209 lines
16 KiB
Markdown
209 lines
16 KiB
Markdown
## DeepSeek-R1的训练流程强化学习(RL)阶段采用了GRPO算法
|
||
|
||
|
||
DeepSeek-R1的训练流程确实包含多个阶段,其中强化学习(RL)阶段采用了GRPO(Group Relative Policy Optimization)算法。具体流程如下:
|
||
|
||
1.**监督微调(SFT)阶段**
|
||
|
||
首先使用高质量标注数据对基础模型(如DeepSeek-V3)进行监督微调,提升模型在特定任务上的初步性能,为后续RL训练奠定基础。
|
||
|
||
2.**强化学习(RL)阶段**
|
||
|
||
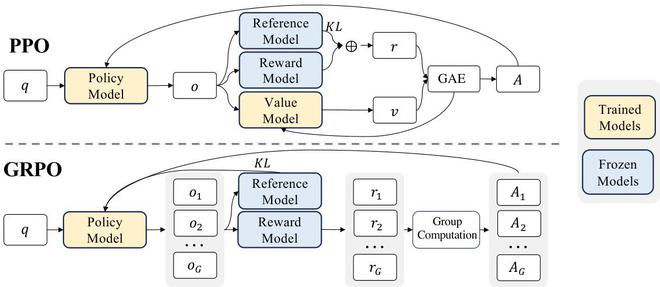
- **GRPO算法应用**:基于SFT后的模型,引入GRPO进行强化学习优化。GRPO的核心特点包括:
|
||
- **组内奖励归一化**:对每个输入提示生成多个输出(组采样),计算组内相对奖励作为优势值,无需依赖价值网络。
|
||
- **动态梯度正则化**:通过KL散度约束策略更新,确保训练稳定性。
|
||
|
||
|
||
|
||
|
||
|
||
- **多阶段RL迭代**:例如,在推理导向的RL中,模型专注于数学、编程等结构化任务,通过基于规则的奖励(如答案正确性、格式规范)优化决策过程;在通用对齐RL中,结合人类偏好奖励提升输出的安全性和实用性。
|
||
|
||
- **显著效果**:通过GRPO优化,模型在AIME 2024数学竞赛中的Pass@1得分从15.6%跃升至71.0%,代码生成任务的可运行率提升至85%。
|
||
|
||
3.**拒绝采样(RS)阶段**
|
||
|
||
生成合成数据集(如60万推理样本和20万通用任务样本),通过监督微调扩展模型的泛化能力,使其适应写作、角色扮演等开放域任务。
|
||
|
||
4.**最终强化学习阶段**
|
||
|
||
再次应用GRPO算法,结合更复杂的奖励模型(如基于结果的奖励和人类偏好模型),进一步优化模型的有用性、无害性和社会适应性。
|
||
|
||
**与其他方法的对比**
|
||
相比OpenAI的RLHF,GRPO的优势在于取消价值网络、降低内存占用(例如策略模型无需额外价值模型参数),并通过组内对比简化优势计算,显著提升训练效率和稳定性。此外,GRPO在多轮RL迭代中表现出更强的收敛性,例如在纯RL训练的R1-Zero阶段(未使用SFT),模型仍能通过GRPO自我进化推理能力。
|
||
|
||
综上,GRPO算法在DeepSeek-R1的多个RL阶段中发挥了核心作用,通过组相对策略优化、动态梯度约束等技术,实现了复杂推理任务的显著性能提升,同时兼顾训练效率和稳定性。
|
||
|
||
GRPO算法在强化学习中的具体实现和优化策略是什么?
