Compare commits
17 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
6b506a1c08 | ||
|
|
0c9f4fa97e | ||
|
|
1c9b09fb78 | ||
|
|
9fb14f23d2 | ||
|
|
4795dc4f68 | ||
|
|
acf0f804c5 | ||
|
|
4e2951854b | ||
|
|
80dfb429d7 | ||
|
|
9c0ba77e22 | ||
|
|
46b4651073 | ||
|
|
03842353e4 | ||
|
|
22bb07f00e | ||
|
|
660f883197 | ||
|
|
988de80b66 | ||
|
|
dc6aa226ee | ||
|
|
a7b6b080ab | ||
|
|
9202cbd4d4 |
@@ -41,7 +41,8 @@ Generate a swarm of worker agents with a coding agent(queen) that control them.
|
||||
|
||||
Visit [adenhq.com](https://adenhq.com) for complete documentation, examples, and guides.
|
||||
|
||||
[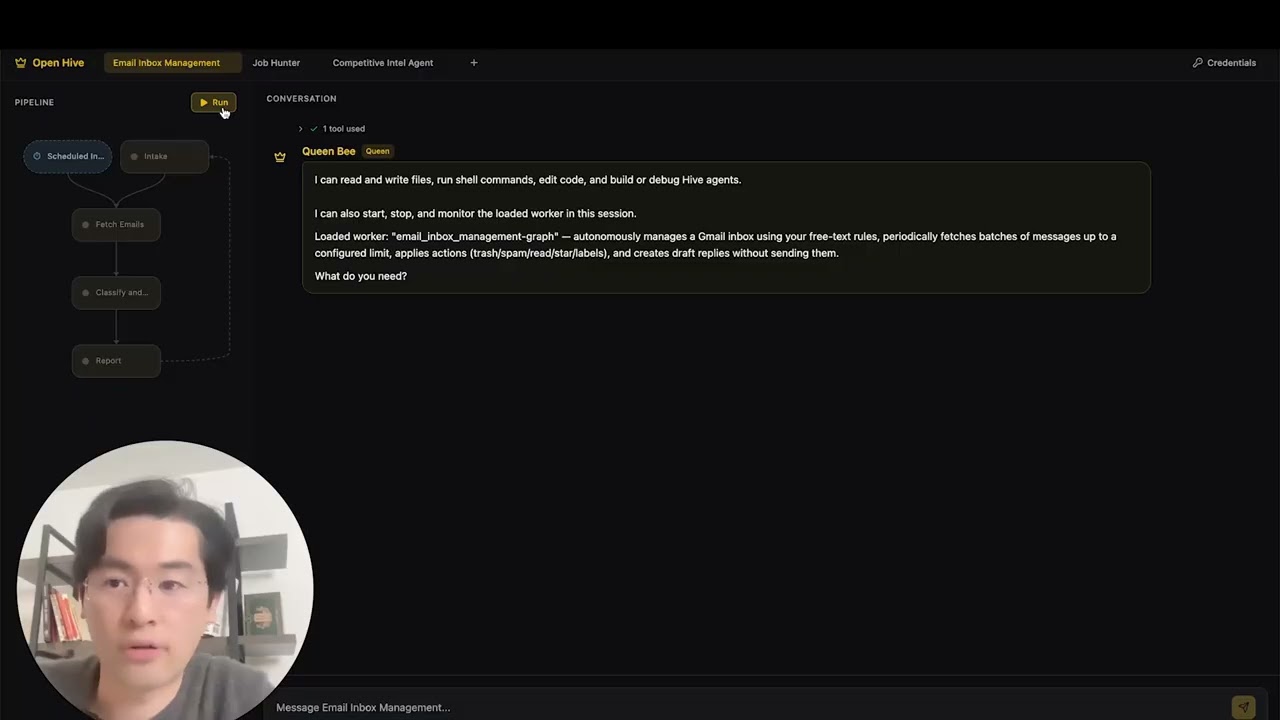](https://www.youtube.com/watch?v=XDOG9fOaLjU)
|
||||
https://github.com/user-attachments/assets/aad3a035-e7b3-4cac-b13d-4a83c7002c30
|
||||
|
||||
|
||||
## Who Is Hive For?
|
||||
|
||||
|
||||
@@ -1,31 +0,0 @@
|
||||
perf: reduce subprocess spawning in quickstart scripts (#4427)
|
||||
|
||||
## Problem
|
||||
Windows process creation (CreateProcess) is 10-100x slower than Linux fork/exec.
|
||||
The quickstart scripts were spawning 4+ separate `uv run python -c "import X"`
|
||||
processes to verify imports, adding ~600ms overhead on Windows.
|
||||
|
||||
## Solution
|
||||
Consolidated all import checks into a single batch script that checks multiple
|
||||
modules in one subprocess call, reducing spawn overhead by ~75%.
|
||||
|
||||
## Changes
|
||||
- **New**: `scripts/check_requirements.py` - Batched import checker
|
||||
- **New**: `scripts/test_check_requirements.py` - Test suite
|
||||
- **New**: `scripts/benchmark_quickstart.ps1` - Performance benchmark tool
|
||||
- **Modified**: `quickstart.ps1` - Updated import verification (2 sections)
|
||||
- **Modified**: `quickstart.sh` - Updated import verification
|
||||
|
||||
## Performance Impact
|
||||
**Benchmark results on Windows:**
|
||||
- Before: ~19.8 seconds for import checks
|
||||
- After: ~4.9 seconds for import checks
|
||||
- **Improvement: 14.9 seconds saved (75.2% faster)**
|
||||
|
||||
## Testing
|
||||
- ✅ All functional tests pass (`scripts/test_check_requirements.py`)
|
||||
- ✅ Quickstart scripts work correctly on Windows
|
||||
- ✅ Error handling verified (invalid imports reported correctly)
|
||||
- ✅ Performance benchmark confirms 75%+ improvement
|
||||
|
||||
Fixes #4427
|
||||
@@ -51,7 +51,13 @@ def get_preferred_model() -> str:
|
||||
"""Return the user's preferred LLM model string (e.g. 'anthropic/claude-sonnet-4-20250514')."""
|
||||
llm = get_hive_config().get("llm", {})
|
||||
if llm.get("provider") and llm.get("model"):
|
||||
return f"{llm['provider']}/{llm['model']}"
|
||||
provider = str(llm["provider"])
|
||||
model = str(llm["model"]).strip()
|
||||
# OpenRouter quickstart stores raw model IDs; tolerate pasted "openrouter/<id>" too.
|
||||
if provider.lower() == "openrouter" and model.lower().startswith("openrouter/"):
|
||||
model = model[len("openrouter/") :]
|
||||
if model:
|
||||
return f"{provider}/{model}"
|
||||
return "anthropic/claude-sonnet-4-20250514"
|
||||
|
||||
|
||||
@@ -61,6 +67,7 @@ def get_max_tokens() -> int:
|
||||
|
||||
|
||||
DEFAULT_MAX_CONTEXT_TOKENS = 32_000
|
||||
OPENROUTER_API_BASE = "https://openrouter.ai/api/v1"
|
||||
|
||||
|
||||
def get_max_context_tokens() -> int:
|
||||
@@ -142,7 +149,11 @@ def get_api_base() -> str | None:
|
||||
if llm.get("use_kimi_code_subscription"):
|
||||
# Kimi Code uses an Anthropic-compatible endpoint (no /v1 suffix).
|
||||
return "https://api.kimi.com/coding"
|
||||
return llm.get("api_base")
|
||||
if llm.get("api_base"):
|
||||
return llm["api_base"]
|
||||
if str(llm.get("provider", "")).lower() == "openrouter":
|
||||
return OPENROUTER_API_BASE
|
||||
return None
|
||||
|
||||
|
||||
def get_llm_extra_kwargs() -> dict[str, Any]:
|
||||
|
||||
@@ -51,6 +51,16 @@ def ensure_credential_key_env() -> None:
|
||||
if found and value:
|
||||
os.environ[var_name] = value
|
||||
logger.debug("Loaded %s from shell config", var_name)
|
||||
# Also load the currently configured LLM env var even if it's not in CREDENTIAL_SPECS.
|
||||
# This keeps quickstart-written keys available to fresh processes on Unix shells.
|
||||
from framework.config import get_hive_config
|
||||
|
||||
llm_env_var = str(get_hive_config().get("llm", {}).get("api_key_env_var", "")).strip()
|
||||
if llm_env_var and not os.environ.get(llm_env_var):
|
||||
found, value = check_env_var_in_shell_config(llm_env_var)
|
||||
if found and value:
|
||||
os.environ[llm_env_var] = value
|
||||
logger.debug("Loaded configured LLM env var %s from shell config", llm_env_var)
|
||||
except ImportError:
|
||||
pass
|
||||
|
||||
|
||||
@@ -822,6 +822,7 @@ class EventLoopNode(NodeProtocol):
|
||||
)
|
||||
_stream_retry_count = 0
|
||||
_turn_cancelled = False
|
||||
_llm_turn_failed_waiting_input = False
|
||||
while True:
|
||||
try:
|
||||
(
|
||||
@@ -941,6 +942,16 @@ class EventLoopNode(NodeProtocol):
|
||||
# can retry or adjust the request.
|
||||
if ctx.node_spec.client_facing:
|
||||
error_msg = f"LLM call failed: {e}"
|
||||
_guardrail_phrase = (
|
||||
"no endpoints available matching your guardrail restrictions "
|
||||
"and data policy"
|
||||
)
|
||||
if _guardrail_phrase in str(e).lower():
|
||||
error_msg += (
|
||||
" OpenRouter blocked this model under current privacy settings. "
|
||||
"Update https://openrouter.ai/settings/privacy or choose another "
|
||||
"OpenRouter model."
|
||||
)
|
||||
logger.error(
|
||||
"[%s] iter=%d: %s — waiting for user input",
|
||||
node_id,
|
||||
@@ -962,6 +973,7 @@ class EventLoopNode(NodeProtocol):
|
||||
f"[Error: {error_msg}. Please try again.]"
|
||||
)
|
||||
await self._await_user_input(ctx, prompt="")
|
||||
_llm_turn_failed_waiting_input = True
|
||||
break # exit retry loop, continue outer iteration
|
||||
|
||||
# Non-client-facing: crash as before
|
||||
@@ -1012,6 +1024,11 @@ class EventLoopNode(NodeProtocol):
|
||||
await self._await_user_input(ctx, prompt="")
|
||||
continue # back to top of for-iteration loop
|
||||
|
||||
# Client-facing non-transient LLM failures wait for user input and then
|
||||
# continue the outer loop without touching per-turn token vars.
|
||||
if _llm_turn_failed_waiting_input:
|
||||
continue
|
||||
|
||||
# 6e'. Feed actual API token count back for accurate estimation
|
||||
turn_input = turn_tokens.get("input", 0)
|
||||
if turn_input > 0:
|
||||
@@ -2298,7 +2315,6 @@ class EventLoopNode(NodeProtocol):
|
||||
|
||||
elif tc.tool_name == "ask_user":
|
||||
# --- Framework-level ask_user handling ---
|
||||
user_input_requested = True
|
||||
ask_user_prompt = tc.tool_input.get("question", "")
|
||||
raw_options = tc.tool_input.get("options", None)
|
||||
# Defensive: ensure options is a list of strings.
|
||||
@@ -2335,6 +2351,8 @@ class EventLoopNode(NodeProtocol):
|
||||
user_input_requested = False
|
||||
continue
|
||||
|
||||
user_input_requested = True
|
||||
|
||||
# Free-form ask_user (no options): stream the question
|
||||
# text as a chat message so the user can see it. When
|
||||
# options are present the QuestionWidget shows the
|
||||
@@ -2360,7 +2378,6 @@ class EventLoopNode(NodeProtocol):
|
||||
|
||||
elif tc.tool_name == "ask_user_multiple":
|
||||
# --- Framework-level ask_user_multiple ---
|
||||
user_input_requested = True
|
||||
raw_questions = tc.tool_input.get("questions", [])
|
||||
if not isinstance(raw_questions, list) or len(raw_questions) < 2:
|
||||
result = ToolResult(
|
||||
@@ -2398,6 +2415,8 @@ class EventLoopNode(NodeProtocol):
|
||||
}
|
||||
)
|
||||
|
||||
user_input_requested = True
|
||||
|
||||
# Store as multi-question prompt/options for
|
||||
# the event emission path
|
||||
ask_user_prompt = ""
|
||||
@@ -2708,7 +2727,11 @@ class EventLoopNode(NodeProtocol):
|
||||
content=result.content,
|
||||
is_error=result.is_error,
|
||||
)
|
||||
if tc.tool_name in ("ask_user", "ask_user_multiple"):
|
||||
if (
|
||||
tc.tool_name in ("ask_user", "ask_user_multiple")
|
||||
and user_input_requested
|
||||
and not result.is_error
|
||||
):
|
||||
# Defer tool_call_completed until after user responds
|
||||
self._deferred_tool_complete = {
|
||||
"stream_id": stream_id,
|
||||
|
||||
+647
-12
@@ -7,9 +7,13 @@ Groq, and local models.
