下去只會更費錢更混亂
|
||||
- AI 開始混淆概念了,比如把你的技術棧搞錯,或者把不同功能的代碼混在一起
|
||||
- 你自己都覺得亂了,說不清楚當前的狀態,這時候繼續下去只會越來越亂
|
||||
- 還有前面提到的 「死循環」 情況
|
||||
|
||||
簡單來說,當你發現對話已經失控了,就該切斷。與其在泥潭裡掙扎,不如重新開始。
|
||||
|
||||
|
||||
|
||||
|
||||
## 四、如何給 AI 餵入報錯資訊
|
||||
|
||||
很多時候,AI 生成的代碼有 bug,但它不知道。這時候,你需要把報錯資訊準確地餵給它。
|
||||
|
||||
|
||||
|
||||
|
||||
### 完整複製錯誤資訊
|
||||
|
||||
不要只說 "代碼報錯了" 或者 "不工作",而是要把完整的錯誤資訊複製給 AI。
|
||||
|
||||
❌ 不好的反饋:你的代碼有問題,運行不了。
|
||||
|
||||
✅ 好的反饋:
|
||||
|
||||
```markdown
|
||||
代碼運行時報錯了,錯誤資訊如下:
|
||||
TypeError: Cannot read property 'map' of undefined
|
||||
at NoteList (NoteList.tsx:15)
|
||||
at renderWithHooks (react-dom.development.js:14985)
|
||||
這是第 15 行的代碼:
|
||||
{notes.map(note => <NoteItem key={note.id} note={note} />)}
|
||||
```
|
||||
|
||||
完整的錯誤資訊能讓 AI 快速定位問題。
|
||||
|
||||
|
||||
|
||||
|
||||
### 提供上下文代碼
|
||||
|
||||
除了錯誤資訊,還要提供相關的代碼上下文。
|
||||
|
||||
```markdown
|
||||
這是出錯的組件完整代碼,錯誤發生在第 9 行:
|
||||
export function NoteList() {
|
||||
const [notes, setNotes] = useState();
|
||||
|
||||
useEffect(() => {
|
||||
fetchNotes().then(data => setNotes(data));
|
||||
}, []);
|
||||
|
||||
return (
|
||||
<div>
|
||||
{notes.map(note => <NoteItem key={note.id} note={note} />)}
|
||||
</div>
|
||||
);
|
||||
}
|
||||
```
|
||||
|
||||
這樣 AI 就能看到完整的上下文,給出準確的修復方案。
|
||||
|
||||
|
||||
|
||||
|
||||
### 說明重現步驟
|
||||
|
||||
如果是和用戶互動相關的 bug,要說明如何重現。
|
||||
|
||||
```markdown
|
||||
這個錯誤只在特定情況下出現:
|
||||
|
||||
1. 用戶首次進入頁面時正常
|
||||
2. 點擊 '刷新' 按鈕後正常
|
||||
3. 但如果用戶先刪除一條筆記,再點擊"刷新",就會報錯
|
||||
|
||||
錯誤資訊是:【貼上錯誤資訊】
|
||||
```
|
||||
|
||||
畢竟 AI 是看不到用戶動作的,詳細的重現步驟能幫助 AI 理解問題的本質。
