14 KiB
Gemini CLI: Hands-on Testing of Google's Free AI Command Line Tool
Hello, I'm Yupi.
Google has launched an interesting AI command-line tool — Gemini CLI, which directly integrates AI into the terminal.
According to the official introduction, this tool can:
- Handle large codebases (up to 1 million Token context)
- Multimodal capabilities: Generate new applications from PDFs or sketches
- Automate operations: Help query code merge requests and handle complex code merges
- Integrated with numerous tools: Supports connecting to MCP servers, image, video, and audio generation
- Built-in search, and more
Positioned against Claude Code, it currently offers free usage quotas, and best of all, the code is open source!
As of January 2026, Gemini CLI has already garnered 90,000+ GitHub Stars, skyrocketing in popularity!
So, how does this tool actually perform? I'll take you through a hands-on experience and share my genuine impressions.
⭐️ Recommended video version: https://bilibili.com/video/BV1LuKdzjEAc
1. Installation and Setup
Following the official documentation, we first need to install the Node.js runtime environment. Simply go to the official website to install it, note that the version must be >= 20 (latest requirement as of 2026).
Then, open the terminal and enter a command to install the tool globally:
npm install -g @google/gemini-cli
Or install using Homebrew (macOS/Linux):
brew install gemini-cli
After installation, enter the gemini command to perform some basic setup:
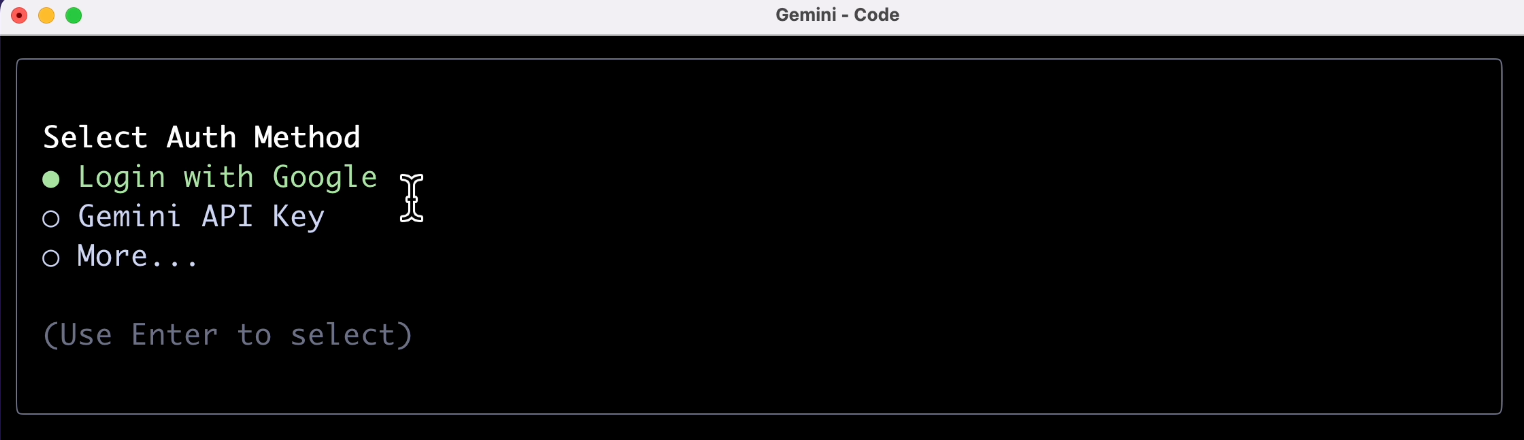
Next is the crucial part, requiring a wave of account verification. Individual users should select the first option.
Here, you might encounter two types of verification failures. The first is due to network issues (hard to resolve), and the second is an account type mismatch, as shown:
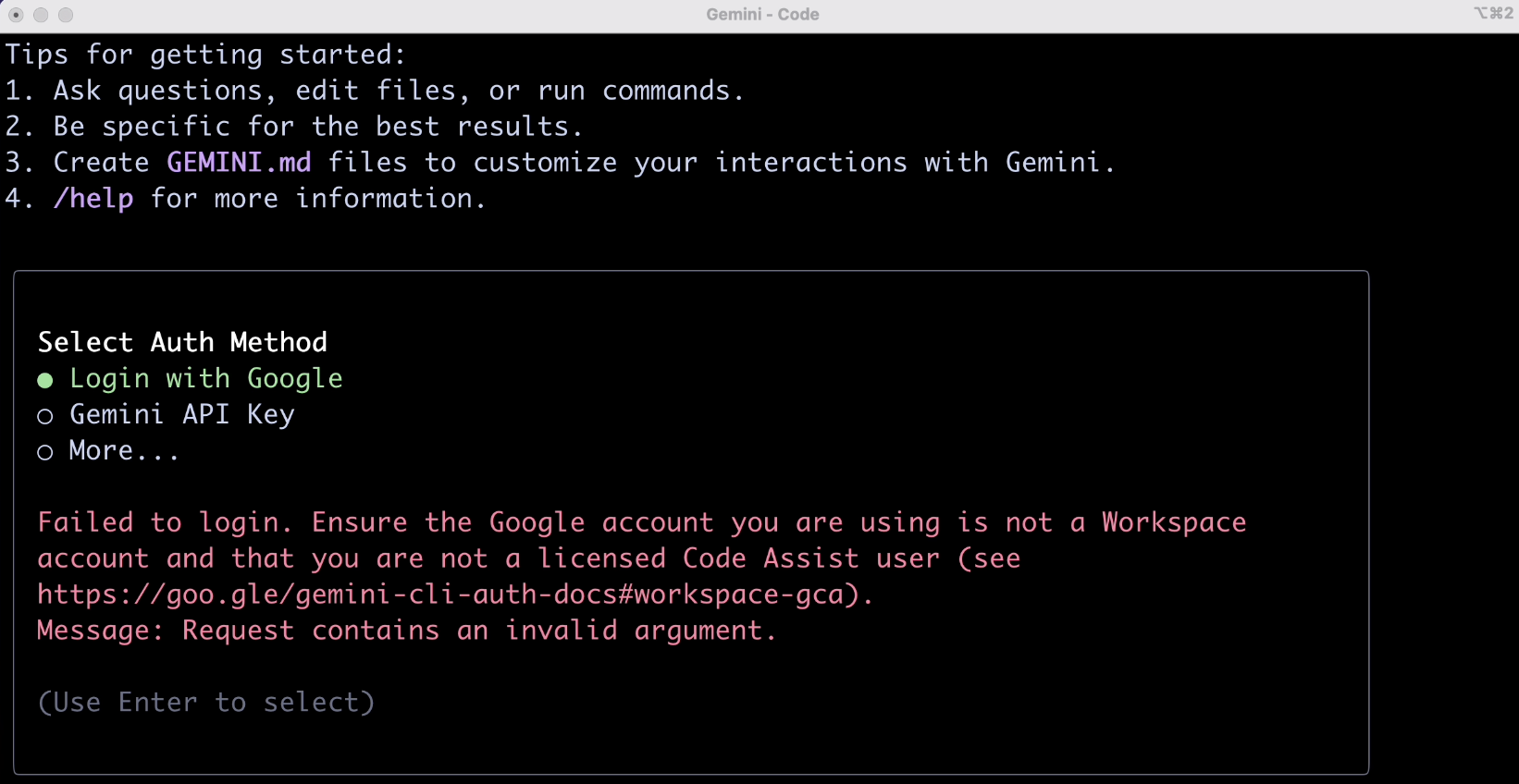
For the second case, the solution is simple. Go to the Google Cloud console, create a new project to get a project_id:
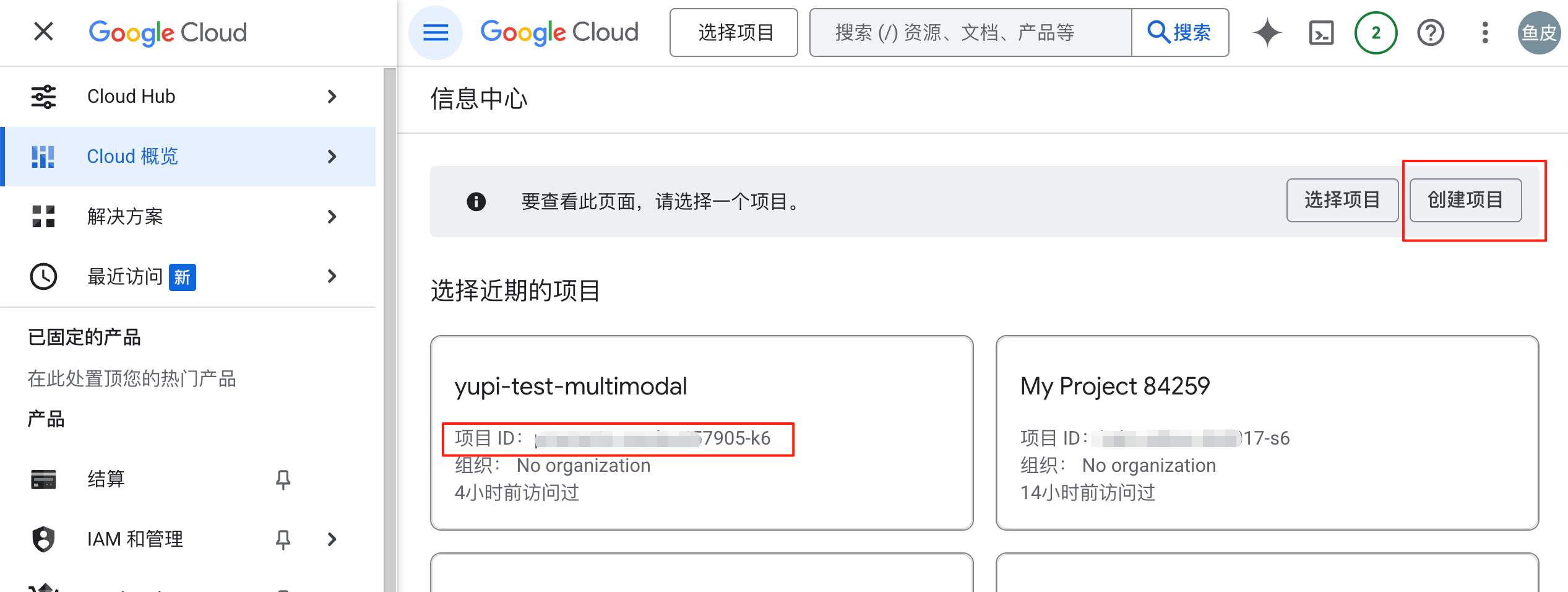
Then, enter the following command in the terminal to set the environment variable, and retry to log in:
export GOOGLE_CLOUD_PROJECT=<your project_id>
After successful login, we can start using it.
2. Practical Testing
Next, I selected 8 different scenarios to verify its capabilities from multiple aspects. You can also get a sense of Gemini CLI's actual performance. Only when everyone says it's good is it truly good.

1. Basic Q&A
Input prompt:
Hello, what can you do? What are your advantages?
Unexpectedly, it started with an error? And various gibberish.
