- 新增支线文章:OpenClaw 部署教程、GLM-5 + OpenClaw AI 伴侣实战 - 融合内容:Claude Opus 4.6 / GPT-5.3-Codex 信息更新到模型选择指南, Claude Code 技巧融入命令行工具文章,Agentic Engineering 融入概念大全 - 概念大全新增:Agentic Engineering、深度思考、自适应思考、Hooks、 Subagents、斜杠命令、上下文压缩等概念,调整 MCP 和斜杠命令的板块归属 - 优质扩展推荐:新增 Agent Skills 技能类独立章节,充实 40+ 精选资源 - 全教程更新过时的模型版本引用(Opus 4.5→4.6, GLM-4.7→5 等)
1075 lines
43 KiB
Markdown
1075 lines
43 KiB
Markdown
# Vibe Coding 概念大全
|
||
|
||
> 一文搞懂 AI 编程的所有核心术语
|
||
|
||
|
||
|
||
你好,我是程序员鱼皮,前腾讯全栈开发,全网 200 万粉的 [AI 编程博主](https://space.bilibili.com/12890453),也是 [AI 导航](https://ai.codefather.cn) 和 [编程导航](https://www.codefather.cn) 等 10+ 自研产品的创造者。
|
||
|
||
在学习 Vibe Coding 的过程中,你一定会遇到各种陌生的名词和术语。比如什么是 Token?什么是上下文窗口?什么是 RAG?这些概念听起来很高大上,但其实理解起来并不难。
|
||
|
||
这篇文章就是你的 **AI 编程术语词典**,我会用最通俗易懂的语言,把 Vibe Coding 中最常见、最重要的概念讲清楚。你可以把它收藏起来,遇到不懂的词就来查一查。
|
||
|
||
|
||
|
||
## AI 基础概念
|
||
|
||
|
||
### 人工智能(AI)
|
||
|
||
人工智能(Artificial Intelligence)是让计算机模拟人类智能的技术。简单来说,就是让机器能像人一样思考、学习和解决问题。
|
||
|
||
在 Vibe Coding 中,AI 就是你的编程助手。你告诉它要做什么,它帮你写代码。就像你有一个 24 小时在线的程序员朋友,随时可以帮你干活。
|
||
|
||
|
||
|
||
|
||
### 大语言模型(LLM)
|
||
|
||
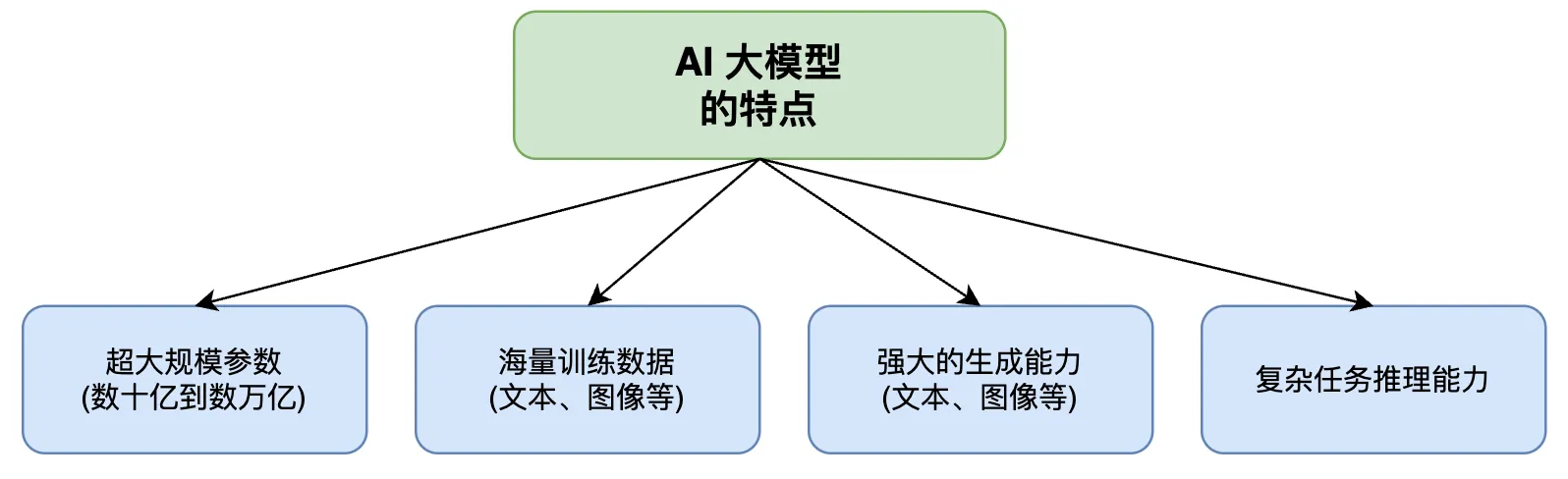
大语言模型(Large Language Model)是一种能够理解和生成人类语言的 AI 系统。ChatGPT、Claude、Gemini、DeepSeek 都是大语言模型。
|
||
|
||
为什么叫 “大” 呢?因为这些模型的参数量非常庞大,动辄几十亿甚至上万亿个参数。参数越多,模型通常越聪明,但也越消耗计算资源。
|
||
|
||
你可以把大语言模型理解成一个读过海量书籍和代码的超级学霸,它见过无数的编程案例,所以能帮你写代码、解释代码、修复 bug。
|
||
|
||
|
||
|
||
|
||
|
||
### 模型参数
|
||
|
||
参数是模型在训练过程中学到的 “知识点”,用数字的形式存储在模型中。参数越多,模型能记住的知识就越丰富,通常也越聪明。
|
||
|
||
比如:
|
||
|
||
- GPT-4 大约有 1.8 万亿参数
|
||
- Claude 3.5 Sonnet 的参数量未公开,但估计在千亿级别
|
||
- DeepSeek-V3 有 6710 亿参数
|
||
|
||
参数量会影响模型的能力和运行成本。一般来说,参数越多的模型越贵,但效果也越好。
|
||
|
||
|
||
|
||
|
||
### 训练和推理
|
||
|
||
训练(Training)是让 AI 模型从大量数据中学习知识的过程。这个过程需要海量的计算资源和时间,通常由 AI 公司完成。你不需要自己训练模型。
|
||
|
||
推理(Inference)是模型学完之后,用学到的知识来回答问题、生成内容的过程。当你用 ChatGPT 对话时,就是在进行推理。
|
||
|
||
打个比方:训练就像学生上学读书,推理就像学生参加考试答题。我们日常使用 AI 工具,都是在用推理能力。
|
||
|
||
|
||
|
||
|
||
### 微调(Fine-tuning)
|
||
|
||
微调是在已有模型的基础上,用特定领域的数据继续训练,让模型在某个领域表现更好。
|
||
|
||
比如,你可以用大量的医学资料微调一个模型,让它成为医学专家。或者用你公司的代码库微调,让它更了解你的项目风格。
|
||
|
||
对于普通用户来说,微调成本较高,一般不需要自己做。直接使用现成的模型就够用了。
|
||
|
||
|
||
|
||
## Token 和计费
|
||
|
||
|
||
### Token
|
||
|
||
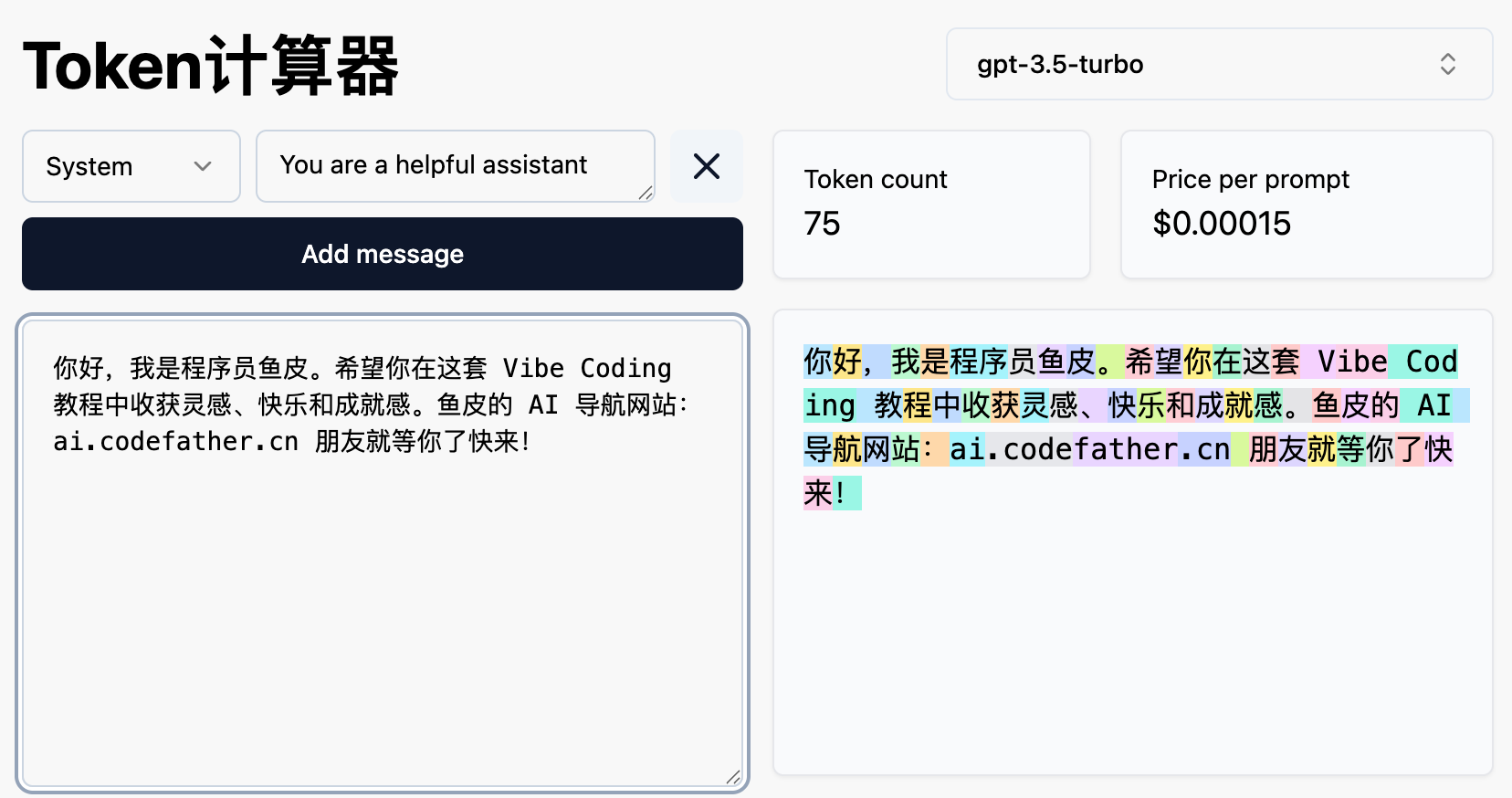
Token 是 AI 模型处理文本的基本单位。你可以简单理解为 “词块”。
|
||
|
||
在英文中,一个 Token 大约是一个单词或单词的一部分。在中文中,一个汉字通常是 1-2 个 Token。
|
||
|
||
为什么 Token 重要?因为 AI 服务通常按 Token 收费。你输入的文字和 AI 输出的文字都会消耗 Token。Token 用得越多,花的钱就越多。
|
||
|
||
举个例子:
|
||
|
||
- "Hello World" 大约是 2 个 Token
|
||
- “你好世界” 大约是 4-6 个 Token
|
||
|
||
|
||
|
||
|
||
|
||
### 输入 Token 和输出 Token
|
||
|
||
AI 服务通常分别计算输入和输出的 Token:
|
||
|
||
- 输入 Token:你发给 AI 的内容(提示词、代码、文件等)
|
||
- 输出 Token:AI 返回给你的内容(回答、生成的代码等)
|
||
|
||
一般来说,输出 Token 比输入 Token 更贵,因为生成内容比理解内容更消耗算力。
|
||
|
||
省钱小技巧:写清楚、写简洁的提示词,让 AI 一次就能理解你的需求,减少反复对话。
|
||
|
||
|
||
|
||
### 上下文窗口
|
||
|
||