|
||||
See: https://docs.litellm.ai/docs/providers
|
||||
"""
|
||||
|
||||
import ast
|
||||
import asyncio
|
||||
import hashlib
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
import time
|
||||
from collections.abc import AsyncIterator
|
||||
from datetime import datetime
|
||||
@@ -44,7 +48,10 @@ def _patch_litellm_anthropic_oauth() -> None:
|
||||
"""
|
||||
try:
|
||||
from litellm.llms.anthropic.common_utils import AnthropicModelInfo
|
||||
from litellm.types.llms.anthropic import ANTHROPIC_OAUTH_TOKEN_PREFIX
|
||||
from litellm.types.llms.anthropic import (
|
||||
ANTHROPIC_OAUTH_BETA_HEADER,
|
||||
ANTHROPIC_OAUTH_TOKEN_PREFIX,
|
||||
)
|
||||
except ImportError:
|
||||
logger.warning(
|
||||
"Could not apply litellm Anthropic OAuth patch — litellm internals may have "
|
||||
@@ -69,9 +76,27 @@ def _patch_litellm_anthropic_oauth() -> None:
|
||||
api_key=api_key,
|
||||
api_base=api_base,
|
||||
)
|
||||
# Check both authorization header and x-api-key for OAuth tokens.
|
||||
# litellm's optionally_handle_anthropic_oauth only checks headers["authorization"],
|
||||
# but hive passes OAuth tokens via api_key — so litellm puts them into x-api-key.
|
||||
# Anthropic rejects OAuth tokens in x-api-key; they must go in Authorization: Bearer.
|
||||
auth = result.get("authorization", "")
|
||||
if auth.startswith(f"Bearer {ANTHROPIC_OAUTH_TOKEN_PREFIX}"):
|
||||
x_api_key = result.get("x-api-key", "")
|
||||
oauth_prefix = f"Bearer {ANTHROPIC_OAUTH_TOKEN_PREFIX}"
|
||||
auth_is_oauth = auth.startswith(oauth_prefix)
|
||||
key_is_oauth = x_api_key.startswith(ANTHROPIC_OAUTH_TOKEN_PREFIX)
|
||||
if auth_is_oauth or key_is_oauth:
|
||||
token = x_api_key if key_is_oauth else auth.removeprefix("Bearer ").strip()
|
||||
result.pop("x-api-key", None)
|
||||
result["authorization"] = f"Bearer {token}"
|
||||
# Merge the OAuth beta header with any existing beta headers.
|
||||
existing_beta = result.get("anthropic-beta", "")
|
||||
beta_parts = (
|
||||
[b.strip() for b in existing_beta.split(",") if b.strip()] if existing_beta else []
|
||||
)
|
||||
if ANTHROPIC_OAUTH_BETA_HEADER not in beta_parts:
|
||||
beta_parts.append(ANTHROPIC_OAUTH_BETA_HEADER)
|
||||
result["anthropic-beta"] = ",".join(beta_parts)
|
||||
return result
|
||||
|
||||
AnthropicModelInfo.validate_environment = _patched_validate_environment
|
||||
@@ -130,11 +155,15 @@ def _patch_litellm_metadata_nonetype() -> None:
|
||||
if litellm is not None:
|
||||
_patch_litellm_anthropic_oauth()
|
||||
_patch_litellm_metadata_nonetype()
|
||||
# Let litellm silently drop params unsupported by the target provider
|
||||
# (e.g. stream_options for Anthropic) instead of forwarding them verbatim.
|
||||
litellm.drop_params = True
|
||||
|
||||
RATE_LIMIT_MAX_RETRIES = 10
|
||||
RATE_LIMIT_BACKOFF_BASE = 2 # seconds
|
||||
RATE_LIMIT_MAX_DELAY = 120 # seconds - cap to prevent absurd waits
|
||||
MINIMAX_API_BASE = "https://api.minimax.io/v1"
|
||||
OPENROUTER_API_BASE = "https://openrouter.ai/api/v1"
|
||||
|
||||
# Providers that accept cache_control on message content blocks.
|
||||
# Anthropic: native ephemeral caching. MiniMax & Z-AI/GLM: pass-through to their APIs.
|
||||
@@ -159,10 +188,69 @@ def _model_supports_cache_control(model: str) -> bool:
|
||||
# enforces a coding-agent whitelist that blocks unknown User-Agents.
|
||||
KIMI_API_BASE = "https://api.kimi.com/coding"
|
||||
|
||||
# Claude Code OAuth subscription: the Anthropic API requires a specific
|
||||
# User-Agent and a billing integrity header for OAuth-authenticated requests.
|
||||
CLAUDE_CODE_VERSION = "2.1.76"
|
||||
CLAUDE_CODE_USER_AGENT = f"claude-code/{CLAUDE_CODE_VERSION}"
|
||||
_CLAUDE_CODE_BILLING_SALT = "59cf53e54c78"
|
||||
|
||||
|
||||
def _sample_js_code_unit(text: str, idx: int) -> str:
|
||||
"""Return the character at UTF-16 code unit index *idx*, matching JS semantics."""
|
||||
encoded = text.encode("utf-16-le")
|
||||
unit_offset = idx * 2
|
||||
if unit_offset + 2 > len(encoded):
|
||||
return "0"
|
||||
code_unit = int.from_bytes(encoded[unit_offset : unit_offset + 2], "little")
|
||||
return chr(code_unit)
|
||||
|
||||
|
||||
def _claude_code_billing_header(messages: list[dict[str, Any]]) -> str:
|
||||
"""Build the billing integrity system block required by Anthropic's OAuth path."""
|
||||
# Find the first user message text
|
||||
first_text = ""
|
||||
for msg in messages:
|
||||
if msg.get("role") != "user":
|
||||
continue
|
||||
content = msg.get("content")
|
||||
if isinstance(content, str):
|
||||
first_text = content
|
||||
break
|
||||
if isinstance(content, list):
|
||||
for block in content:
|
||||
if isinstance(block, dict) and block.get("type") == "text" and block.get("text"):
|
||||
first_text = block["text"]
|
||||
break
|
||||
if first_text:
|
||||
break
|
||||
|
||||
sampled = "".join(_sample_js_code_unit(first_text, i) for i in (4, 7, 20))
|
||||
version_hash = hashlib.sha256(
|
||||
f"{_CLAUDE_CODE_BILLING_SALT}{sampled}{CLAUDE_CODE_VERSION}".encode()
|
||||
).hexdigest()
|
||||
entrypoint = os.environ.get("CLAUDE_CODE_ENTRYPOINT", "").strip() or "cli"
|
||||
return (
|
||||
f"x-anthropic-billing-header: cc_version={CLAUDE_CODE_VERSION}.{version_hash[:3]}; "
|
||||
f"cc_entrypoint={entrypoint}; cch=00000;"
|
||||
)
|
||||
|
||||
|
||||
# Empty-stream retries use a short fixed delay, not the rate-limit backoff.
|
||||
# Conversation-structure issues are deterministic — long waits don't help.
|
||||
EMPTY_STREAM_MAX_RETRIES = 3
|
||||
EMPTY_STREAM_RETRY_DELAY = 1.0 # seconds
|
||||
OPENROUTER_TOOL_COMPAT_ERROR_SNIPPETS = (
|
||||
"no endpoints found that support tool use",
|
||||
"no endpoints available that support tool use",
|
||||
"provider routing",
|
||||
)
|
||||
OPENROUTER_TOOL_CALL_RE = re.compile(
|
||||
r"<\|tool_call_start\|>\s*(.*?)\s*<\|tool_call_end\|>",
|
||||
re.DOTALL,
|
||||
)
|
||||
OPENROUTER_TOOL_COMPAT_CACHE_TTL_SECONDS = 3600
|
||||
# OpenRouter routing can change over time, so tool-compat caching must expire.
|
||||
OPENROUTER_TOOL_COMPAT_MODEL_CACHE: dict[str, float] = {}
|
||||
|
||||
# Directory for dumping failed requests
|
||||
FAILED_REQUESTS_DIR = Path.home() / ".hive" / "failed_requests"
|
||||
@@ -205,6 +293,24 @@ def _prune_failed_request_dumps(max_files: int = MAX_FAILED_REQUEST_DUMPS) -> No
|
||||
pass # Best-effort — never block the caller
|
||||
|
||||
|
||||
def _remember_openrouter_tool_compat_model(model: str) -> None:
|
||||
"""Cache OpenRouter tool-compat fallback for a bounded time window."""
|
||||
OPENROUTER_TOOL_COMPAT_MODEL_CACHE[model] = (
|
||||
time.monotonic() + OPENROUTER_TOOL_COMPAT_CACHE_TTL_SECONDS
|
||||
)
|
||||
|
||||
|
||||
def _is_openrouter_tool_compat_cached(model: str) -> bool:
|
||||
"""Return True when the cached OpenRouter compat entry is still fresh."""
|
||||
expires_at = OPENROUTER_TOOL_COMPAT_MODEL_CACHE.get(model)
|
||||
if expires_at is None:
|
||||
return False
|
||||
if expires_at <= time.monotonic():
|
||||
OPENROUTER_TOOL_COMPAT_MODEL_CACHE.pop(model, None)
|
||||
return False
|
||||
return True
|
||||
|
||||
|
||||
def _dump_failed_request(
|
||||
model: str,
|
||||
kwargs: dict[str, Any],
|
||||
@@ -408,6 +514,12 @@ class LiteLLMProvider(LLMProvider):
|
||||
self.api_key = api_key
|
||||
self.api_base = api_base or self._default_api_base_for_model(_original_model)
|
||||
self.extra_kwargs = kwargs
|
||||
# Detect Claude Code OAuth subscription by checking the api_key prefix.
|
||||
self._claude_code_oauth = bool(api_key and api_key.startswith("sk-ant-oat"))
|
||||
if self._claude_code_oauth:
|
||||
# Anthropic requires a specific User-Agent for OAuth requests.
|
||||
eh = self.extra_kwargs.setdefault("extra_headers", {})
|
||||
eh.setdefault("user-agent", CLAUDE_CODE_USER_AGENT)
|
||||
# The Codex ChatGPT backend (chatgpt.com/backend-api/codex) rejects
|
||||
# several standard OpenAI params: max_output_tokens, stream_options.
|
||||
self._codex_backend = bool(
|
||||
@@ -431,6 +543,8 @@ class LiteLLMProvider(LLMProvider):
|
||||
model_lower = model.lower()
|
||||
if model_lower.startswith("minimax/") or model_lower.startswith("minimax-"):
|
||||
return MINIMAX_API_BASE
|
||||
if model_lower.startswith("openrouter/"):
|
||||
return OPENROUTER_API_BASE
|
||||
if model_lower.startswith("kimi/"):
|
||||
return KIMI_API_BASE
|
||||
if model_lower.startswith("hive/"):
|
||||
@@ -773,6 +887,9 @@ class LiteLLMProvider(LLMProvider):
|
||||
return await self._collect_stream_to_response(stream_iter)
|
||||
|
||||
full_messages: list[dict[str, Any]] = []
|
||||
if self._claude_code_oauth:
|
||||
billing = _claude_code_billing_header(messages)
|
||||
full_messages.append({"role": "system", "content": billing})
|
||||
if system:
|
||||
sys_msg: dict[str, Any] = {"role": "system", "content": system}
|
||||
if _model_supports_cache_control(self.model):
|
||||
@@ -834,11 +951,504 @@ class LiteLLMProvider(LLMProvider):
|
||||
},
|
||||
}
|
||||
|
||||
def _is_anthropic_model(self) -> bool:
|
||||
"""Return True when the configured model targets Anthropic."""
|
||||
model = (self.model or "").lower()
|
||||
return model.startswith("anthropic/") or model.startswith("claude-")
|
||||
|
||||
def _is_minimax_model(self) -> bool:
|
||||
"""Return True when the configured model targets MiniMax."""
|
||||
model = (self.model or "").lower()
|
||||
return model.startswith("minimax/") or model.startswith("minimax-")
|
||||
|
||||
def _is_openrouter_model(self) -> bool:
|
||||
"""Return True when the configured model targets OpenRouter."""
|
||||
model = (self.model or "").lower()
|
||||
if model.startswith("openrouter/"):
|
||||
return True
|
||||
api_base = (self.api_base or "").lower()
|
||||
return "openrouter.ai/api/v1" in api_base
|
||||
|
||||
def _should_use_openrouter_tool_compat(
|
||||
self,
|
||||
error: BaseException,
|
||||
tools: list[Tool] | None,
|
||||
) -> bool:
|
||||
"""Return True when OpenRouter rejects native tool use for the model."""
|
||||
if not tools or not self._is_openrouter_model():
|
||||
return False
|
||||
error_text = str(error).lower()
|
||||
return "openrouter" in error_text and any(
|
||||
snippet in error_text for snippet in OPENROUTER_TOOL_COMPAT_ERROR_SNIPPETS
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def _extract_json_object(text: str) -> dict[str, Any] | None:
|
||||
"""Extract the first JSON object from a model response."""
|
||||
candidates = [text.strip()]
|
||||
|
||||
stripped = text.strip()
|
||||
if stripped.startswith("```"):
|
||||
fence_lines = stripped.splitlines()
|
||||
if len(fence_lines) >= 3:
|
||||
candidates.append("\n".join(fence_lines[1:-1]).strip())
|
||||
|
||||
decoder = json.JSONDecoder()
|
||||
for candidate in candidates:
|
||||
if not candidate:
|
||||
continue
|
||||
try:
|
||||
parsed = json.loads(candidate)
|
||||
except json.JSONDecodeError:
|
||||
parsed = None
|
||||
if isinstance(parsed, dict):
|
||||
return parsed
|
||||
|
||||
for start_idx, char in enumerate(candidate):
|
||||
if char != "{":
|
||||
continue
|
||||
try:
|
||||
parsed, _ = decoder.raw_decode(candidate[start_idx:])
|
||||
except json.JSONDecodeError:
|
||||
continue
|
||||
if isinstance(parsed, dict):
|
||||
return parsed
|
||||
return None
|
||||
|
||||
def _parse_openrouter_tool_compat_response(
|
||||
self,
|
||||
content: str,
|
||||
tools: list[Tool],
|
||||
) -> tuple[str, list[dict[str, Any]]]:
|
||||
"""Parse JSON tool-compat output into assistant text and tool calls."""
|
||||
payload = self._extract_json_object(content)
|
||||
if payload is None:
|
||||
text_tool_content, text_tool_calls = self._parse_openrouter_text_tool_calls(
|
||||
content,
|
||||
tools,
|
||||
)
|
||||
if text_tool_calls:
|
||||
logger.info(
|
||||
"[openrouter-tool-compat] Parsed textual tool-call markers for %s",
|
||||
self.model,
|
||||
)
|
||||
return text_tool_content, text_tool_calls
|
||||
logger.info(
|
||||
"[openrouter-tool-compat] %s returned non-JSON fallback content; "
|
||||
"treating it as plain text.",
|
||||
self.model,
|
||||
)
|
||||
return content.strip(), []
|
||||
|
||||
assistant_text = payload.get("assistant_response")
|
||||
if not isinstance(assistant_text, str):
|
||||
assistant_text = payload.get("content")
|
||||
if not isinstance(assistant_text, str):
|
||||
assistant_text = payload.get("response")
|
||||
if not isinstance(assistant_text, str):
|
||||
assistant_text = ""
|
||||
|
||||
tool_calls_raw = payload.get("tool_calls")
|
||||
if not tool_calls_raw and {"name", "arguments"} <= payload.keys():
|
||||
tool_calls_raw = [payload]
|
||||
elif isinstance(payload.get("tool_call"), dict):
|
||||
tool_calls_raw = [payload["tool_call"]]
|
||||
|
||||
if not isinstance(tool_calls_raw, list):
|
||||
tool_calls_raw = []
|
||||
|
||||
allowed_tool_names = {tool.name for tool in tools}
|
||||
tool_calls: list[dict[str, Any]] = []
|
||||
compat_prefix = f"openrouter_compat_{time.time_ns()}"
|
||||
|
||||
for idx, raw_call in enumerate(tool_calls_raw):
|
||||
if not isinstance(raw_call, dict):
|
||||
continue
|
||||
|
||||
function_block = raw_call.get("function")
|
||||
function_name = (
|
||||
raw_call.get("name")
|
||||
or raw_call.get("tool_name")
|
||||
or (function_block.get("name") if isinstance(function_block, dict) else None)
|
||||
)
|
||||
if not isinstance(function_name, str) or function_name not in allowed_tool_names:
|
||||
if function_name:
|
||||
logger.warning(
|
||||
"[openrouter-tool-compat] Ignoring unknown tool '%s' for model %s",
|
||||
function_name,
|
||||
self.model,
|
||||
)
|
||||
continue
|
||||
|
||||
arguments = raw_call.get("arguments")
|
||||
if arguments is None:
|
||||
arguments = raw_call.get("tool_input")
|
||||
if arguments is None:
|
||||
arguments = raw_call.get("input")
|
||||
if arguments is None and isinstance(function_block, dict):
|
||||
arguments = function_block.get("arguments")
|
||||
if arguments is None:
|
||||
arguments = {}
|
||||
|
||||
if isinstance(arguments, str):
|
||||
try:
|
||||
arguments = json.loads(arguments)
|
||||
except json.JSONDecodeError:
|
||||
arguments = {"_raw": arguments}
|
||||
elif not isinstance(arguments, dict):
|
||||
arguments = {"value": arguments}
|
||||
|
||||
tool_calls.append(
|
||||
{
|
||||
"id": f"{compat_prefix}_{idx}",
|
||||
"name": function_name,
|
||||
"input": arguments,
|
||||
}
|
||||
)
|
||||
|
||||
return assistant_text.strip(), tool_calls
|
||||
|
||||
@staticmethod
|
||||
def _close_truncated_json_fragment(fragment: str) -> str:
|
||||
"""Close a truncated JSON fragment by balancing quotes/brackets."""