|
||||
|
||||
|
||||
|
||||
|
||||
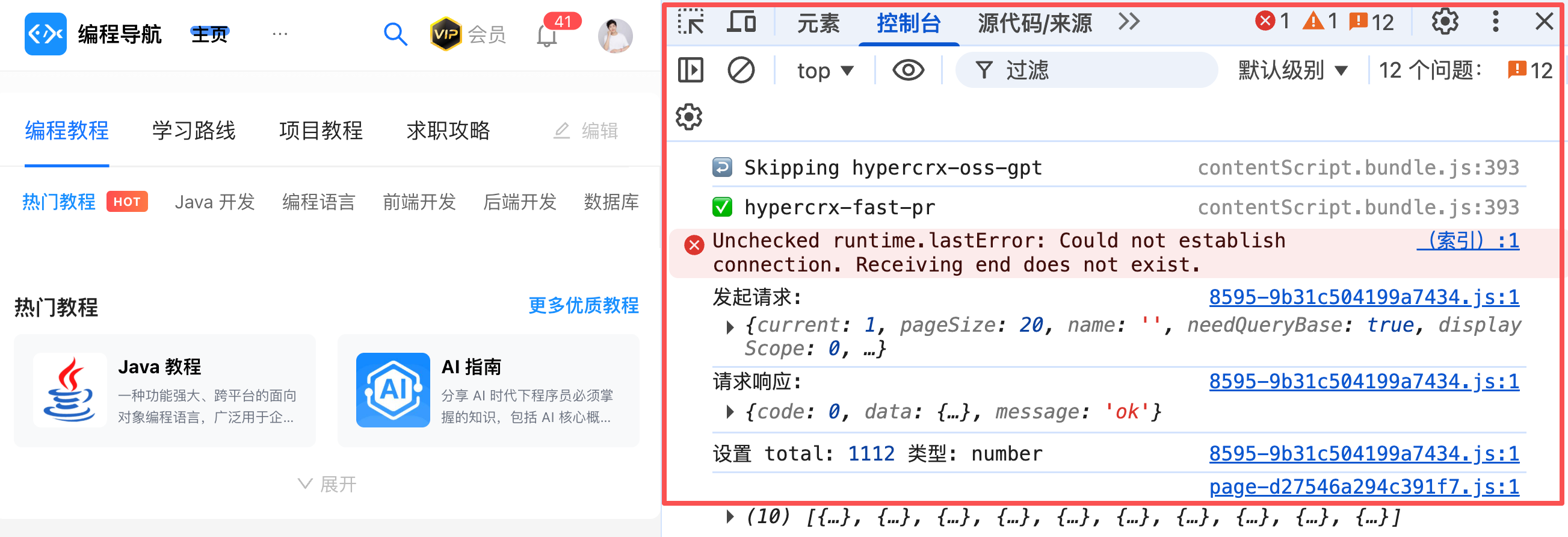
### 使用瀏覽器控制台
|
||||
|
||||
如果是網頁的前端出現了問題,那麼一定要利用好瀏覽器控制台。
|
||||
|
||||
按 F12 打開開發者工具,切換到 Console 控制台標籤,你會看到:
|
||||
|
||||
- 錯誤資訊(紅色)
|
||||
- 警告資訊(黃色)
|
||||
- 日誌資訊(白色)
|
||||
|
||||
把這些資訊截圖或複製給 AI,它能更快地找到問題。
|
||||
|
||||
|
||||
|
||||
如果你不知道是不是前端出了問題,或者根本不知道什麼是前端,那大概率就是前端出了問題。
|
||||
|
||||
|
||||
|
||||
|
||||
## 五、判斷問題來源
|
||||
|
||||
有時候,問題不在 AI,而在你的需求或邏輯本身。
|
||||
|
||||
如果是 AI 的問題,一般有這些特徵:
|
||||
|
||||
- 代碼語法錯誤或無法運行
|
||||
- 使用了不存在的 API
|
||||
- 邏輯明顯不符合你的描述
|
||||
- 代碼風格和之前的完全不一致
|
||||
|
||||
這些問題可以通過更好的提示或切斷上下文來解決。
|
||||
|
||||
但如果是邏輯問題,一般有這些特徵:
|
||||
|
||||
- 代碼能運行,但結果不對
|
||||
- 邊界情況沒有處理
|
||||
- 性能有問題
|
||||
- 用戶體驗不好
|
||||
|
||||
這些問題需要你重新思考需求,而不是盲目責怪 AI。
|
||||
|
||||
|
||||
|
||||
### 怎麼判斷問題來源?
|
||||
|
||||
一個簡單的方法是問自己:如果我把這個需求給一個真人開發者,他能做對嗎?
|
||||
|
||||
如果答案是 「不確定」 或者 「可能也會有問題」,那很可能是需求本身不夠清晰。
|
||||
|
||||
這時候,你需要先:
|
||||
|
||||
1. 重新梳理需求
|
||||
2. 明確邊界條件
|
||||
3. 畫出流程圖或狀態圖
|
||||
4. 寫出詳細的測試用例
|
||||
|
||||
然後再和 AI 討論實現方案。
|
||||
|
||||
有同學說:我怎麼知道真人開發者能不能做對啊?!
|
||||
|
||||
這其實也是缺少專業知識的問題,如果你本身懂技術,會更好地駕馭 AI 和判斷問題。即使你不知道這個問題的答案,也可以試著換種方式描述你的需求,或者借助其他 AI 來潤色需求、幫你做判斷。
|
||||
|
||||
|
||||
|
||||
|
||||
## 六、實戰案例:修復失控的項目
|
||||
|
||||
讓我用一個真實的案例,展示如何修復一個失控的項目。
|
||||
|
||||
|
||||
|
||||
### 場景描述
|
||||
|
||||
你在做一個待辦事項應用,想實現拖拽排序功能。你和 AI 對話了十幾輪,但功能還是不對:
|
||||
|
||||
- 第一次:AI 用了一個不存在的庫
|
||||
- 第二次:改用了 react-beautiful-dnd,但代碼報錯
|
||||
- 第三次:修復了報錯,但拖拽後數據沒有更新
|
||||
- 第四次:數據更新了,但界面沒有刷新
|
||||
- 第五次:界面刷新了,但順序不對
|
||||
- 你開始懷疑人生……
|
||||
|
||||
接下來你會怎麼做呢?