上下文窗口(Context Window)是指 AI 模型一次能 “记住” 的最大内容量,用 Token 来衡量。
|
||
|
||
不同模型的上下文窗口大小不同:
|
||
|
||
- GPT-4o:128K Token(约 10 万中文字)
|
||
- Claude 3.5 Sonnet:200K Token(约 15 万中文字)
|
||
- Gemini 2.0 Pro:2M Token(约 150 万中文字)
|
||
|
||
上下文窗口越大,AI 能处理的代码量就越多,能记住的对话历史就越长。如果你的项目代码很多,选择上下文窗口大的模型会更合适。
|
||
|
||
但要注意,上下文窗口越大,每次请求消耗的 Token 也越多,成本也会更高。
|
||
|
||
|
||
|
||
## 提示词相关
|
||
|
||
|
||
### 提示词(Prompt)
|
||
|
||
提示词是你给 AI 的指令或问题。在 Vibe Coding 中,提示词就是你用自然语言描述的需求。
|
||
|
||
提示词的质量直接决定了 AI 输出的质量。一个好的提示词应该:
|
||
|
||
- 具体明确,不含糊
|
||
- 包含必要的背景信息
|
||
- 说明期望的输出格式
|
||
|
||
比如,“做一个网站” 是一个模糊的提示词,而 “用 React 做一个记账网站,包含添加支出、查看列表、统计总额三个功能,界面用蓝色调” 就是一个好的提示词。
|
||
|
||
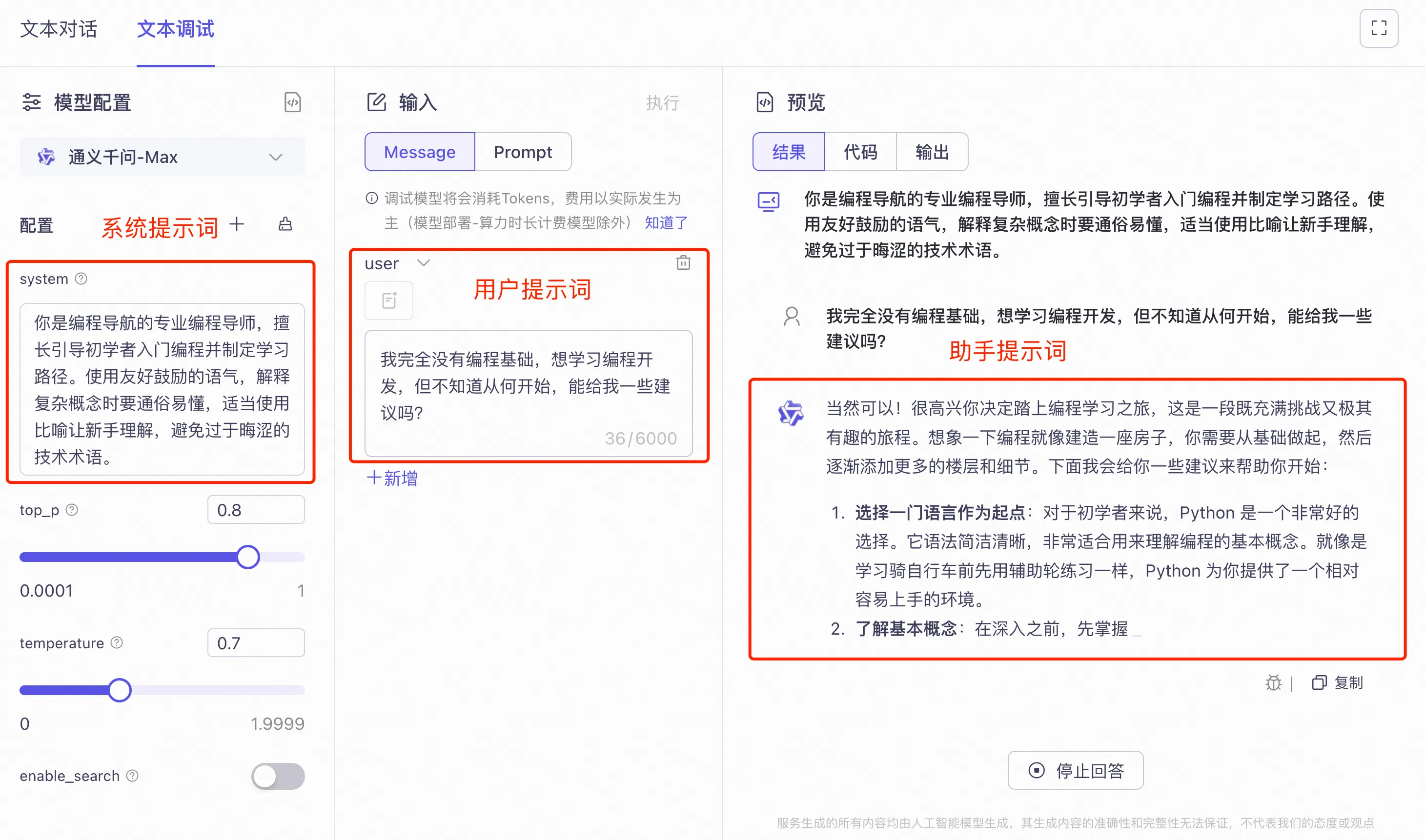
在 AI 对话中,消息通常分为三种角色:
|
||
|
||
- 系统提示词(System):设置 AI 的角色和行为规则,对用户不可见
|
||
- 用户提示词(User):你发送给 AI 的消息
|
||
- 助手提示词(Assistant):AI 回复给你的消息
|
||
|
||
理解这 3 种角色有助于你更好地构造对话。比如在调试时,你可以在提示词中模拟之前的对话历史,让 AI 更好地理解上下文。
|
||
|
||
|
||
|
||
### 系统提示词
|
||
|
||
系统提示词(System Prompt)是在对话开始前设置的指令,用来定义 AI 的角色、行为和限制。
|
||
|
||
比如,你可以设置系统提示词:“你是一位资深的 React 开发专家,请用简洁清晰的代码风格回答问题。”
|
||
|
||
系统提示词在整个对话过程中都会生效,是定制 AI 行为的重要方式。
|
||
|
||
|
||
|
||
|
||
|
||
### 提示词工程
|
||
|
||
提示词工程(Prompt Engineering)是设计和优化提示词的技术,目的是让 AI 更好地理解你的意图,生成更符合预期的结果。
|
||
|
||
这是 Vibe Coding 的核心技能之一。好的提示词工程师能用更少的对话轮次,让 AI 生成更高质量的代码。
|
||
|
||
|
||
|
||
### 零样本提示(Zero-shot)
|
||
|
||
零样本提示是指直接给 AI 一个任务,不提供任何示例。
|
||
|
||
比如:“请把这段英文翻译成中文。”
|
||
|
||
AI 会根据自己的训练知识来完成任务。对于简单任务,零样本提示通常就够用了。
|
||
|
||
|
||
|
||
### 少样本提示(Few-shot)
|
||
|
||
少样本提示是在提示词中提供几个示例,让 AI 学习你想要的格式或风格。
|
||
|
||
比如:
|
||
|
||
```
|
||
请按以下格式翻译:
|
||
英文:Hello → 中文:你好
|
||
英文:Thank you → 中文:谢谢
|
||
英文:Good morning → 中文:
|
||
```
|
||
|
||
通过提供示例,AI 能更准确地理解你的需求,输出更一致的结果。
|
||
|
||
|
||
|
||
### 思维链提示(Chain-of-Thought)
|
||
|
||
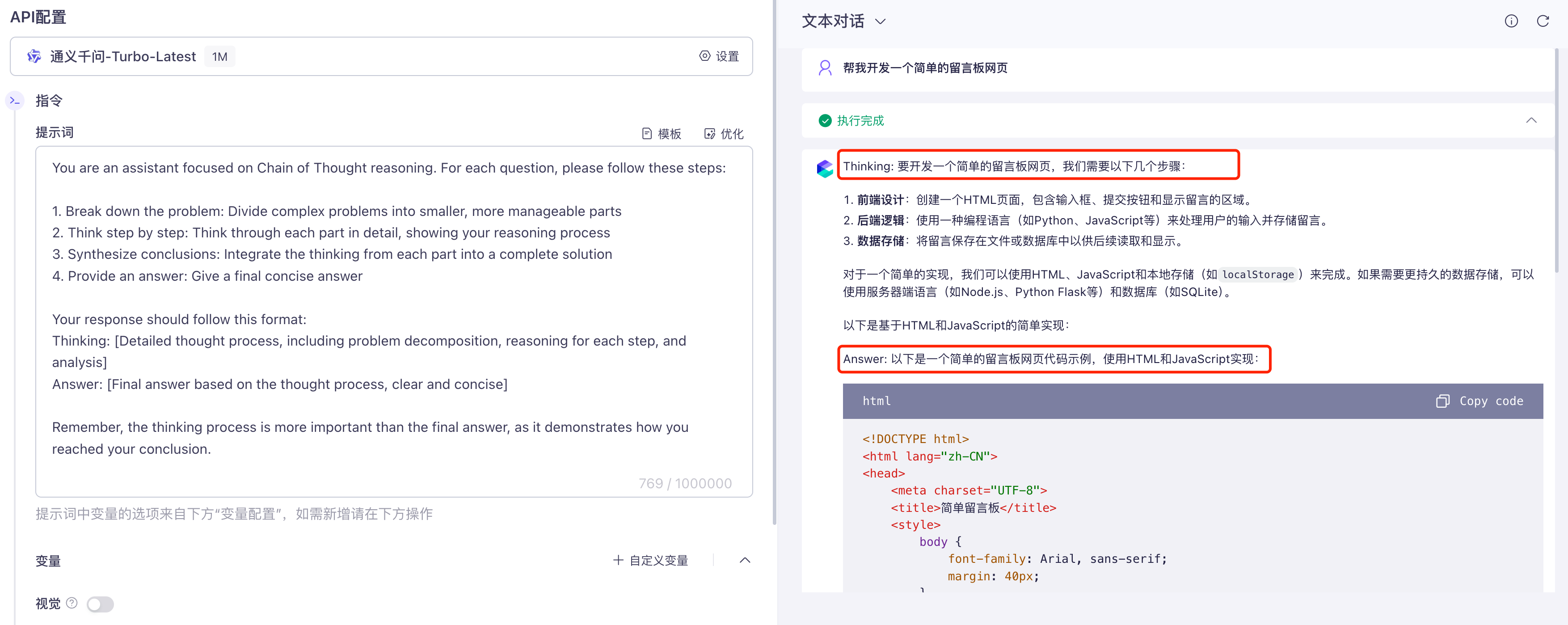
思维链提示是让 AI 一步一步思考问题,而不是直接给出答案。这对于复杂的推理任务特别有效。
|
||
|
||
你可以在提示词中加上 “请一步一步思考” 或 "Let's think step by step",AI 就会展示它的推理过程,通常能得到更准确的答案。
|
||
|
||
在编程中,思维链提示能帮助 AI 更好地理解复杂需求,生成更合理的代码结构。
|
||
|
||
|
||
|
||
|
||
|
||
### Markdown 语言
|
||
|
||
Markdown 是一种轻量级的文本标记语言,用简单的符号来表示格式。比如用 `#` 表示标题,用 `**文字**` 表示加粗,用 `-` 表示列表。
|
||
|
||
在 Vibe Coding 中,Markdown 非常重要,因为:
|
||
|
||
- AI 生成的回答通常是 Markdown 格式
|
||
- 项目文档(如 README)用 Markdown 编写
|
||
- 规则文件也是 Markdown 格式
|
||
|
||
学会 Markdown 能让你更好地与 AI 交流,也能写出更规范的项目文档。
|
||
|
||
|
||
|
||
|
||
## AI 编程模式
|
||
|
||
|
||
### Vibe Coding
|
||
|
||
Vibe Coding 是由计算机科学家 Andrej Karpathy 在 2025 年 2 月提出的概念。它描述了一种全新的编程方式:通过自然语言和 AI 对话,让 AI 帮你写代码,你只需要描述需求、测试结果、指导方向。
|
||
|
||
Vibe Coding 的核心理念是:你不需要精通编程语法,只需要能清楚表达你的想法。AI 负责把你的想法变成可运行的代码。
|
||
|
||
这就像点外卖一样:你告诉外卖平台你想吃什么,餐厅帮你做好送到手上。你不需要会做饭,但要知道自己想吃什么。
|
||
|
||
|
||
|
||
### Agentic Engineering 智能体工程
|
||
|
||
Agentic Engineering(智能体工程)是 2026 年 2 月由 Andrej Karpathy(也就是提出 Vibe Coding 的那位大佬)提出的新概念,可以理解为 Vibe Coding 的规范版。
|
||
|
||