|
||||
stack: list[str] = []
|
||||
in_string = False
|
||||
escaped = False
|
||||
normalized = fragment.rstrip()
|
||||
|
||||
while normalized and normalized[-1] in ",:{[":
|
||||
normalized = normalized[:-1].rstrip()
|
||||
|
||||
for char in normalized:
|
||||
if in_string:
|
||||
if escaped:
|
||||
escaped = False
|
||||
elif char == "\\":
|
||||
escaped = True
|
||||
elif char == '"':
|
||||
in_string = False
|
||||
continue
|
||||
|
||||
if char == '"':
|
||||
in_string = True
|
||||
elif char in "{[":
|
||||
stack.append(char)
|
||||
elif char == "}" and stack and stack[-1] == "{":
|
||||
stack.pop()
|
||||
elif char == "]" and stack and stack[-1] == "[":
|
||||
stack.pop()
|
||||
|
||||
if in_string:
|
||||
if escaped:
|
||||
normalized = normalized[:-1]
|
||||
normalized += '"'
|
||||
|
||||
for opener in reversed(stack):
|
||||
normalized += "}" if opener == "{" else "]"
|
||||
|
||||
return normalized
|
||||
|
||||
def _repair_truncated_tool_arguments(self, raw_arguments: str) -> dict[str, Any] | None:
|
||||
"""Try to recover a truncated JSON object from tool-call arguments."""
|
||||
stripped = raw_arguments.strip()
|
||||
if not stripped or stripped[0] != "{":
|
||||
return None
|
||||
|
||||
max_trim = min(len(stripped), 256)
|
||||
for trim in range(max_trim + 1):
|
||||
candidate = stripped[: len(stripped) - trim].rstrip()
|
||||
if not candidate:
|
||||
break
|
||||
candidate = self._close_truncated_json_fragment(candidate)
|
||||
try:
|
||||
parsed = json.loads(candidate)
|
||||
except json.JSONDecodeError:
|
||||
continue
|
||||
if isinstance(parsed, dict):
|
||||
return parsed
|
||||
return None
|
||||
|
||||
def _parse_tool_call_arguments(self, raw_arguments: str, tool_name: str) -> dict[str, Any]:
|
||||
"""Parse streamed tool arguments, repairing truncation when possible."""
|
||||
try:
|
||||
parsed = json.loads(raw_arguments) if raw_arguments else {}
|
||||
except json.JSONDecodeError:
|
||||
parsed = None
|
||||
|
||||
if isinstance(parsed, dict):
|
||||
return parsed
|
||||
|
||||
repaired = self._repair_truncated_tool_arguments(raw_arguments)
|
||||
if repaired is not None:
|
||||
logger.warning(
|
||||
"[tool-args] Recovered truncated arguments for %s on %s",
|
||||
tool_name,
|
||||
self.model,
|
||||
)
|
||||
return repaired
|
||||
|
||||
raise ValueError(
|
||||
f"Failed to parse tool call arguments for '{tool_name}' (likely truncated JSON)."
|
||||
)
|
||||
|
||||
def _parse_openrouter_text_tool_calls(
|
||||
self,
|
||||
content: str,
|
||||
tools: list[Tool],
|
||||
) -> tuple[str, list[dict[str, Any]]]:
|
||||
"""Parse textual OpenRouter tool calls into synthetic tool calls.
|
||||
|
||||
Supports both:
|
||||
- Marker wrapped payloads: <|tool_call_start|>...<|tool_call_end|>
|
||||
- Plain one-line tool calls: ask_user("...", ["..."])
|
||||
"""
|
||||
tools_by_name = {tool.name: tool for tool in tools}
|
||||
compat_prefix = f"openrouter_compat_{time.time_ns()}"
|
||||
tool_calls: list[dict[str, Any]] = []
|
||||
segment_index = 0
|
||||
|
||||
for match in OPENROUTER_TOOL_CALL_RE.finditer(content):
|
||||
parsed_calls = self._parse_openrouter_text_tool_call_block(
|
||||
block=match.group(1),
|
||||
tools_by_name=tools_by_name,
|
||||
compat_prefix=f"{compat_prefix}_{segment_index}",
|
||||
)
|
||||
if parsed_calls:
|
||||
segment_index += 1
|
||||
tool_calls.extend(parsed_calls)
|
||||
|
||||
stripped_content = OPENROUTER_TOOL_CALL_RE.sub("", content)
|
||||
retained_lines: list[str] = []
|
||||
for line in stripped_content.splitlines():
|
||||
stripped_line = line.strip()
|
||||
if not stripped_line:
|
||||
retained_lines.append(line)
|
||||
continue
|
||||
|
||||
candidate = stripped_line
|
||||
if candidate.startswith("`") and candidate.endswith("`") and len(candidate) > 1:
|
||||
candidate = candidate[1:-1].strip()
|
||||
|
||||
parsed_calls = self._parse_openrouter_text_tool_call_block(
|
||||
block=candidate,
|
||||
tools_by_name=tools_by_name,
|
||||
compat_prefix=f"{compat_prefix}_{segment_index}",
|
||||
)
|
||||
if parsed_calls:
|
||||
segment_index += 1
|
||||
tool_calls.extend(parsed_calls)
|
||||
continue
|
||||
|
||||
retained_lines.append(line)
|
||||
|
||||
stripped_text = "\n".join(retained_lines).strip()
|
||||
return stripped_text, tool_calls
|
||||
|
||||
def _parse_openrouter_text_tool_call_block(
|
||||
self,
|
||||
block: str,
|
||||
tools_by_name: dict[str, Tool],
|
||||
compat_prefix: str,
|
||||
) -> list[dict[str, Any]]:
|
||||
"""Parse a single textual tool-call block like [tool(arg='x')]."""
|
||||
try:
|
||||
parsed = ast.parse(block.strip(), mode="eval").body
|
||||
except SyntaxError:
|
||||
return []
|
||||
|
||||
call_nodes = parsed.elts if isinstance(parsed, ast.List) else [parsed]
|
||||
tool_calls: list[dict[str, Any]] = []
|
||||
|
||||
for call_index, call_node in enumerate(call_nodes):
|
||||
if not isinstance(call_node, ast.Call) or not isinstance(call_node.func, ast.Name):
|
||||
continue
|
||||
|
||||
tool_name = call_node.func.id
|
||||
tool = tools_by_name.get(tool_name)
|
||||
if tool is None:
|
||||
continue
|
||||
|
||||
try:
|
||||
tool_input = self._parse_openrouter_text_tool_call_arguments(
|
||||
call_node=call_node,
|
||||
tool=tool,
|
||||
)
|
||||
except (ValueError, SyntaxError):
|
||||
continue
|
||||
|
||||
tool_calls.append(
|
||||
{
|
||||
"id": f"{compat_prefix}_{call_index}",
|
||||
"name": tool_name,
|
||||
"input": tool_input,
|
||||
}
|
||||
)
|
||||
|
||||
return tool_calls
|
||||
|
||||
@staticmethod
|
||||
def _parse_openrouter_text_tool_call_arguments(
|
||||
call_node: ast.Call,
|
||||
tool: Tool,
|
||||
) -> dict[str, Any]:
|
||||
"""Parse positional/keyword args from a textual tool call."""
|
||||
properties = tool.parameters.get("properties", {})
|
||||
positional_keys = list(properties.keys())
|
||||
tool_input: dict[str, Any] = {}
|
||||
|
||||
if len(call_node.args) > len(positional_keys):
|
||||
raise ValueError("Too many positional args for textual tool call")
|
||||
|
||||
for idx, arg_node in enumerate(call_node.args):
|
||||
tool_input[positional_keys[idx]] = ast.literal_eval(arg_node)
|
||||
|
||||
for kwarg in call_node.keywords:
|
||||
if kwarg.arg is None:
|
||||
raise ValueError("Star args are not supported in textual tool calls")
|
||||
tool_input[kwarg.arg] = ast.literal_eval(kwarg.value)
|
||||
|
||||
return tool_input
|
||||
|
||||
def _build_openrouter_tool_compat_messages(
|
||||
self,
|
||||
messages: list[dict[str, Any]],
|
||||
system: str,
|
||||
tools: list[Tool],
|
||||
) -> list[dict[str, Any]]:
|
||||
"""Build a JSON-only prompt for models without native tool support."""
|
||||
tool_specs = [
|
||||
{
|
||||
"name": tool.name,
|
||||
"description": tool.description,
|
||||
"parameters": tool.parameters,
|
||||
}
|
||||
for tool in tools
|
||||
]
|
||||
compat_instruction = (
|
||||
"Tool compatibility mode is active because this OpenRouter model does not support "
|
||||
"native function calling on the routed provider.\n"
|
||||
"Return exactly one JSON object and nothing else.\n"
|
||||
'Schema: {"assistant_response": string, '
|
||||
'"tool_calls": [{"name": string, "arguments": object}]}\n'
|
||||
"Rules:\n"
|
||||
"- If a tool is required, put one or more entries in tool_calls "
|
||||
"and do not invent tool results.\n"
|
||||
"- If no tool is required, set tool_calls to [] and put the full "
|
||||
"answer in assistant_response.\n"
|
||||
"- Only use tool names from the allowed tool list.\n"
|
||||
"- arguments must always be valid JSON objects.\n"
|
||||
f"Allowed tools:\n{json.dumps(tool_specs, ensure_ascii=True)}"
|
||||
)
|
||||
compat_system = compat_instruction if not system else f"{system}\n\n{compat_instruction}"
|
||||
|
||||
full_messages: list[dict[str, Any]] = [{"role": "system", "content": compat_system}]
|
||||
full_messages.extend(messages)
|
||||
return [
|
||||
message
|
||||
for message in full_messages
|
||||
if not (
|
||||
message.get("role") == "assistant"
|
||||
and not message.get("content")
|
||||
and not message.get("tool_calls")
|
||||
)
|
||||
]
|
||||
|
||||
async def _acomplete_via_openrouter_tool_compat(
|
||||
self,
|
||||
messages: list[dict[str, Any]],
|
||||
system: str,
|
||||
tools: list[Tool],
|
||||
max_tokens: int,
|
||||
) -> LLMResponse:
|
||||
"""Emulate tool calling via JSON when OpenRouter rejects native tools."""
|
||||
full_messages = self._build_openrouter_tool_compat_messages(messages, system, tools)
|
||||
kwargs: dict[str, Any] = {
|
||||
"model": self.model,
|
||||
"messages": full_messages,
|
||||
"max_tokens": max_tokens,
|
||||
**self.extra_kwargs,
|
||||
}
|
||||
if self.api_key:
|
||||
kwargs["api_key"] = self.api_key
|
||||
if self.api_base:
|
||||
kwargs["api_base"] = self.api_base
|
||||
|
||||
response = await self._acompletion_with_rate_limit_retry(**kwargs)
|
||||
raw_content = response.choices[0].message.content or ""
|
||||
assistant_text, tool_calls = self._parse_openrouter_tool_compat_response(
|
||||
raw_content,
|
||||
tools,
|
||||
)
|
||||
usage = response.usage
|
||||
input_tokens = usage.prompt_tokens if usage else 0
|
||||
output_tokens = usage.completion_tokens if usage else 0
|
||||
stop_reason = "tool_calls" if tool_calls else (response.choices[0].finish_reason or "stop")
|
||||
|
||||
return LLMResponse(
|
||||
content=assistant_text,
|
||||
model=response.model or self.model,
|
||||
input_tokens=input_tokens,
|
||||
output_tokens=output_tokens,
|
||||
stop_reason=stop_reason,
|
||||
raw_response={
|
||||
"compat_mode": "openrouter_tool_emulation",
|
||||
"tool_calls": tool_calls,
|
||||
"response": response,
|
||||
},
|
||||
)
|
||||
|
||||
async def _stream_via_openrouter_tool_compat(
|
||||
self,
|
||||
messages: list[dict[str, Any]],
|
||||
system: str,
|
||||
tools: list[Tool],
|
||||
max_tokens: int,
|
||||
) -> AsyncIterator[StreamEvent]:
|
||||
"""Fallback stream for OpenRouter models without native tool support."""