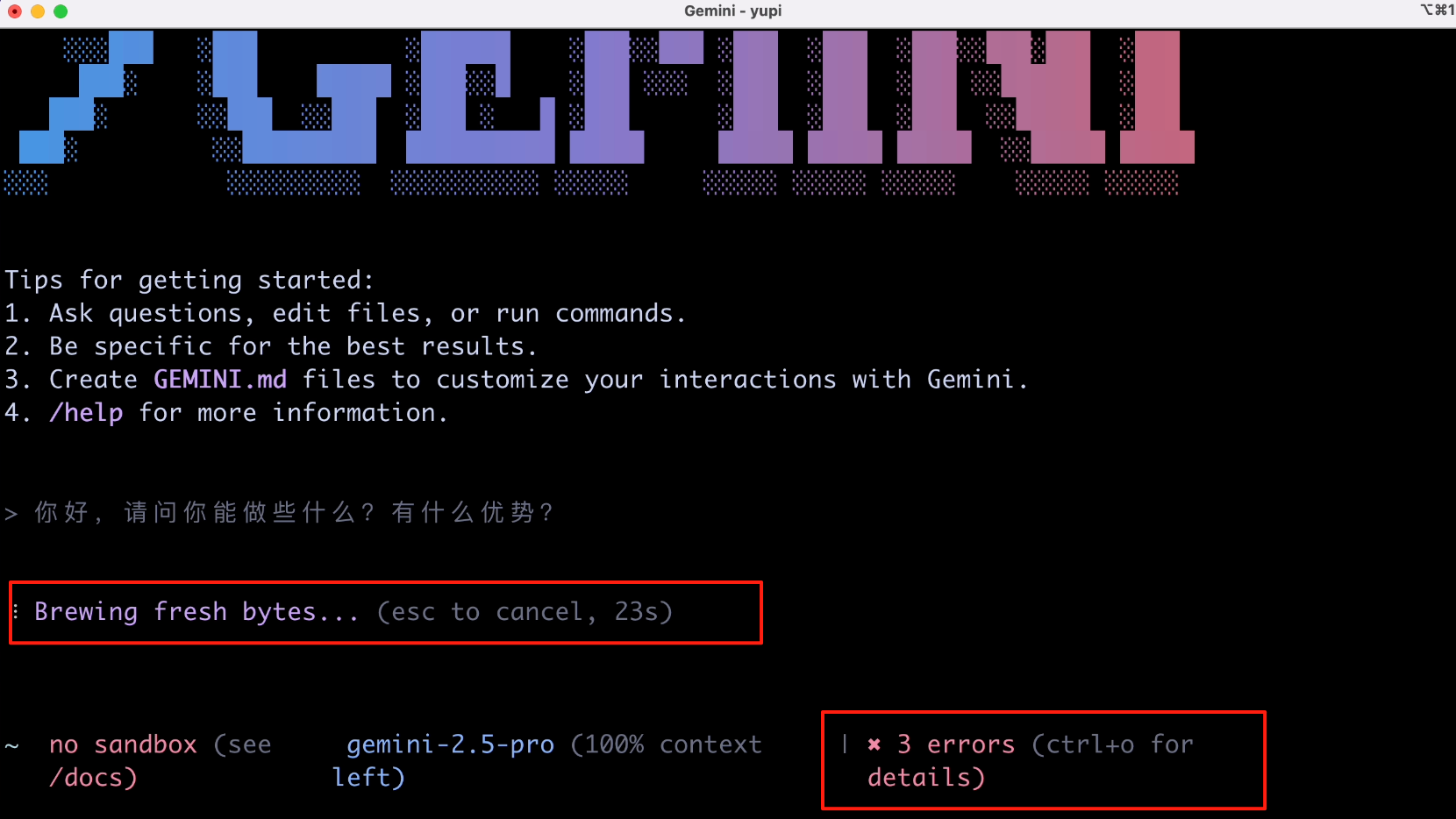
After a while, it finally filled the screen with red errors. The error message indicated that I didn't enable API permissions:
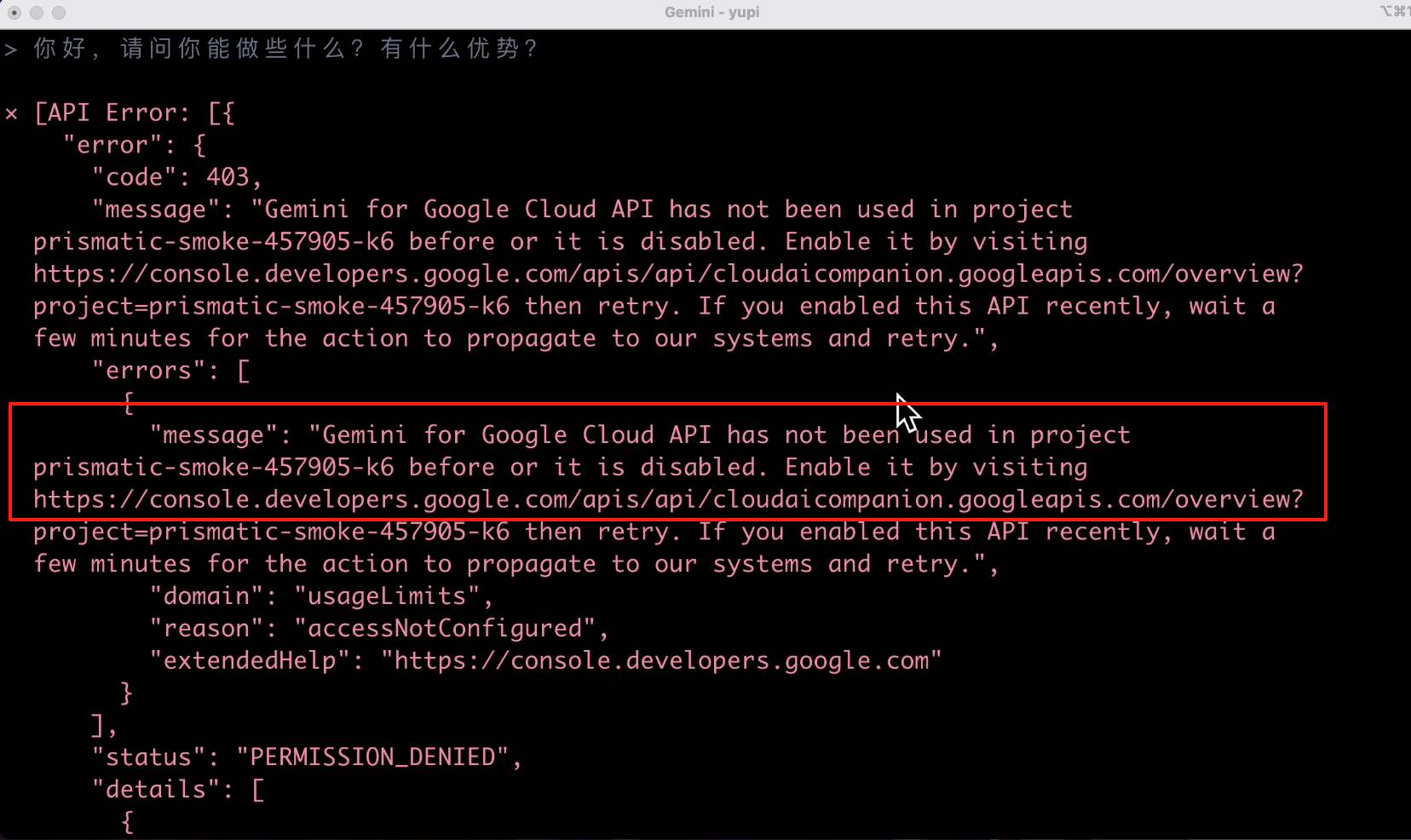
Directly visiting the URL in the error message allows you to enable API permissions in the console. Let's enable it:

Try again! This time, the AI's response was on point. It said it's an AI software engineer, ensuring transparent and secure operations. The result was decent, but the speed was a bit slow. A simple question took 20 seconds, which is a side effect of intelligent agents.
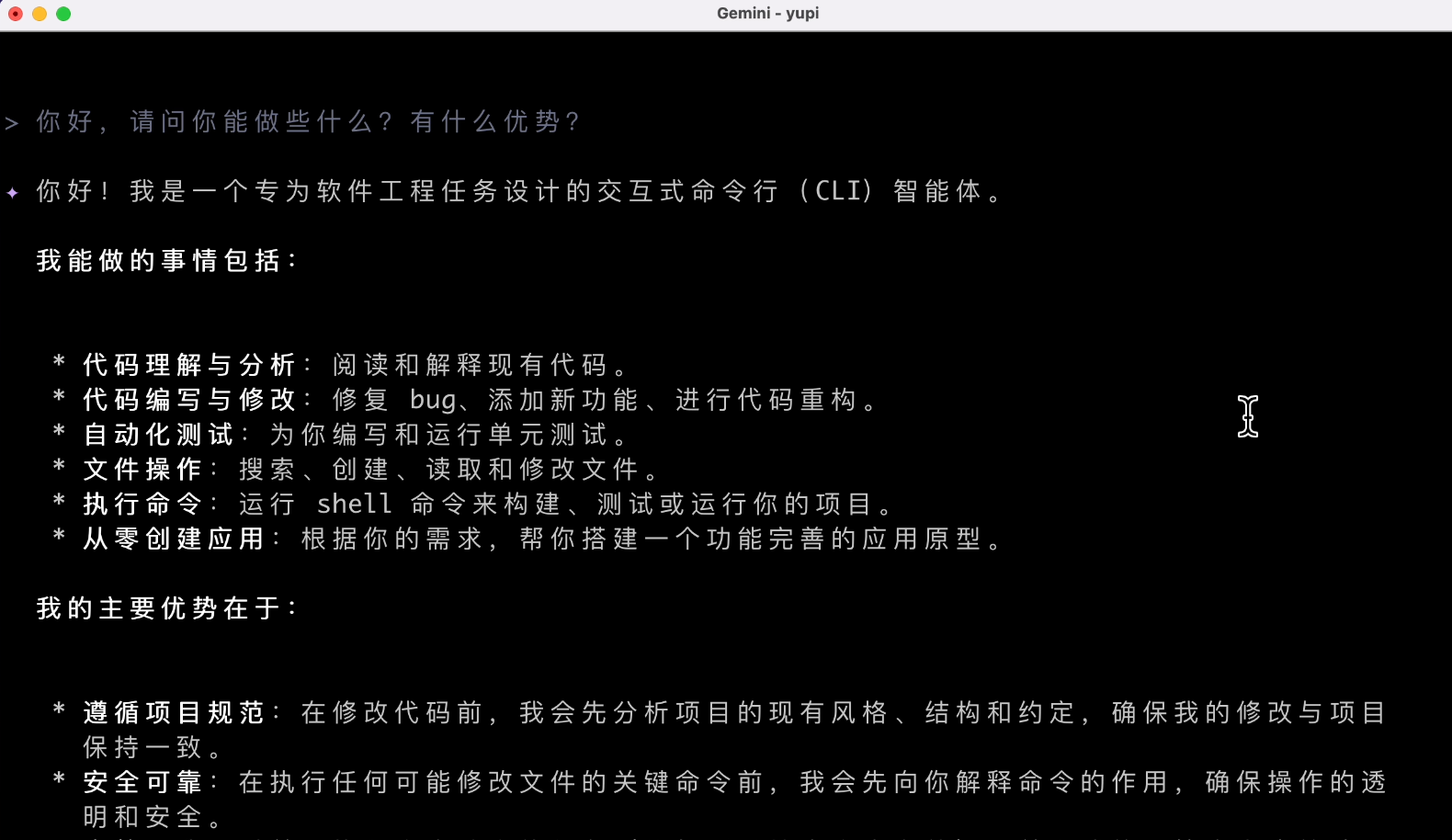
2. Web Search
Input prompt to let the AI automatically download memes:
Please help me get 10 healthy panda head memes and download them to the current directory
The AI recommended several meme websites but couldn't download them directly:
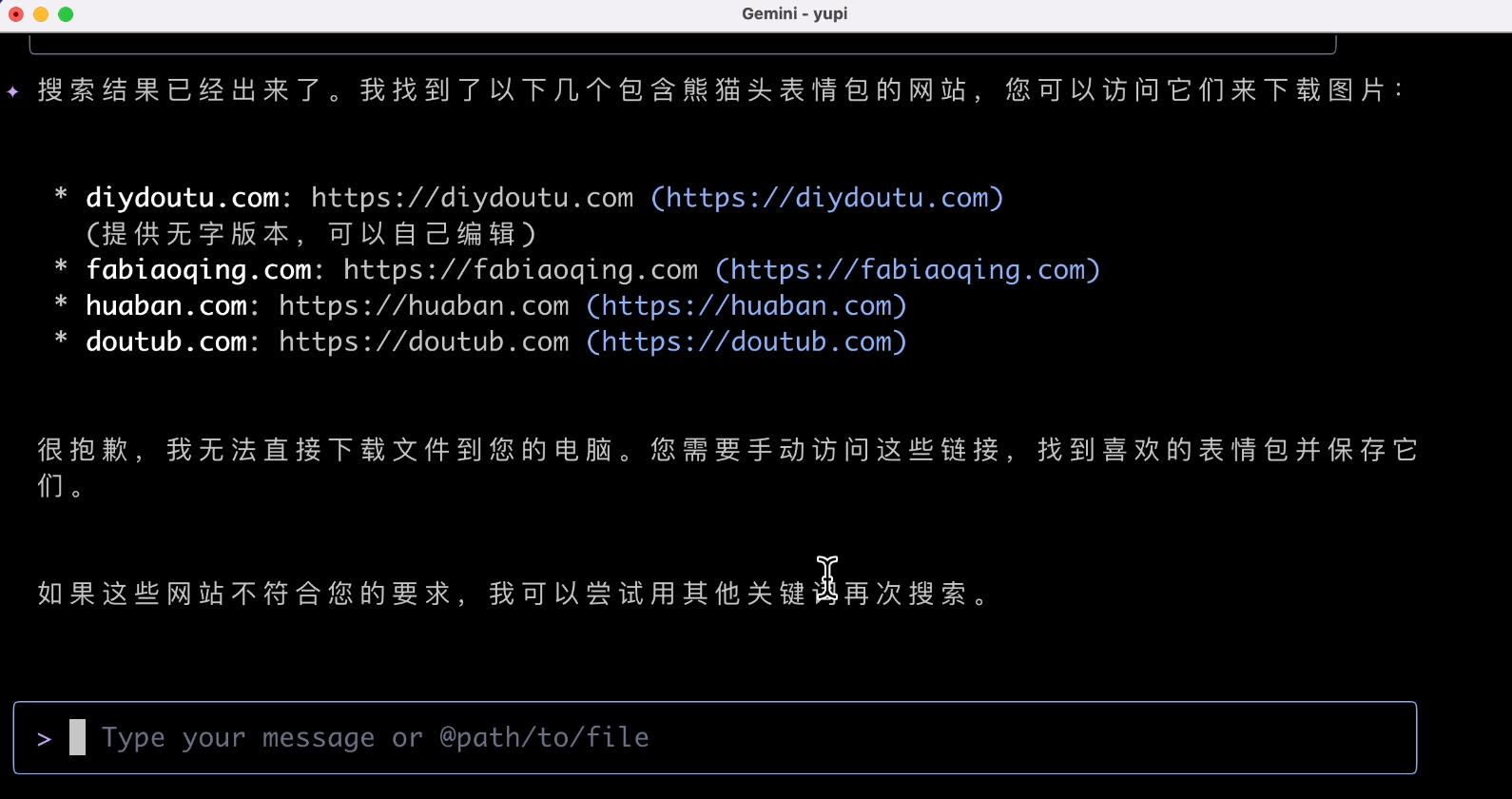
Does it not support download tools?