Vibe Coding 就是跟着感觉写代码:你给 AI 一句话,AI 吐出代码,能跑就行,跑不了就把报错粘回去让 AI 再改。做个小工具贼拉快,但项目一大就容易翻车。
|
||
|
||
而 Agentic Engineering 的思路是:你先想清楚要干嘛、写好方案、拆好任务,再把活交给 AI 去执行,它干完了你还得验收,质量不行打回去重做。
|
||
|
||
打个比方,Vibe Coding 的时候你是个 DJ,放什么歌全凭感觉;Agentic Engineering 里你是包工头,流程、质量、验收都得你说了算。**一个跟着感觉走,一个按流程来。**
|
||
|
||
当然,不是说 Vibe Coding 已经过时了。Vibe Coding 负责让你看到可能性,Agentic Engineering 负责把可能性变成真正能用的东西。二者适用于不同的场景,做个小工具用 Vibe Coding,做正式项目就需要 Agentic Engineering 的思维。
|
||
|
||

|
||
|
||
|
||
|
||
|
||
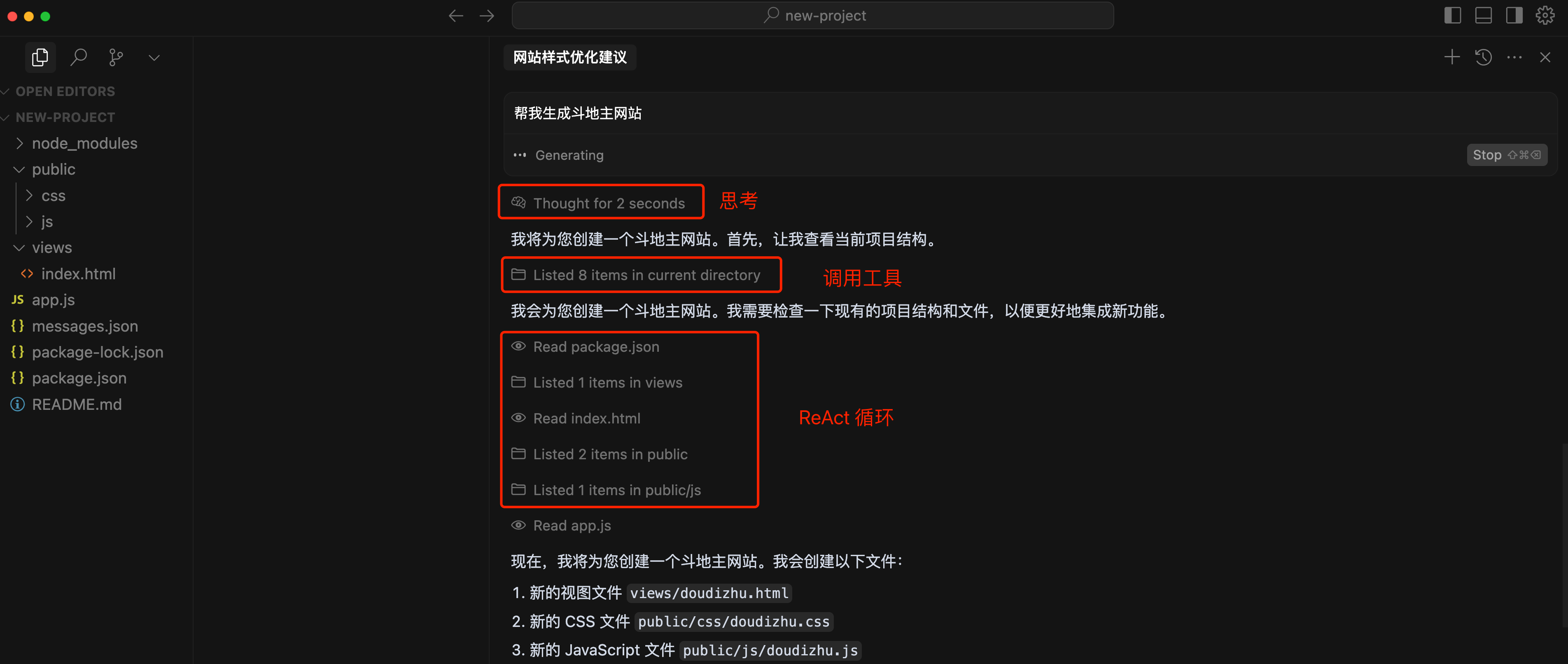
### Agentic Coding 智能体编程
|
||
|
||
Agentic Coding 是指让 AI 像一个自主的 “智能体”(Agent)一样工作,能够自己规划任务、执行操作、验证结果,而不只是被动地回答问题。
|
||
|
||
在 Cursor 的 Agent 模式中,AI 可以:
|
||
|
||
- 自动读取和分析多个文件
|
||
- 规划实现方案
|
||
- 执行代码修改
|
||
- 运行测试验证
|
||
- 自动修复问题
|
||
|
||
这比传统的问答式 AI 更强大,因为它能自主完成复杂的多步骤任务。
|
||
|
||
|
||
|
||
|
||
|
||
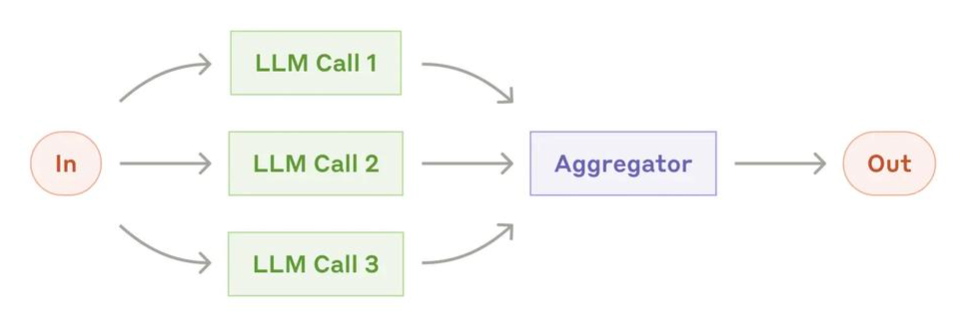
### 多智能体协作
|
||
|
||
多智能体协作(Multi-Agent)是指多个 AI 智能体分工合作,共同完成复杂任务。
|
||
|
||
比如,一个智能体负责设计架构,一个负责写前端代码,一个负责写后端代码,一个负责代码审查。它们像一个团队一样协作。
|
||
|
||
这两年,多智能体系统正在成为 AI 编程的重要趋势,能够处理更复杂的项目。
|
||
|
||
|
||
|
||
|
||
|
||
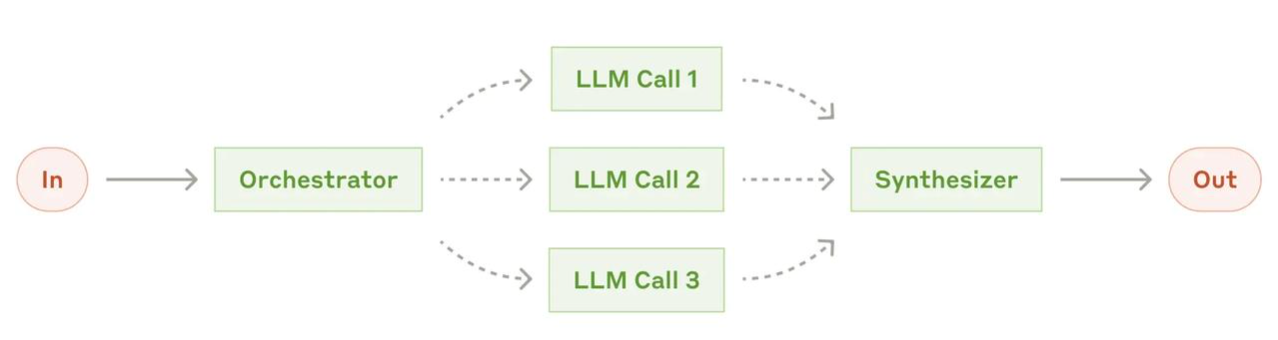
### 智能体编排
|
||
|
||
编排是指协调和管理多个 AI 智能体或 AI 任务的过程,确保它们按正确的顺序和方式工作。
|
||
|
||
就像乐队指挥一样,编排器决定哪个智能体在什么时候做什么事情,如何传递信息,如何汇总结果。
|
||
|
||
|
||
|
||
|
||
|
||
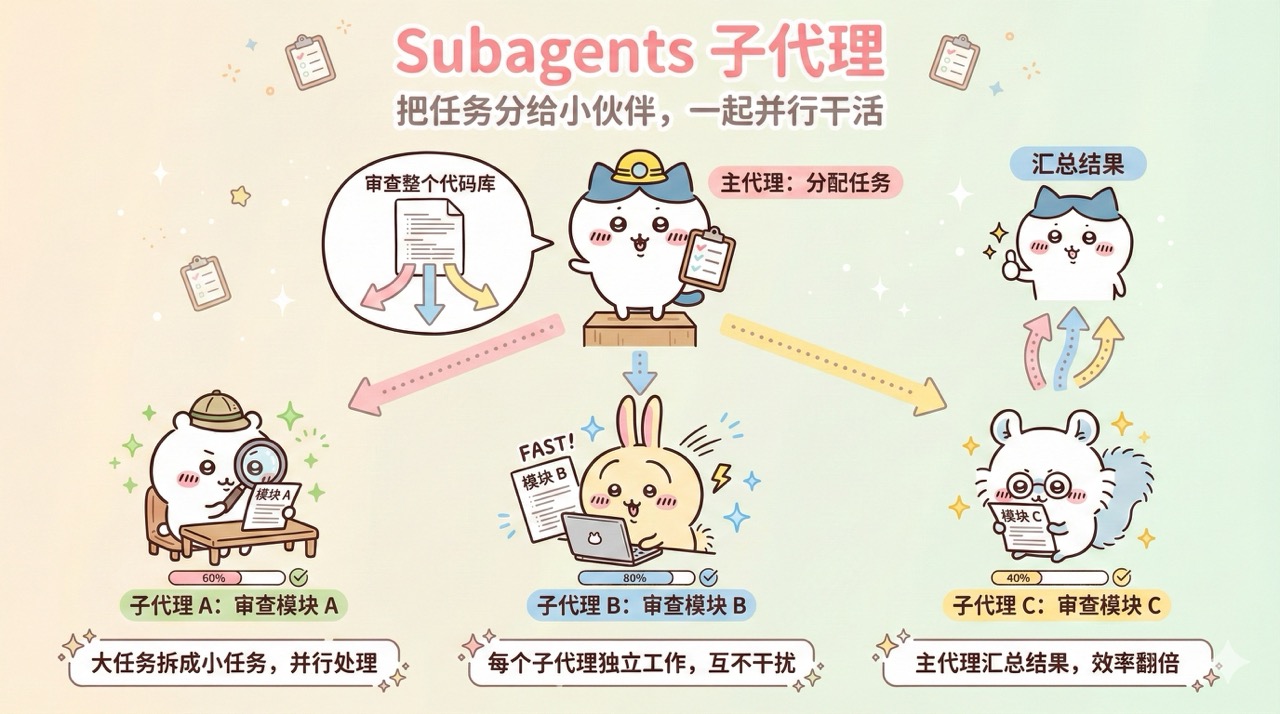
### Subagents 子代理
|
||
|
||
Subagents(子代理)是指主 AI 智能体将部分任务分派给独立的子智能体来并行处理的能力。
|
||
|
||
你可以把它理解成 AI 的下属。当主 AI 遇到一个大任务时,它可以把独立的小任务分给几个子代理同时干,自己继续处理其他工作。
|
||
|
||
Subagents 的好处是:
|
||
|
||
- 并行处理多个独立任务,效率翻倍
|
||
- 主代理的上下文保持干净,不会被子任务的细节污染
|
||
- 每个子代理可以专注于自己的任务,结果更准确
|
||
|
||
|
||
|
||
在 Claude Code 中,你可以在请求后面加一句 "use subagents",就能启用这个能力。比如让几个子代理同时审查代码库的不同模块,速度会快很多。
|
||
|
||
不过子代理也有局限,每个子代理的上下文是独立的,它们之间无法直接共享信息,所以不适合有强依赖关系的任务。另外,多个子代理同时运行会消耗更多 Token,成本会相应增加。
|
||
|
||
|
||
|
||
### Agent Loop 智能体循环
|
||
|
||
Agent Loop 是 AI 智能体的核心工作机制,描述了智能体如何持续运行来完成任务。
|
||
|
||
一个典型的 Agent Loop 包括:
|
||
|
||
1. 感知:获取当前环境信息(读取文件、查看错误等)
|
||
2. 思考:分析情况,决定下一步行动
|
||
3. 行动:执行具体操作(写代码、运行命令等)
|
||
4. 观察:检查行动的结果
|
||
5. 循环:根据结果决定是否继续
|
||
|
||
这个循环会一直进行,直到任务完成或达到终止条件。理解 Agent Loop 能帮你更好地使用 Cursor Agent 等工具。
|
||
|
||
|
||
|
||
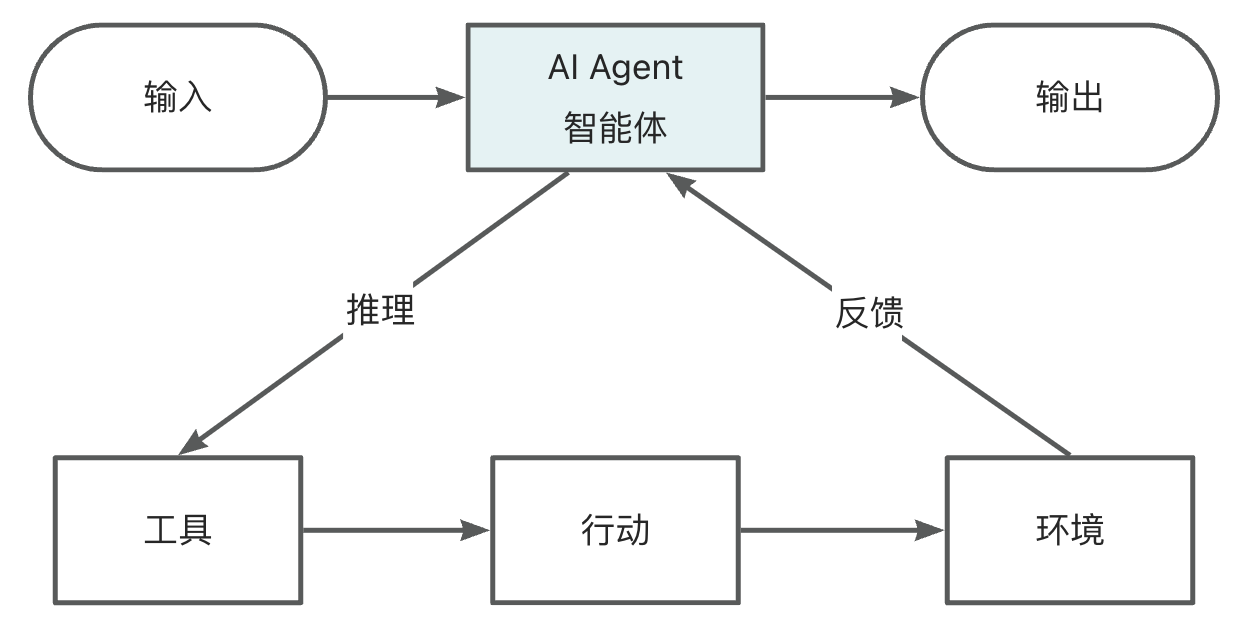
### ReAct 推理与行动
|
||
|
||
ReAct(Reasoning and Acting)是一种让 AI 智能体交替进行推理和行动的技术框架。
|
||
|
||
传统的 AI 要么只思考不行动,要么只行动不思考。ReAct 让 AI 能够:
|
||
|
||
- 先推理:思考当前情况,制定计划
|
||
- 再行动:执行具体操作
|
||
- 观察结果:看看行动效果如何
|
||
- 继续推理:根据结果调整策略
|
||
|
||
这种 “思考 - 行动 - 观察” 的循环让 AI 能更可靠地完成复杂任务,是现代 AI 编程工具的核心技术之一。
|
||
|
||
|
||
|
||
|
||
|
||
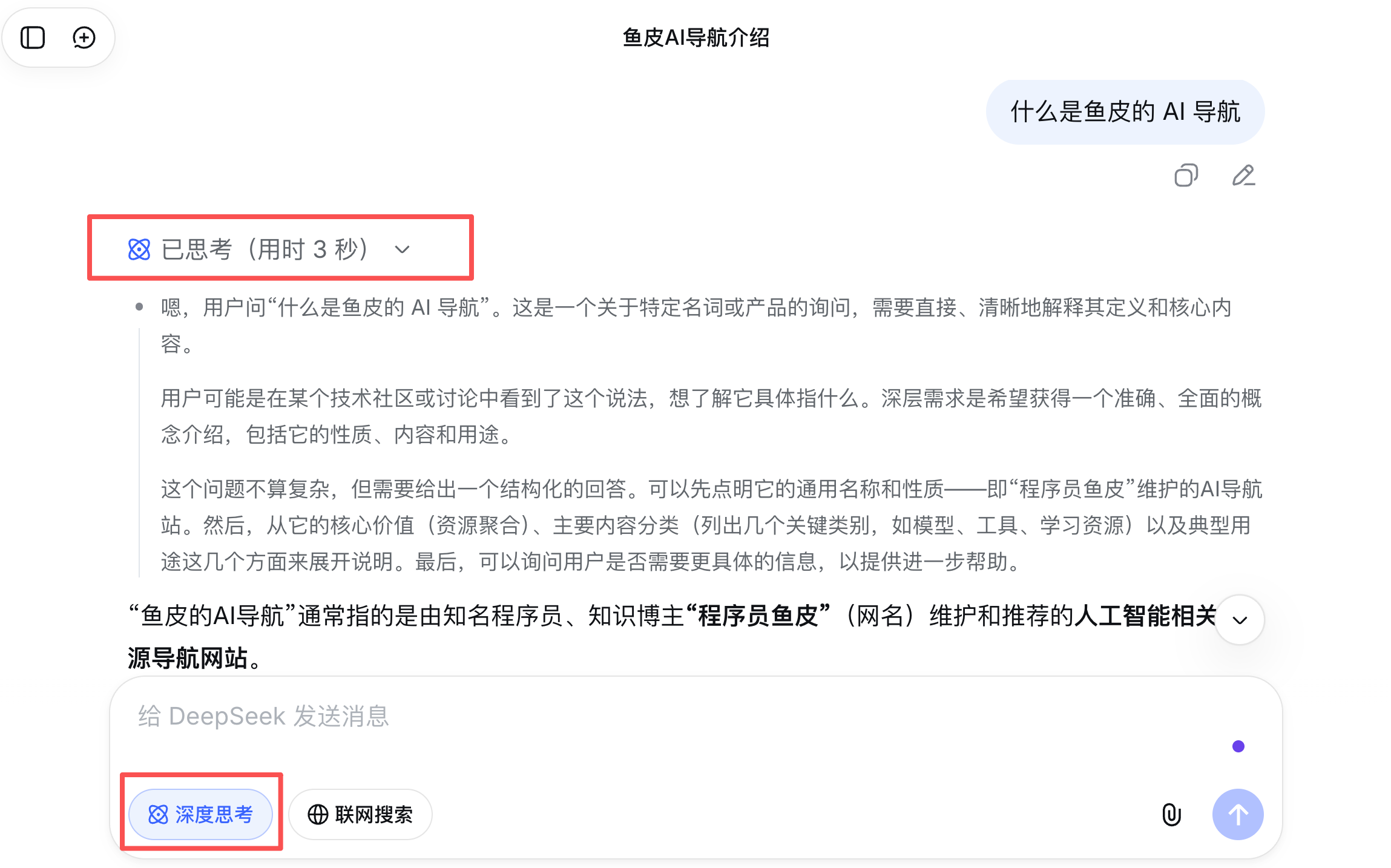
### 深度思考
|
||
|
||
深度思考(Deep Thinking)是让 AI 在回答之前先进行一段内部推理的能力,也叫 “扩展思考” 或 “思考模式”。
|
||
|
||
普通模式下,AI 收到问题后会直接生成回答。而开启深度思考后,AI 会先在内部进行一系列推理步骤,比如分析问题、考虑多种方案、评估利弊,然后才输出最终答案。你有时能在 AI 的回复中看到一个 “思考中...” 的过程,那就是深度思考在工作。
|
||
|
||
|
||
|
||
深度思考特别适合复杂的编程任务,比如设计系统架构、排查难以定位的 Bug、优化算法等。代价是速度更慢、Token 消耗更多。
|
||
|
||
目前主流模型都支持深度思考,并且你可以选择是否开启思考模式。
|
||