|
||
|
||
GRPO(Group Relative Policy Optimization)算法是一种在强化学习中用于优化策略的新型方法,特别适用于大规模语言模型(LLM)的训练。以下是GRPO算法的具体实现和优化策略的详细说明:
|
||
|
||
1.**算法核心思想**
|
||
|
||
GRPO的核心思想是通过比较不同策略组(Group)的表现来优化策略,而不是依赖于传统的价值函数模型。这种方法避免了PPO(Proximal Policy Optimization)算法中常见的计算开销和策略更新不稳定的问题,显著提高了训练的稳定性和效率。
|
||
|
||
2.**具体实现步骤**
|
||
|
||
GRPO算法的实现可以分为以下几个关键步骤:
|
||
|
||
(1)**采样和奖励评分**
|
||
|
||
- **采样**:从当前策略模型生成多个候选输出(即多个策略组)。这些候选输出可以是不同的解码路径或生成结果。
|
||
- **奖励评分**:为每个候选输出分配一个奖励值,通常使用二进制奖励系统(如是否正确完成任务)。这种评分方式简单且有效。
|
||
|
||
(2)**组内相对奖励**
|
||
|
||
- GRPO通过计算同一组内不同候选输出的相对奖励值来优化策略。具体来说,它比较每个候选输出相对于其他候选输出的优势和劣势,并根据这些相对值调整策略参数。
|
||
|
||
(3)**策略更新**
|
||
|
||
- **更新规则**:GRPO采用相对优势方法,更新策略参数以增加选择更好候选输出的概率,同时减少选择较差候选输出的概率。更新公式如下:
|
||
|
||
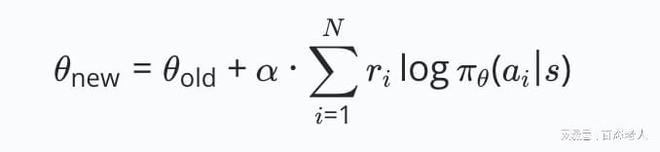
|
||
|
||
|
||
|
||
其中,ri
|
||
是第i个候选输出的相对奖励值,α是学习率,πθ(ai∣s)是在状态s下选择动作ai的概率。
|
||
|
||
(4)**动态梯度正则化**
|
||
|
||
- GRPO引入了动态梯度正则化机制,以避免模型在训练过程中出现过拟合或梯度爆炸问题。这种机制确保了训练过程的稳定性和高效性。
|
||
|
||
3.**优化策略**
|
||
|
||
GRPO算法通过以下优化策略进一步提升性能:
|
||
|
||
(1)**减少对价值网络的依赖**
|
||
|
||
- 与PPO等传统方法不同,GRPO不需要依赖价值网络来评估策略的好坏。这大大降低了计算开销和内存占用,使得算法更适合大规模模型的训练。
|
||
|
||
(2)**提高训练稳定性**
|
||
|
||
- GRPO通过组内相对奖励机制,减少了策略更新的方差,从而提高了训练过程的稳定性。这种方法避免了因策略更新剧烈变化而导致的训练不稳定问题。
|
||
|
||
(3)**降低计算成本**
|
||
|
||
- GRPO通过直接比较候选输出的相对奖励值,避免了复杂的评论模型和剪裁机制。这不仅简化了训练流程,还显著降低了计算成本。
|
||
|
||
(4)**适用于多任务学习和强化学习场景**
|
||
|
||
- GRPO不仅适用于单任务学习,还可以扩展到多任务学习或多智能体强化学习场景。通过组间比较,GRPO能够提升多样性并避免局部最优。
|
||
|
||
4.**实验结果**
|
||
|
||
在DeepSeek-R1模型中,GRPO算法表现出显著的优势。实验结果显示,GRPO在数学推理、代码生成等复杂任务中,能够有效提升模型的回答质量和训练效率。
|
||
|
||
5.**总结**
|
||
|
||
GRPO算法通过组内相对奖励机制和动态梯度正则化,显著优化了强化学习中的策略更新过程。它不仅减少了对价值网络的依赖,还提高了训练的稳定性和效率,特别适合大规模语言模型的训练。
|
||
|
||
DeepSeek-R1模型在使用GRPO算法后的性能提升具体表现在哪些方面?
|
||
|
||
DeepSeek-R1模型在使用GRPO算法后,性能提升主要体现在以下几个方面:
|
||
|
||
1. **计算效率和内存占用**:GRPO算法通过避免对价值网络的依赖,显著降低了计算和存储需求。这使得DeepSeek-R1模型在大规模语言模型的微调中表现更加高效,尤其是在数学推理和代码生成任务中。
|
||
2. **训练效率**:GRPO算法通过组内相对奖励机制优化策略模型,避免了传统PPO算法中复杂的样本采集和价值函数计算过程,从而提高了训练效率。例如,在数学推理任务中,DeepSeek-R1的训练速度提升了3倍。
|
||
3. **性能提升**:在具体任务中,DeepSeek-R1模型的性能得到了显著提升。例如,在AIME 2024推理基准测试中,DeepSeek-R1-Zero的Pass@1准确率从15.6%提升至71.0%,多数投票下进一步提升至86.7%,接近OpenAI的o1-0912水平。
|
||
4. **稳定性**:GRPO算法通过裁剪概率比,有效防止了策略更新过于剧烈,从而保持了训练过程的稳定性。
|
||
5. **代码可运行性和推理能力**:在代码生成任务中,DeepSeek-R1模型的代码可运行性显著提高,同时推理能力也得到了增强。
|
||
6. **多阶段训练方法**:DeepSeek-R1采用了多阶段混合训练策略,包括监督微调(SFT)、强化学习(RL)、拒绝采样(RS)和最终强化学习阶段。这种训练方法进一步提升了模型的性能和效率。
|
||
7. **长上下文处理能力**:DeepSeek-R1在长上下文基准测试中表现出色,胜率高达92.3%,远超DeepSeek-V3。
|
||
8. **推理路径优化**:GRPO算法通过规则奖励系统评估模型的推理路径,并指导模型改进,从而提高了推理的准确性和效率。
|
||
|
||
如何比较GRPO算法与其他强化学习算法(如PPO)在大语言模型训练中的效果和效率?
