54 lines
5.7 KiB
Markdown
54 lines
5.7 KiB
Markdown
# 阿里开源全新推理模型 QwQ-32B,一台 Mac 就能实现顶级推理能力
|
||
|
||
QwQ-32B 在数学推理、编程能力等问题解决方面表现出色。
|
||
|
||

|
||
|
||
3 月 6 日,阿里巴巴旗下的 Qwen 团队用一条题为《QwQ-32B:拥抱强化学习的力量》的博文公布了全新的开源大型推理模型 QwQ-32B(Qwen-with-Questions), **这款仅有 320 亿参数的模型通过强化学习技术,在多项基准测试中展现出与拥有 6710 亿参数(激活参数 37B)的 DeepSeek-R1 相媲美的性能。**
|
||
|
||
图丨相关博文(来源:Qwen)
|
||
|
||
**QwQ-32B 在数学推理、编程能力等问题解决方面表现出色。** 根据官方发布的基准测试结果,在数学推理基准 AIME24 上,QwQ-32B 达到了 79.5 分,几乎与 DeepSeek-R1 的 79.8 分持平,远超 OpenAI o1-mini 的 63.6 分,也超过了 DeepSeek-R1 蒸馏到 Llama-70B 和 Qwen-32B 的版本(分别为 70.0 和 72.6 分)。
|
||
|
||
在编程能力方面,QwQ-32B 在 LiveCodeBench 上获得了 63.4 分,接近 DeepSeek-R1 的 65.9 分,明显优于 o1-mini 的 53.8 分和蒸馏模型。在 LiveBench 测试中,QwQ-32B 得分 73.1,与 DeepSeek-R1 的 71.6 分相当,且大幅领先于 o1-mini 的 59.1 分。在 IFEval 和 BFCL 上,也略微超过了 R1。
|
||
|
||
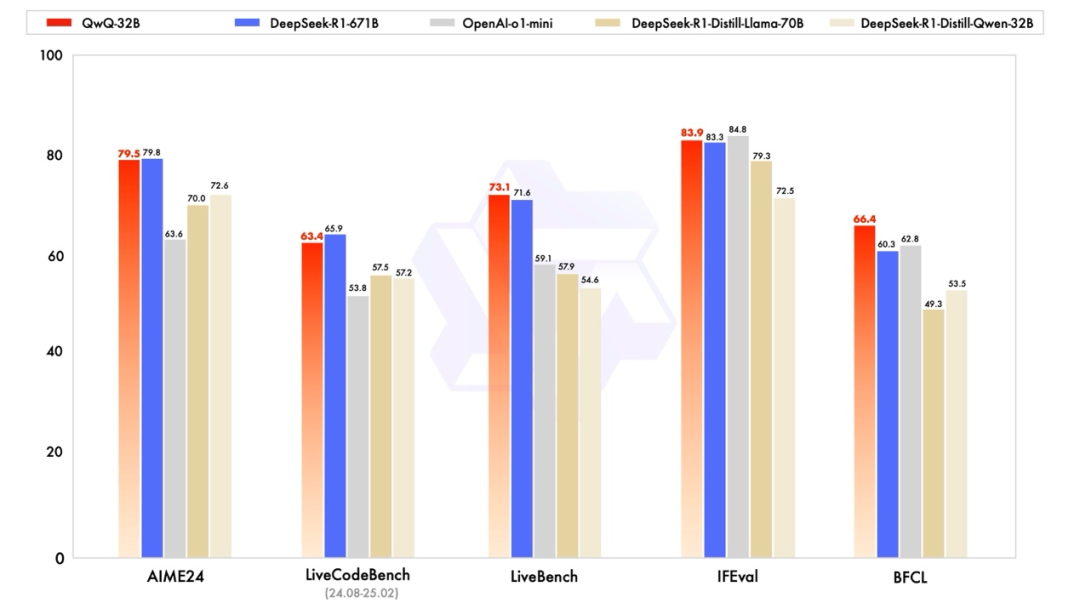图丨基准测试结果(来源:Qwen)
|
||
|
||
Hugging Face 的 Vaibhav Srivastav 在评测后发表评论: **“QwQ-32B 在 Hyperbolic Labs 支持下的推理速度‘快得惊人’,完全可与顶级模型媲美。”**“在 Apache 2.0 许可下,它成功击败了 DeepSeek-R1 和 OpenAI o1-mini。”
|
||
|
||
图丨相关推文(来源:X)
|
||
|
||
不过,有部分用户反应,QwQ-32B 有时会出现过度思考的问题,哪怕是很简单的问题也会生成大量的思维链(比如在经典的“Strawberry”问题上,它会输出近七万字的思维链),导致其输出结果的速度较慢。
|
||
|
||
模型架构方面,QwQ-32B 采用因果语言模型架构,具有 64 层 Transformer 结构,相比常见的模型层数更深。它完整集成了 RoPE(旋转位置编码)、SwiGLU 激活函数、RMSNorm 层归一化和 Attention QKV 偏置,这些都是当前先进大模型的标准配置。
|
||