|
||
|
||
|
||
|
||
### 自适应思考
|
||
|
||
自适应思考(Adaptive Thinking)是深度思考的智能化版本,让 AI 自动判断当前问题需要多深的思考程度。
|
||
|
||
以前深度推理模式只能手动开关,开了的话简单问题也慢吞吞地想半天(浪费钱),关了的话复杂问题又容易出错。
|
||
|
||
AI 有了自适应思考能力后,可以做到简单问题秒回,复杂问题会自动进入深度思考模式。这样既保证了质量,又节省了时间和成本。
|
||
|
||

|
||
|
||
Anthropic 在 Claude Opus 4.6 中率先引入了自适应思考能力,开发者可以设置不同的思考力度级别来平衡质量和成本。
|
||
|
||
|
||
|
||
|
||
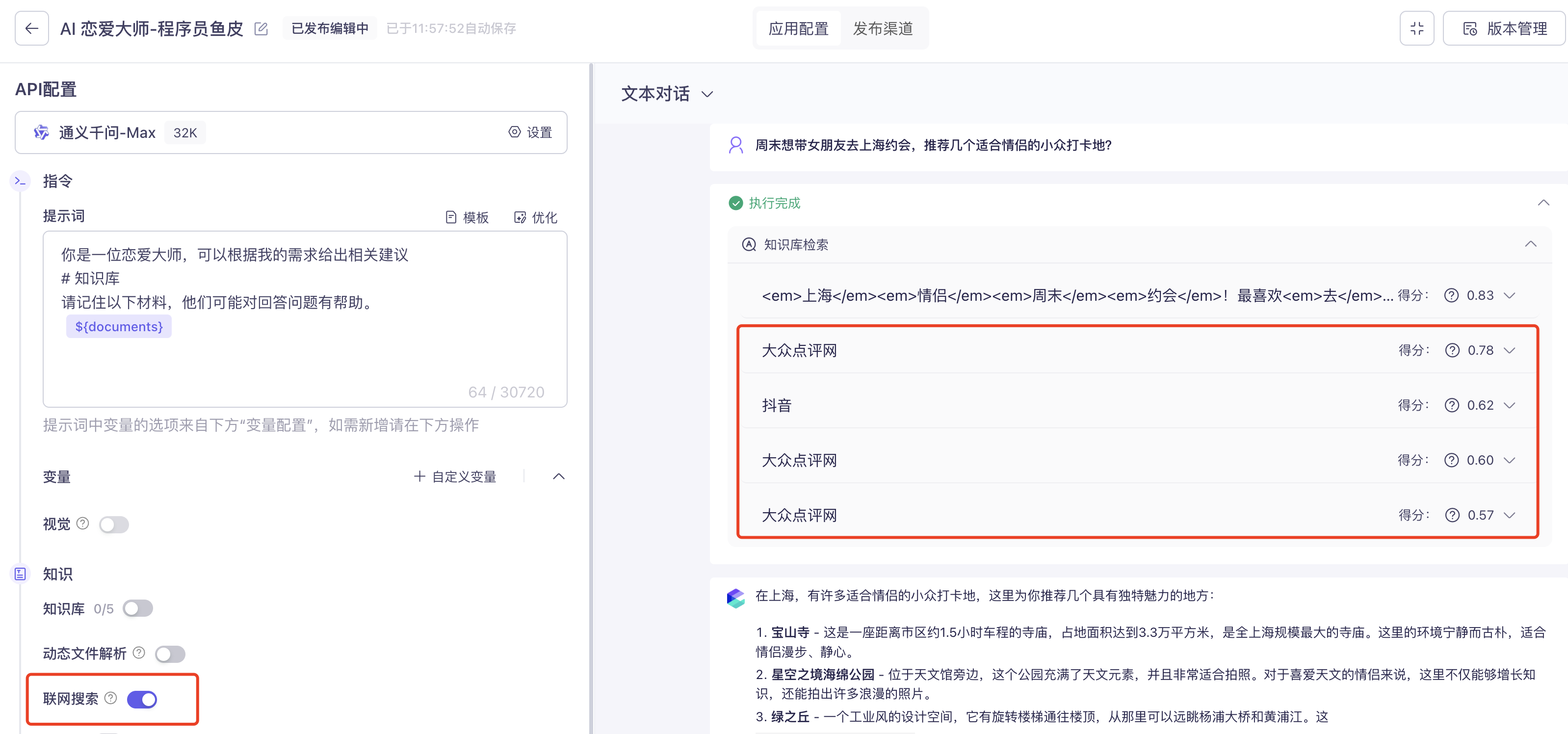
### 工具调用
|
||
|
||
工具调用(Tool Use / Function Calling)是让 AI 能够使用外部工具和功能的技术。AI 本身只能生成文字,但通过工具调用,它可以:
|
||
|
||
- 读写文件
|
||
- 执行命令行命令
|
||
- 搜索网页
|
||
- 调用 API
|
||
- 操作数据库
|
||
|
||
|
||
|
||
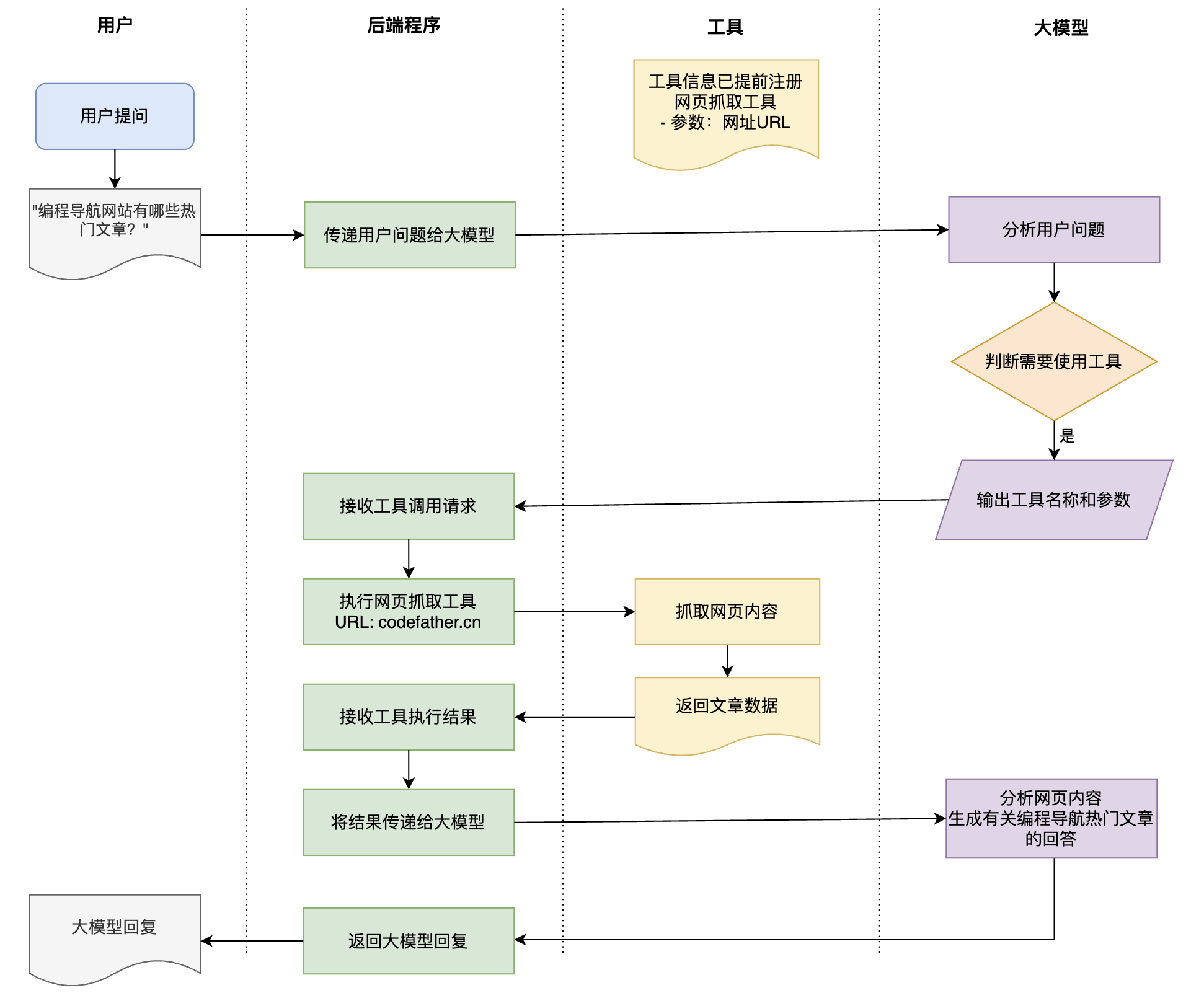
工具调用的工作流程分为 4 步:
|
||
|
||
1. 识别需求:AI 判断当前任务需要使用工具
|
||
2. 选择工具:从可用工具中选择合适的
|
||
3. 执行调用:用正确的参数调用工具
|
||
4. 整合结果:将工具返回的结果融入回答
|
||
|
||
|
||
|
||
需要注意的是,AI 模型本身并不直接执行工具,而是生成 “我想调用这个工具,参数是这些” 的指令,由外部程序执行后把结果返回给 AI。
|
||
|
||
在 Vibe Coding 中,工具调用让 AI 从 "只会说" 变成 "能动手"。比如 Cursor 的 Agent 模式就是通过工具调用来读取文件、修改代码、运行命令的。
|
||
|
||
|
||
|
||
### MCP 模型上下文协议
|
||
|
||
MCP(Model Context Protocol)是 Anthropic 在 2024 年底推出的开放标准,用于让 AI 模型安全地连接外部数据源和工具。
|
||
|
||
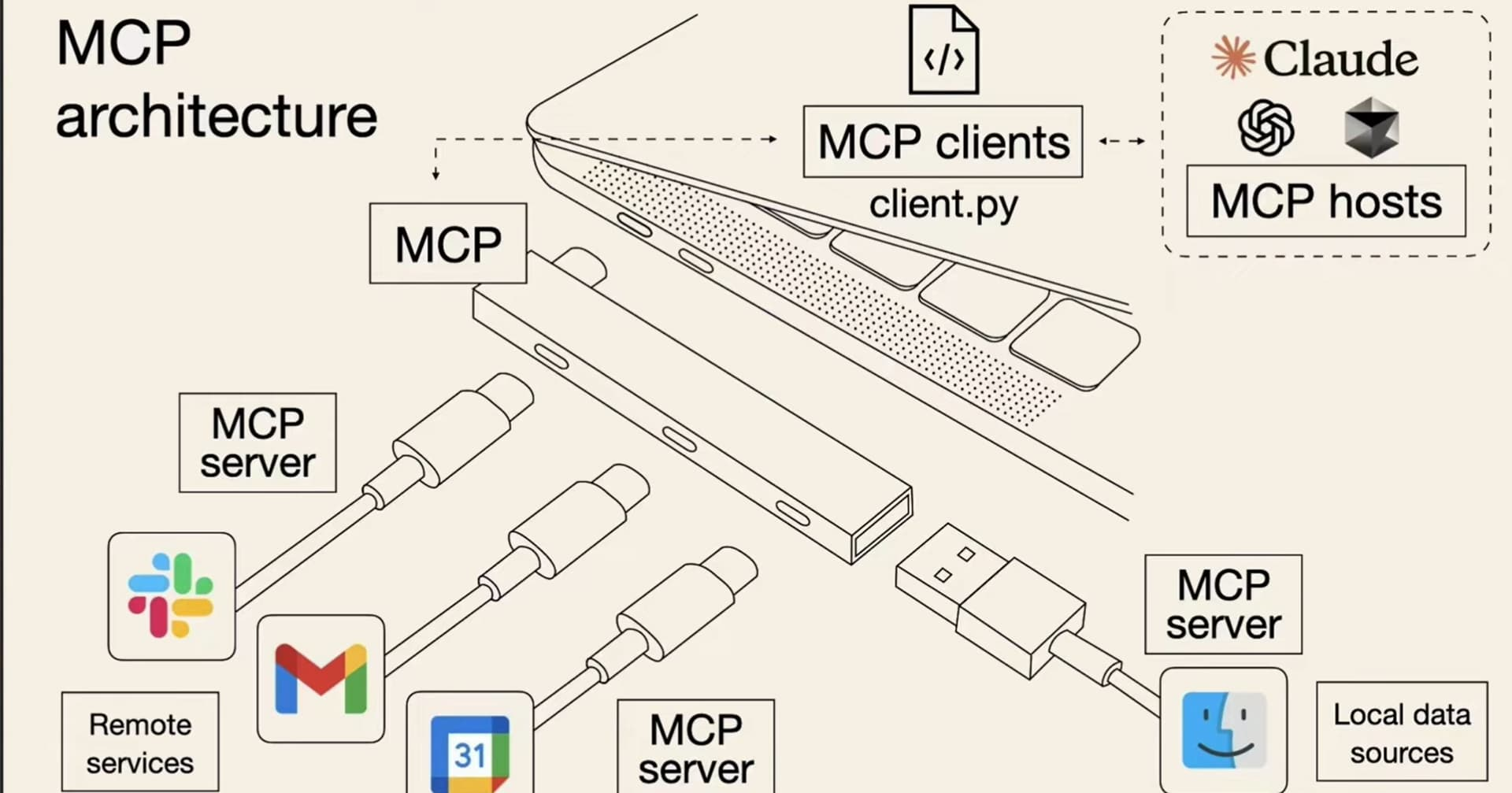
你可以把 MCP 理解成 AI 世界的 “USB 接口”。有了 MCP,AI 就能方便地读取你的文件、访问数据库、调用各种工具,而不需要每个工具都单独开发接口。
|
||
|
||
|
||
|
||
MCP 的核心价值在于 **标准化**。开发者不需要为每个 AI 工具单独开发连接器,只需要按照 MCP 标准开发一次,就能被所有支持 MCP 的 AI 工具使用。目前 Claude Code、Cursor、Windsurf 等主流 AI 编程工具,以及各种网页 AI Agent 应用都已经支持 MCP 协议。
|
||
|
||
|
||
|
||
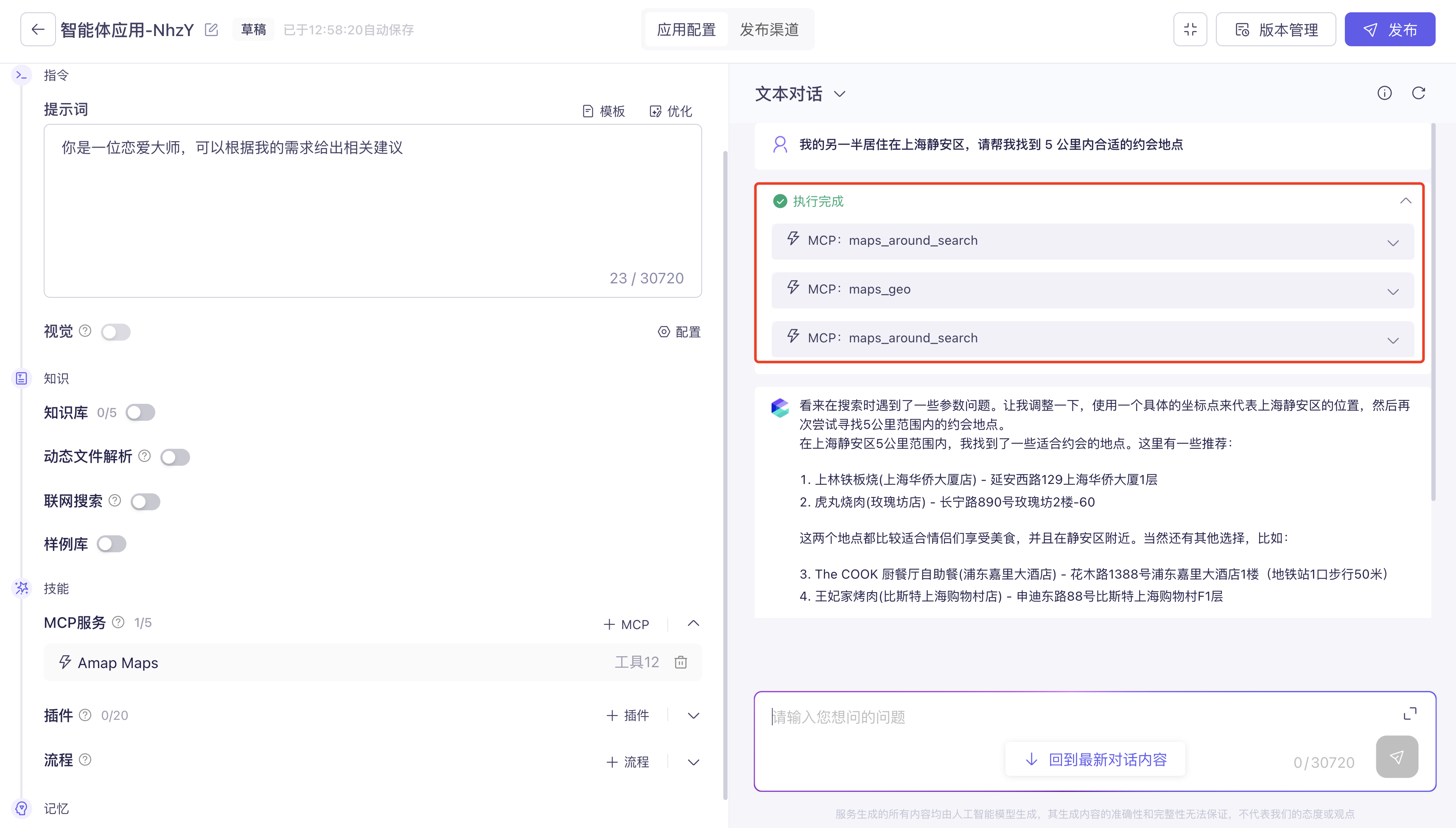
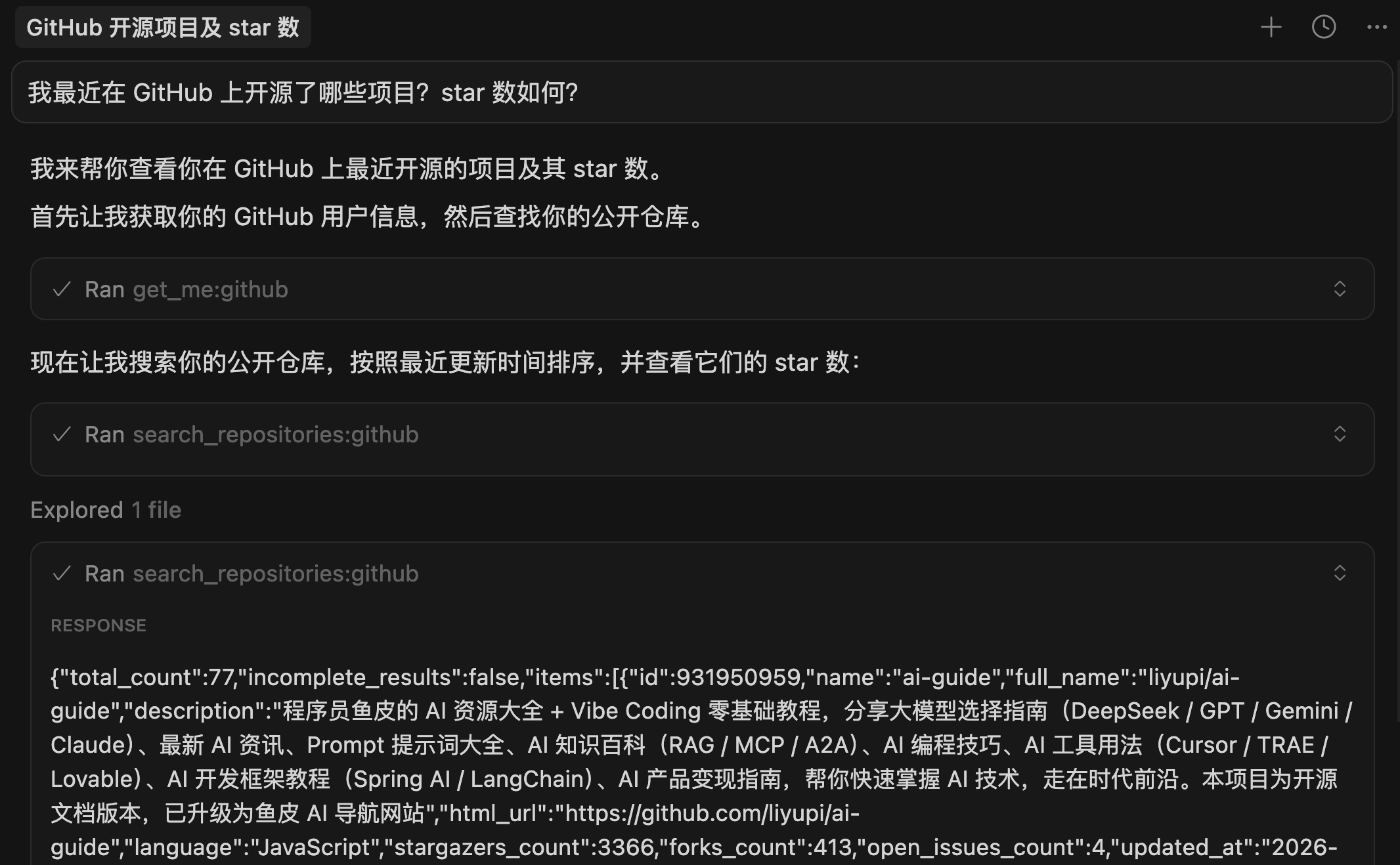
在 Vibe Coding 中,MCP 让 AI 能够连接更多外部工具和数据源,大大扩展了 AI 的能力边界。比如通过 Figma MCP,AI 可以直接读取设计稿并生成对应的网页代码;通过 GitHub MCP,AI 可以直接操作代码仓库、创建 PR;通过数据库 MCP,AI 可以查询和分析业务数据。
|
||
|
||
|
||
|
||
💡 想要发现更多好用的 MCP 服务?可以访问 [鱼皮 AI 导航 - MCP 大全](https://ai.codefather.cn/mcp),持续更新优质 MCP,帮你重塑 AI 工作流。
|
||
|
||
|
||
|
||
### Agent Skills 智能体技能
|
||
|
||
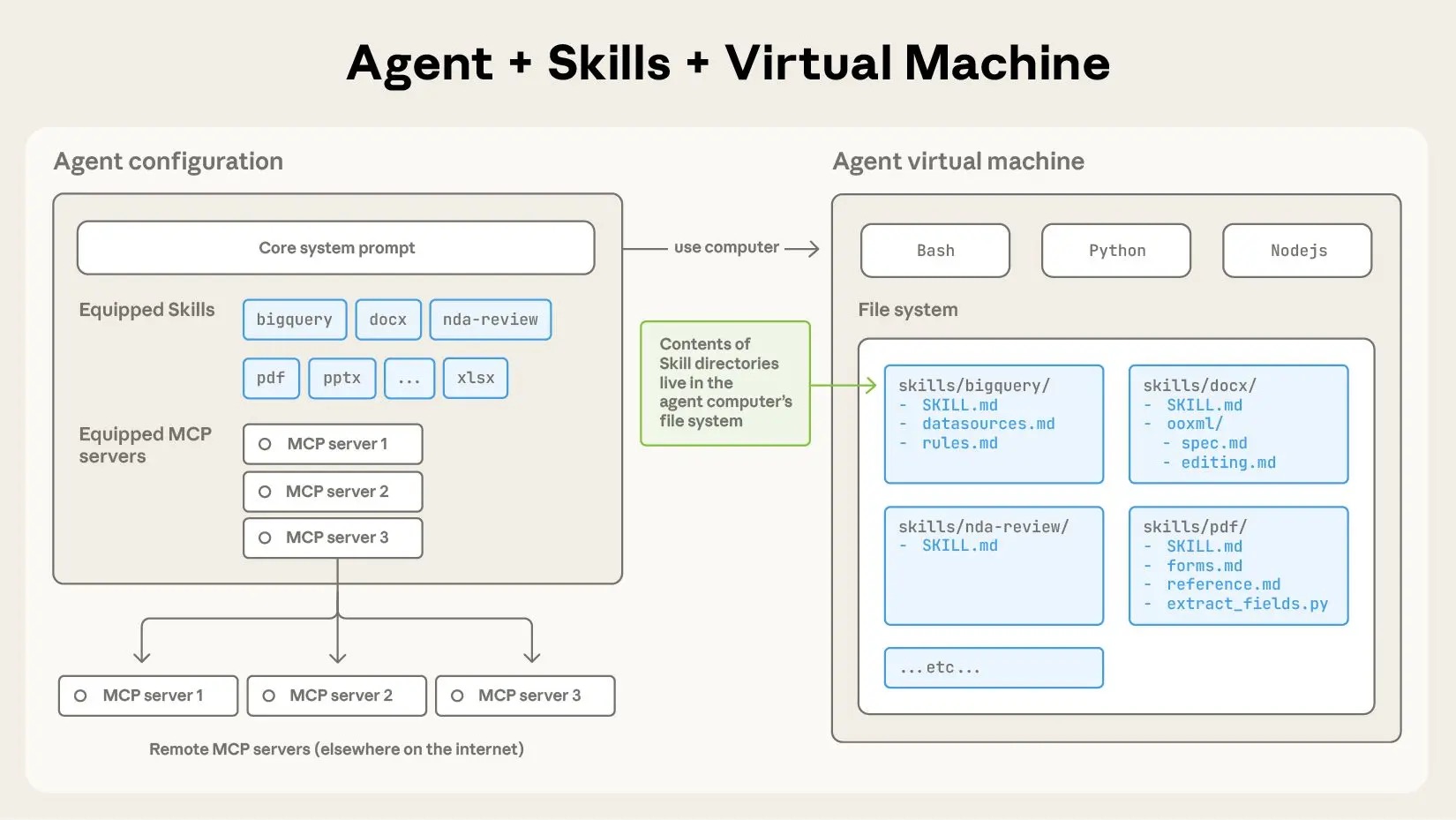
Agent Skills(智能体技能)是 Anthropic 在 2025 年 10 月推出的开放标准,用于给 AI 智能体扩展特定领域的专业能力。
|
||
|
||
简单来说,Skill 就是一个包含 `SKILL.md` 文件的文件夹,里面可以放置指令说明、脚本代码、参考资料等。当 AI 遇到相关任务时,会自动加载对应的 Skill 来增强自己的能力。
|
||
|
||
|
||
|
||
你可以把 Skill 理解成给 AI 的 “新员工入职指南”。比如:
|
||
|
||
- 一个 PDF 处理 Skill,教会 AI 如何填写 PDF 表单
|
||
- 一个项目部署 Skill,包含你团队特有的部署流程和脚本
|
||
- 一个代码审查 Skill,定义了你项目的代码规范和检查清单
|
||
|
||
Skills 的核心设计是 **渐进式披露**:AI 只在需要时才加载相关内容,不会一次性把所有信息都塞进上下文,既节省 Token 又保持灵活性。
|
||
|
||

|
||
|
||
💡 想要发现更多好用的 Agent Skills?可以访问 [鱼皮 AI 导航 - Skills 大全](https://ai.codefather.cn/skills),持续更新优质技能,释放 AI 执行潜力。
|
||
|
||
|
||
|
||
### Hooks 钩子
|
||
|
||
Hooks(钩子)是 AI 编程工具中的一种自动化机制,可以在特定事件发生时自动执行预设的操作。
|
||
|
||
你可以把 Hooks 理解成触发器:当 AI 完成某个动作(比如生成代码、提交代码、运行命令)时,Hook 会自动触发一段脚本或检查流程。
|
||
|
||
比如在 Claude Code 中,Hooks 可以用来:
|
||
|
||
- 代码生成后自动运行格式化工具
|
||
- 文件修改后自动执行测试
|
||
- 权限请求时自动判断是否安全并批准
|
||
- 提交代码前自动检查代码规范
|
||
|
||

|
||
|
||
Hooks 让你的 AI 工作流更加自动化,减少手动操作。不过要注意,Hooks 配置不当可能会阻塞 AI 的正常工作流程,建议先在小范围测试,确认没问题再推广到整个项目。
|
||
|
||
|
||
|
||