|
||||
from framework.llm.stream_events import (
|
||||
FinishEvent,
|
||||
StreamErrorEvent,
|
||||
TextDeltaEvent,
|
||||
TextEndEvent,
|
||||
ToolCallEvent,
|
||||
)
|
||||
|
||||
logger.info(
|
||||
"[openrouter-tool-compat] Using compatibility mode for %s",
|
||||
self.model,
|
||||
)
|
||||
try:
|
||||
response = await self._acomplete_via_openrouter_tool_compat(
|
||||
messages=messages,
|
||||
system=system,
|
||||
tools=tools,
|
||||
max_tokens=max_tokens,
|
||||
)
|
||||
except Exception as e:
|
||||
yield StreamErrorEvent(error=str(e), recoverable=False)
|
||||
return
|
||||
|
||||
raw_response = response.raw_response if isinstance(response.raw_response, dict) else {}
|
||||
tool_calls = raw_response.get("tool_calls", [])
|
||||
|
||||
if response.content:
|
||||
yield TextDeltaEvent(content=response.content, snapshot=response.content)
|
||||
yield TextEndEvent(full_text=response.content)
|
||||
|
||||
for tool_call in tool_calls:
|
||||
yield ToolCallEvent(
|
||||
tool_use_id=tool_call["id"],
|
||||
tool_name=tool_call["name"],
|
||||
tool_input=tool_call["input"],
|
||||
)
|
||||
|
||||
yield FinishEvent(
|
||||
stop_reason=response.stop_reason,
|
||||
input_tokens=response.input_tokens,
|
||||
output_tokens=response.output_tokens,
|
||||
model=response.model,
|
||||
)
|
||||
|
||||
async def _stream_via_nonstream_completion(
|
||||
self,
|
||||
messages: list[dict[str, Any]],
|
||||
@@ -882,12 +1492,11 @@ class LiteLLMProvider(LLMProvider):
|
||||
tool_calls = msg.tool_calls or []
|
||||
|
||||
for tc in tool_calls:
|
||||
parsed_args: Any
|
||||
args = tc.function.arguments if tc.function else ""
|
||||
try:
|
||||
parsed_args = json.loads(args) if args else {}
|
||||
except json.JSONDecodeError:
|
||||
parsed_args = {"_raw": args}
|
||||
parsed_args = self._parse_tool_call_arguments(
|
||||
args,
|
||||
tc.function.name if tc.function else "",
|
||||
)
|
||||
yield ToolCallEvent(
|
||||
tool_use_id=getattr(tc, "id", ""),
|
||||
tool_name=tc.function.name if tc.function else "",
|
||||
@@ -946,7 +1555,20 @@ class LiteLLMProvider(LLMProvider):
|
||||
yield event
|
||||
return
|
||||
|
||||
if tools and self._is_openrouter_model() and _is_openrouter_tool_compat_cached(self.model):
|
||||
async for event in self._stream_via_openrouter_tool_compat(
|
||||
messages=messages,
|
||||
system=system,
|
||||
tools=tools,
|
||||
max_tokens=max_tokens,
|
||||
):
|
||||
yield event
|
||||
return
|
||||
|
||||
full_messages: list[dict[str, Any]] = []
|
||||
if self._claude_code_oauth:
|
||||
billing = _claude_code_billing_header(messages)
|
||||
full_messages.append({"role": "system", "content": billing})
|
||||
if system:
|
||||
sys_msg: dict[str, Any] = {"role": "system", "content": system}
|
||||
if _model_supports_cache_control(self.model):
|
||||
@@ -984,9 +1606,12 @@ class LiteLLMProvider(LLMProvider):
|
||||
"messages": full_messages,
|
||||
"max_tokens": max_tokens,
|
||||
"stream": True,
|
||||
"stream_options": {"include_usage": True},
|
||||
**self.extra_kwargs,
|
||||
}
|
||||
# stream_options is OpenAI-specific; Anthropic rejects it with 400.
|
||||
# Only include it for providers that support it.
|
||||
if not self._is_anthropic_model():
|
||||
kwargs["stream_options"] = {"include_usage": True}
|
||||
if self.api_key:
|
||||
kwargs["api_key"] = self.api_key
|
||||
if self.api_base:
|
||||
@@ -1092,10 +1717,10 @@ class LiteLLMProvider(LLMProvider):
|
||||
if choice.finish_reason:
|
||||
stream_finish_reason = choice.finish_reason
|
||||
for _idx, tc_data in sorted(tool_calls_acc.items()):
|
||||
try:
|
||||
parsed_args = json.loads(tc_data["arguments"])
|
||||
except (json.JSONDecodeError, KeyError):
|
||||
parsed_args = {"_raw": tc_data.get("arguments", "")}
|
||||
parsed_args = self._parse_tool_call_arguments(
|
||||
tc_data.get("arguments", ""),
|
||||
tc_data.get("name", ""),
|
||||
)
|
||||
tail_events.append(
|
||||
ToolCallEvent(
|
||||
tool_use_id=tc_data["id"],
|
||||
@@ -1276,6 +1901,16 @@ class LiteLLMProvider(LLMProvider):
|
||||
return
|
||||
|
||||
except Exception as e:
|
||||
if self._should_use_openrouter_tool_compat(e, tools):
|
||||
_remember_openrouter_tool_compat_model(self.model)
|
||||
async for event in self._stream_via_openrouter_tool_compat(
|
||||
messages=messages,
|
||||
system=system,
|
||||
tools=tools or [],
|
||||
max_tokens=max_tokens,
|
||||
):
|
||||
yield event
|
||||
return
|
||||
if _is_stream_transient_error(e) and attempt < RATE_LIMIT_MAX_RETRIES:
|
||||
wait = _compute_retry_delay(attempt, exception=e)
|
||||
logger.warning(
|
||||
|
||||
@@ -208,7 +208,12 @@ def configure_logging(
|
||||
|
||||
# Suppress noisy LiteLLM INFO logs (model/provider line + Provider List URL
|
||||
# printed on every single completion call). Warnings and errors still show.
|
||||
logging.getLogger("LiteLLM").setLevel(logging.WARNING)
|
||||
# Honour LITELLM_LOG env var so users can opt-in to debug output.
|
||||
_litellm_level = os.getenv("LITELLM_LOG", "").upper()
|
||||
if _litellm_level and hasattr(logging, _litellm_level):
|
||||
logging.getLogger("LiteLLM").setLevel(getattr(logging, _litellm_level))
|
||||
else:
|
||||
logging.getLogger("LiteLLM").setLevel(logging.WARNING)
|
||||
|
||||
# When in JSON mode, configure known third-party loggers to use JSON formatter
|
||||
# This ensures libraries like LiteLLM, httpcore also output clean JSON
|
||||
|
||||
@@ -1381,6 +1381,8 @@ class AgentRunner:
|
||||
return "MISTRAL_API_KEY"
|
||||
elif model_lower.startswith("groq/"):
|
||||
return "GROQ_API_KEY"
|
||||
elif model_lower.startswith("openrouter/"):
|
||||
return "OPENROUTER_API_KEY"
|
||||
elif self._is_local_model(model_lower):
|
||||
return None # Local models don't need an API key
|
||||
elif model_lower.startswith("azure/"):
|
||||
|
||||
Generated
+8
@@ -60,6 +60,7 @@
|
||||
"integrity": "sha512-CGOfOJqWjg2qW/Mb6zNsDm+u5vFQ8DxXfbM09z69p5Z6+mE1ikP2jUXw+j42Pf1XTYED2Rni5f95npYeuwMDQA==",
|
||||
"dev": true,
|
||||
"license": "MIT",
|
||||
"peer": true,
|
||||
"dependencies": {
|
||||
"@babel/code-frame": "^7.29.0",
|
||||
"@babel/generator": "^7.29.0",
|
||||
@@ -1556,6 +1557,7 @@
|
||||
"integrity": "sha512-4K3bqJpXpqfg2XKGK9bpDTc6xO/xoUP/RBWS7AtRMug6zZFaRekiLzjVtAoZMquxoAbzBvy5nxQ7veS5eYzf8A==",
|
||||
"dev": true,
|
||||
"license": "MIT",
|
||||
"peer": true,
|
||||
"dependencies": {
|
||||
"undici-types": "~7.18.0"
|
||||
}
|
||||
@@ -1571,6 +1573,7 @@
|
||||
"resolved": "https://registry.npmjs.org/@types/react/-/react-18.3.28.tgz",
|
||||
"integrity": "sha512-z9VXpC7MWrhfWipitjNdgCauoMLRdIILQsAEV+ZesIzBq/oUlxk0m3ApZuMFCXdnS4U7KrI+l3WRUEGQ8K1QKw==",
|
||||
"license": "MIT",
|
||||
"peer": true,
|
||||
"dependencies": {
|
||||
"@types/prop-types": "*",
|
||||
"csstype": "^3.2.2"
|
||||
@@ -1783,6 +1786,7 @@
|
||||
}
|
||||
],
|
||||
"license": "MIT",
|
||||
"peer": true,
|
||||
"dependencies": {
|
||||
"baseline-browser-mapping": "^2.9.0",
|
||||
"caniuse-lite": "^1.0.30001759",
|
||||
@@ -3560,6 +3564,7 @@
|
||||
"integrity": "sha512-5gTmgEY/sqK6gFXLIsQNH19lWb4ebPDLA4SdLP7dsWkIXHWlG66oPuVvXSGFPppYZz8ZDZq0dYYrbHfBCVUb1Q==",
|
||||
"dev": true,
|
||||
"license": "MIT",
|
||||
"peer": true,
|
||||
"engines": {
|
||||
"node": ">=12"
|
||||
},
|
||||
@@ -3611,6 +3616,7 @@
|
||||
"resolved": "https://registry.npmjs.org/react/-/react-18.3.1.tgz",
|
||||
"integrity": "sha512-wS+hAgJShR0KhEvPJArfuPVN1+Hz1t0Y6n5jLrGQbkb4urgPE/0Rve+1kMB1v/oWgHgm4WIcV+i7F2pTVj+2iQ==",
|
||||
"license": "MIT",
|
||||
"peer": true,
|
||||
"dependencies": {
|
||||
"loose-envify": "^1.1.0"
|
||||
},
|
||||
@@ -3623,6 +3629,7 @@
|
||||
"resolved": "https://registry.npmjs.org/react-dom/-/react-dom-18.3.1.tgz",
|
||||
"integrity": "sha512-5m4nQKp+rZRb09LNH59GM4BxTh9251/ylbKIbpe7TpGxfJ+9kv6BLkLBXIjjspbgbnIBNqlI23tRnTWT0snUIw==",
|
||||
"license": "MIT",
|
||||
"peer": true,
|
||||
"dependencies": {
|
||||
"loose-envify": "^1.1.0",
|
||||
"scheduler": "^0.23.2"
|
||||
@@ -4183,6 +4190,7 @@
|
||||
"integrity": "sha512-+Oxm7q9hDoLMyJOYfUYBuHQo+dkAloi33apOPP56pzj+vsdJDzr+j1NISE5pyaAuKL4A3UD34qd0lx5+kfKp2g==",
|
||||
"dev": true,
|
||||
"license": "MIT",
|
||||
"peer": true,
|
||||
"dependencies": {
|
||||
"esbuild": "^0.25.0",
|
||||
"fdir": "^6.4.4",
|
||||
|
||||
@@ -0,0 +1,209 @@
|
||||
import importlib.util
|
||||
from pathlib import Path
|
||||
|
||||
|
||||
def _load_check_llm_key_module():
|
||||
module_path = Path(__file__).resolve().parents[2] / "scripts" / "check_llm_key.py"
|
||||
spec = importlib.util.spec_from_file_location("check_llm_key_script", module_path)
|
||||
module = importlib.util.module_from_spec(spec)
|
||||
assert spec.loader is not None
|
||||
spec.loader.exec_module(module)
|
||||
return module
|
||||
|
||||
|
||||
def _run_openrouter_check(monkeypatch, status_code: int):
|
||||
module = _load_check_llm_key_module()
|
||||
calls = {}
|
||||
|
||||
class FakeResponse:
|
||||
def __init__(self, code):
|
||||
self.status_code = code
|
||||
|
||||
class FakeClient:
|
||||
def __init__(self, timeout):
|
||||
calls["timeout"] = timeout
|
||||
|
||||
def __enter__(self):
|
||||
return self
|
||||
|
||||
def __exit__(self, exc_type, exc, tb):
|
||||
return False
|
||||
|
||||
def get(self, endpoint, headers):
|
||||
calls["endpoint"] = endpoint
|
||||
calls["headers"] = headers
|
||||
return FakeResponse(status_code)
|
||||
|
||||
monkeypatch.setattr(module.httpx, "Client", FakeClient)
|
||||
result = module.check_openrouter("test-key")
|
||||
return result, calls
|
||||
|
||||
|
||||
def _run_openrouter_model_check(
|
||||
monkeypatch,
|
||||
status_code: int,
|
||||
payload: dict | None = None,
|
||||
model: str = "openai/gpt-4o-mini",
|
||||
):
|
||||
module = _load_check_llm_key_module()
|
||||
calls = {}
|
||||
|
||||
class FakeResponse:
|
||||
def __init__(self, code):
|
||||
self.status_code = code
|
||||
self._payload = payload
|
||||
self.text = ""
|
||||
|
||||
def json(self):
|
||||
if self._payload is None:
|
||||
raise ValueError("no json")
|
||||
return self._payload
|
||||
|
||||
class FakeClient:
|
||||
def __init__(self, timeout):
|
||||
calls["timeout"] = timeout
|
||||
|
||||
def __enter__(self):
|
||||
return self
|
||||
|
||||
def __exit__(self, exc_type, exc, tb):
|
||||
return False
|
||||
|
||||
def get(self, endpoint, headers):
|
||||
calls["endpoint"] = endpoint
|
||||
calls["headers"] = headers
|
||||
return FakeResponse(status_code)
|
||||
|
||||
monkeypatch.setattr(module.httpx, "Client", FakeClient)
|
||||
result = module.check_openrouter_model("test-key", model)
|
||||
return result, calls
|
||||
|
||||
|
||||
def test_check_openrouter_200(monkeypatch):
|
||||
result, calls = _run_openrouter_check(monkeypatch, 200)
|
||||
assert result == {"valid": True, "message": "OpenRouter API key valid"}
|
||||
assert calls["endpoint"] == "https://openrouter.ai/api/v1/models"
|
||||
assert calls["headers"] == {"Authorization": "Bearer test-key"}
|
||||
|
||||
|
||||
def test_check_openrouter_401(monkeypatch):
|
||||
result, _ = _run_openrouter_check(monkeypatch, 401)
|
||||
assert result == {"valid": False, "message": "Invalid OpenRouter API key"}
|
||||
|
||||
|
||||
def test_check_openrouter_403(monkeypatch):
|
||||
result, _ = _run_openrouter_check(monkeypatch, 403)
|
||||
assert result == {"valid": False, "message": "OpenRouter API key lacks permissions"}
|
||||
|
||||
|
||||
def test_check_openrouter_429(monkeypatch):
|
||||
result, _ = _run_openrouter_check(monkeypatch, 429)
|
||||
assert result == {"valid": True, "message": "OpenRouter API key valid"}
|
||||
|
||||
|
||||
def test_check_openrouter_model_200(monkeypatch):
|
||||
result, calls = _run_openrouter_model_check(
|
||||
monkeypatch,
|
||||
200,
|
||||
{
|
||||
"data": [
|
||||
{
|
||||
"id": "openai/gpt-4o-mini",
|
||||
"canonical_slug": "openai/gpt-4o-mini",
|
||||
}
|
||||
]
|
||||
},
|
||||
)
|
||||
assert result == {
|
||||
"valid": True,
|
||||
"message": "OpenRouter model is available: openai/gpt-4o-mini",
|
||||
"model": "openai/gpt-4o-mini",
|
||||
}
|
||||
assert calls["endpoint"] == "https://openrouter.ai/api/v1/models/user"
|
||||
assert calls["headers"] == {"Authorization": "Bearer test-key"}
|
||||
|
||||
|
||||
def test_check_openrouter_model_200_matches_canonical_slug(monkeypatch):
|
||||
result, _ = _run_openrouter_model_check(
|
||||
monkeypatch,
|
||||
200,
|
||||
{
|
||||
"data": [
|
||||
{
|
||||
"id": "mistralai/mistral-small-4",
|
||||
"canonical_slug": "mistralai/mistral-small-2603",
|
||||
}
|
||||
]
|
||||
},
|
||||
model="mistralai/mistral-small-2603",
|
||||
)
|
||||
assert result == {
|
||||
"valid": True,
|
||||
"message": "OpenRouter model is available: mistralai/mistral-small-2603",
|
||||
"model": "mistralai/mistral-small-2603",
|
||||
}
|
||||
|
||||
|
||||
def test_check_openrouter_model_200_sanitizes_pasted_unicode(monkeypatch):
|
||||
result, _ = _run_openrouter_model_check(
|
||||
monkeypatch,
|
||||
200,
|
||||
{
|
||||
"data": [
|
||||
{
|
||||
"id": "z-ai/glm-5-turbo",
|
||||
"canonical_slug": "z-ai/glm-5-turbo",
|
||||
}
|
||||
]
|
||||
},
|
||||
model="openrouter/z-ai\u200b/glm\u20115\u2011turbo",
|
||||
)
|
||||
assert result == {
|
||||
"valid": True,
|
||||
"message": "OpenRouter model is available: z-ai/glm-5-turbo",
|
||||
"model": "z-ai/glm-5-turbo",
|
||||
}
|
||||
|
||||
|
||||
def test_check_openrouter_model_200_not_found_with_suggestions(monkeypatch):
|
||||
result, _ = _run_openrouter_model_check(
|
||||
monkeypatch,
|
||||
200,
|
||||
{
|
||||
"data": [
|
||||
{"id": "z-ai/glm-5-turbo"},
|
||||
{"id": "z-ai/glm-4.6v"},
|
||||
]
|
||||
},
|
||||
model="z-ai/glm-5-turb",
|
||||
)
|
||||
assert result == {
|
||||
"valid": False,
|
||||
"message": (
|
||||
"OpenRouter model is not available for this key/settings: z-ai/glm-5-turb. "
|
||||
"Closest matches: z-ai/glm-5-turbo"
|
||||
),
|
||||
}
|
||||
|
||||
|
||||
def test_check_openrouter_model_404_with_error_message(monkeypatch):
|
||||
result, _ = _run_openrouter_model_check(
|
||||
monkeypatch,
|
||||
404,
|
||||
{"error": {"message": "No endpoints available for this model"}},
|
||||
)
|
||||
assert result == {
|
||||
"valid": False,
|
||||
"message": (
|
||||
"OpenRouter model is not available for this key/settings: openai/gpt-4o-mini. "
|
||||
"No endpoints available for this model"
|
||||
),
|
||||
}
|
||||
|
||||
|
||||
def test_check_openrouter_model_429(monkeypatch):
|
||||
result, _ = _run_openrouter_model_check(monkeypatch, 429)
|
||||
assert result == {
|
||||
"valid": True,
|
||||
"message": "OpenRouter model check rate-limited; assuming model is reachable",
|
||||
}
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
import logging
|
||||
|
||||
from framework.config import get_hive_config
|
||||
from framework.config import get_api_base, get_hive_config, get_preferred_model
|
||||
|
||||
|
||||
class TestGetHiveConfig:
|
||||
@@ -21,3 +21,47 @@ class TestGetHiveConfig:
|
||||
assert result == {}
|
||||
assert "Failed to load Hive config" in caplog.text
|
||||
assert str(config_file) in caplog.text
|
||||
|
||||
|
||||
class TestOpenRouterConfig:
|
||||
"""OpenRouter config composition and fallback behavior."""