We can press the / key to see the commands supported by Gemini CLI:
Looking at the tool list, it seems there's no web resource download tool, which is tough for the AI. But it supports writing Shell scripts, so let's guide the AI to write a script for resource download.
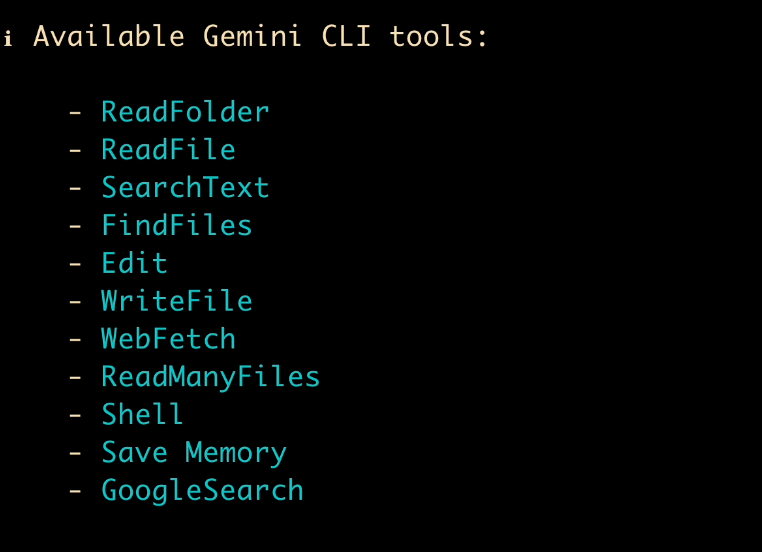
Prompt:
Please help me get 10 healthy panda head memes and download them to the current directory. You can achieve this by writing an executable script
This time, we can see the agent starting to plan tasks autonomously. It first created a script, and the "write file" operation requires our confirmation. It's recommended to choose "Allow Once" for safety:
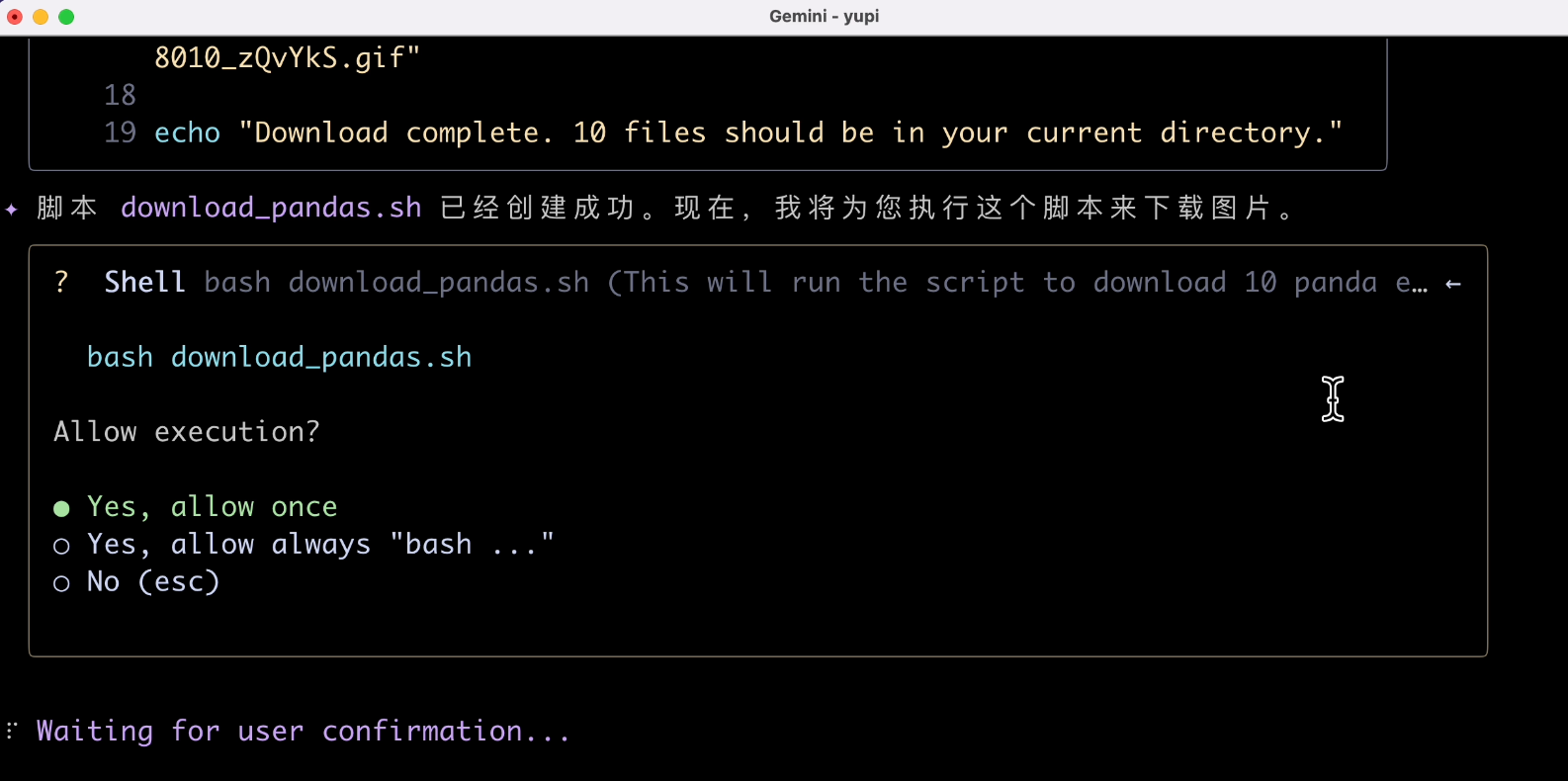
When encountering issues, it tries to re-plan and retry, which is a key capability of intelligent agents:
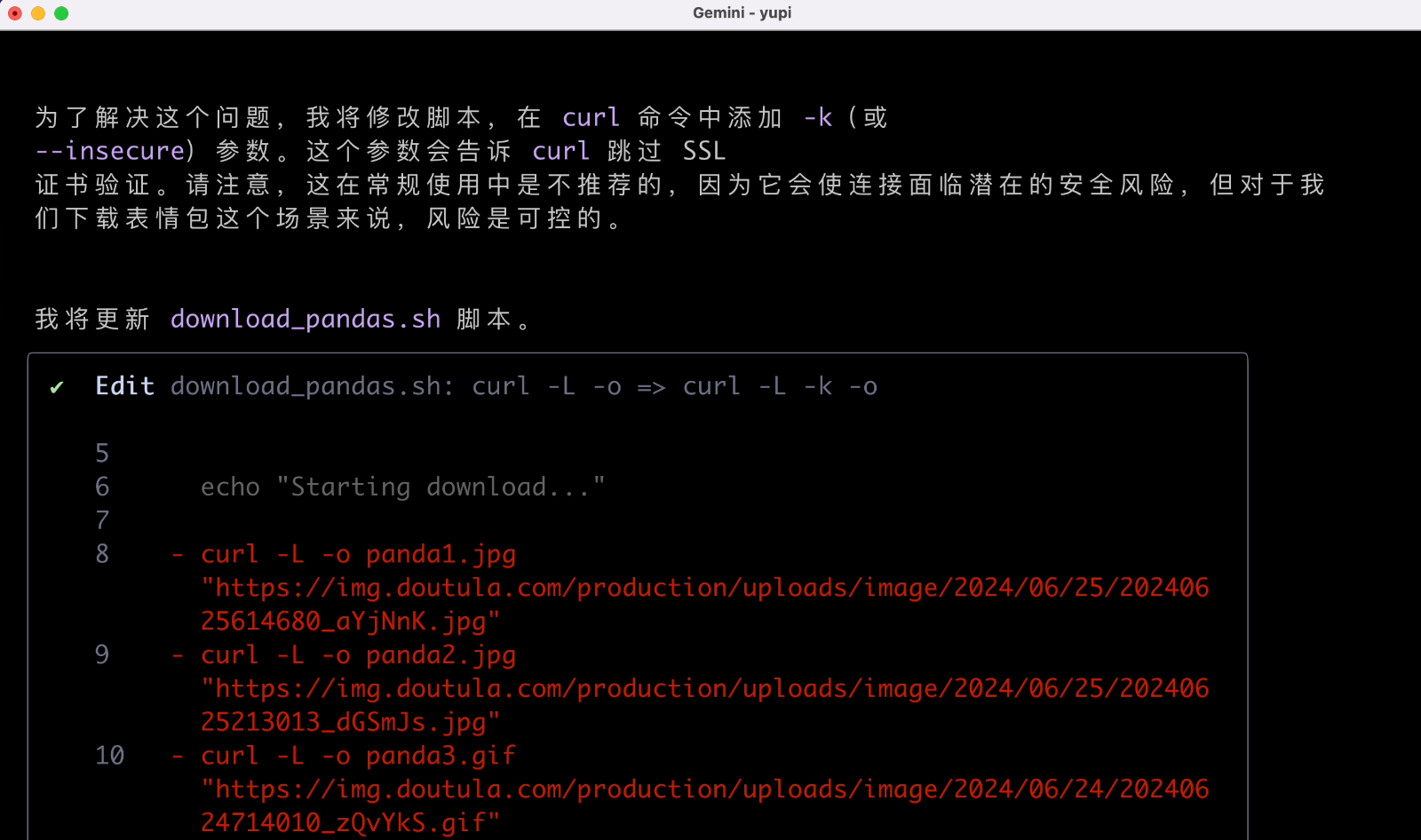
After task completion, it remembers to clean up the script, which is a nice touch.