### 斜杠命令
|
||
|
||
斜杠命令(Slash Commands)是在 AI 编程工具的对话框中输入 `/` 触发的快捷指令,可以快速执行常用操作。
|
||
|
||
你可以把斜杠命令理解成操作 AI 的快捷键。Cursor、Claude Code 等主流 AI 编程工具都支持斜杠命令,比如在 Claude Code 中:
|
||
|
||
- `/help`:查看可用命令
|
||
- `/compact`:压缩当前对话的上下文
|
||
- `/config`:修改配置
|
||
- `/skills`:查看已安装的技能
|
||
|
||
|
||
|
||
更强大的是,你可以自定义斜杠命令,把常用的工作流封装起来复用。比如创建一个 `/commit-push-pr` 命令,一次性完成代码提交、推送和创建 PR;或者搞个 `/techdebt` 命令,每次会话结束跑一下清理重复代码。自定义命令还可以用 Git 管理,跨项目复用。
|
||
|
||
|
||
|
||
### A2A(Agent-to-Agent)
|
||
|
||
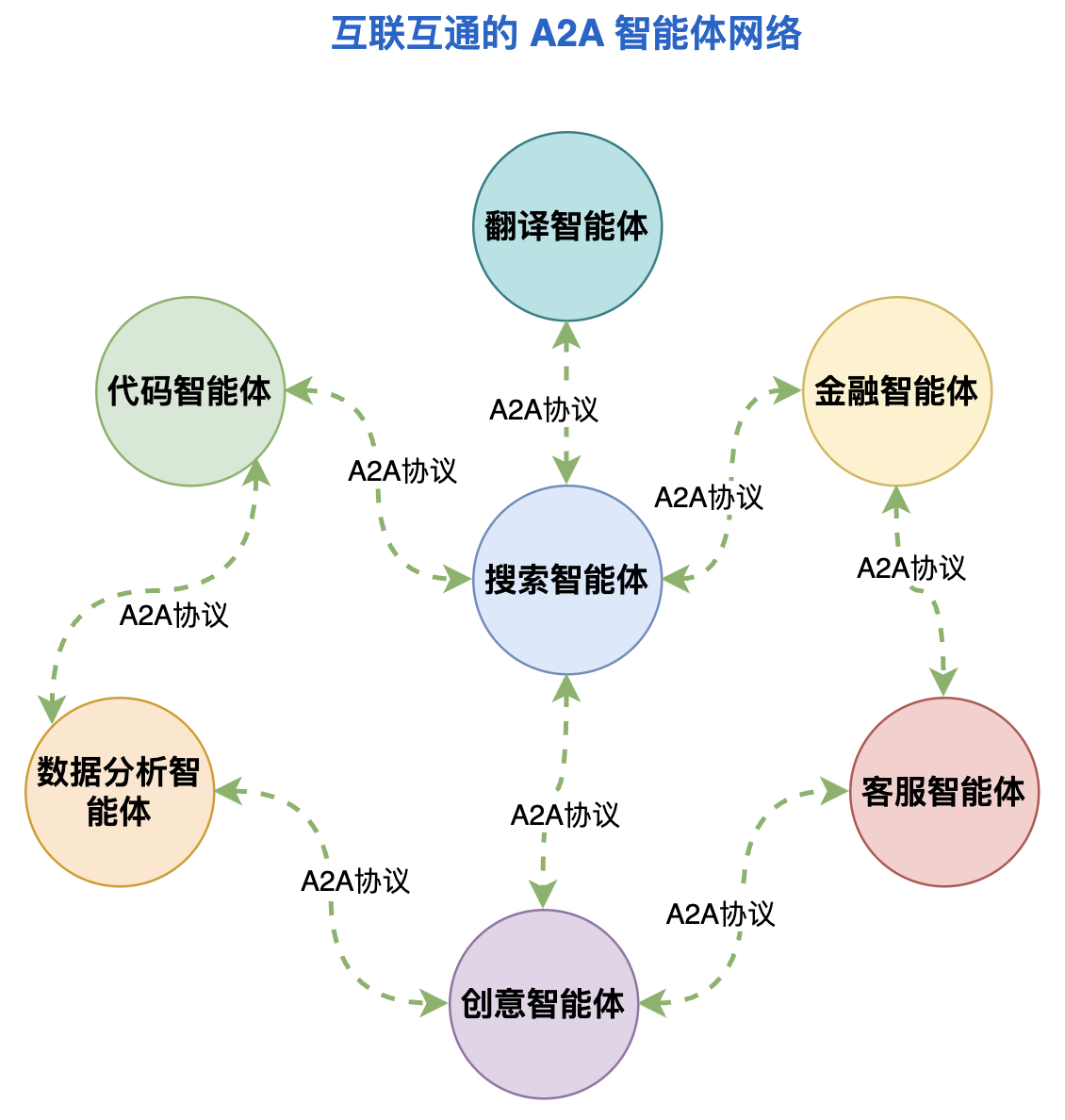
A2A(Agent-to-Agent)是指 AI 智能体之间相互通信和协作的协议或方式,是多智能体系统的基础技术。
|
||
|
||
就像人和人之间需要语言来沟通,AI 智能体之间也需要标准化的方式来交换信息、分配任务、汇报结果。
|
||
|
||
A2A 协议让不同的 AI 智能体能够组成团队,分工合作完成复杂任务。
|
||
|
||
|
||
|
||
|
||
|
||
### BMAD 敏捷 AI 开发方法
|
||
|
||
[BMAD-METHOD](https://github.com/bmad-code-org/BMAD-METHOD)(Breakthrough Method of Agile AI-Driven Development,突破性敏捷 AI 驱动开发方法)是一套系统化的 AI 智能体开发框架,旨在将原本混乱的 AI 编程过程变得结构化、可复用。
|
||
|
||
BMAD 使用 **角色化智能体** 的方式组织开发流程,每个智能体扮演特定角色:
|
||
|
||
- Analyst Agent(分析师):创建项目简报,包含市场分析和用户画像
|
||
- PM Agent(产品经理):将简报转化为详细的产品需求文档(PRD)
|
||
- Architect Agent(架构师):设计技术实现方案和系统架构
|
||
|
||
BMAD 中的智能体分为两种类型:
|
||
|
||
- Simple Agents(简单智能体):单文件、自包含,适合代码审查、文档生成等聚焦任务
|
||
- Expert Agents(专家智能体):具有跨会话持久记忆,配有专属文件夹存放资源,适合复杂的多步骤工作流
|
||
|
||
每个智能体都有标准化的组成部分:人设(角色、身份、沟通风格、原则)、能力列表、交互菜单,以及可选的关键行动。
|
||
|
||
BMAD 在 GitHub 上获得了几万+ Star,说明这种结构化的 AI 开发方法正在被越来越多的开发者认可。
|
||
|
||
|
||
|
||
|
||
|
||
|
||
### Browser Use 浏览器使用
|
||
|
||
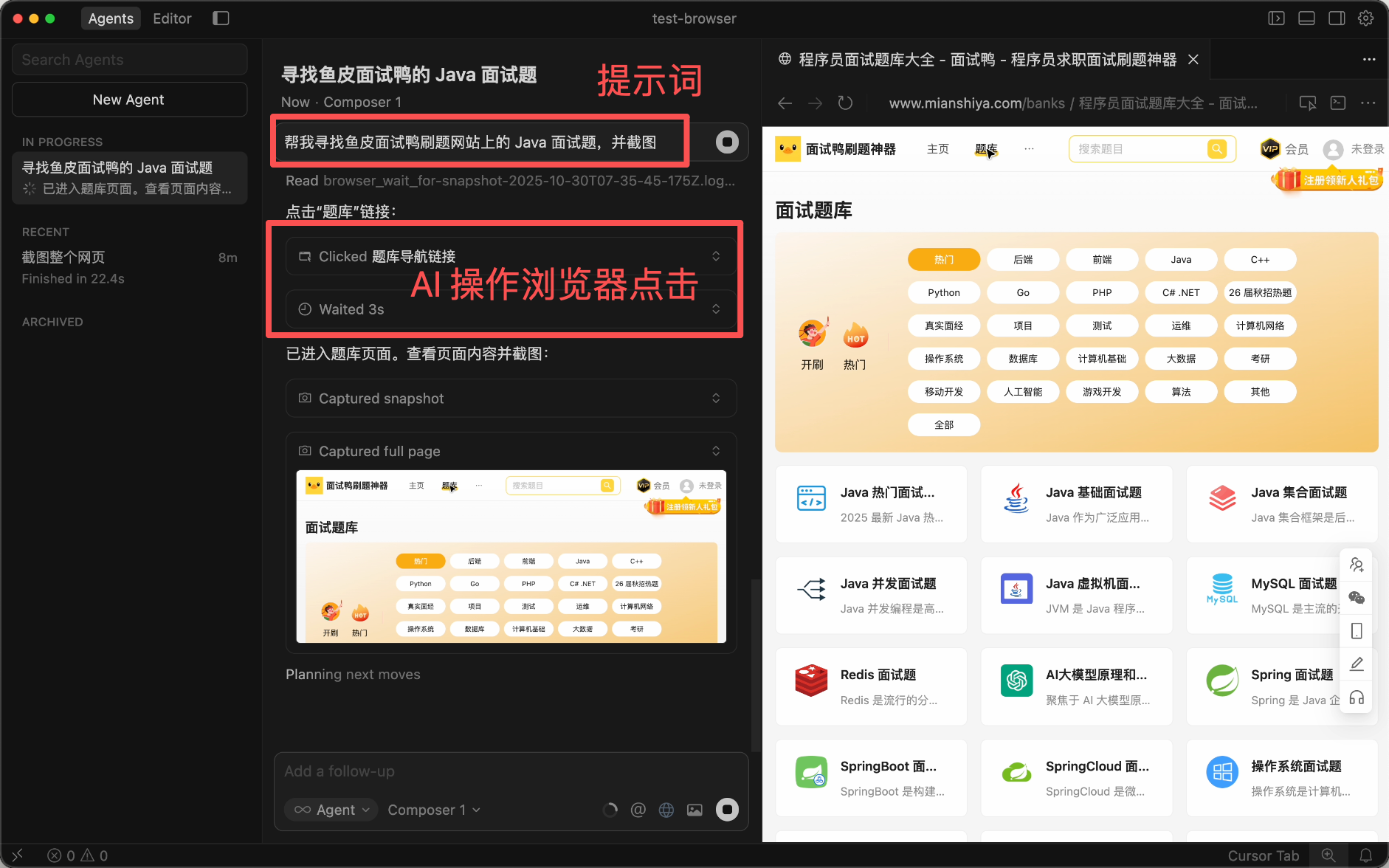
Browser Use(浏览器使用)是让 AI 智能体能够自动操控网页浏览器的技术能力。通过 Browser Use,AI 可以像人类一样浏览网页、点击按钮、填写表单、提取数据。
|
||
|
||
Browser Use 的典型应用场景:
|
||
|
||
- 自动化研究:让 AI 在多个网站上搜索、整理信息
|
||
- 数据采集:从网页中提取结构化数据
|
||
- 表单填写:自动完成繁琐的在线表单
|
||
- 跨平台操作:在不同网站间完成多步骤任务
|
||
|
||
比较知名的开源项目是 [Browser-Use](https://github.com/browser-use/browser-use),支持通过 Python 调用多种大模型来控制浏览器。此外,Cursor、Claude Code 等主流 AI 编程工具也内置了 Browser Use 能力,可以在开发过程中自动打开浏览器预览效果、执行测试等操作。
|
||
|
||
|
||
|
||
Browser Use 的一个关键优势是,AI 可以利用你现有的浏览器会话和登录状态,无需为每个网站单独开发 API 集成。也就是说,AI 能够访问那些没有公开 API 的网站,大大扩展了自动化的应用范围。
|
||
|
||
|
||
|
||
### Computer Use 计算机使用
|
||
|
||
Computer Use(计算机使用)是 Anthropic 公司在 2024 年推出的 AI 能力,让 Claude 能够像人类一样操作整个计算机桌面。
|
||
|
||
和 Browser Use 只能操作浏览器不同,Computer Use 可以操作任何桌面应用程序,比如:
|
||
|
||
- 查看屏幕截图,理解界面元素
|
||
- 移动鼠标光标,点击按钮
|
||
- 使用键盘输入文字
|
||
- 执行命令行操作
|
||
|
||
Computer Use 的工作原理是一个持续的反馈循环:
|
||
|
||
1. 截图分析:AI 捕获并分析当前屏幕
|
||
2. 决策规划:根据任务目标确定下一步操作
|
||
3. 执行操作:发送鼠标/键盘输入
|
||
4. 观察结果:检查操作效果,调整策略
|
||
|
||
💡 为了安全起见,Computer Use 通常在虚拟机或容器中运行,不会直接控制你的真实电脑。
|
||
|
||
Computer Use 代表了 AI 从 "只能生成文字" 到 "能够操作软件" 的重大跨越,彻底改变人机交互方式。
|
||
|
||
基于 Computer Use 技术,Anthropic 在 2026 年推出了 [Claude Cowork](https://claude.com/product/cowork),这是一个桌面端 AI 助手,可以直接访问你电脑上的文件和文件夹,帮你整理下载目录、从截图中提取数据到表格、准备品牌报告等日常办公任务。
|
||
|
||
|
||
|
||
|
||
|
||
|
||
## 上下文管理
|
||
|
||
|
||
### 上下文(Context)
|