|
||||
|
||||
def test_get_preferred_model_for_openrouter(self, tmp_path, monkeypatch):
|
||||
config_file = tmp_path / "configuration.json"
|
||||
config_file.write_text(
|
||||
'{"llm":{"provider":"openrouter","model":"x-ai/grok-4.20-beta"}}',
|
||||
encoding="utf-8",
|
||||
)
|
||||
monkeypatch.setattr("framework.config.HIVE_CONFIG_FILE", config_file)
|
||||
|
||||
assert get_preferred_model() == "openrouter/x-ai/grok-4.20-beta"
|
||||
|
||||
def test_get_preferred_model_normalizes_openrouter_prefixed_model(self, tmp_path, monkeypatch):
|
||||
config_file = tmp_path / "configuration.json"
|
||||
config_file.write_text(
|
||||
'{"llm":{"provider":"openrouter","model":"openrouter/x-ai/grok-4.20-beta"}}',
|
||||
encoding="utf-8",
|
||||
)
|
||||
monkeypatch.setattr("framework.config.HIVE_CONFIG_FILE", config_file)
|
||||
|
||||
assert get_preferred_model() == "openrouter/x-ai/grok-4.20-beta"
|
||||
|
||||
def test_get_api_base_falls_back_to_openrouter_default(self, tmp_path, monkeypatch):
|
||||
config_file = tmp_path / "configuration.json"
|
||||
config_file.write_text(
|
||||
'{"llm":{"provider":"openrouter","model":"x-ai/grok-4.20-beta"}}',
|
||||
encoding="utf-8",
|
||||
)
|
||||
monkeypatch.setattr("framework.config.HIVE_CONFIG_FILE", config_file)
|
||||
|
||||
assert get_api_base() == "https://openrouter.ai/api/v1"
|
||||
|
||||
def test_get_api_base_keeps_explicit_openrouter_api_base(self, tmp_path, monkeypatch):
|
||||
config_file = tmp_path / "configuration.json"
|
||||
config_file.write_text(
|
||||
'{"llm":{"provider":"openrouter","model":"x-ai/grok-4.20-beta","api_base":"https://proxy.example/v1"}}',
|
||||
encoding="utf-8",
|
||||
)
|
||||
monkeypatch.setattr("framework.config.HIVE_CONFIG_FILE", config_file)
|
||||
|
||||
assert get_api_base() == "https://proxy.example/v1"
|
||||
|
||||
@@ -0,0 +1,70 @@
|
||||
import os
|
||||
import sys
|
||||
from types import ModuleType, SimpleNamespace
|
||||
|
||||
from framework.credentials import key_storage
|
||||
from framework.credentials.validation import ensure_credential_key_env
|
||||
|
||||
|
||||
def _install_fake_aden_modules(monkeypatch, check_fn, credential_specs):
|
||||
shell_config_module = ModuleType("aden_tools.credentials.shell_config")
|
||||
shell_config_module.check_env_var_in_shell_config = check_fn
|
||||
|
||||
credentials_module = ModuleType("aden_tools.credentials")
|
||||
credentials_module.CREDENTIAL_SPECS = credential_specs
|
||||
|
||||
monkeypatch.setitem(sys.modules, "aden_tools.credentials.shell_config", shell_config_module)
|
||||
monkeypatch.setitem(sys.modules, "aden_tools.credentials", credentials_module)
|
||||
|
||||
|
||||
def test_bootstrap_loads_configured_llm_env_var_from_shell_config(monkeypatch):
|
||||
monkeypatch.setattr(key_storage, "load_credential_key", lambda: None)
|
||||
monkeypatch.setattr(key_storage, "load_aden_api_key", lambda: None)
|
||||
monkeypatch.setattr(
|
||||
"framework.config.get_hive_config",
|
||||
lambda: {"llm": {"api_key_env_var": "OPENROUTER_API_KEY"}},
|
||||
)
|
||||
monkeypatch.delenv("OPENROUTER_API_KEY", raising=False)
|
||||
monkeypatch.delenv("ANTHROPIC_API_KEY", raising=False)
|
||||
|
||||
calls = []
|
||||
|
||||
def check_env(var_name):
|
||||
calls.append(var_name)
|
||||
if var_name == "OPENROUTER_API_KEY":
|
||||
return True, "or-key-123"
|
||||
return False, None
|
||||
|
||||
_install_fake_aden_modules(
|
||||
monkeypatch,
|
||||
check_env,
|
||||
{"anthropic": SimpleNamespace(env_var="ANTHROPIC_API_KEY")},
|
||||
)
|
||||
|
||||
ensure_credential_key_env()
|
||||
|
||||
assert os.environ.get("OPENROUTER_API_KEY") == "or-key-123"
|
||||
assert "OPENROUTER_API_KEY" in calls
|
||||
|
||||
|
||||
def test_bootstrap_does_not_override_existing_configured_llm_env_var(monkeypatch):
|
||||
monkeypatch.setattr(key_storage, "load_credential_key", lambda: None)
|
||||
monkeypatch.setattr(key_storage, "load_aden_api_key", lambda: None)
|
||||
monkeypatch.setattr(
|
||||
"framework.config.get_hive_config",
|
||||
lambda: {"llm": {"api_key_env_var": "OPENROUTER_API_KEY"}},
|
||||
)
|
||||
monkeypatch.setenv("OPENROUTER_API_KEY", "already-set")
|
||||
|
||||
calls = []
|
||||
|
||||
def check_env(var_name):
|
||||
calls.append(var_name)
|
||||
return True, "new-value-should-not-apply"
|
||||
|
||||
_install_fake_aden_modules(monkeypatch, check_env, {})
|
||||
|
||||
ensure_credential_key_env()
|
||||
|
||||
assert os.environ.get("OPENROUTER_API_KEY") == "already-set"
|
||||
assert "OPENROUTER_API_KEY" not in calls
|
||||
@@ -1530,6 +1530,34 @@ class TestTransientErrorRetry:
|
||||
await node.execute(ctx)
|
||||
assert llm._call_index == 1 # only tried once
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_client_facing_non_transient_error_does_not_crash(
|
||||
self, runtime, node_spec, memory
|
||||
):
|
||||
"""Client-facing non-transient errors should wait for input, not crash on token vars."""
|
||||
node_spec.output_keys = []
|
||||
node_spec.client_facing = True
|
||||
llm = ErrorThenSuccessLLM(
|
||||
error=ValueError("bad request: blocked by policy"),
|
||||
fail_count=100, # always fails
|
||||
success_scenario=text_scenario("unreachable"),
|
||||
)
|
||||
ctx = build_ctx(runtime, node_spec, memory, llm)
|
||||
node = EventLoopNode(
|
||||
config=LoopConfig(
|
||||
max_iterations=1,
|
||||
max_stream_retries=0,
|
||||
stream_retry_backoff_base=0.01,
|
||||
),
|
||||
)
|
||||
node._await_user_input = AsyncMock(return_value=None)
|
||||
|
||||
result = await node.execute(ctx)
|
||||
|
||||
assert result.success is False
|
||||
assert "Max iterations" in (result.error or "")
|
||||
node._await_user_input.assert_awaited_once()
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_transient_error_exhausts_retries(self, runtime, node_spec, memory):
|
||||
"""Transient errors that exhaust retries should raise."""
|
||||
|
||||
@@ -19,7 +19,11 @@ from unittest.mock import AsyncMock, MagicMock, patch
|
||||
import pytest
|
||||
|
||||
from framework.llm.anthropic import AnthropicProvider
|
||||
from framework.llm.litellm import LiteLLMProvider, _compute_retry_delay
|
||||
from framework.llm.litellm import (
|
||||
OPENROUTER_TOOL_COMPAT_MODEL_CACHE,
|
||||
LiteLLMProvider,
|
||||
_compute_retry_delay,
|
||||
)
|
||||
from framework.llm.provider import LLMProvider, LLMResponse, Tool
|
||||
|
||||
|
||||
@@ -72,6 +76,20 @@ class TestLiteLLMProviderInit:
|
||||
)
|
||||
assert provider.api_base == "https://proxy.example/v1"
|
||||
|
||||
def test_init_openrouter_defaults_api_base(self):
|
||||
"""OpenRouter should default to the official OpenAI-compatible endpoint."""
|
||||
provider = LiteLLMProvider(model="openrouter/x-ai/grok-4.20-beta", api_key="my-key")
|
||||
assert provider.api_base == "https://openrouter.ai/api/v1"
|
||||
|
||||
def test_init_openrouter_keeps_custom_api_base(self):
|
||||
"""Explicit api_base should win over OpenRouter defaults."""
|
||||
provider = LiteLLMProvider(
|
||||
model="openrouter/x-ai/grok-4.20-beta",
|
||||
api_key="my-key",
|
||||
api_base="https://proxy.example/v1",
|
||||
)
|
||||
assert provider.api_base == "https://proxy.example/v1"
|
||||
|
||||
def test_init_ollama_no_key_needed(self):
|
||||
"""Test that Ollama models don't require API key."""
|
||||
with patch.dict(os.environ, {}, clear=True):
|
||||
@@ -192,6 +210,34 @@ class TestToolConversion:
|
||||
assert result["function"]["parameters"]["properties"]["query"]["type"] == "string"
|
||||
assert result["function"]["parameters"]["required"] == ["query"]
|
||||
|
||||
def test_parse_tool_call_arguments_repairs_truncated_json(self):
|
||||
"""Truncated JSON fragments should be repaired into valid tool inputs."""
|
||||
provider = LiteLLMProvider(model="gpt-4o-mini", api_key="test-key")
|
||||
|
||||
parsed = provider._parse_tool_call_arguments(
|
||||
(
|
||||
'{"question":"What story structure should the agent use?",'
|
||||
'"options":["3-act structure","Beginning-Middle-End","Random paragraph"'
|
||||
),
|
||||
"ask_user",
|
||||
)
|
||||
|
||||
assert parsed == {
|
||||
"question": "What story structure should the agent use?",
|
||||
"options": [
|
||||
"3-act structure",
|
||||
"Beginning-Middle-End",
|
||||
"Random paragraph",
|
||||
],
|
||||
}
|
||||
|
||||
def test_parse_tool_call_arguments_raises_when_unrepairable(self):
|
||||
"""Completely invalid JSON should fail fast instead of producing _raw loops."""
|
||||
provider = LiteLLMProvider(model="gpt-4o-mini", api_key="test-key")
|
||||
|
||||
with pytest.raises(ValueError, match="Failed to parse tool call arguments"):
|
||||
provider._parse_tool_call_arguments('{"question": foo', "ask_user")
|
||||
|
||||
|
||||
class TestAnthropicProviderBackwardCompatibility:
|
||||
"""Test AnthropicProvider backward compatibility with LiteLLM backend."""