|
||
|
||
GRPO(Group Relative Policy Optimization)算法与传统的PPO(Proximal Policy Optimization)算法在大语言模型训练中的效果和效率方面存在显著差异。以下从多个角度进行详细比较:
|
||
|
||
1.**计算资源与内存需求**
|
||
|
||
- **PPO算法**:PPO算法需要维护一个与策略模型大小相当的价值网络(Value Model),用于估计优势函数。在处理大规模语言模型时,价值网络的训练和更新会消耗大量的计算资源和内存,尤其是在千亿或万亿参数的语言模型中,这种需求尤为突出。
|
||
- **GRPO算法**:GRPO算法通过组内相对奖励优化策略模型,避免了对价值网络的依赖,从而显著降低了计算和存储需求。这使得GRPO在大规模模型训练中更加高效。
|
||
|
||
2.**训练效率与稳定性**
|
||
|
||
- **PPO算法**:PPO算法在更新策略时可能会导致策略分布发生剧烈变化,这会增加训练的不稳定性,并可能导致训练效率低下。
|
||
- **GRPO算法**:GRPO通过组内相对奖励计算优势函数,并引入KL散度约束来控制策略更新幅度,从而提高了训练的稳定性和效率。此外,动态梯度正则化进一步解决了大规模数值模型训练中的稳定性问题。
|
||
|
||
3.**模型性能**
|
||
|
||
- **PPO算法**:PPO算法在大语言模型的微调中被广泛应用,但其性能受限于价值网络的计算负担和策略更新的不稳定性。
|
||
- **GRPO算法**:GRPO在数学推理和代码生成任务中表现出色,显著提升了模型的通过率和代码可运行性。此外,其训练效率也得到了显著提升。
|
||
|
||
4.**算法设计与实现**
|
||
|
||
- **PPO算法**:PPO算法的核心是通过截断的策略优化来平衡样本复杂性和计算效率。其目标函数包括累积奖励最大化、KL散度限制和价值函数误差平方和的最小化。
|
||
- **GRPO算法**:GRPO算法的核心是通过组内相对奖励计算优势函数,并引入动态梯度正则化和KL散度约束。其输入包括环境状态、观测值和一组观测值,输出为动作序列和策略模型的更新规则。
|
||
|
||
5.**应用场景**
|
||
|
||
- **PPO算法**:PPO算法适用于多种强化学习任务,包括模拟机器人操作、Atari游戏以及自然语言处理任务。其广泛应用于OpenAI的RLHF(Reinforcement Learning from Human Feedback)框架中。
|
||
- **GRPO算法**:GRPO算法特别适用于需要高效计算和高稳定性的场景,如数学推理、代码生成和对话系统。其在这些任务中表现出色,尤其是在处理大规模模型时。
|
||
|
||
6.**总结**
|
||
|
||
GRPO算法在大语言模型训练中相较于PPO算法具有以下优势:
|
||
|
||
1. **计算资源与内存需求更低**:无需维护价值网络,降低了计算和存储负担。
|
||
2. **训练效率与稳定性更高**:通过组内相对奖励和动态梯度正则化,提高了训练的稳定性和效率。
|
||
3. **模型性能更优**:在数学推理、代码生成等任务中表现优异,提升了模型的通过率和代码可运行性。
|
||
|
||
然而,PPO算法在某些特定任务中仍然具有其独特的优势,例如其在模拟机器人操作和Atari游戏中的应用。
|
||
|
||
在DeepSeek-R1的训练流程中,拒绝采样(RS)阶段是如何工作的,以及它对模型泛化能力的影响?