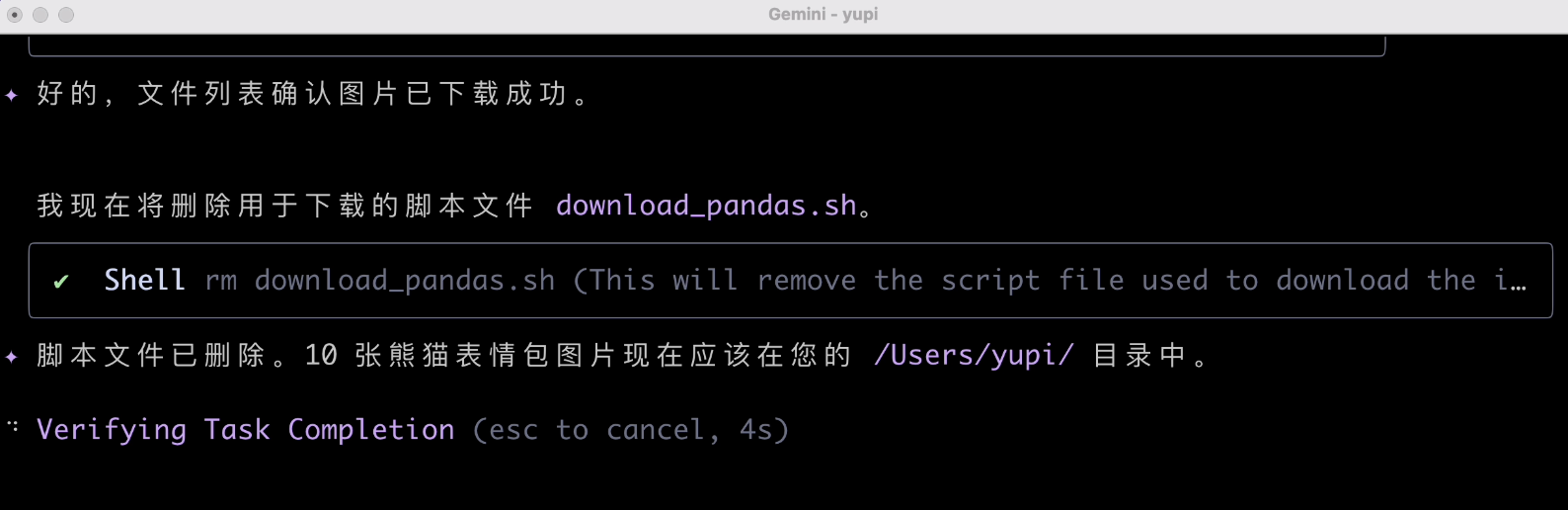
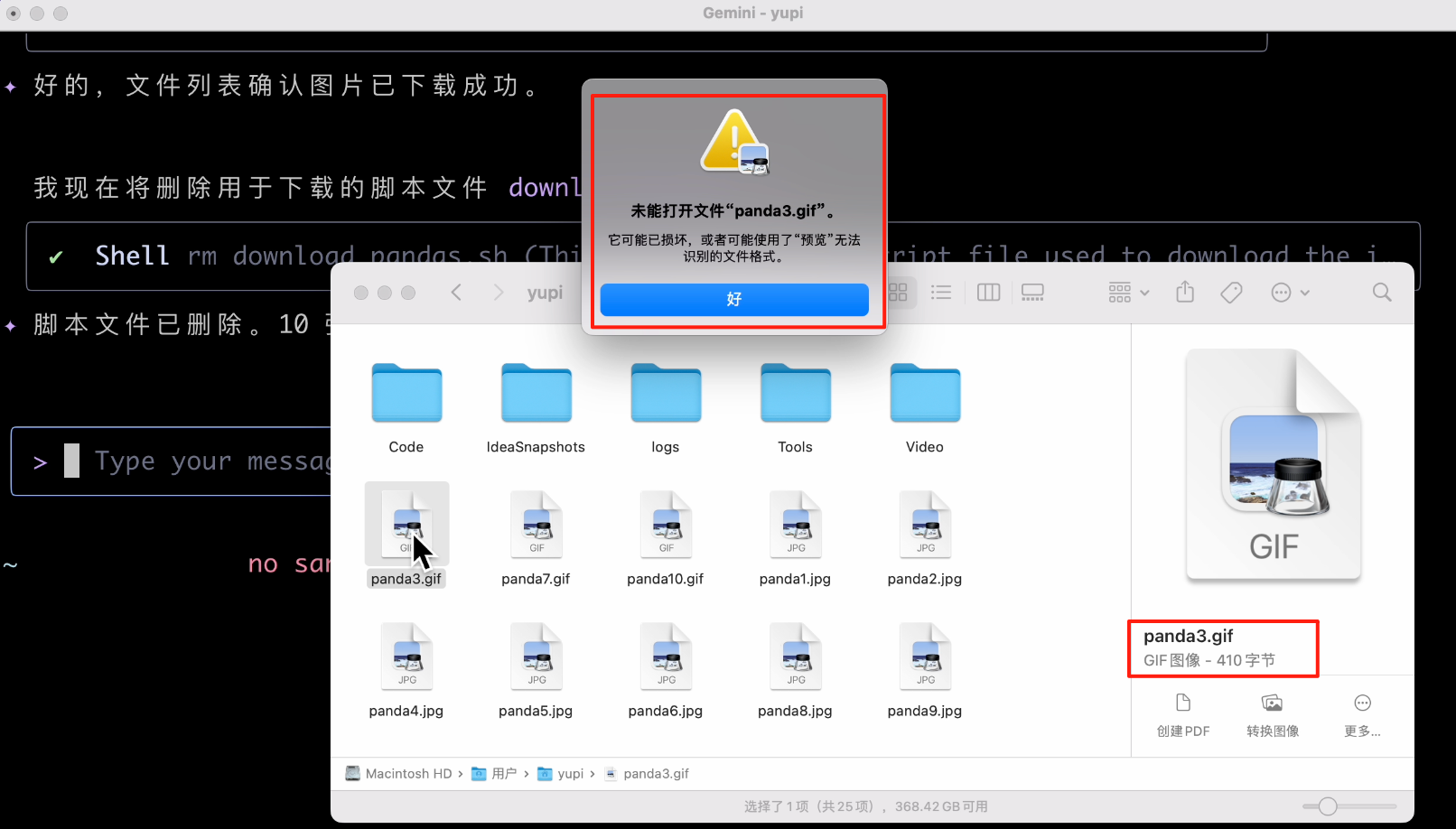
Alright, mission accomplished. Let's check the downloaded files. Is this size serious? It indeed failed; the downloaded images were completely wrong!
3. File Operations
Input the following prompt to let the AI help process my local meme files:
Help me double the size of all memes, convert them to WEBP format, and then combine all memes into a GIF
Then, I should specify the file path, or the AI might not know what to process.
When I pressed the @ key to specify the file path, the input box froze? Honestly, this interaction experience isn't great. Every time I select a file, it freezes, and I can't select directories.
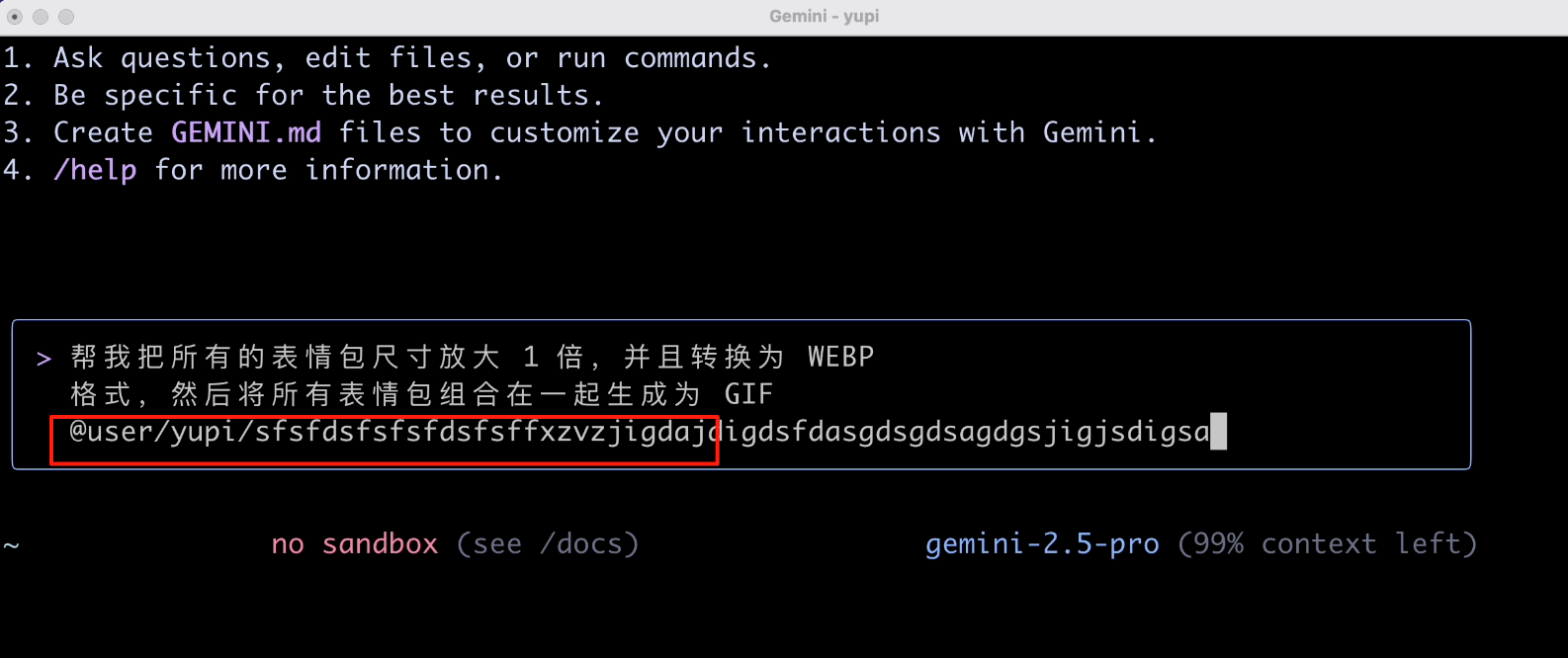
After some struggle, I found that I need to select slowly, following the directory tree listed by the program. Let's select one image first:

Okay, this time the AI was smart and asked if I wanted to process multiple files. Definitely:

Then, the AI found it couldn't process images and needed to download an image processing tool. It said it would use Mac's package management tool to install it. Agree:
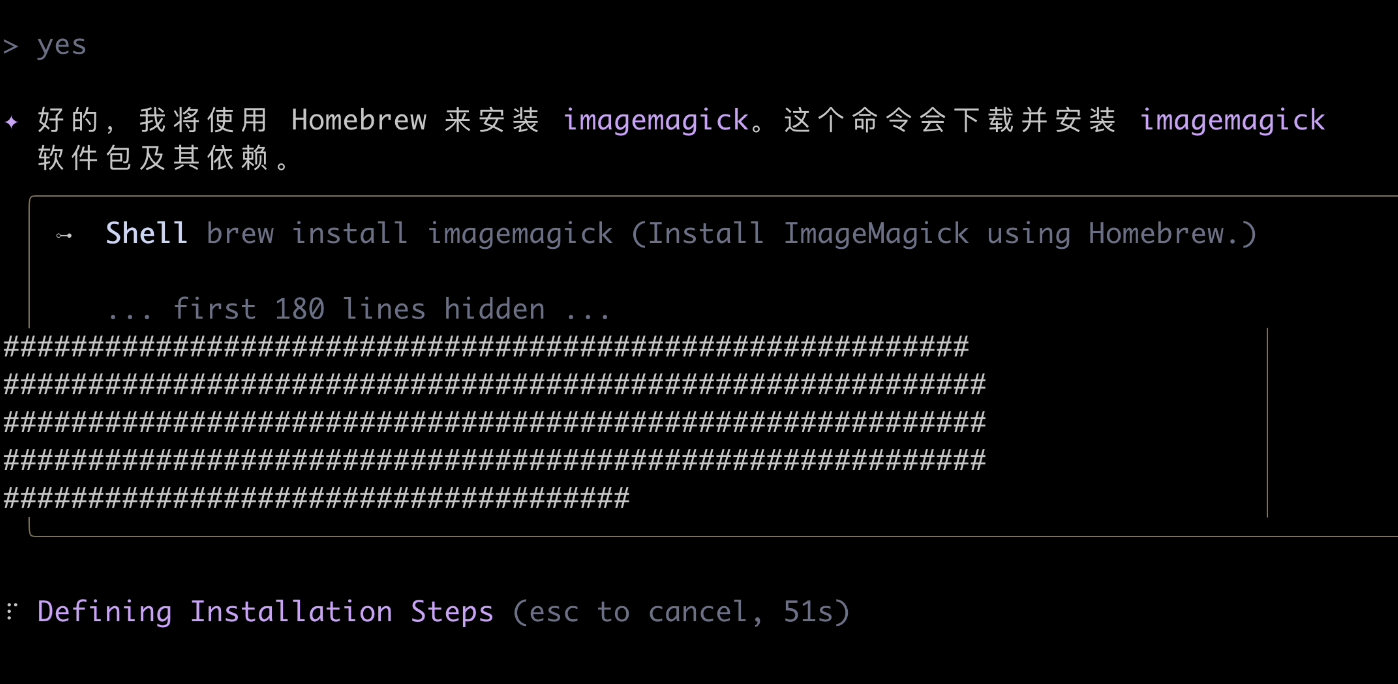
After a long wait, it still wasn't done after nearly 10 minutes?!