|
||
模型采用了广义查询注意力机制,具体配置为 40 个查询头、8 个键值对头,这种配置优化了注意力机制的效率和性能。 **QwQ-32B 的上下文窗口长度高达 131,072 个 token,远超普通模型,支持超长文本处理。**
|
||
|
||
QwQ-32B 的训练过程分为三个阶段:预训练、监督微调和强化学习,其中强化学习又分为两个关键阶段:
|
||
|
||
第一阶段聚焦于数学和编程能力的提升。Qwen 团队从冷启动检查点开始,采用基于结果的奖励驱动的强化学习扩展方法。在数学问题训练时,模型使用专门的准确性验证器(Accuracy Verifier),而非传统奖励模型;编程任务则通过代码执行服务器(Code Execution Server)评估代码是否通过预定义测试用例。训练过程中,随着训练轮次增加,两个领域的性能持续提升。
|
||
|
||
第二阶段则侧重通用能力增强。模型引入通用奖励模型和规则验证器进行训练。即使是少量的训练步骤,也显著提升了指令跟随、人类偏好对齐和智能体性能,并且实现通用能力提升的同时,不显著降低第一阶段获得的数学和编程能力。
|
||
|
||
由此,QwQ 得以在 32B 的小参数上就实现了强大的推理能力。昨天还在感叹花八九万买 512GB 内存 M3 Ultra 的 Mac Studio 就能运行完整版 DeepSeek-R1 了(甚至还需要量化),但现在,只需要几千块的 Mac Mini,你就能获得接近的体验。
|
||
|
||
而且,QwQ-32B 的小参数量带来了更低的延迟和更高的吞吐量。在相同硬件条件下,小参数模型在推理速度上具有天然优势,能够提供更快的响应时间和更高的并发处理能力。对于一些中小型研究团队、初创企业和个人开发者来说,这无疑大大降低了他们使用先进推理模型的门槛。
|
||
|
||
而且,QwQ-32B 也整合了与智能体相关的能力,使模型能够在思考的同时使用工具,并根据环境反馈调整推理过程。在此基础上,QwQ-32B 就可以作为企业自动化流程中的核心推理引擎,处理从数据分析、报告生成到编程辅助等各种复杂任务。
|
||
|
||
目前, **QwQ-32B 已在 Hugging Face 和 ModelScope 上以 Apache 2.0 许可开源,个人用户也可通过 Qwen Chat 直接体验该模型。**
|
||
|
||
从 DeepSeek-R1 到 diffusion LLMs,再到 QwQ-32B,最近的一系列突破似乎让实现顶级性能模型所需要的算力越来越低,尽管未来对于高性能芯片的总需求或许并不会减少,但这种变化对于那些以往依赖大量计算资源的巨头们来说,恐怕免不了造成一些冲击。
|
||
|
||
参考资料:
|
||
|
||
https://qwenlm.github.io/zh/blog/qwq-32b/
|
||
|
||
运营/排版:何晨龙
|
||
|
||
2025 年 03 月 05 日
|
||
|
||

|
||
|
||
> 来源:www.mittrchina.com
|