|
||||
|
||||
|
||||
|
||||
### 1、暫停並分析
|
||||
|
||||
不要繼續下去了!先暫停,分析一下問題:
|
||||
|
||||
- 核心問題是什麼?(拖拽排序)
|
||||
- 為什麼一直不對?(可能是 AI 對狀態管理理解有誤)
|
||||
- 有沒有更簡單的方案?(也許不需要用庫)
|
||||
|
||||
|
||||
|
||||
### 2、切斷上下文
|
||||
|
||||
開一個新對話,但這次換個方式問:
|
||||
|
||||
```markdown
|
||||
我想實現一個簡單的拖拽排序功能。不要用第三方庫,用原生的 HTML5 Drag and Drop API
|
||||
需求:
|
||||
1. 用戶可以拖動列表項
|
||||
2. 拖動時顯示佔位符
|
||||
3. 放下時更新順序
|
||||
4. 數據用 useState 管理
|
||||
請先給我一個最簡單的實現,只要能拖動就行,不需要動畫。
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
### 3、逐步完善
|
||||
|
||||
AI 給了一個簡單的版本,你測試後發現能用,爽爽爽。
|
||||
|
||||
然後再逐步添加功能:
|
||||
|
||||
1. 很好,現在加上拖動時的視覺反饋:被拖動的項半透明。
|
||||
2. 再加上佔位符:拖動時在目標位置顯示一個虛線框。
|
||||
3. 最後加上平滑的動畫效果。
|
||||
|
||||
每一步都很小,每一步都能測試,這樣就不會失控。
|
||||
|
||||
|
||||
|
||||
|
||||
### 4、總結經驗
|
||||
|
||||
問題解決後,讓 AI 幫你總結:
|
||||
|
||||
```markdown
|
||||
我們剛才實現了拖拽排序功能。請總結一下:
|
||||
1. 為什麼之前的方案不行?
|
||||
2. 這個方案的關鍵點是什麼?
|
||||
3. 如果以後要實現類似功能,應該注意什麼?
|
||||
```
|
||||
|
||||
這些總結可以加入你的項目文檔,避免以後重複踩坑。
|
||||
|
||||
|
||||
|
||||
## 七、預防幻覺的技巧
|
||||
|
||||
除了修復問題,我們還可以提前預防。
|
||||
|
||||
|
||||
|
||||
### 1、要求 AI 解釋
|
||||
|
||||
不要盲目接受 AI 的答案,讓它解釋為什麼這樣做。
|
||||
|
||||
- 你為什麼選擇用 useCallback 而不是 useMemo?
|
||||
- 這個方案的優缺點是什麼?
|
||||
- 有沒有其他實現方式?
|
||||
|
||||
通過解釋,你能發現 AI 是否真的理解了問題。
|
||||
|
||||
|
||||
|
||||
### 2、要求提供文檔連結
|
||||
|
||||
如果 AI 提到了某個 API 或庫,讓它提供官方文檔連結。
|
||||
|
||||
```markdown
|
||||
你提到了 react-query 的 useInfiniteQuery,能給我官方文檔的連結嗎?
|
||||
```
|
||||
|
||||
如果 AI 給不出連結,或者連結是錯的,那這個 API 可能是它編造的。
|
||||
|
||||
|
||||
|
||||
### 3、分步驗證
|
||||
|
||||
不要一次性實現整個功能,而是分步驗證。
|
||||
|
||||
- 先幫我實現最核心的部分,其他的暫時用假數據
|
||||
- 這一步能運行了,我們再做下一步
|
||||
|
||||
小步快跑,每一步都驗證,能及早發現問題。
|
||||
|
||||
|
||||
|
||||
### 4、使用類型系統
|
||||
|
||||
建議在項目中使用 TypeScript 技術,它是一種給 JavaScript 加上類型檢查的編程語言,可以充分利用它的類型系統來預防問題。
|
||||
|
||||
什麼是類型系統?