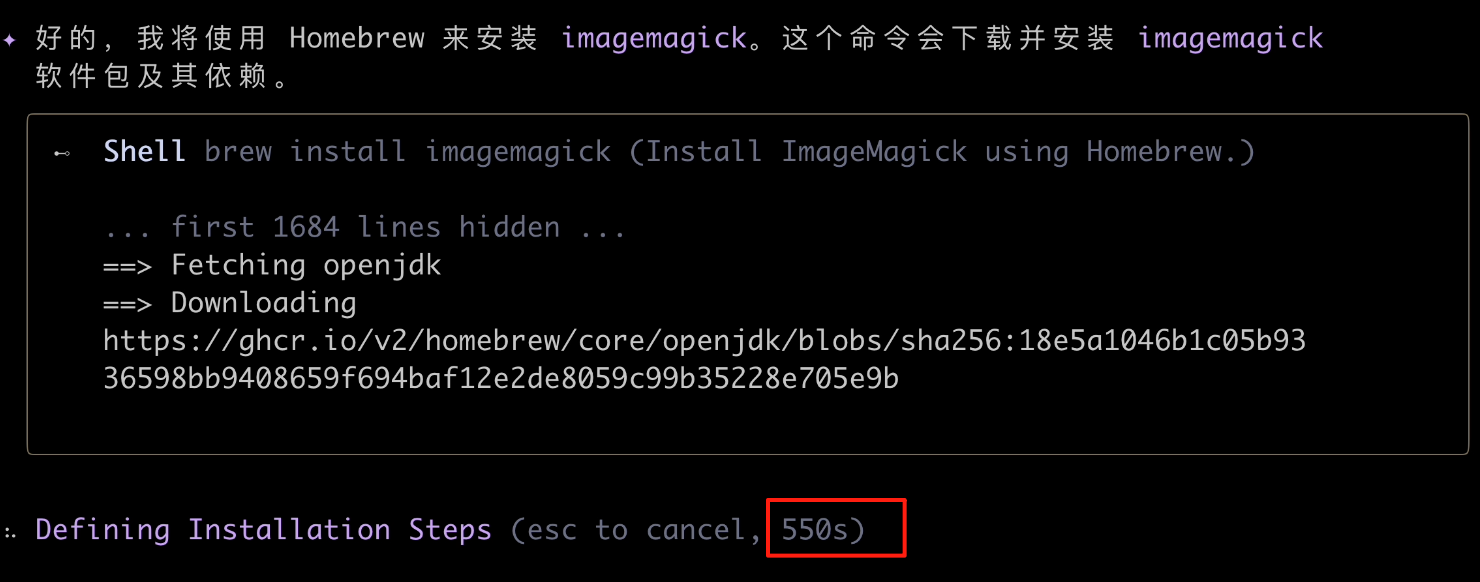
Maybe it's my network, but I couldn't wait any longer. Honestly, by this point, I was already a bit frustrated. It's 2:30 AM, and I'm waiting for software installation?

Isn't this something you could easily do with a simple Python script?
This tool seems more suited for programmers, with some guidance needed. For example, let's have the AI use a Python script to achieve the task:
Help me double the size of all memes, convert them to WEBP format, and then combine all memes into a GIF, using a Python script
We can see the AI installed an image processing library and created a virtual environment. Its consideration for security is commendable:
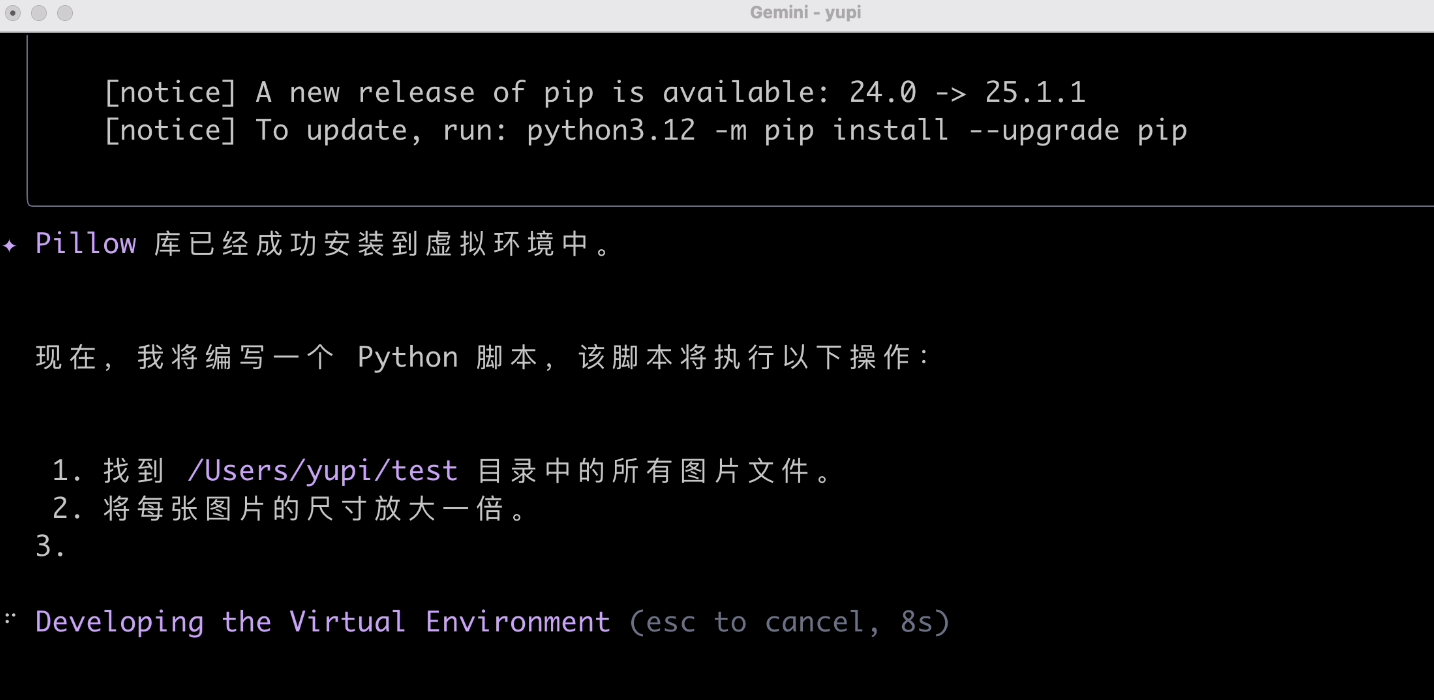
Then, it wrote and executed the script:
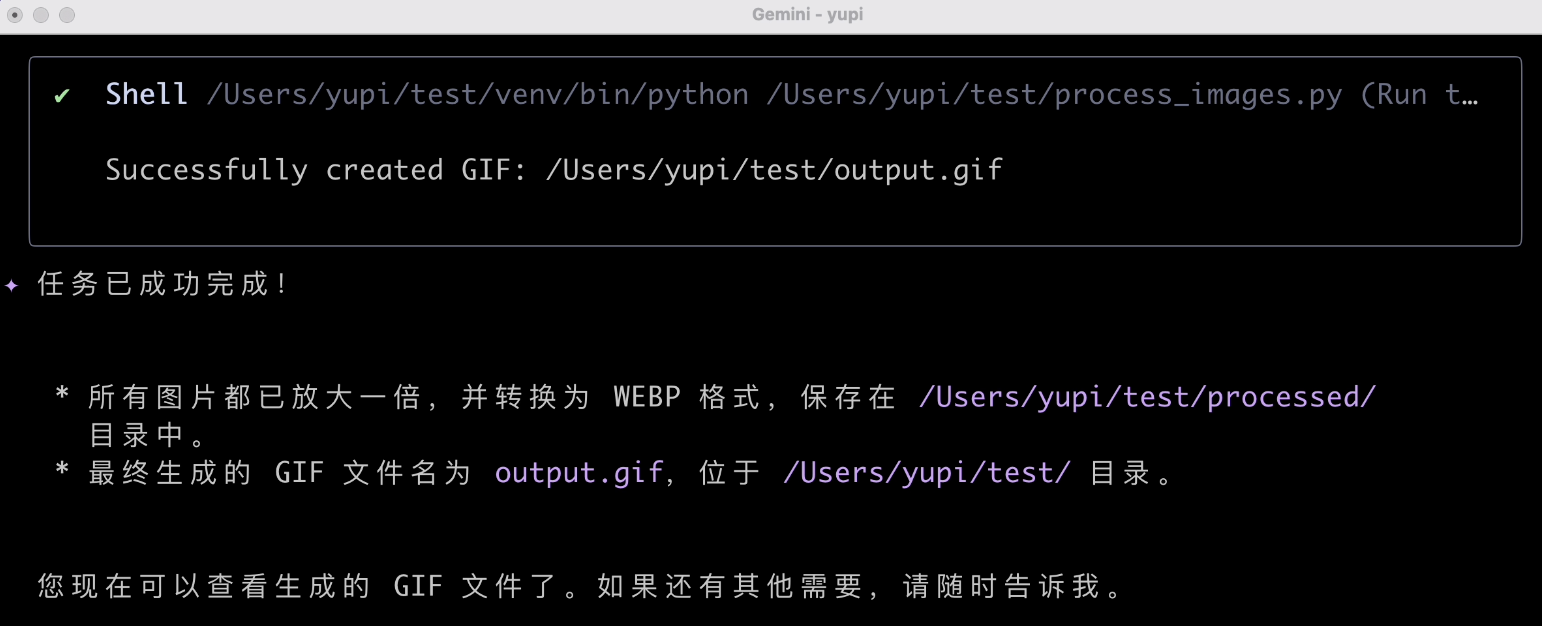
Task successfully completed. Let's check the results:
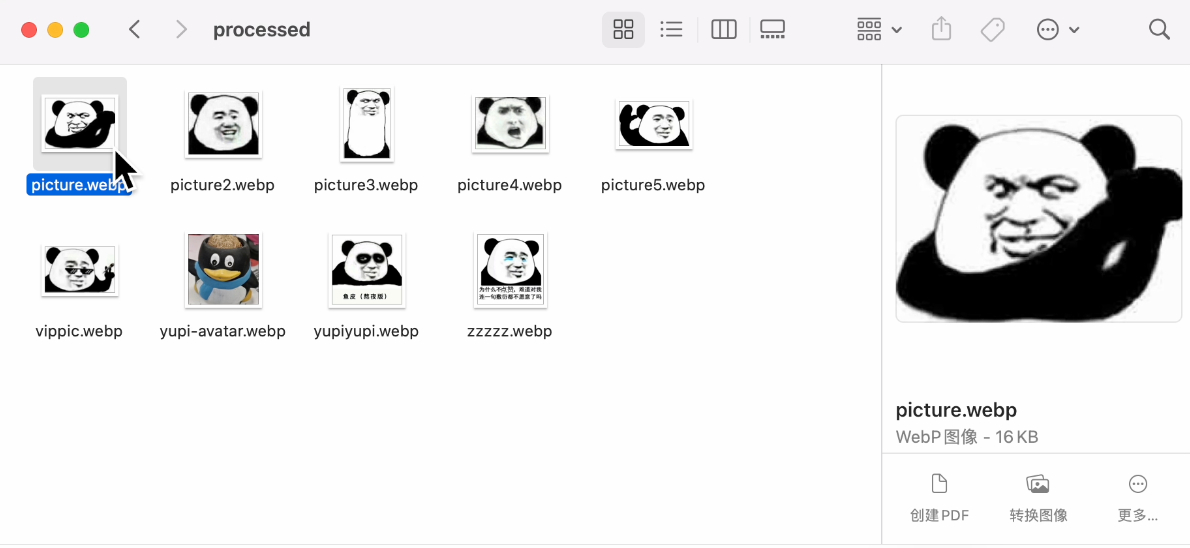
The size was indeed doubled, the format was successfully converted, and the GIF was generated. Finally, a task completed successfully. Not bad. Processing local images this way is indeed more convenient than web-based AI applications.