||
|
||
上下文是 AI 在回答问题时能够参考的所有信息,包括:
|
||
|
||
- 当前对话的历史
|
||
- 你打开的代码文件
|
||
- 项目的结构和配置
|
||
- 你提供的参考资料
|
||
|
||
上下文越丰富、越相关,AI 生成的代码就越符合你的需求。这就像给一个新同事交接工作 —— 你给的背景信息越多,他上手就越快。
|
||
|
||
|
||
|
||
### 上下文工程
|
||
|
||
上下文工程(Context Engineering)是有策略地管理和优化提供给 AI 的上下文信息的技术。
|
||
|
||
核心目标是 **让 AI 拥有恰到好处的信息**。既不能太少(导致 AI 不了解情况),也不能太多(导致信息过载、成本上升)。
|
||
|
||
好的上下文工程包括:
|
||
|
||
- 选择最相关的文件
|
||
- 提供必要的背景说明
|
||
- 使用规则文件定义项目规范
|
||
- 适时清理无关的对话历史
|
||
|
||
|
||
|
||
### 上下文压缩
|
||
|
||
上下文压缩(Context Compaction)是 AI 自动压缩和总结之前对话内容的技术,解决的是长时间运行任务中上下文溢出的问题。
|
||
|
||
以前跑长任务的时候,AI 经常会撞到上下文长度的天花板,前面聊过的内容被挤掉后 AI 就失忆了,导致生成的代码和之前的约定对不上。有了上下文压缩,AI 会在上下文快要满的时候,自动把前面的对话总结成更精简的形式,保留关键信息的同时释放空间,这样就能持续工作更久而不会失忆。
|
||
|
||
你可以把它想象成项目经理写会议纪要。已经开了 3 小时的会,不可能把每句话都记下来,但关键决策、待办事项、重要结论都会被记录。AI 的上下文压缩也是类似的思路,把冗长的对话历史浓缩成关键信息。
|
||
|
||

|
||
|
||
Claude Opus 4.6 就内置了上下文压缩能力,搭配它的 100 万 token 上下文窗口,可以让长时间运行的编程任务更加稳定。
|
||
|
||
|
||
|
||
|
||
### 规则文件
|
||
|
||
规则文件(Rules File)是放在项目中的配置文件,用来告诉 AI 你的项目规范、技术栈、代码风格等信息。有了规则文件,AI 每次生成代码时都可以参考这些规则,生成的代码更符合你的项目风格,省去了反复强调的麻烦。
|
||
|
||
|
||
不同 AI 编程工具使用不同的规则文件格式:
|
||
|
||
- Cursor:早期使用 `.cursorrules` 单文件格式,现在推荐使用 `.cursor/rules/*.mdc` 多文件格式
|
||
- Claude Code:使用 `CLAUDE.md` 文件
|
||
- GitHub Copilot:使用 `.github/copilot-instructions.md` 文件
|
||
|
||
以 Cursor 为例,现代的 `.mdc` 规则文件支持 YAML 元数据,可以指定规则的适用范围:
|
||
|
||
```yaml
|
||
---
|
||
description: React 组件开发规范
|
||
globs: src/components/**/*.tsx
|
||
alwaysApply: false
|
||
---
|
||
# React 规范
|
||
- 使用函数式组件
|
||
- 优先使用 hooks
|
||
```
|
||
|
||
规则文件的激活方式有多种,比如:
|
||
|
||
- 始终生效:设置 `alwaysApply: true`
|
||
- 模式匹配:当引用匹配 `globs` 的文件时自动激活
|
||
- 手动调用:在对话中用 `@规则名` 引用
|
||
- AI 自主决定:AI 根据任务相关性自动加载
|
||
|
||
|
||
💡 注意,随着工具版本的更新,这些文件的名称和标准可能会发生改变,一切以工具官方文档为主。
|
||
|
||
|
||
|
||
### AGENTS.md
|
||
|
||
[AGENTS.md](https://agents.md/) 是一种开放的文件格式,专门用于给 AI 编程智能体提供项目指令。
|
||
|
||

|
||
|
||
传统的 README.md 是写给人看的,主要介绍项目是什么、怎么用。而 AGENTS.md 是写给 AI 看的,包含 AI 工作时需要的技术细节:
|
||
|
||
- 项目的构建和启动命令
|
||
- 测试运行方式
|
||
- 代码风格和规范
|
||
- 项目结构说明
|
||
|
||
一个典型的 AGENTS.md 文件大概长这样:
|
||
|
||
```markdown
|
||
# 项目设置
|
||
- 安装依赖:npm install
|
||
- 启动开发:npm run dev
|
||
- 运行测试:npm test
|
||
|
||
# 代码规范
|
||
- 使用 TypeScript 严格模式
|
||
- 组件文件使用 PascalCase 命名
|
||
- 工具函数使用 camelCase 命名
|
||
```
|
||
|
||
AGENTS.md 的优势在于它是一个开放标准,被数万个开源项目采用。当你使用支持该标准的 AI 编程工具(如 Claude Code、OpenAI Codex、Cursor、GitHub Copilot 等)时,AI 会自动识别项目根目录下的 AGENTS.md 文件,并将其中的指令发送给 AI,无需你手动引用。
|
||
|
||
|
||
|
||
### SDD 规范驱动开发
|
||
|
||
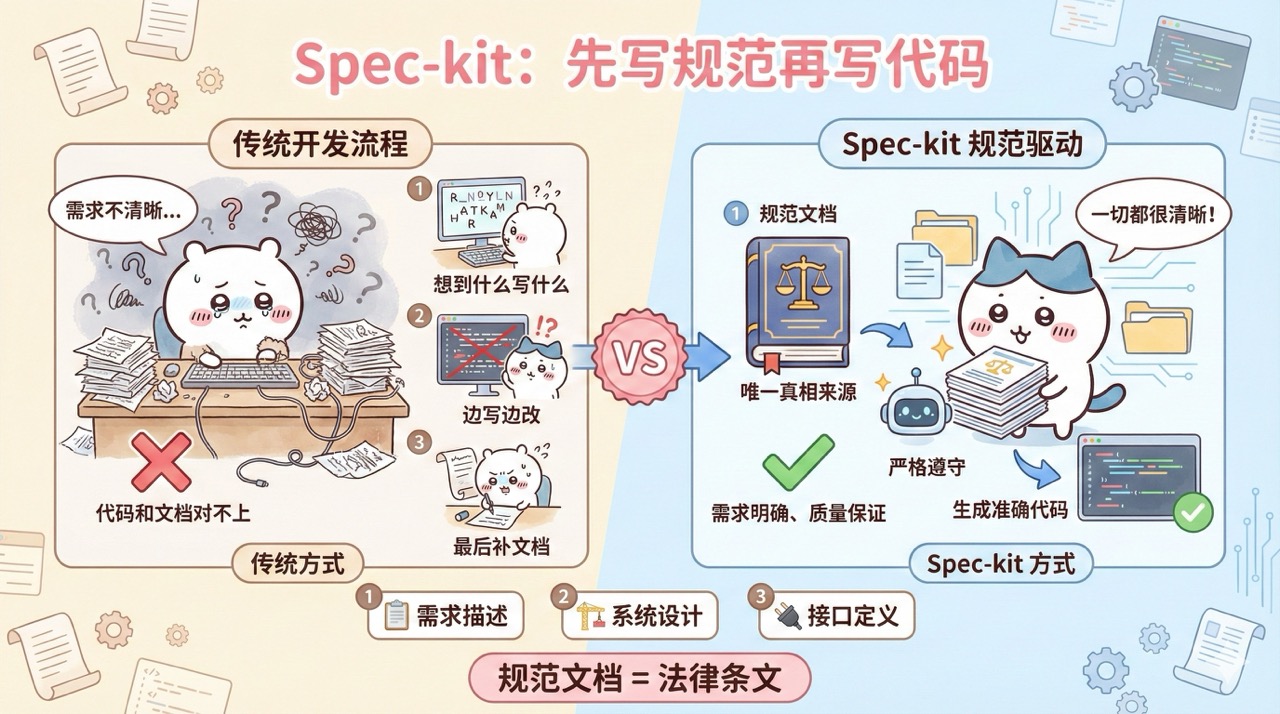
SDD(Spec-Driven Development,规范驱动开发)是 AI 时代的一种新型开发方法论,强调在编码之前先创建精确、机器可读的规范文档。
|
||
|
||
传统开发流程是:想到什么写什么,边写边改,最后再补文档。这样容易导致需求不清晰、代码和文档对不上。
|
||
|
||
而 SDD 的思路正好相反:**先把需求写成规范文档,并且把规范文档当作代码的唯一真相来源**。
|
||
|
||
你可以把规范文档理解为 “项目宪法”,它包含了详细的需求描述、系统设计和接口定义。AI 必须严格遵守这些条文来生成代码,确保产出完全符合预期。
|
||
|
||
|
||
|
||
为什么 SDD 越来越受重视?