|
||||
@@ -682,6 +728,315 @@ class TestMiniMaxStreamFallback:
|
||||
assert not LiteLLMProvider(model="gpt-4o-mini", api_key="x")._is_minimax_model()
|
||||
|
||||
|
||||
class TestOpenRouterToolCompatFallback:
|
||||
"""OpenRouter models should fall back when native tool use is unavailable."""
|
||||
|
||||
def teardown_method(self):
|
||||
OPENROUTER_TOOL_COMPAT_MODEL_CACHE.clear()
|
||||
|
||||
@pytest.mark.asyncio
|
||||
@patch("litellm.acompletion")
|
||||
async def test_stream_falls_back_to_json_tool_emulation(self, mock_acompletion):
|
||||
"""OpenRouter tool-use 404s should emit synthetic ToolCallEvents instead of errors."""
|
||||
from framework.llm.stream_events import FinishEvent, ToolCallEvent
|
||||
|
||||
provider = LiteLLMProvider(
|
||||
model="openrouter/liquid/lfm-2.5-1.2b-thinking:free",
|
||||
api_key="test-key",
|
||||
)
|
||||
tools = [
|
||||
Tool(
|
||||
name="web_search",
|
||||
description="Search the web",
|
||||
parameters={
|
||||
"properties": {
|
||||
"query": {"type": "string"},
|
||||
"num_results": {"type": "integer"},
|
||||
},
|
||||
"required": ["query"],
|
||||
},
|
||||
)
|
||||
]
|
||||
|
||||
compat_response = MagicMock()
|
||||
compat_response.choices = [MagicMock()]
|
||||
compat_response.choices[0].message.content = (
|
||||
'{"assistant_response":"","tool_calls":['
|
||||
'{"name":"web_search","arguments":'
|
||||
'{"query":"Python 3.13 release notes","num_results":3}}'
|
||||
"]}"
|
||||
)
|
||||
compat_response.choices[0].finish_reason = "stop"
|
||||
compat_response.model = provider.model
|
||||
compat_response.usage.prompt_tokens = 18
|
||||
compat_response.usage.completion_tokens = 9
|
||||
|
||||
async def side_effect(*args, **kwargs):
|
||||
if kwargs.get("stream"):
|
||||
raise RuntimeError(
|
||||
'OpenrouterException - {"error":{"message":"No endpoints found '
|
||||
"that support tool use. To learn more about provider routing, "
|
||||
'visit: https://openrouter.ai/docs/guides/routing/provider-selection",'
|
||||
'"code":404}}'
|
||||
)
|
||||
return compat_response
|
||||
|
||||
mock_acompletion.side_effect = side_effect
|
||||
|
||||
events = []
|
||||
async for event in provider.stream(
|
||||
messages=[{"role": "user", "content": "Search for the Python 3.13 release notes."}],
|
||||
system="Use tools when needed.",
|
||||
tools=tools,
|
||||
max_tokens=256,
|
||||
):
|
||||
events.append(event)
|
||||
|
||||
tool_calls = [event for event in events if isinstance(event, ToolCallEvent)]
|
||||
assert len(tool_calls) == 1
|
||||
assert tool_calls[0].tool_name == "web_search"
|
||||
assert tool_calls[0].tool_input == {
|
||||
"query": "Python 3.13 release notes",
|
||||
"num_results": 3,
|
||||
}
|
||||
assert tool_calls[0].tool_use_id.startswith("openrouter_compat_")
|
||||
|
||||
finish_events = [event for event in events if isinstance(event, FinishEvent)]
|
||||
assert len(finish_events) == 1
|
||||
assert finish_events[0].stop_reason == "tool_calls"
|
||||
assert finish_events[0].input_tokens == 18
|
||||
assert finish_events[0].output_tokens == 9
|
||||
|
||||
assert mock_acompletion.call_count == 2
|
||||
first_call = mock_acompletion.call_args_list[0].kwargs
|
||||
assert first_call["stream"] is True
|
||||
assert "tools" in first_call
|
||||
|
||||
second_call = mock_acompletion.call_args_list[1].kwargs
|
||||
assert "tools" not in second_call
|
||||
assert "Tool compatibility mode is active" in second_call["messages"][0]["content"]
|
||||
assert provider.model in OPENROUTER_TOOL_COMPAT_MODEL_CACHE
|
||||
|
||||
@pytest.mark.asyncio
|
||||
@patch("litellm.acompletion")
|
||||
async def test_stream_tool_compat_parses_textual_tool_calls_and_uses_cache(
|
||||
self,
|
||||
mock_acompletion,
|
||||
):
|
||||
"""Textual tool-call markers should become ToolCallEvents and skip repeat probing."""
|
||||
from framework.llm.stream_events import ToolCallEvent
|
||||
|
||||
provider = LiteLLMProvider(
|
||||
model="openrouter/liquid/lfm-2.5-1.2b-thinking:free",
|
||||
api_key="test-key",
|
||||
)
|
||||
tools = [
|
||||
Tool(
|
||||
name="ask_user_multiple",
|
||||
description="Ask the user a multiple-choice question",
|
||||
parameters={
|
||||
"properties": {
|
||||
"options": {"type": "array"},
|
||||
"question": {"type": "string"},
|
||||
"prompt": {"type": "string"},
|
||||
},
|
||||
"required": ["options", "question", "prompt"],
|
||||
},
|
||||
)
|
||||
]
|
||||
|
||||
compat_response = MagicMock()
|
||||
compat_response.choices = [MagicMock()]
|
||||
compat_response.choices[0].message.content = (
|
||||
"<|tool_call_start|>"
|
||||
"[ask_user_multiple(options=['Quartet Collaborator', 'Project Advisor'], "
|
||||
"question='Who are you?', prompt='Who are you?')]"
|
||||
"<|tool_call_end|>"
|
||||
)
|
||||
compat_response.choices[0].finish_reason = "stop"
|
||||
compat_response.model = provider.model
|
||||
compat_response.usage.prompt_tokens = 10
|
||||
compat_response.usage.completion_tokens = 5
|
||||
|
||||
call_state = {"count": 0}
|
||||
|
||||
async def side_effect(*args, **kwargs):
|
||||
call_state["count"] += 1
|
||||
if kwargs.get("stream"):
|
||||
raise RuntimeError(
|
||||
'OpenrouterException - {"error":{"message":"No endpoints found '
|
||||
'that support tool use.","code":404}}'
|
||||
)
|
||||
return compat_response
|
||||
|
||||
mock_acompletion.side_effect = side_effect
|
||||
|
||||
first_events = []
|
||||
async for event in provider.stream(
|
||||
messages=[{"role": "user", "content": "Who are you?"}],
|
||||
system="Use tools when needed.",
|
||||
tools=tools,
|
||||
max_tokens=128,
|
||||
):
|
||||
first_events.append(event)
|
||||
|
||||
tool_calls = [event for event in first_events if isinstance(event, ToolCallEvent)]
|
||||
assert len(tool_calls) == 1
|
||||
assert tool_calls[0].tool_name == "ask_user_multiple"
|
||||
assert tool_calls[0].tool_input == {
|
||||
"options": ["Quartet Collaborator", "Project Advisor"],
|
||||
"question": "Who are you?",
|
||||
"prompt": "Who are you?",
|
||||
}
|
||||
|
||||
second_events = []
|
||||
async for event in provider.stream(
|
||||
messages=[{"role": "user", "content": "Who are you?"}],
|
||||
system="Use tools when needed.",
|
||||
tools=tools,
|
||||
max_tokens=128,
|
||||
):
|
||||
second_events.append(event)
|
||||
|
||||
second_tool_calls = [event for event in second_events if isinstance(event, ToolCallEvent)]
|
||||
assert len(second_tool_calls) == 1
|
||||
assert mock_acompletion.call_count == 3
|
||||
assert mock_acompletion.call_args_list[0].kwargs["stream"] is True
|
||||
assert "stream" not in mock_acompletion.call_args_list[1].kwargs
|
||||
assert "stream" not in mock_acompletion.call_args_list[2].kwargs
|
||||
|
||||
@pytest.mark.asyncio
|
||||
@patch("litellm.acompletion")
|
||||
async def test_stream_tool_compat_parses_plain_text_tool_call_lines(
|
||||
self,
|
||||
mock_acompletion,
|
||||
):
|
||||
"""Plain textual tool-call lines should execute as tools, not user-visible text."""
|
||||
from framework.llm.stream_events import FinishEvent, TextDeltaEvent, ToolCallEvent
|
||||
|
||||
provider = LiteLLMProvider(
|
||||
model="openrouter/liquid/lfm-2.5-1.2b-thinking:free",
|
||||
api_key="test-key",
|
||||
)
|
||||
tools = [
|
||||
Tool(
|
||||
name="ask_user",
|
||||
description="Ask the user a single multiple-choice question",
|
||||
parameters={
|
||||
"properties": {
|
||||
"question": {"type": "string"},
|
||||
"options": {"type": "array"},
|
||||
},
|
||||
"required": ["question", "options"],
|
||||
},
|
||||
)
|
||||
]
|
||||
|
||||
compat_response = MagicMock()
|
||||
compat_response.choices = [MagicMock()]
|
||||
compat_response.choices[0].message.content = (
|
||||
"Queen has been loaded. It's ready to assist with your planning needs.\n\n"
|
||||
"ask_user('What would you like to do?', ['Define a new agent', "
|
||||
"'Diagnose an existing agent', 'Explore tools'])"
|
||||
)
|
||||
compat_response.choices[0].finish_reason = "stop"
|
||||
compat_response.model = provider.model
|
||||
compat_response.usage.prompt_tokens = 11
|
||||
compat_response.usage.completion_tokens = 7
|
||||
|
||||
async def side_effect(*args, **kwargs):
|
||||
if kwargs.get("stream"):
|
||||
raise RuntimeError(
|
||||
'OpenrouterException - {"error":{"message":"No endpoints found '
|
||||
'that support tool use.","code":404}}'
|
||||
)
|
||||
return compat_response
|
||||
|
||||
mock_acompletion.side_effect = side_effect
|
||||
|
||||
events = []
|
||||
async for event in provider.stream(
|
||||
messages=[{"role": "user", "content": "hello"}],
|
||||
system="Use tools when needed.",
|
||||
tools=tools,
|
||||
max_tokens=128,
|
||||
):
|
||||
events.append(event)
|
||||
|
||||
tool_calls = [event for event in events if isinstance(event, ToolCallEvent)]
|
||||
assert len(tool_calls) == 1
|
||||
assert tool_calls[0].tool_name == "ask_user"
|
||||
assert tool_calls[0].tool_input == {
|
||||
"question": "What would you like to do?",
|
||||
"options": ["Define a new agent", "Diagnose an existing agent", "Explore tools"],
|
||||
}
|
||||
|
||||
text_events = [event for event in events if isinstance(event, TextDeltaEvent)]
|
||||
assert len(text_events) == 1
|
||||
assert "ask_user(" not in text_events[0].snapshot
|
||||
assert text_events[0].snapshot == (
|
||||
"Queen has been loaded. It's ready to assist with your planning needs."
|
||||
)
|
||||
|
||||
finish_events = [event for event in events if isinstance(event, FinishEvent)]
|
||||
assert len(finish_events) == 1
|
||||
assert finish_events[0].stop_reason == "tool_calls"
|
||||
|
||||
@pytest.mark.asyncio
|
||||
@patch("litellm.acompletion")
|
||||
async def test_stream_tool_compat_treats_non_json_as_plain_text(self, mock_acompletion):
|
||||
"""If fallback output is not valid JSON, preserve it as assistant text."""
|
||||
from framework.llm.stream_events import FinishEvent, TextDeltaEvent, ToolCallEvent
|
||||
|
||||
provider = LiteLLMProvider(
|
||||
model="openrouter/liquid/lfm-2.5-1.2b-thinking:free",
|
||||
api_key="test-key",
|
||||
)
|
||||
tools = [
|
||||
Tool(
|
||||
name="web_search",
|
||||
description="Search the web",
|
||||
parameters={"properties": {"query": {"type": "string"}}, "required": ["query"]},
|
||||
)
|
||||
]
|
||||
|
||||
compat_response = MagicMock()
|
||||
compat_response.choices = [MagicMock()]
|
||||
compat_response.choices[0].message.content = "I can answer directly without tools."
|
||||
compat_response.choices[0].finish_reason = "stop"
|
||||
compat_response.model = provider.model
|
||||
compat_response.usage.prompt_tokens = 12
|
||||
compat_response.usage.completion_tokens = 6
|
||||
|
||||
async def side_effect(*args, **kwargs):
|
||||
if kwargs.get("stream"):
|
||||
raise RuntimeError(
|
||||
'OpenrouterException - {"error":{"message":"No endpoints found '
|
||||
'that support tool use.","code":404}}'
|
||||
)
|
||||
return compat_response
|
||||
|
||||
mock_acompletion.side_effect = side_effect
|
||||
|
||||
events = []
|
||||
async for event in provider.stream(
|
||||
messages=[{"role": "user", "content": "Say hello."}],
|
||||
system="Be concise.",
|
||||
tools=tools,
|
||||
max_tokens=128,
|
||||
):
|
||||
events.append(event)
|
||||
|
||||
text_events = [event for event in events if isinstance(event, TextDeltaEvent)]
|
||||
assert len(text_events) == 1
|
||||
assert text_events[0].snapshot == "I can answer directly without tools."