|
||
|
||
在DeepSeek-R1的训练流程中,拒绝采样(Rejection Sampling, RS)阶段是一个关键环节,其主要目的是优化模型的推理能力,并提升其泛化性能。以下是拒绝采样阶段的工作机制及其对模型泛化能力的影响的详细说明:
|
||
|
||
拒绝采样阶段的工作机制
|
||
|
||
1. **生成候选指令**:在拒绝采样阶段,模型首先生成多个候选指令或回答。这些候选指令可能来自不同的领域,包括推理、写作、角色扮演等任务。
|
||
2. **评估候选质量**:通过训练过的奖励模型(Reward Model),对每个候选指令的质量进行评估。奖励模型会计算每个候选指令的质量分数,以判断其是否符合要求。
|
||
3. **筛选高质量样本**:根据奖励模型的评估结果,筛选出高质量的候选指令。这些高质量的样本将被用于后续的监督微调(SFT)阶段。
|
||
4. **生成SFT数据**:通过拒绝采样生成的高质量样本,构建监督微调数据集(SFT Data)。这些数据不仅包括推理任务的数据,还涵盖了写作、角色扮演等非推理任务的数据,从而增强模型在多任务上的能力。
|
||
|
||
拒绝采样对模型泛化能力的影响
|
||
|
||
1. **提升推理能力**:拒绝采样通过筛选高质量的候选指令,确保生成的数据更加准确和可靠。这有助于模型在推理任务中避免逻辑错误或不合理的推理链路,从而提升其推理能力。
|
||
2. **增强通用能力**:拒绝采样不仅限于推理任务,还涉及其他领域的数据(如写作、角色扮演等)。这种多任务的数据分布有助于模型学习更复杂的分布,从而提升其在多种任务上的泛化能力。
|
||
3. **优化模型性能**:通过拒绝采样生成的高质量数据,可以更有效地指导监督微调阶段的训练。这不仅提高了模型在推理任务上的表现,还增强了其在非推理任务上的能力,使模型在多种任务上都能表现出色。
|
||
4. **减少训练成本**:拒绝采样通过筛选高质量样本,减少了无效数据的训练成本。这使得模型能够在有限的计算资源下,更高效地完成训练。
|
||
|
||
总结
|
||
|
||
拒绝采样阶段在DeepSeek-R1的训练流程中起到了至关重要的作用。它通过生成和筛选高质量的候选指令,优化了监督微调数据的质量,从而提升了模型在推理和多任务上的泛化能力。
|
||
|
||
DeepSeek-R1模型在最终强化学习阶段结合的复杂奖励模型是如何设计的?
|
||
|
||
DeepSeek-R1模型在最终强化学习阶段结合的复杂奖励模型设计主要体现在以下几个方面:
|
||
|
||
1.**准确性奖励(Accuracy Reward)**
|
||
|
||
准确性奖励用于评估模型答案的正确性。在数学问题中,这种奖励可以通过检查答案是否符合标准格式来实现;在编程任务中,则可以通过编译器反馈测试用例的正确性来评估答案的准确性。这种奖励机制确保了模型在推理过程中能够生成准确且符合要求的答案。
|
||
|
||
2.**格式奖励(Format Reward)**
|
||
|
||
格式奖励用于引导模型按照指定的格式输出推理过程。例如,在数学问题中,格式奖励可以要求模型将答案和推理过程清晰地分开,并使用特定的标签(如“
|
||
|
||
”)标注思考过程。这种奖励机制不仅提高了模型输出的可读性,还帮助用户更好地理解模型的推理逻辑。
|
||
|
||
3.**语言一致性奖励(Language Consistency Reward)**
|
||
|
||
在涉及多种语言的提示链中,DeepSeek-R1引入了语言一致性奖励,该奖励根据目标语言链中目标语言词汇的占比进行计算。虽然这种奖励可能会导致模型性能略微下降,但其目的是使模型输出更符合用户的阅读习惯。
|
||
|
||
4.**奖励建模与优化**
|
||
|
||
在强化学习阶段,DeepSeek-R1通过组内奖励差异(即不同样本之间的奖励差异)来计算优势值(advantage),从而优化策略模型。此外,为了增加模型生成多样性的奖励建模,还引入了KL散度正则化项。这些机制共同作用,使模型在训练过程中逐步提升其推理能力。
|
||
|
||
5.**多阶段训练与奖励信号的逐步引入**
|
||
|
||
DeepSeek-R1采用多阶段训练方法,从冷启动数据微调开始,逐步引入监督微调、强化学习和二级强化学习等阶段。在每个阶段,奖励信号的引入方式不同。例如,在冷启动阶段,模型通过少量长COT数据进行训练;在强化学习阶段,则通过准确性奖励和格式奖励逐步引导模型优化。
|
||
|
||
6.**奖励信号的组合与优化**
|
||
|
||
在最终强化学习阶段,DeepSeek-R1将准确性奖励和语言一致性奖励直接相加,形成最终的奖励信号。这种组合方式不仅提高了模型的准确性,还增强了其对用户需求的适应性。
|
||
|
||
综上,DeepSeek-R1的复杂奖励模型通过结合准确性奖励、格式奖励、语言一致性奖励以及优化机制,实现了对模型推理能力的全面提升。
|
||
|
||
|
||
|
||
> 来源:https://www.163.com/dy/article/JO1NC3OP0553TT8I.html?utm_source=chatgpt.com |