|
||
|
||
因为 AI 生成代码的质量直接取决于上下文的清晰度,而不仅仅是依靠提示词技巧。一个清晰的规范文档能比任何 Prompt 黑魔法更有效地减少错误。
|
||
|
||
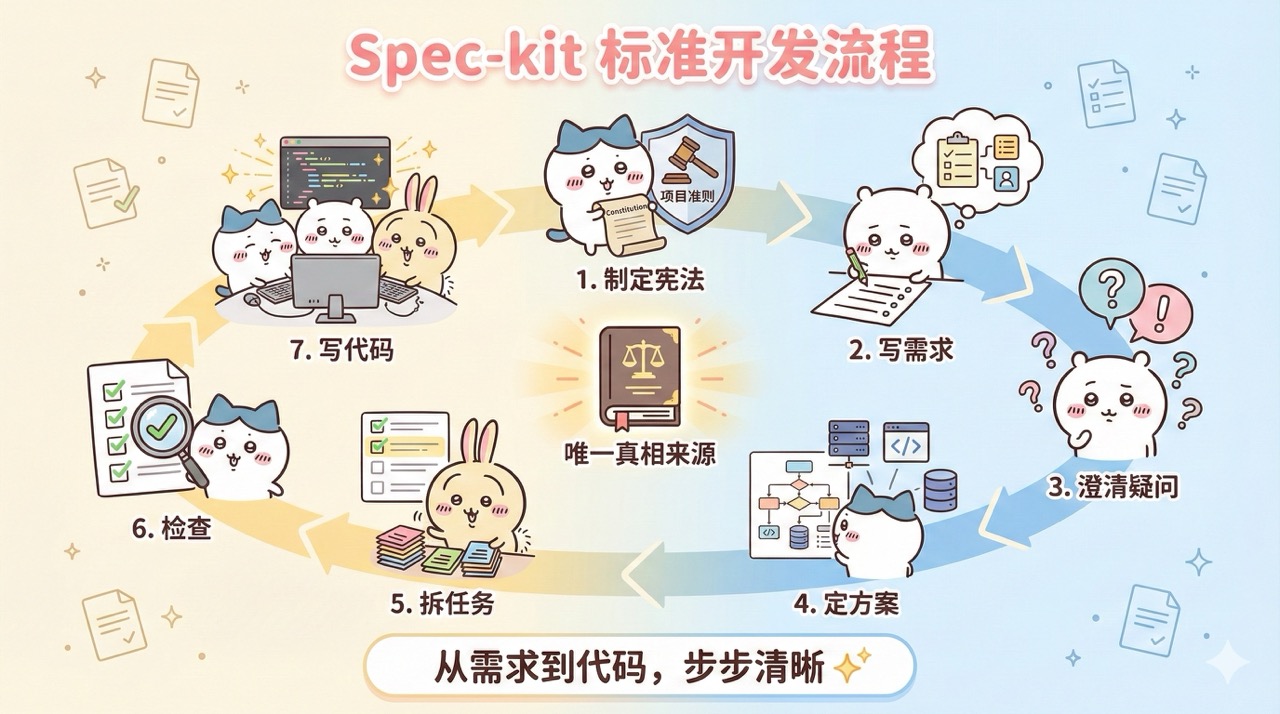
SDD 的典型工作流程:
|
||
|
||
1. Constitution(制定准则):定义项目的基本原则、代码规范、性能标准
|
||
2. Specify(编写规范):描述要做什么功能、为什么做、用户需求是什么
|
||
3. Clarify(澄清疑问):让 AI 提出结构化问题,明确边界情况和错误处理
|
||
4. Plan(制定方案):确定技术栈、系统架构、数据模型、API 接口
|
||
5. Tasks(拆解任务):把计划拆解成可执行的任务列表,标注依赖关系和优先级
|
||
6. Implement(执行实现):AI 按照任务列表生成代码,人类验证
|
||
|
||
|
||
|
||
2025 年 9 月,GitHub 发布了开源的 [Spec Kit](https://github.com/github/spec-kit) 工具包,帮助开发者在 AI 编程中实践 SDD 方法论。它支持 Claude Code、GitHub Copilot 等主流编程工具,通过一套斜杠命令引导你完成上述流程。
|
||
|
||
|
||
|
||
|
||
|
||
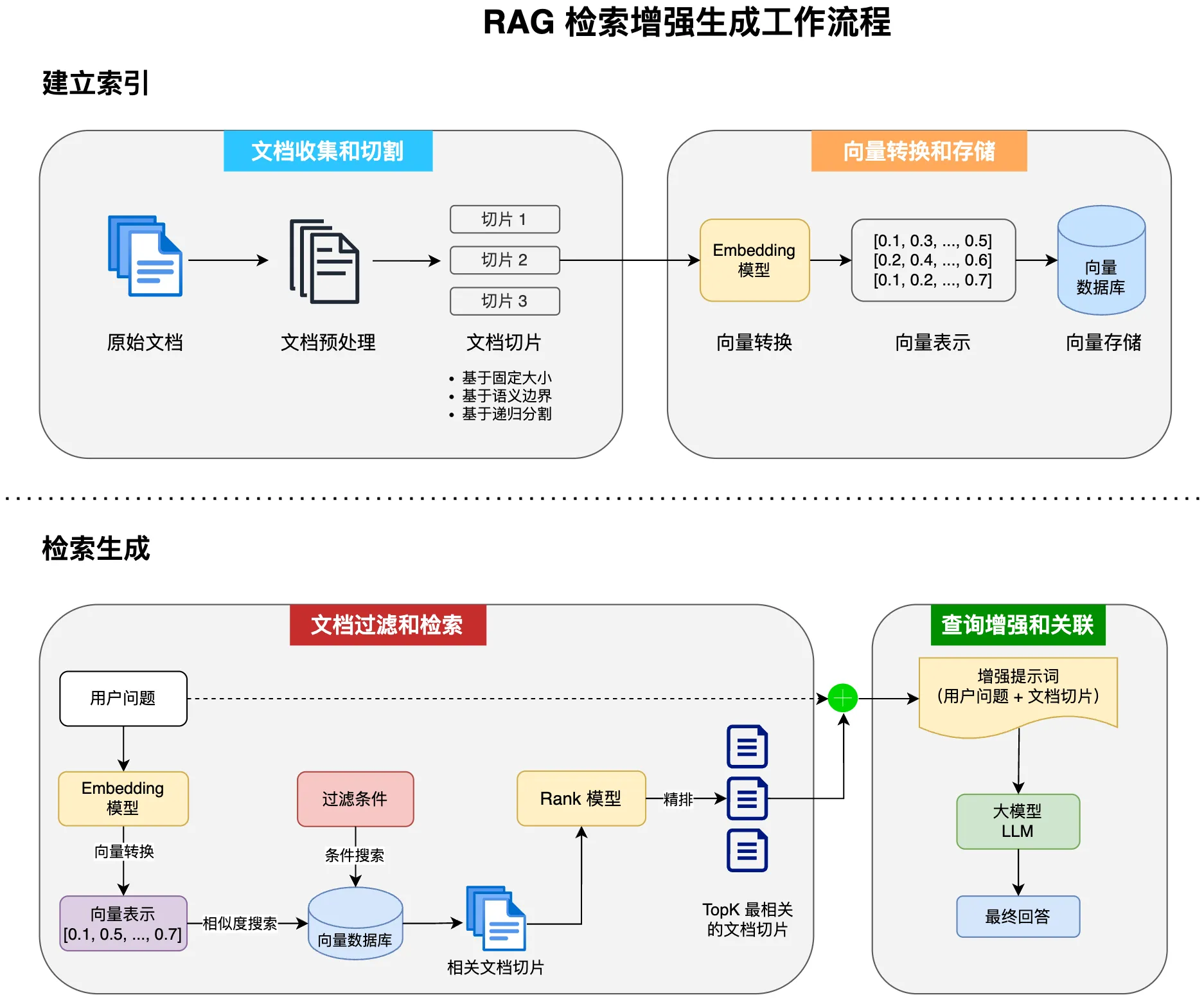
### RAG 检索增强生成
|
||
|
||
RAG(Retrieval-Augmented Generation)是一种让 AI 能够查阅外部知识库的技术。
|
||
|
||
普通的 AI 只能依赖训练时学到的知识,而 RAG 能让 AI 在回答问题时,先从你的文档、代码库、知识库中检索相关信息,然后基于这些信息生成回答。
|
||
|
||
这对于 Vibe Coding 特别有用,因为 AI 可以参考你项目中的已有代码,生成风格一致的新代码。
|
||
|
||
|
||
|
||
|
||
|
||
|
||
### 向量数据库
|
||
|
||
向量数据库是专门用来存储和查询 “向量”(一种数字表示形式)的数据库。在 AI 领域,它常用来存储文本的语义表示。
|
||
|
||
当你把代码或文档存入向量数据库后,AI 就能快速找到语义相似的内容,即使搜索词和原文不完全一样。
|
||
|
||
比如,你搜 “用户登录”,它能找到叫 "handleAuth" 的函数,因为它们在语义上是相关的。
|
||
|
||

|
||
|
||
|
||
|
||
|
||
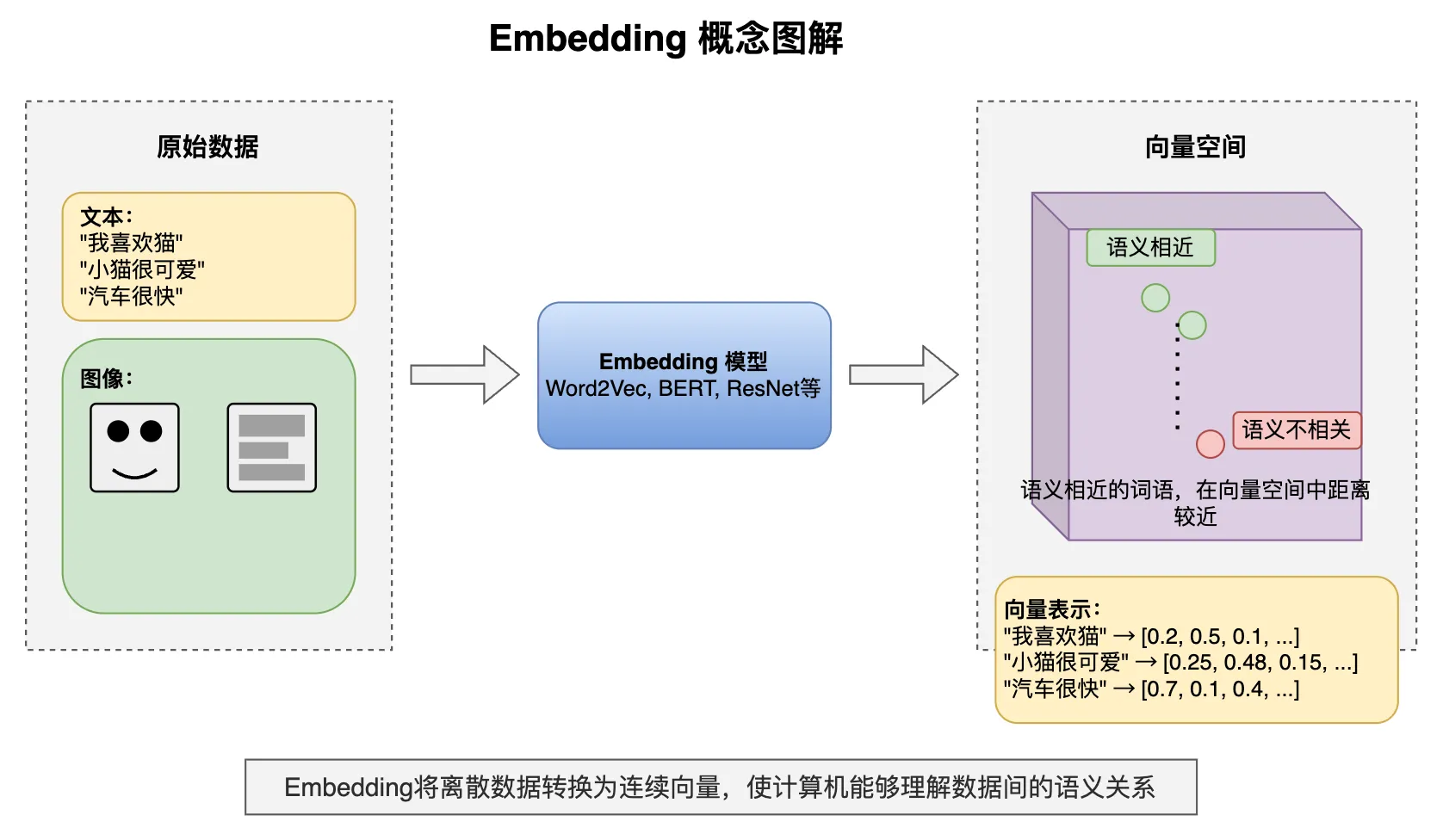
### 嵌入 Embedding
|
||
|
||
嵌入是把文本、代码等内容转换成数字向量的过程。这些向量能够捕捉内容的语义信息。
|
||
|
||
在向量空间中,语义相似的内容会靠得更近。这就是为什么向量数据库能进行语义搜索的原理。
|
||
|
||
你不需要深入理解嵌入的技术细节,只需要知道它是 RAG 和代码语义搜索的基础技术。
|
||
|
||
|
||
|
||
|
||
|
||
|
||
## AI 输出相关
|
||
|
||
|
||
### AI 幻觉
|
||
|
||
AI 幻觉(Hallucination)是指 AI 编造了不存在的内容,比如虚构的 API、错误的函数用法、不存在的库。
|
||
|
||
这是大语言模型的固有问题,因为它们是基于概率生成内容的,有时会 “脑补” 不存在的东西。
|
||
|
||
遇到幻觉时的应对方法:
|
||
|
||
- 要求 AI 提供文档链接验证
|
||
- 自己查官方文档确认
|
||
- 换个模型试试
|
||
- 开新对话重新描述问题
|
||
|
||
|
||
|
||
|
||
### 温度
|
||
|
||
温度(Temperature)是控制 AI 输出随机性的参数,取值通常在 0-2 之间。
|
||
|
||
- 温度低(如 0.1):输出更确定、更保守,适合写代码
|
||
- 温度高(如 1.0):输出更随机、更有创意,适合头脑风暴
|
||
|
||
在编程场景中,通常使用较低的温度,让 AI 生成更稳定、更可预测的代码。
|
||
|
||
|
||
|
||
### 流式输出
|
||
|
||
流式输出(Streaming)是指 AI 一边生成内容,一边实时显示给你,而不是等全部生成完再显示。
|
||
|
||
这就像看直播而不是看录播,你能实时看到 AI 的思考过程,如果发现方向不对,可以及时中断。
|
||
|
||
大多数 AI 编程工具都支持流式输出,让交互体验更流畅。
|
||
|
||
|
||
|
||
## 开发工具概念
|
||
|
||
|
||
### IDE 集成开发环境
|
||
|
||
IDE(Integrated Development Environment)是程序员用来写代码的综合软件,通常包含代码编辑器、调试器、终端等工具。
|
||
|
||
VS Code 是目前最流行的 IDE。Cursor 和 Windsurf 都是基于 VS Code 开发的 AI 代码编辑器,继承了 VS Code 的功能,同时增加了 AI 能力。
|
||
|
||
|
||
|
||
|
||
|
||
|
||
### 代码编辑器
|
||
|
||
代码编辑器是用来编写和修改代码的工具。它通常提供语法高亮、代码补全、错误提示等功能,帮助你更高效地写代码。
|
||
|
||
常见的代码编辑器有 Sublime Text 等。区别于 IDE 的区别,它们相对轻量、启动快速,适合快速编辑单个文件;而 IDE 的功能更全面,集成了调试器、终端、版本控制等工具,适合大型项目开发。
|
||
|
||
在 Vibe Coding 时代,代码编辑器集成了 AI 能力,可以根据你的提示词自动生成代码、解释代码、修复错误。比如 Cursor 虽然功能强大像 IDE,但它的核心还是一个 AI 增强的代码编辑器。
|
||
|
||
|
||
|
||
|
||
### 零代码平台
|
||
|
||
零代码平台(No-Code Platform)是不需要写代码就能创建应用的平台。你通过可视化界面拖拽组件、配置参数来构建应用。
|
||
|
||
在 AI 时代,像 Bolt.new、Lovable、v0.dev、百度秒哒这样的平台结合了零代码和 AI,你用自然语言描述需求,平台自动生成完整的应用。
|
||
|
||
零代码平台特别适合完全没有编程经验的新手,或者想快速做原型的场景。
|
||
|
||

|
||
|
||
|
||
|
||
|
||
### 代码补全
|
||
|
||
代码补全(Code Completion)是 AI 预测你接下来要写什么代码,并自动提供建议的功能。
|
||
|
||
当你写代码时,AI 会根据上下文推测你的意图,提供代码片段供你选择。按下 Tab 键就能接受建议,大大提高编码速度。
|
||
|
||
GitHub Copilot 是目前最知名的 AI 代码补全工具。
|
||
|
||
|
||
|
||
### 代码审查
|
||
|
||
代码审查(Code Review)是检查代码质量、发现问题、提出改进建议的过程。
|
||
|
||
在传统开发中,一般会由同事或上级来做。在 Vibe Coding 中,你可以让 AI 帮你审查代码,它会指出潜在的 bug、安全问题、性能问题,并提供修改建议。
|
||
|
||
|
||
|
||
但要注意,AI 的审查不能完全替代人工审查,特别是对于重要的生产代码。
|
||
|
||
|
||
|
||
|
||
### Linter 代码检查器
|
||
|
||
Linter 是自动检查代码问题的工具,能发现语法错误、风格问题、潜在 bug 等。
|
||
|
||
常见的 Linter 有 ESLint(JavaScript)、Pylint(Python)等,它们像一个严格的语法老师,帮你保持代码规范。
|
||
|
||
在 Vibe Coding 中,Linter 能帮你快速发现 AI 生成代码中的问题。
|
||
|
||
|
||
|
||
|
||
### 调试
|
||
|
||
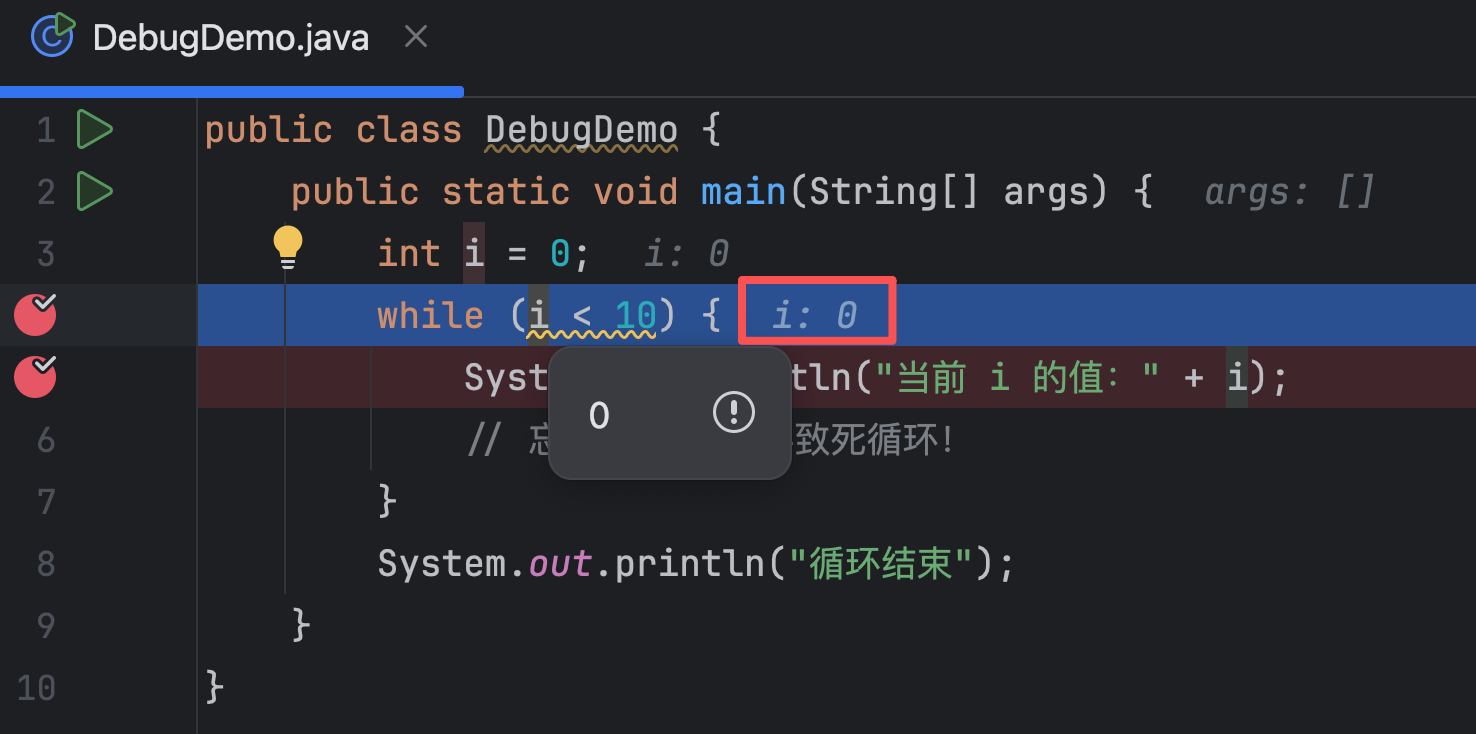
调试(Debug)是找到并修复代码中错误的过程。当代码运行结果不符合预期时,你需要调试来定位问题。
|
||
|
||
调试的常用方法包括:
|
||
|
||
- 设置断点,逐步执行代码
|
||
- 查看变量的值
|
||
- 阅读错误信息和堆栈跟踪
|
||
- 添加日志输出
|
||
|
||
|
||
|
||
在 Vibe Coding 中,你可以把错误信息发给 AI,让它帮你分析原因并提供修复方案。
|
||
|