|
||||
assert not any(isinstance(event, ToolCallEvent) for event in events)
|
||||
|
||||
finish_events = [event for event in events if isinstance(event, FinishEvent)]
|
||||
assert len(finish_events) == 1
|
||||
assert finish_events[0].stop_reason == "stop"
|
||||
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# AgentRunner._is_local_model — parameterized tests
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
@@ -21,3 +21,8 @@ def test_minimax_provider_prefix_maps_to_minimax_api_key():
|
||||
def test_minimax_model_name_prefix_maps_to_minimax_api_key():
|
||||
runner = _runner_for_unit_test()
|
||||
assert runner._get_api_key_env_var("minimax-chat") == "MINIMAX_API_KEY"
|
||||
|
||||
|
||||
def test_openrouter_provider_prefix_maps_to_openrouter_api_key():
|
||||
runner = _runner_for_unit_test()
|
||||
assert runner._get_api_key_env_var("openrouter/x-ai/grok-4.20-beta") == "OPENROUTER_API_KEY"
|
||||
|
||||
+137
-21
@@ -778,6 +778,7 @@ $ProviderMap = [ordered]@{
|
||||
GOOGLE_API_KEY = @{ Name = "Google AI"; Id = "google" }
|
||||
GROQ_API_KEY = @{ Name = "Groq"; Id = "groq" }
|
||||
CEREBRAS_API_KEY = @{ Name = "Cerebras"; Id = "cerebras" }
|
||||
OPENROUTER_API_KEY = @{ Name = "OpenRouter"; Id = "openrouter" }
|
||||
MISTRAL_API_KEY = @{ Name = "Mistral"; Id = "mistral" }
|
||||
TOGETHER_API_KEY = @{ Name = "Together AI"; Id = "together" }
|
||||
DEEPSEEK_API_KEY = @{ Name = "DeepSeek"; Id = "deepseek" }
|
||||
@@ -820,9 +821,81 @@ $ModelChoices = @{
|
||||
)
|
||||
}
|
||||
|
||||
function Normalize-OpenRouterModelId {
|
||||
param([string]$ModelId)
|
||||
$normalized = if ($ModelId) { $ModelId.Trim() } else { "" }
|
||||
if ($normalized -match '(?i)^openrouter/(.+)$') {
|
||||
$normalized = $matches[1]
|
||||
}
|
||||
return $normalized
|
||||
}
|
||||
|
||||
function Get-ModelSelection {
|
||||
param([string]$ProviderId)
|
||||
|
||||
if ($ProviderId -eq "openrouter") {
|
||||
$defaultModel = ""
|
||||
if ($PrevModel -and $PrevProvider -eq $ProviderId) {
|
||||
$defaultModel = Normalize-OpenRouterModelId $PrevModel
|
||||
}
|
||||
Write-Host ""
|
||||
Write-Color -Text "Enter your OpenRouter model id:" -Color White
|
||||
Write-Color -Text " Paste from openrouter.ai (example: x-ai/grok-4.20-beta)" -Color DarkGray
|
||||
Write-Color -Text " If calls fail with guardrail/privacy errors: openrouter.ai/settings/privacy" -Color DarkGray
|
||||
Write-Host ""
|
||||
while ($true) {
|
||||
if ($defaultModel) {
|
||||
$rawModel = Read-Host "Model id [$defaultModel]"
|
||||
if ([string]::IsNullOrWhiteSpace($rawModel)) { $rawModel = $defaultModel }
|
||||
} else {
|
||||
$rawModel = Read-Host "Model id"
|
||||
}
|
||||
$normalizedModel = Normalize-OpenRouterModelId $rawModel
|
||||
if (-not [string]::IsNullOrWhiteSpace($normalizedModel)) {
|
||||
$openrouterKey = $null
|
||||
if ($SelectedEnvVar) {
|
||||
$openrouterKey = [System.Environment]::GetEnvironmentVariable($SelectedEnvVar, "Process")
|
||||
if (-not $openrouterKey) {
|
||||
$openrouterKey = [System.Environment]::GetEnvironmentVariable($SelectedEnvVar, "User")
|
||||
}
|
||||
}
|
||||
|
||||
if ($openrouterKey) {
|
||||
Write-Host " Verifying model id... " -NoNewline
|
||||
try {
|
||||
$modelApiBase = if ($SelectedApiBase) { $SelectedApiBase } else { "https://openrouter.ai/api/v1" }
|
||||
$hcResult = & uv run python (Join-Path $ScriptDir "scripts/check_llm_key.py") "openrouter" $openrouterKey $modelApiBase $normalizedModel 2>$null
|
||||
$hcJson = $hcResult | ConvertFrom-Json
|
||||
if ($hcJson.valid -eq $true) {
|
||||
if ($hcJson.model) {
|
||||
$normalizedModel = [string]$hcJson.model
|
||||
}
|
||||
Write-Color -Text "ok" -Color Green
|
||||
} elseif ($hcJson.valid -eq $false) {
|
||||
Write-Color -Text "failed" -Color Red
|
||||
Write-Warn $hcJson.message
|
||||
Write-Host ""
|
||||
continue
|
||||
} else {
|
||||
Write-Color -Text "--" -Color Yellow
|
||||
Write-Color -Text " Could not verify model id (network issue). Continuing with your selection." -Color DarkGray
|
||||
}
|
||||
} catch {
|
||||
Write-Color -Text "--" -Color Yellow
|
||||
Write-Color -Text " Could not verify model id (network issue). Continuing with your selection." -Color DarkGray
|
||||
}
|
||||
} else {
|
||||
Write-Color -Text " Skipping model verification (OpenRouter key not available in current shell)." -Color DarkGray
|
||||
}
|
||||
|
||||
Write-Host ""
|
||||
Write-Ok "Model: $normalizedModel"
|
||||
return @{ Model = $normalizedModel; MaxTokens = 8192; MaxContextTokens = 120000 }
|
||||
}
|
||||
Write-Color -Text "Model id cannot be empty." -Color Red
|
||||
}
|
||||
}
|
||||
|
||||
$choices = $ModelChoices[$ProviderId]
|
||||
if (-not $choices -or $choices.Count -eq 0) {
|
||||
return @{ Model = $DefaultModels[$ProviderId]; MaxTokens = 8192; MaxContextTokens = 120000 }
|
||||
@@ -883,6 +956,7 @@ $SelectedEnvVar = ""
|
||||
$SelectedModel = ""
|
||||
$SelectedMaxTokens = 8192
|
||||
$SelectedMaxContextTokens = 120000
|
||||
$SelectedApiBase = ""
|
||||
$SubscriptionMode = ""
|
||||
|
||||
# ── Credential detection (silent — just set flags) ───────────
|
||||
@@ -912,15 +986,16 @@ if (-not $hiveKey) { $hiveKey = $env:HIVE_API_KEY }
|
||||
if ($hiveKey) { $HiveCredDetected = $true }
|
||||
|
||||
# Detect API key providers
|
||||
$ProviderMenuEnvVars = @("ANTHROPIC_API_KEY", "OPENAI_API_KEY", "GEMINI_API_KEY", "GROQ_API_KEY", "CEREBRAS_API_KEY")
|
||||
$ProviderMenuNames = @("Anthropic (Claude) - Recommended", "OpenAI (GPT)", "Google Gemini - Free tier available", "Groq - Fast, free tier", "Cerebras - Fast, free tier")
|
||||
$ProviderMenuIds = @("anthropic", "openai", "gemini", "groq", "cerebras")
|
||||
$ProviderMenuEnvVars = @("ANTHROPIC_API_KEY", "OPENAI_API_KEY", "GEMINI_API_KEY", "GROQ_API_KEY", "CEREBRAS_API_KEY", "OPENROUTER_API_KEY")
|
||||
$ProviderMenuNames = @("Anthropic (Claude) - Recommended", "OpenAI (GPT)", "Google Gemini - Free tier available", "Groq - Fast, free tier", "Cerebras - Fast, free tier", "OpenRouter - Bring any OpenRouter model")
|
||||
$ProviderMenuIds = @("anthropic", "openai", "gemini", "groq", "cerebras", "openrouter")
|
||||
$ProviderMenuUrls = @(
|
||||
"https://console.anthropic.com/settings/keys",
|
||||
"https://platform.openai.com/api-keys",
|
||||
"https://aistudio.google.com/apikey",
|
||||
"https://console.groq.com/keys",
|
||||
"https://cloud.cerebras.ai/"
|
||||
"https://cloud.cerebras.ai/",
|
||||
"https://openrouter.ai/keys"
|
||||
)
|
||||
|
||||
# ── Read previous configuration (if any) ──────────────────────
|
||||
@@ -979,6 +1054,7 @@ if ($PrevSubMode -or $PrevProvider) {
|
||||
"gemini" { $DefaultChoice = "8" }
|
||||
"groq" { $DefaultChoice = "9" }
|
||||
"cerebras" { $DefaultChoice = "10" }
|
||||
"openrouter" { $DefaultChoice = "11" }
|
||||
"kimi" { $DefaultChoice = "4" }
|
||||
}
|
||||
}
|
||||
@@ -1028,7 +1104,7 @@ if ($HiveCredDetected) { Write-Color -Text " (credential detected)" -Color Gree
|
||||
Write-Host ""
|
||||
Write-Color -Text " API key providers:" -Color Cyan
|
||||
|
||||
# 6-10) API key providers
|
||||
# 6-11) API key providers
|
||||
for ($idx = 0; $idx -lt $ProviderMenuEnvVars.Count; $idx++) {
|
||||
$num = $idx + 6
|
||||
$envVal = [System.Environment]::GetEnvironmentVariable($ProviderMenuEnvVars[$idx], "Process")
|
||||
@@ -1039,8 +1115,9 @@ for ($idx = 0; $idx -lt $ProviderMenuEnvVars.Count; $idx++) {
|
||||
if ($envVal) { Write-Color -Text " (credential detected)" -Color Green } else { Write-Host "" }
|
||||
}
|
||||
|
||||
$SkipChoice = 6 + $ProviderMenuEnvVars.Count
|
||||
Write-Host " " -NoNewline
|
||||
Write-Color -Text "11" -Color Cyan -NoNewline
|
||||
Write-Color -Text "$SkipChoice" -Color Cyan -NoNewline
|
||||
Write-Host ") Skip for now"
|
||||
Write-Host ""
|
||||
|
||||
@@ -1051,16 +1128,16 @@ if ($DefaultChoice) {
|
||||
|
||||
while ($true) {
|
||||
if ($DefaultChoice) {
|
||||
$raw = Read-Host "Enter choice (1-11) [$DefaultChoice]"
|
||||
$raw = Read-Host "Enter choice (1-$SkipChoice) [$DefaultChoice]"
|
||||
if ([string]::IsNullOrWhiteSpace($raw)) { $raw = $DefaultChoice }
|
||||
} else {
|
||||
$raw = Read-Host "Enter choice (1-11)"
|
||||
$raw = Read-Host "Enter choice (1-$SkipChoice)"
|
||||
}
|
||||
if ($raw -match '^\d+$') {
|
||||
$num = [int]$raw
|
||||
if ($num -ge 1 -and $num -le 11) { break }
|
||||
if ($num -ge 1 -and $num -le $SkipChoice) { break }
|
||||
}
|
||||
Write-Color -Text "Invalid choice. Please enter 1-11" -Color Red
|
||||
Write-Color -Text "Invalid choice. Please enter 1-$SkipChoice" -Color Red
|
||||
}
|
||||
|
||||
switch ($num) {
|
||||
@@ -1163,13 +1240,18 @@ switch ($num) {
|
||||
}
|
||||
Write-Color -Text " Model: $SelectedModel | API: $HiveLlmEndpoint" -Color DarkGray
|
||||
}
|
||||
{ $_ -ge 6 -and $_ -le 10 } {
|
||||
{ $_ -ge 6 -and $_ -le 11 } {
|
||||
# API key providers
|
||||
$provIdx = $num - 6
|
||||
$SelectedEnvVar = $ProviderMenuEnvVars[$provIdx]
|
||||
$SelectedProviderId = $ProviderMenuIds[$provIdx]
|
||||
$providerName = $ProviderMenuNames[$provIdx] -replace ' - .*', '' # strip description
|
||||
$signupUrl = $ProviderMenuUrls[$provIdx]
|
||||
if ($SelectedProviderId -eq "openrouter") {
|
||||
$SelectedApiBase = "https://openrouter.ai/api/v1"
|
||||
} else {
|
||||
$SelectedApiBase = ""
|
||||
}
|
||||
|
||||
# Prompt for key (allow replacement if already set) with verification + retry
|
||||
while ($true) {
|
||||
@@ -1198,7 +1280,11 @@ switch ($num) {
|
||||
# Health check the new key
|
||||
Write-Host " Verifying API key... " -NoNewline
|
||||
try {
|
||||
$hcResult = & $UvCmd run python (Join-Path $ScriptDir "scripts/check_llm_key.py") $SelectedProviderId $apiKey 2>$null
|
||||
if ($SelectedApiBase) {
|
||||
$hcResult = & uv run python (Join-Path $ScriptDir "scripts/check_llm_key.py") $SelectedProviderId $apiKey $SelectedApiBase 2>$null
|
||||
} else {
|
||||
$hcResult = & uv run python (Join-Path $ScriptDir "scripts/check_llm_key.py") $SelectedProviderId $apiKey 2>$null
|
||||
}
|
||||
$hcJson = $hcResult | ConvertFrom-Json
|
||||
if ($hcJson.valid -eq $true) {
|
||||
Write-Color -Text "ok" -Color Green
|
||||
@@ -1236,7 +1322,7 @@ switch ($num) {
|
||||
}
|
||||
}
|
||||
}
|
||||
11 {
|
||||
{ $_ -eq $SkipChoice } {
|
||||
Write-Host ""
|
||||
Write-Warn "Skipped. An LLM API key is required to test and use worker agents."
|
||||
Write-Host " Add your API key later by running:"
|
||||
@@ -1484,6 +1570,9 @@ if ($SelectedProviderId) {
|
||||
} elseif ($SubscriptionMode -eq "hive_llm") {
|
||||
$config.llm["api_base"] = $HiveLlmEndpoint
|
||||
$config.llm["api_key_env_var"] = $SelectedEnvVar
|
||||
} elseif ($SelectedProviderId -eq "openrouter") {
|
||||
$config.llm["api_base"] = "https://openrouter.ai/api/v1"
|
||||
$config.llm["api_key_env_var"] = $SelectedEnvVar
|
||||
} else {
|
||||
$config.llm["api_key_env_var"] = $SelectedEnvVar
|
||||
}
|
||||
@@ -1783,6 +1872,9 @@ if ($SelectedProviderId) {
|
||||
Write-Color -Text " API: api.z.ai (OpenAI-compatible)" -Color DarkGray
|
||||
} elseif ($SubscriptionMode -eq "codex") {
|
||||
Write-Ok "OpenAI Codex Subscription -> $SelectedModel"
|
||||
} elseif ($SelectedProviderId -eq "openrouter") {
|
||||
Write-Ok "OpenRouter API Key -> $SelectedModel"
|
||||
Write-Color -Text " API: openrouter.ai/api/v1 (OpenAI-compatible)" -Color DarkGray
|
||||
} else {
|
||||
Write-Color -Text " $SelectedProviderId" -Color Cyan -NoNewline
|
||||
Write-Host " -> " -NoNewline
|
||||
@@ -1813,14 +1905,39 @@ if ($CodexAvailable) {
|
||||
Write-Host ""
|
||||
}
|
||||
|
||||
# Auto-launch dashboard or show manual instructions
|
||||
# Setup-only mode: show manual instructions
|
||||
if ($FrontendBuilt) {
|
||||
Write-Color -Text "Launching dashboard..." -Color White
|
||||
Write-Color -Text "â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•" -Color Yellow
|
||||
Write-Host ""
|
||||
Write-Color -Text " Starting server on http://localhost:8787" -Color DarkGray
|
||||
Write-Color -Text " Press Ctrl+C to stop" -Color DarkGray
|
||||
Write-Color -Text " IMPORTANT: Restart your terminal now!" -Color Yellow
|
||||
Write-Host ""
|
||||
Write-Color -Text "â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•â•" -Color Yellow
|
||||
Write-Host ""
|
||||
Write-Host 'Environment variables (uv, API keys) are now configured, but you need to'
|
||||
Write-Host 'restart your terminal for them to take effect in new sessions.'