4. Code Generation
Input the following prompt to have the AI create a pixel photography website:
Please help me create a website that can call the camera to take photos, convert the photos to pixel style, support downloads, and have a simple and cool interface
This time, the generation speed was quite fast, but it required multiple manual confirmations during the process:
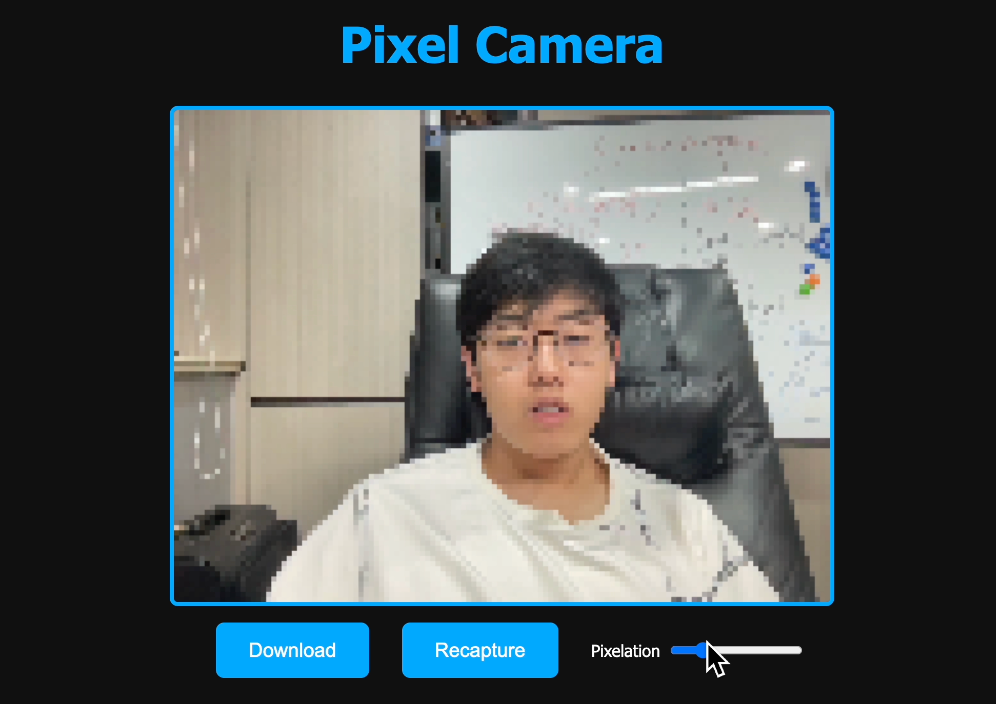
Let's check the generated website:
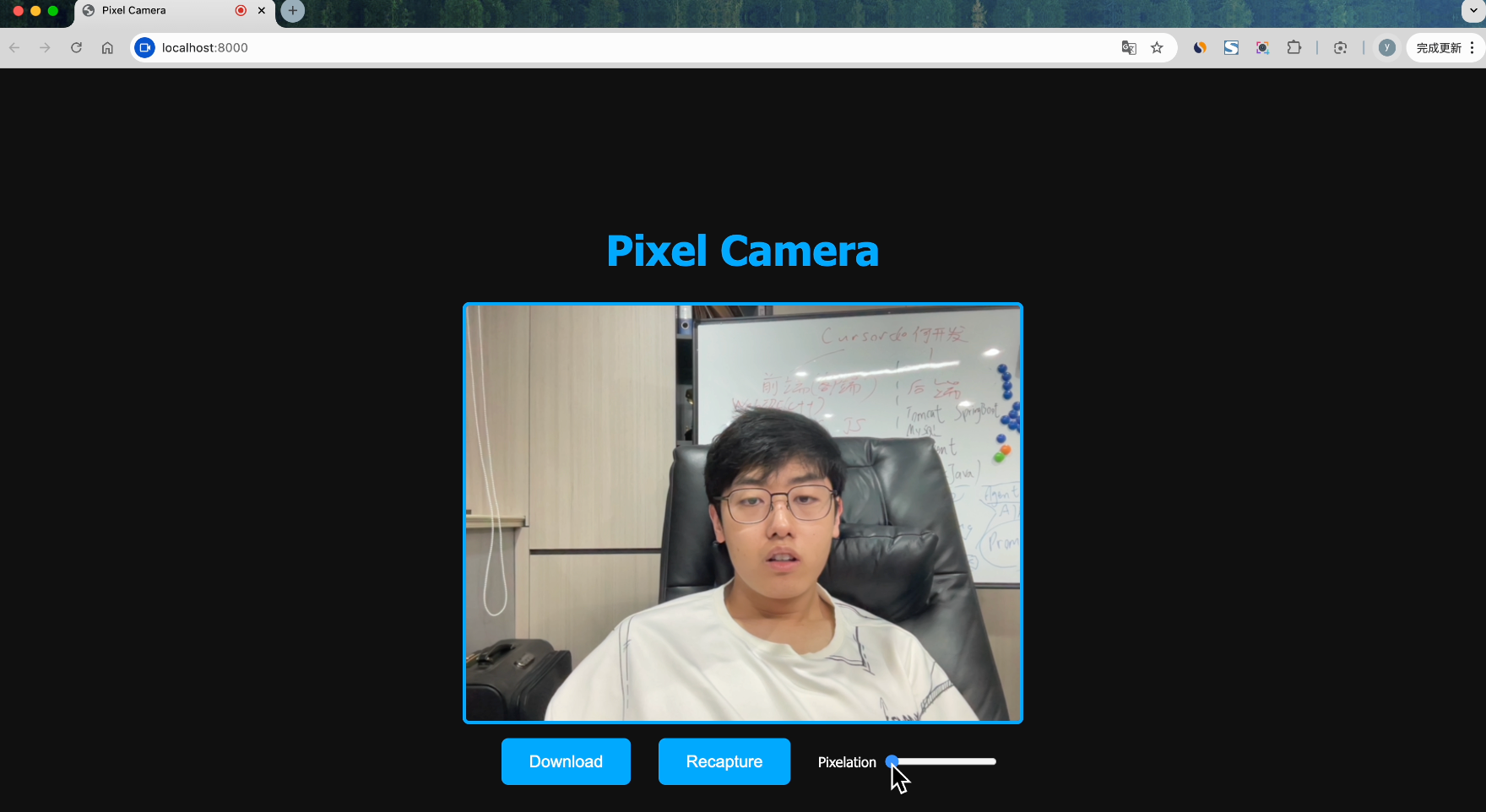
You can adjust the pixel density and download photos with one click. The effect is quite good, and the AI successfully completed this task~
5. Code Explanation
Add a learning guide to the newly generated project. Input prompt:
Help me generate a learning guide for this project to help new developers get started quickly
Since the AI has context, it directly understood which project I wanted it to analyze and quickly generated a project document.
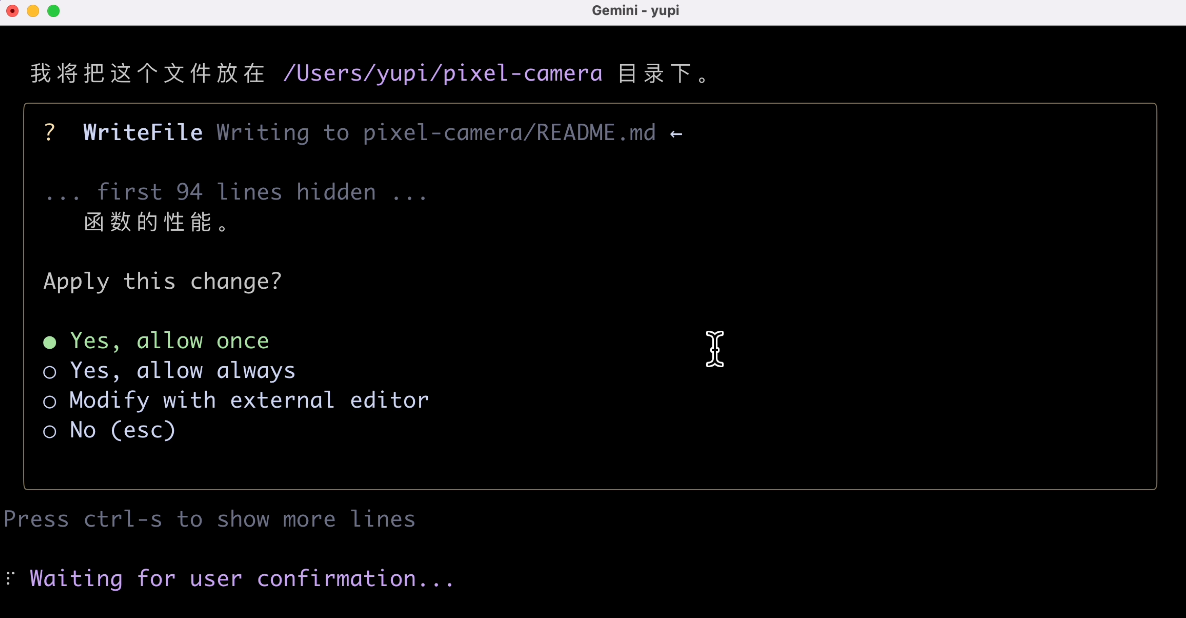
Then, I asked the AI to open the document file:
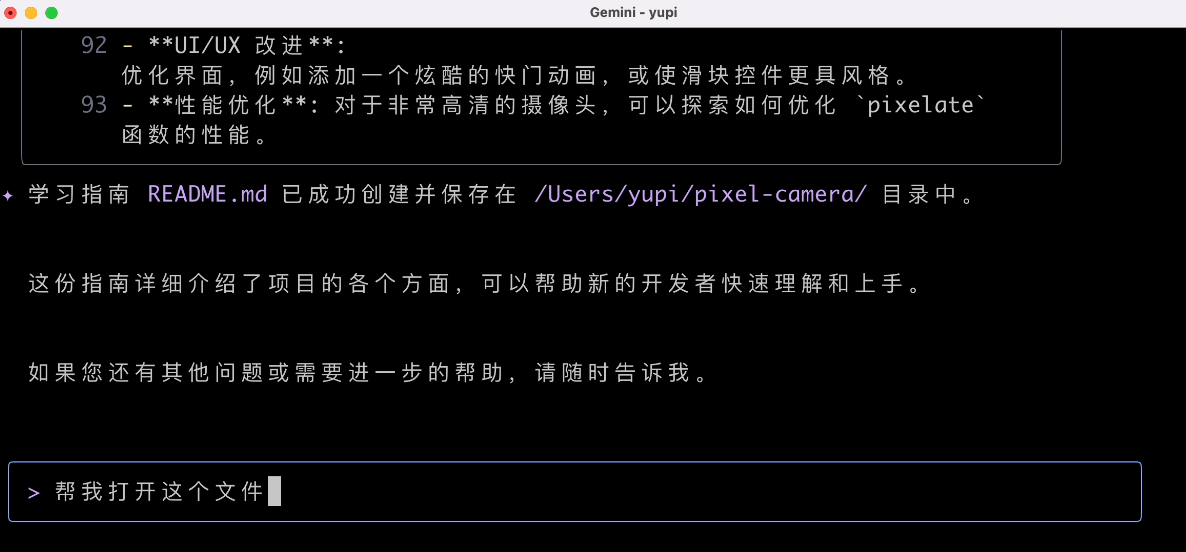
I originally wanted the AI to directly open a Markdown reader, but it output a bunch of irrelevant content. I don't understand.
I'll open it myself. The generated document content is decent, standard GitHub open-source project documentation.

6. Architecture Diagram Generation
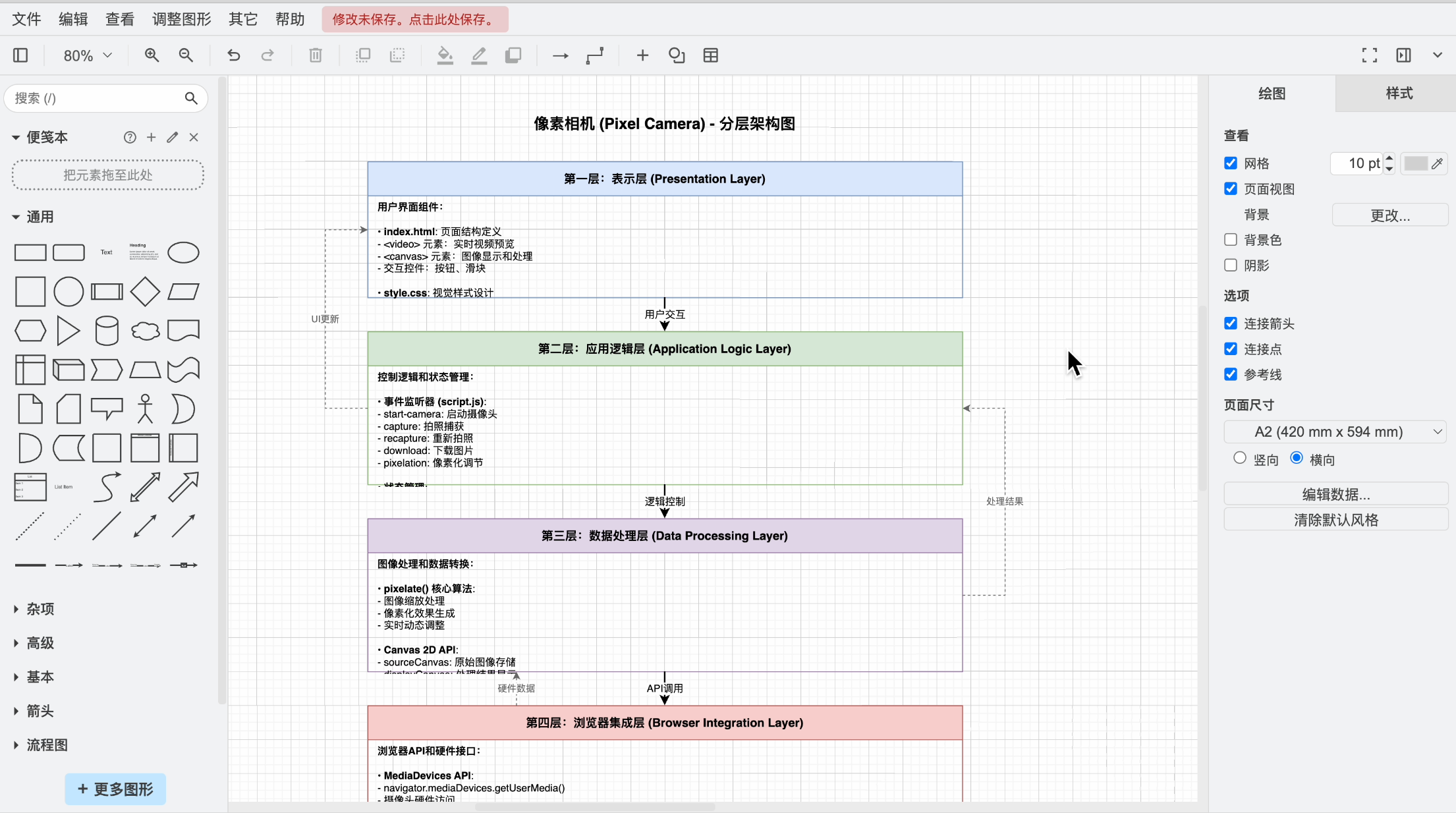
Alright, given that the previous task was completed well, let's increase the difficulty. Have the AI generate a layered architecture diagram for the project:
Help me generate a layered architecture diagram for the current project
The result was a bit of a mix-up. The AI generated an architecture design document:
You call this pure English document an architecture diagram?