||
|
||
|
||
## 项目管理概念
|
||
|
||
|
||
### MVP(最小可行产品)
|
||
|
||
MVP(Minimum Viable Product)是用最少的功能满足核心需求的产品版本。
|
||
|
||
做 MVP 的好处是:
|
||
|
||
- 快速验证想法是否可行
|
||
- 避免在不必要的功能上浪费时间
|
||
- 更快获得用户反馈
|
||
|
||
比如做记账应用,MVP 版本可能只有记录支出、查看列表两个功能,其他高级功能以后再加。
|
||
|
||
|
||
|
||
### 迭代开发
|
||
|
||
迭代开发是把大项目分成多个小周期,每个周期完成一部分功能的开发方法。
|
||
|
||
每个迭代周期包括:计划 => 开发 => 测试 => 发布 => 反馈 => 改进。
|
||
|
||
这种方法特别适合 Vibe Coding,因为你可以让 AI 先实现核心功能,测试没问题后再逐步添加新功能。
|
||
|
||
|
||
|
||
### 重构
|
||
|
||
重构(Refactoring)是在不改变功能的前提下,改进代码结构和质量的过程。
|
||
|
||
重构的目的是让代码更清晰、更易维护、更高效。常见的重构包括:
|
||
|
||
- 提取重复代码为函数
|
||
- 改进变量和函数命名
|
||
- 简化复杂的逻辑
|
||
- 拆分过长的文件
|
||
|
||
在 Vibe Coding 中,你可以让 AI 帮你重构代码,但要小步进行,每次重构后都要测试。
|
||
|
||
|
||
|
||
### 技术债
|
||
|
||
技术债(Technical Debt)是为了快速完成功能而采用的临时方案,这些方案在未来需要花时间修复和改进。
|
||
|
||
就像信用卡欠款一样,虽然现在透支方便,但以后要还,还要加利息。
|
||
|
||
在 Vibe Coding 中,AI 生成的代码可能不是最优方案,积累太多技术债会让项目越来越难维护。定期重构是偿还技术债的方式,防止出现屎山代码。
|
||
|
||

|
||
|
||
|
||
|
||
### 版本控制
|
||
|
||
版本控制是记录代码变更历史的系统,让你能追踪每次修改、对比不同版本、回退到之前的状态。
|
||
|
||
Git 是最流行的版本控制工具,GitHub 是最流行的代码托管平台。
|
||
|
||
在 Vibe Coding 中,版本控制特别重要。因为 AI 可能会生成有问题的代码,有了版本控制,你随时可以回退到之前正常的版本。
|
||
|
||
|
||
|
||
|
||
|
||
|
||
### 部署
|
||
|
||
部署(Deployment)是把开发好的应用发布到服务器上,让用户能够访问使用的过程。
|
||
|
||
常用的部署平台:
|
||
|
||
- Vercel:适合前端和全栈应用
|
||
- Netlify:适合静态网站和前端应用
|
||
- Railway、Render:适合后端服务
|
||
|
||
很多零代码平台(如 Bolt.new)支持一键部署,点个按钮就能上线。
|
||
|
||
|
||
|
||
## 前后端概念
|
||
|
||
|
||
### 前端
|
||
|
||
前端(Frontend)是用户能直接看到和交互的部分,包括网页界面、按钮、表单、动画等。
|
||
|
||
前端技术栈通常包括:
|
||
|
||
- HTML:页面结构
|
||
- CSS:样式和布局
|
||
- JavaScript:交互逻辑
|
||
- React/Vue/Next.js:现代前端框架
|
||
|
||
在 Vibe Coding 中,前端是 AI 最擅长生成的部分,因为效果可以直接看到,方便验证和调整。
|
||
|
||
|
||
|
||
|
||
### 后端
|
||
|
||
后端(Backend)是用户看不到的部分,负责处理业务逻辑、数据存储、用户认证等。
|
||
|
||
后端技术栈通常包括:
|
||
|
||
- Node.js/Python/Java:编程语言
|
||
- Express/FastAPI/Spring:Web 框架
|
||
- MySQL/PostgreSQL/MongoDB:数据库
|
||
|
||
后端比前端更复杂,需要考虑安全性、性能、数据一致性等问题。AI 生成的后端代码需要更仔细地审查。
|
||
|
||
|
||
|
||
|
||
### 全栈
|
||
|
||
全栈(Full-stack)是指同时包含前端和后端的完整应用。全栈开发者是能同时处理前端和后端工作的程序员。
|
||
|
||
在 Vibe Coding 中,像 Bolt.new 这样的工具可以一次性生成全栈应用,前后端代码都帮你写好。
|
||
|
||
想进一步了解全栈程序员是什么、怎么成为全栈程序员?可以看鱼皮的这篇文章:[全栈程序员是什么?](https://www.bilibili.com/opus/534338036646820466)
|
||
|
||
|
||
|
||
|
||
### API
|
||
|
||
API(Application Programming Interface)是不同程序之间通信的接口。
|
||
|
||
你可以把 API 理解成餐厅的菜单。菜单告诉你有什么菜可以点,怎么点,点了之后会得到什么。你不需要知道厨房怎么做菜,只需要按菜单点餐。
|
||
|
||
在 Web 开发中,前端通过 API 和后端通信,获取数据或提交操作。
|
||
|
||

|
||
|
||
想进一步了解 API 接口和标准的 API 接口设计规范,可以观看 [鱼皮的 API 动画科普视频](https://www.bilibili.com/video/BV1WFBXBmExs)。
|
||
|
||
|
||
|
||
|
||
### 数据库
|
||
|
||
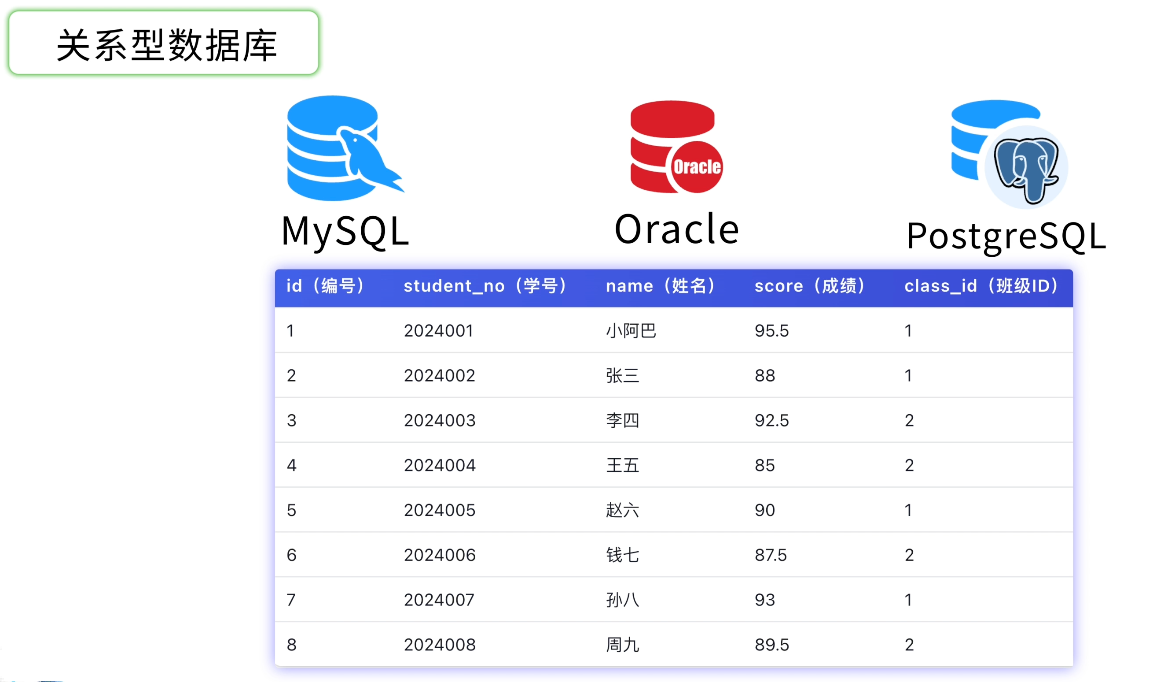
数据库是存储和管理数据的系统。应用中的用户信息、内容、设置等都存在数据库里。
|
||
|
||
常见的数据库类型:
|
||
|
||
- 关系型数据库(MySQL、PostgreSQL):数据以表格形式存储
|
||
- 文档数据库(MongoDB):数据以 JSON 文档形式存储
|
||
- 键值数据库(Redis):适合缓存和快速查找
|
||
|
||
|
||
|
||

|
||
|
||
在 Vibe Coding 中,你可以用 Supabase、Firebase 等 BaaS 服务,不用自己搭建和管理数据库。
|
||
|
||
如果你想系统学习数据库知识,可以看鱼皮的数据库入门教程:[数据库入门教程](https://www.bilibili.com/video/BV1iJSLBbEyD/)
|
||
|
||
|
||
|
||
|
||
### BaaS(后端即服务)
|
||
|
||
BaaS(Backend as a Service)是提供现成后端功能的云服务,包括数据库、用户认证、文件存储等。
|
||
|
||
常用的 BaaS 服务:
|
||
|
||
- Supabase:开源的 Firebase 替代品
|
||
- Firebase:Google 的 BaaS 平台
|
||
- PlanetScale:托管的 MySQL 服务
|
||
|
||
使用 BaaS,你不需要自己写后端代码和管理服务器,能大大加快开发速度。特别适合 Vibe Coding 场景。
|
||
|
||
|
||
|
||
## 写在最后
|
||
|
||
这篇文章涵盖了 Vibe Coding 中最常见的概念和术语。当然,AI 和编程领域的新概念还在不断涌现,这份词典也会持续更新。
|
||
|
||
你不需要一次记住所有概念,遇到不懂的词,回来查一查、或者问一问 AI 就好。随着你不断地实践 Vibe Coding,这些概念会自然而然地变得熟悉。
|
||
|
||
|
||
|
||
|
||
## 推荐资源
|
||
|
||
1)鱼皮 AI 导航网站:[AI 资源大全、最新 AI 资讯、免费 AI 教程](https://ai.codefather.cn)
|
||
|
||
2)编程导航学习圈:[学习路线、编程教程、实战项目、求职宝典、交流答疑](https://www.codefather.cn)
|
||
|
||
3)程序员面试八股文:[实习/校招/社招高频考点、企业真题解析](https://www.mianshiya.com)
|
||
|
||
4)程序员写简历神器:[专业模板、丰富例句、直通面试](https://www.laoyujianli.com)
|
||
|
||
5)1 对 1 模拟面试:[实习/校招/社招面试拿 Offer 必备](https://ai.mianshiya.com)
|