|
||||
|
||||
簡單來說,就是給每個變量、函數都標注清楚它是什麼類型的數據。比如這個變量是數字、那個變量是字符串、這個函數返回的是用戶對象等等。有了這些標注,編輯器就能在你寫代碼時就發現問題,而不是等到運行時才報錯。
|
||||
|
||||
看個例子:
|
||||
|
||||
```ts
|
||||
// ❌ 沒有類型定義:AI 可能生成錯誤的代碼
|
||||
function calculateTotal(items) {
|
||||
return items.reduce((sum, item) => sum + item.price, 0);
|
||||
}
|
||||
|
||||
// 如果傳入的數據格式不對,只有運行時才會報錯
|
||||
calculateTotal([{ name: '商品' }]); // 運行時報錯:price is undefined
|
||||
|
||||
// ✅ 有類型定義:編輯器立刻提示錯誤
|
||||
interface Item {
|
||||
name: string;
|
||||
price: number;
|
||||
}
|
||||
|
||||
function calculateTotal(items: Item[]): number {
|
||||
return items.reduce((sum, item) => sum + item.price, 0);
|
||||
}
|
||||
|
||||
// 編輯器會立刻用紅色波浪線提示:缺少 price 屬性
|
||||
calculateTotal([{ name: '商品' }]); // 編寫時就發現錯誤
|
||||
```
|
||||
|
||||
如果生成的項目比較複雜,AI 應該會默認使用 TypeScript 技術。你也可以主動要求 AI:請給所有函數和組件加上完整的 TypeScript 類型定義。
|
||||
|
||||
這樣,如果 AI 生成的代碼有類型不匹配的問題,編輯器會立刻用紅色波浪線提示你,你就能馬上發現並修復。這比等到運行時才發現問題要高效得多。
|
||||
|
||||
|
||||
|
||||
### 5、寫測試
|
||||
|
||||
讓 AI 幫你寫測試用例:
|
||||
|
||||
```markdown
|
||||
請為這個函數寫單元測試,覆蓋正常情況和邊界情況。
|
||||
```
|
||||
|
||||
測試能幫你發現邏輯問題。
|
||||
|
||||
|
||||
|
||||
### 6、讓 AI 自主驗證工作
|
||||
|
||||
不要光讓 AI 幹活,還要讓它知道怎麼驗證自己的工作。
|
||||
|
||||
比如在開發 Web 應用時,可以讓 AI 打開瀏覽器來測試 UI,發現問題後自動迭代,直到功能正常運行。這樣能形成一個自動化的反饋循環:
|
||||
|
||||
```markdown
|
||||
請實現這個功能,並且在完成後自動打開瀏覽器測試。如果發現問題,請自動修復並重新測試,直到功能正常工作。
|
||||
```
|
||||
|
||||
這種方式能讓 AI 更自主地工作,減少人工干預,特別適合處理需要多次迭代的任務,也是 Claude Code 創始人強烈建議的技巧。
|
||||
|
||||
|
||||
|
||||
## 八、常見幻覺場景和應對方法
|
||||
|
||||
基於我的經驗,這裡總結了一些常見的幻覺場景和應對方法。
|
||||
|
||||
|
||||
|
||||
### 場景一:編造的 API
|
||||
|
||||
表現:AI 使用了一個聽起來很合理,但實際不存在的 API。
|
||||
|
||||
應對:
|
||||
|
||||
```markdown
|
||||
這個 API 在官方文檔中找不到,你確定它存在嗎?請給我文檔連結。
|
||||
```
|
||||
|
||||
如果 AI 承認錯誤,讓它給出正確的 API:
|
||||
|
||||
```markdown
|
||||
那正確的做法是什麼?請用官方推薦的方式實現。
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
### 場景二:過時的寫法
|
||||
|
||||
表現:AI 使用了已廢棄的 API 或舊版本的寫法。
|
||||
|
||||
應對:
|
||||
|
||||
```markdown
|
||||
這個寫法是舊版本的。我用的是 React 19,請用最新的寫法。
|
||||
```
|
||||
|
||||
然後明確要求:
|
||||
|
||||
```markdown
|
||||
請用 Hooks 而不是 Class 組件。
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 場景三:混淆技術棧
|
||||
|
||||
表現:AI 把不同框架的用法混在一起。
|
||||
|
||||
應對:
|
||||
|
||||
```markdown
|
||||
等等,你給的是 Vue 的寫法,我用的是 React。請用 React 的方式重寫。
|
||||
```
|
||||
|
||||
然後重新強調技術棧:
|
||||
|
||||
```markdown
|
||||
我的項目用的是 React 19 + TypeScript,請確保代碼符合這個技術棧。
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 場景四:邏輯漏洞
|
||||
|
||||
表現:代碼能運行,但有明顯的邏輯問題。
|
||||
|
||||
應對:
|
||||
|
||||
```markdown
|
||||
這個方案有問題:如果用戶在加載過程中關閉頁面,數據會丟失。請考慮這個邊界情況。
|
||||
```
|
||||
|
||||
然後要求改進:
|
||||
|
||||
```markdown
|
||||
請加上錯誤處理和數據持久化。
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 場景五:性能問題
|
||||
|
||||
表現:代碼能用,
|
||||
Reference in New Issue
Block a user