Then, I'll exert my remaining professionalism and have it generate drawing code for the architecture diagram:
Help me generate draw.io code for the layered architecture diagram of the current project
This time, it looks more reliable:
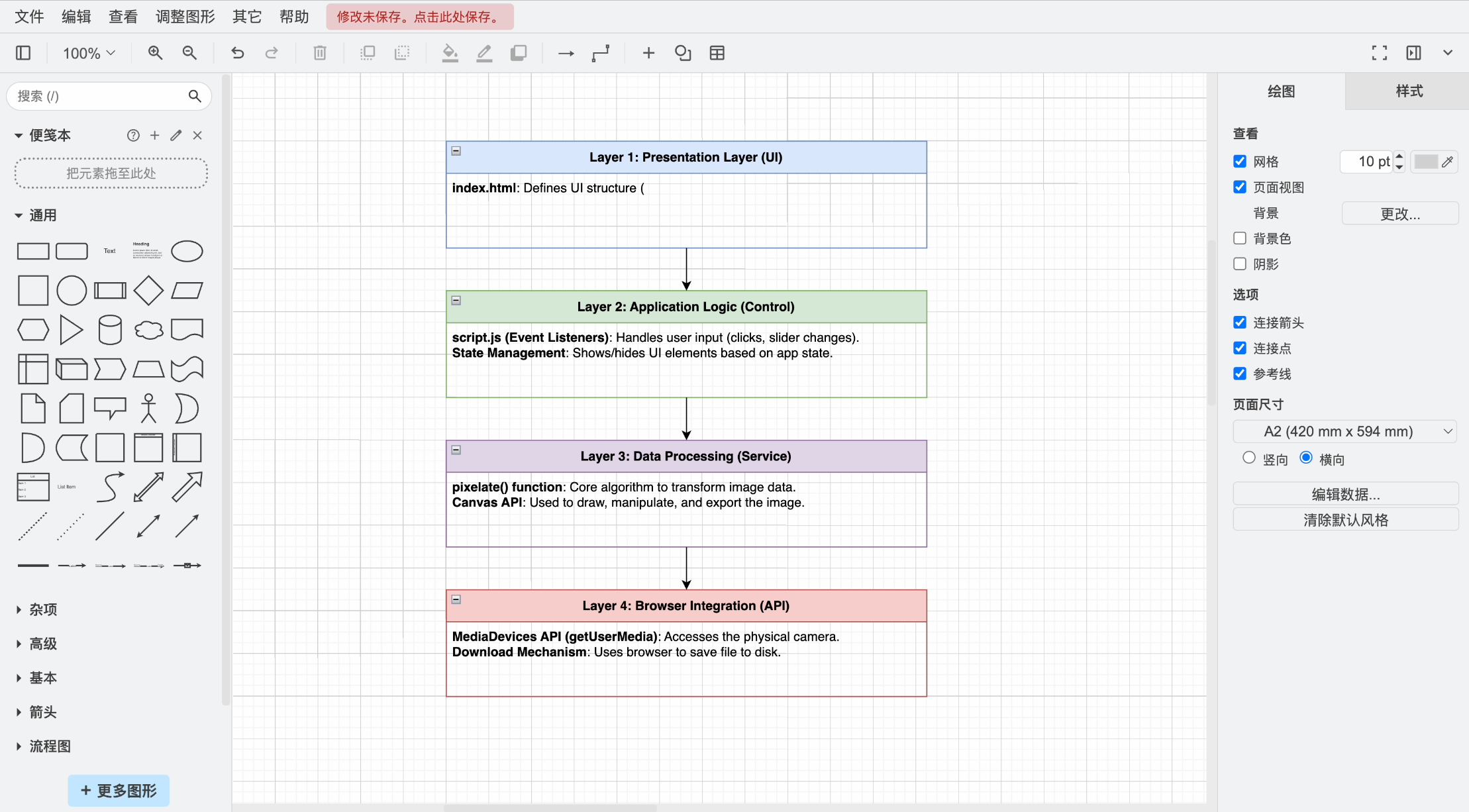
Let's drag the AI-generated architecture diagram code file into draw.io and open it.
Buddy? You call this an architecture diagram?
Let's try the same task with Cursor + Claude 4.
Ah, Claude is quite confident, saying "I can generate a more complete and detailed layered architecture diagram for you":
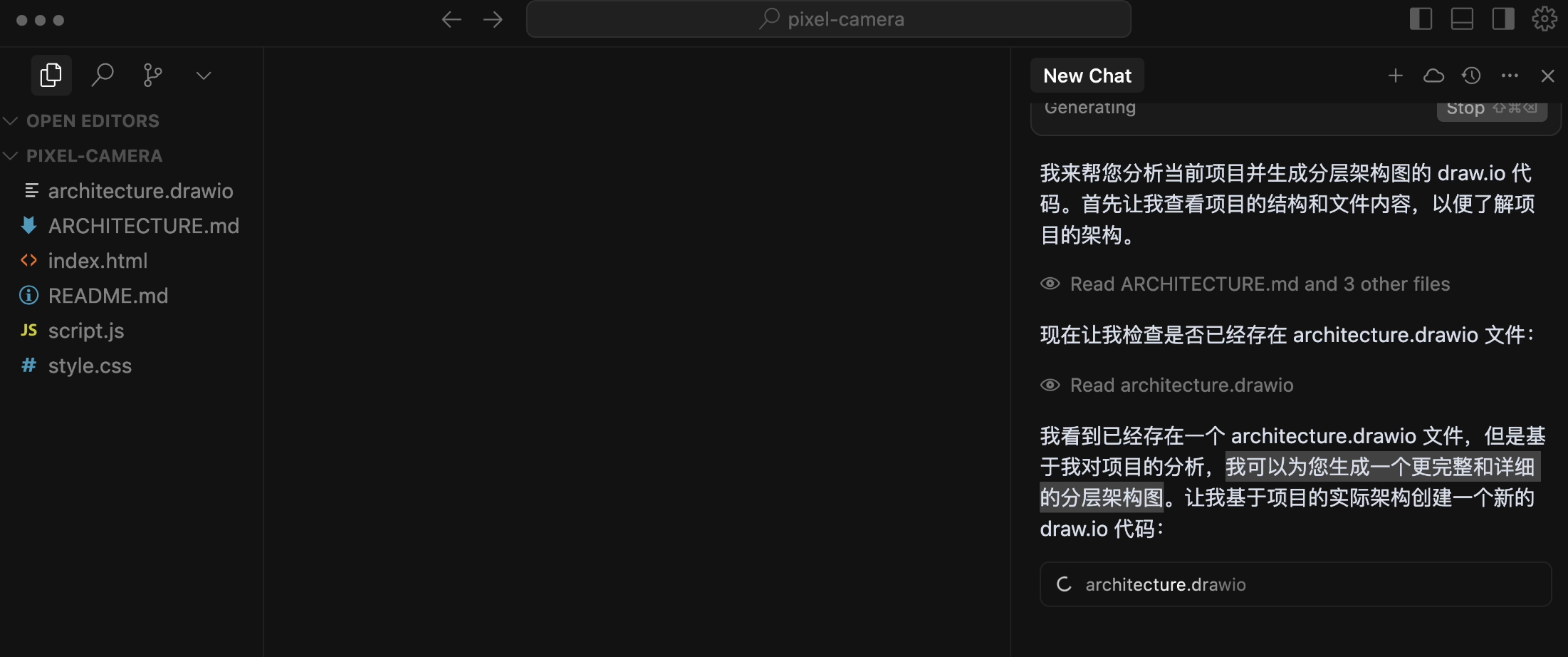
Alright, let's see the generated result. Isn't the difference clear?
7. Visualization Chart Generation
Have the AI analyze the project's commit history. Input prompt:
Based on the current project's commit history, generate a visualization chart to help me analyze the project's development timeline
We can see the AI using the git log command to view the commit history and then starting to generate the chart.
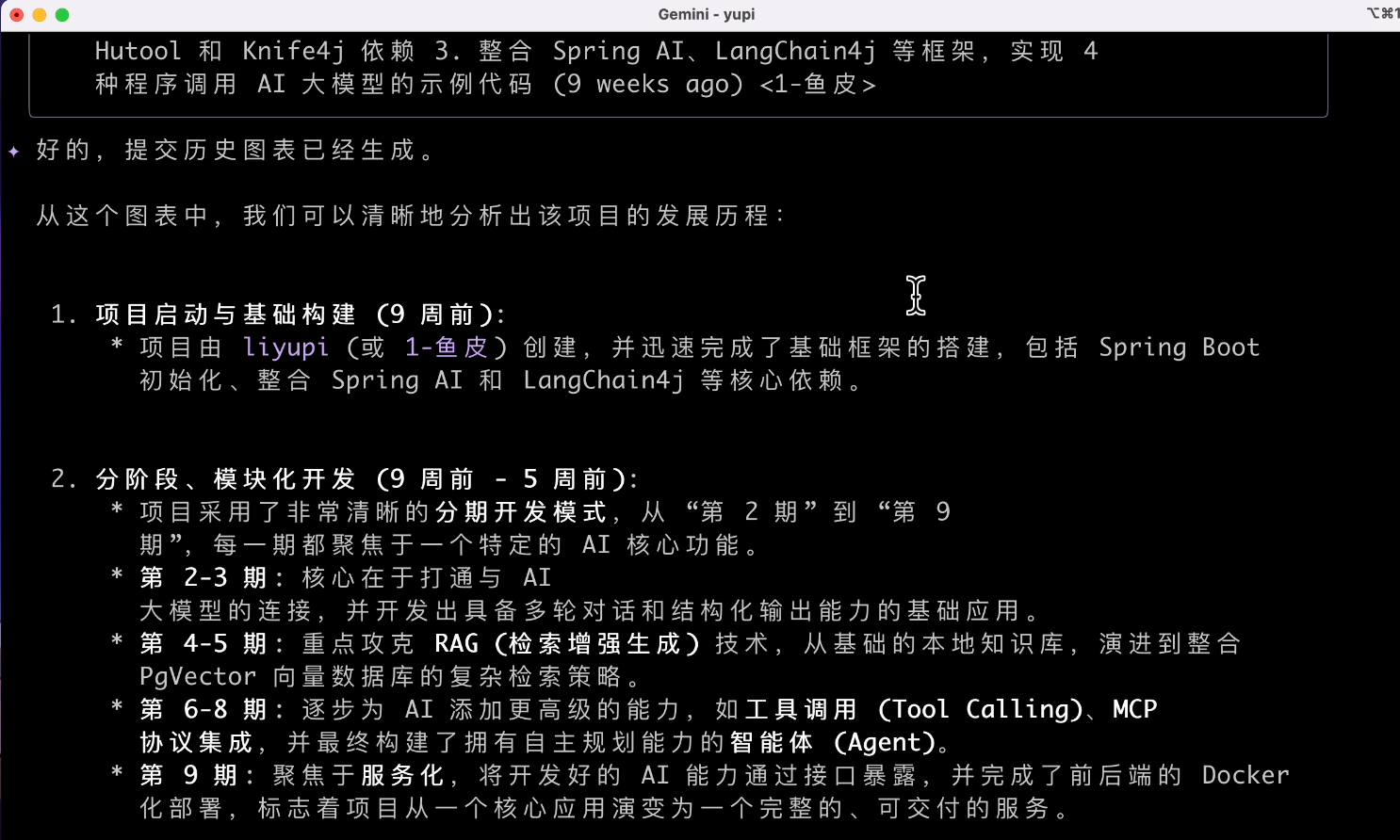
Wait? Where's the chart???
My expectation was definitely to generate an image, or at least a character drawing that looks like a chart. It's a bit tough for it.
8. Multimodal
By the time I got to testing multimodal capabilities, it was already 3 AM, and I was numb. Sigh, let's try multimodal one last time.
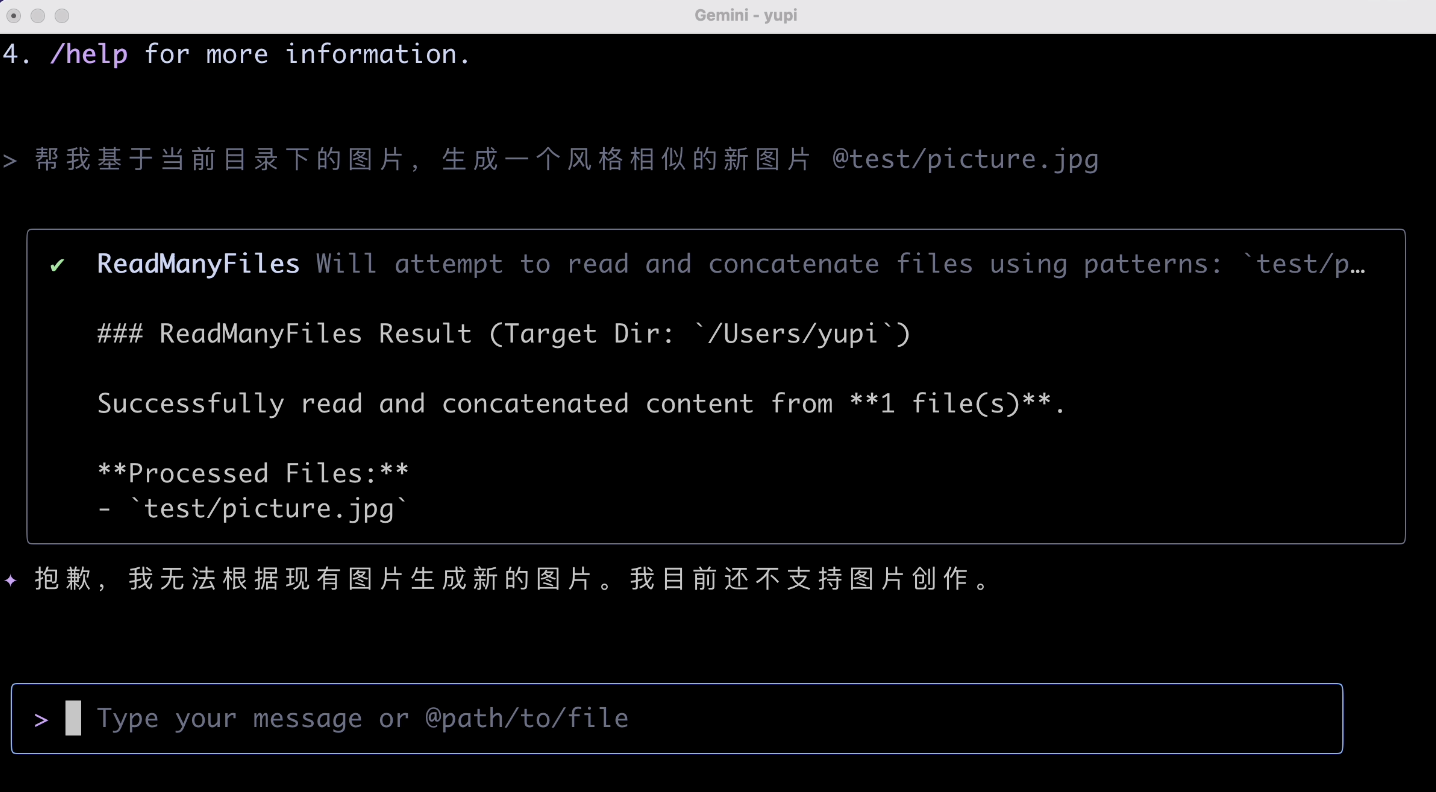
Input image generation prompt:
Help me generate a new image with a similar style based on the images in the current directory
This time, the AI directly refused, not supporting image creation. Why not write a script? You don't need AI; an image processor would work, right?
Then, let's try explaining an image. Input image explanation prompt:
Help me explain all the images in the current directory
It did explain them, but I have to complain—it's still in English. Probably related to the program's language settings. The experience isn't that great.
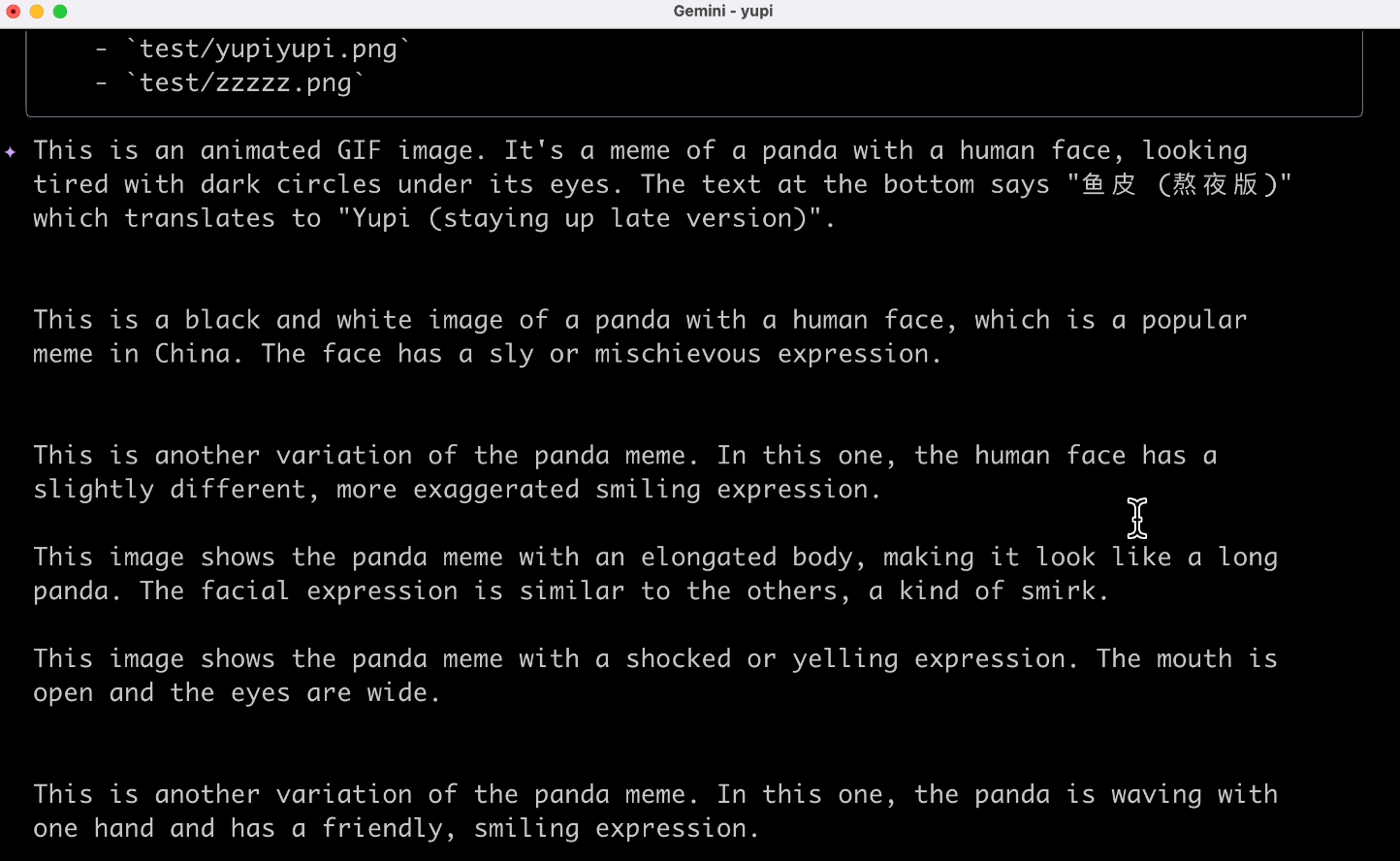
Gemini CLI likely uses the Gemini 2.5 Pro model, which has native multimodal input capabilities, meaning it can recognize images but can't create them. Audio and video creation are probably achieved through third-party large models (or MCP tools).
Finally, let's have it explain a PDF. Input prompt:
Help me summarize the content of the PDF and generate a new PDF
The result surprised me. The AI prompted that the input exceeded the token limit?
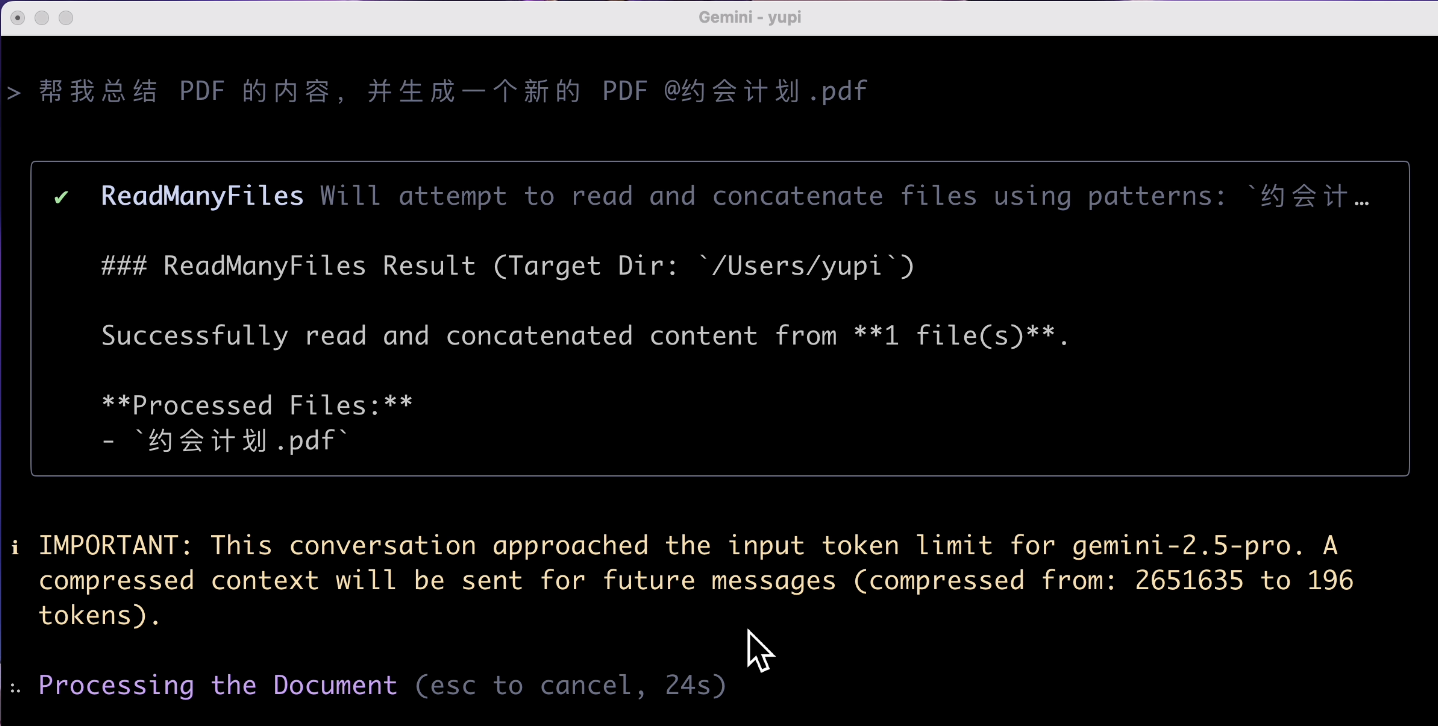
Isn't it supposed to have a 1 million token context? Why does reading a tiny PDF exceed the limit? I wouldn't be surprised if it couldn't generate a PDF, but my