|
||||
Write-Host ""
|
||||
|
||||
Write-Color -Text "Run an Agent:" -Color White
|
||||
Write-Host ""
|
||||
Write-Host " Quickstart only sets things up. Launch the dashboard when you're ready:"
|
||||
Write-Color -Text " hive open" -Color Cyan
|
||||
Write-Host ""
|
||||
|
||||
if ($SelectedProviderId -or $credKey) {
|
||||
Write-Color -Text "Note:" -Color White
|
||||
Write-Host "- uv has been added to your User PATH"
|
||||
if ($SelectedProviderId -and $SelectedEnvVar) {
|
||||
Write-Host "- $SelectedEnvVar is set for LLM access"
|
||||
}
|
||||
if ($credKey) {
|
||||
Write-Host "- HIVE_CREDENTIAL_KEY is set for credential encryption"
|
||||
}
|
||||
Write-Host "- All variables will persist across reboots"
|
||||
Write-Host ""
|
||||
}
|
||||
|
||||
Write-Color -Text 'Run .\quickstart.ps1 again to reconfigure.' -Color DarkGray
|
||||
Write-Host ""
|
||||
& (Join-Path $ScriptDir "hive.ps1") open
|
||||
} else {
|
||||
Write-Color -Text "═══════════════════════════════════════════════════════" -Color Yellow
|
||||
Write-Host ""
|
||||
@@ -1834,9 +1951,8 @@ if ($FrontendBuilt) {
|
||||
|
||||
Write-Color -Text "Run an Agent:" -Color White
|
||||
Write-Host ""
|
||||
Write-Host " Launch the interactive dashboard to browse and run agents:"
|
||||
Write-Host " You can start an example agent or an agent built by yourself:"
|
||||
Write-Color -Text " .\hive.ps1 tui" -Color Cyan
|
||||
Write-Host " Frontend build was skipped or failed. Once the dashboard is available, launch it with:"
|
||||
Write-Color -Text " hive open" -Color Cyan
|
||||
Write-Host ""
|
||||
|
||||
if ($SelectedProviderId -or $credKey) {
|
||||
|
||||
+268
-106
@@ -46,7 +46,6 @@ prompt_yes_no() {
|
||||
else
|
||||
prompt="$prompt [y/N] "
|
||||
fi
|
||||
|
||||
read -r -p "$prompt" response
|
||||
response="${response:-$default}"
|
||||
[[ "$response" =~ ^[Yy] ]]
|
||||
@@ -374,6 +373,7 @@ if [ "$USE_ASSOC_ARRAYS" = true ]; then
|
||||
["GOOGLE_API_KEY"]="Google AI"
|
||||
["GROQ_API_KEY"]="Groq"
|
||||
["CEREBRAS_API_KEY"]="Cerebras"
|
||||
["OPENROUTER_API_KEY"]="OpenRouter"
|
||||
["MISTRAL_API_KEY"]="Mistral"
|
||||
["TOGETHER_API_KEY"]="Together AI"
|
||||
["DEEPSEEK_API_KEY"]="DeepSeek"
|
||||
@@ -387,6 +387,7 @@ if [ "$USE_ASSOC_ARRAYS" = true ]; then
|
||||
["GOOGLE_API_KEY"]="google"
|
||||
["GROQ_API_KEY"]="groq"
|
||||
["CEREBRAS_API_KEY"]="cerebras"
|
||||
["OPENROUTER_API_KEY"]="openrouter"
|
||||
["MISTRAL_API_KEY"]="mistral"
|
||||
["TOGETHER_API_KEY"]="together"
|
||||
["DEEPSEEK_API_KEY"]="deepseek"
|
||||
@@ -510,9 +511,9 @@ if [ "$USE_ASSOC_ARRAYS" = true ]; then
|
||||
}
|
||||
else
|
||||
# Bash 3.2 - use parallel indexed arrays
|
||||
PROVIDER_ENV_VARS=(ANTHROPIC_API_KEY OPENAI_API_KEY MINIMAX_API_KEY GEMINI_API_KEY GOOGLE_API_KEY GROQ_API_KEY CEREBRAS_API_KEY MISTRAL_API_KEY TOGETHER_API_KEY DEEPSEEK_API_KEY)
|
||||
PROVIDER_DISPLAY_NAMES=("Anthropic (Claude)" "OpenAI (GPT)" "MiniMax" "Google Gemini" "Google AI" "Groq" "Cerebras" "Mistral" "Together AI" "DeepSeek")
|
||||
PROVIDER_ID_LIST=(anthropic openai minimax gemini google groq cerebras mistral together deepseek)
|
||||
PROVIDER_ENV_VARS=(ANTHROPIC_API_KEY OPENAI_API_KEY MINIMAX_API_KEY GEMINI_API_KEY GOOGLE_API_KEY GROQ_API_KEY CEREBRAS_API_KEY OPENROUTER_API_KEY MISTRAL_API_KEY TOGETHER_API_KEY DEEPSEEK_API_KEY)
|
||||
PROVIDER_DISPLAY_NAMES=("Anthropic (Claude)" "OpenAI (GPT)" "MiniMax" "Google Gemini" "Google AI" "Groq" "Cerebras" "OpenRouter" "Mistral" "Together AI" "DeepSeek")
|
||||
PROVIDER_ID_LIST=(anthropic openai minimax gemini google groq cerebras openrouter mistral together deepseek)
|
||||
|
||||
# Default models by provider id (parallel arrays)
|
||||
MODEL_PROVIDER_IDS=(anthropic openai minimax gemini groq cerebras mistral together_ai deepseek)
|
||||
@@ -690,10 +691,91 @@ detect_shell_rc() {
|
||||
SHELL_RC_FILE=$(detect_shell_rc)
|
||||
SHELL_NAME=$(basename "$SHELL")
|
||||
|
||||
# Normalize user-pasted OpenRouter model IDs:
|
||||
# - trim whitespace
|
||||
# - strip leading "openrouter/" if present
|
||||
normalize_openrouter_model_id() {
|
||||
local raw="$1"
|
||||
# Trim leading/trailing whitespace
|
||||
raw="${raw#"${raw%%[![:space:]]*}"}"
|
||||
raw="${raw%"${raw##*[![:space:]]}"}"
|
||||
if [[ "$raw" =~ ^[Oo][Pp][Ee][Nn][Rr][Oo][Uu][Tt][Ee][Rr]/(.+)$ ]]; then
|
||||
raw="${BASH_REMATCH[1]}"
|
||||
fi
|
||||
printf '%s' "$raw"
|
||||
}
|
||||
|
||||
# Prompt the user to choose a model for their selected provider.
|
||||
# Sets SELECTED_MODEL, SELECTED_MAX_TOKENS, and SELECTED_MAX_CONTEXT_TOKENS.
|
||||
prompt_model_selection() {
|
||||
local provider_id="$1"
|
||||
|
||||
if [ "$provider_id" = "openrouter" ]; then
|
||||
local default_model=""
|
||||
if [ -n "$PREV_MODEL" ] && [ "$provider_id" = "$PREV_PROVIDER" ]; then
|
||||
default_model="$(normalize_openrouter_model_id "$PREV_MODEL")"
|
||||
fi
|
||||
echo ""
|
||||
echo -e "${BOLD}Enter your OpenRouter model id:${NC}"
|
||||
echo -e " ${DIM}Paste from openrouter.ai (example: x-ai/grok-4.20-beta)${NC}"
|
||||
echo -e " ${DIM}If calls fail with guardrail/privacy errors: openrouter.ai/settings/privacy${NC}"
|
||||
echo ""
|
||||
local input_model=""
|
||||
while true; do
|
||||
if [ -n "$default_model" ]; then
|
||||
read -r -p "Model id [$default_model]: " input_model || true
|
||||
input_model="${input_model:-$default_model}"
|
||||
else
|
||||
read -r -p "Model id: " input_model || true
|
||||
fi
|
||||
local normalized_model
|
||||
normalized_model="$(normalize_openrouter_model_id "$input_model")"
|
||||
if [ -n "$normalized_model" ]; then
|
||||
local openrouter_key=""
|
||||
if [ -n "${SELECTED_ENV_VAR:-}" ]; then
|
||||
openrouter_key="${!SELECTED_ENV_VAR:-}"
|
||||
fi
|
||||
|
||||
if [ -n "$openrouter_key" ]; then
|
||||
local model_hc_result=""
|
||||
local model_hc_valid=""
|
||||
local model_hc_msg=""
|
||||
local model_hc_canonical=""
|
||||
local model_hc_base="${SELECTED_API_BASE:-https://openrouter.ai/api/v1}"
|
||||
echo -n " Verifying model id... "
|
||||
model_hc_result="$(uv run python "$SCRIPT_DIR/scripts/check_llm_key.py" "openrouter" "$openrouter_key" "$model_hc_base" "$normalized_model" 2>/dev/null)" || true
|
||||
model_hc_valid="$(echo "$model_hc_result" | $PYTHON_CMD -c "import json,sys; print(json.loads(sys.stdin.read()).get('valid',''))" 2>/dev/null)" || true
|
||||
model_hc_msg="$(echo "$model_hc_result" | $PYTHON_CMD -c "import json,sys; print(json.loads(sys.stdin.read()).get('message',''))" 2>/dev/null)" || true
|
||||
model_hc_canonical="$(echo "$model_hc_result" | $PYTHON_CMD -c "import json,sys; print(json.loads(sys.stdin.read()).get('model',''))" 2>/dev/null)" || true
|
||||
if [ "$model_hc_valid" = "True" ]; then
|
||||
if [ -n "$model_hc_canonical" ]; then
|
||||
normalized_model="$model_hc_canonical"
|
||||
fi
|
||||
echo -e "${GREEN}ok${NC}"
|
||||
elif [ "$model_hc_valid" = "False" ]; then
|
||||
echo -e "${RED}failed${NC}"
|
||||
echo -e " ${YELLOW}⚠ $model_hc_msg${NC}"
|
||||
echo ""
|
||||
continue
|
||||
else
|
||||
echo -e "${YELLOW}--${NC}"
|
||||
echo -e " ${DIM}Could not verify model id (network issue). Continuing with your selection.${NC}"
|
||||
fi
|
||||
else
|
||||
echo -e " ${DIM}Skipping model verification (OpenRouter key not available in current shell).${NC}"
|
||||
fi
|
||||
|
||||
SELECTED_MODEL="$normalized_model"
|
||||
SELECTED_MAX_TOKENS=8192
|
||||
SELECTED_MAX_CONTEXT_TOKENS=120000
|
||||
echo ""
|
||||
echo -e "${GREEN}⬢${NC} Model: ${DIM}$SELECTED_MODEL${NC}"
|
||||
return
|
||||
fi
|
||||
echo -e "${RED}Model id cannot be empty.${NC}"
|
||||
done
|
||||
fi
|
||||
|
||||
local count
|
||||
count="$(get_model_choice_count "$provider_id")"
|
||||
|
||||
@@ -787,34 +869,73 @@ save_configuration() {
|
||||
max_context_tokens=120000
|
||||
fi
|
||||
|
||||
mkdir -p "$HIVE_CONFIG_DIR"
|
||||
|
||||
$PYTHON_CMD -c "
|
||||
uv run python - \
|
||||
"$provider_id" \
|
||||
"$env_var" \
|
||||
"$model" \
|
||||
"$max_tokens" \
|
||||
"$max_context_tokens" \
|
||||
"$use_claude_code_sub" \
|
||||
"$api_base" \
|
||||
"$use_codex_sub" \
|
||||
"$(date -u +"%Y-%m-%dT%H:%M:%S+00:00")" 2>/dev/null <<'PY'
|
||||
import json
|
||||
config = {
|
||||
'llm': {
|
||||
'provider': '$provider_id',
|
||||
'model': '$model',
|
||||
'max_tokens': $max_tokens,
|
||||
'max_context_tokens': $max_context_tokens,
|
||||
'api_key_env_var': '$env_var'
|
||||
},
|
||||
'created_at': '$(date -u +"%Y-%m-%dT%H:%M:%S+00:00")'
|
||||
import sys
|
||||
from pathlib import Path
|
||||
|
||||
(
|
||||
provider_id,
|
||||
env_var,
|
||||
model,
|
||||
max_tokens,
|
||||
max_context_tokens,
|
||||
use_claude_code_sub,
|
||||
api_base,
|
||||
use_codex_sub,
|
||||
created_at,
|
||||
) = sys.argv[1:10]
|
||||
|
||||
cfg_path = Path.home() / ".hive" / "configuration.json"
|
||||
cfg_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
try:
|
||||
with open(cfg_path, encoding="utf-8-sig") as f:
|
||||
config = json.load(f)
|
||||
except (OSError, json.JSONDecodeError):
|
||||
config = {}
|
||||
|
||||
config["llm"] = {
|
||||
"provider": provider_id,
|
||||
"model": model,
|
||||
"max_tokens": int(max_tokens),
|
||||
"max_context_tokens": int(max_context_tokens),
|
||||
"api_key_env_var": env_var,
|
||||
}
|
||||
if '$use_claude_code_sub' == 'true':
|
||||
config['llm']['use_claude_code_subscription'] = True
|
||||
# No api_key_env_var needed for Claude Code subscription
|
||||
config['llm'].pop('api_key_env_var', None)
|
||||
if '$use_codex_sub' == 'true':
|
||||
config['llm']['use_codex_subscription'] = True
|
||||
# No api_key_env_var needed for Codex subscription
|
||||
config['llm'].pop('api_key_env_var', None)
|
||||
if '$api_base':
|
||||
config['llm']['api_base'] = '$api_base'
|
||||
with open('$HIVE_CONFIG_FILE', 'w') as f:
|
||||
config["created_at"] = created_at
|
||||
|
||||
if use_claude_code_sub == "true":
|
||||
config["llm"]["use_claude_code_subscription"] = True
|
||||
config["llm"].pop("api_key_env_var", None)
|
||||
else:
|
||||
config["llm"].pop("use_claude_code_subscription", None)
|
||||
|
||||
if use_codex_sub == "true":
|
||||
config["llm"]["use_codex_subscription"] = True
|
||||
config["llm"].pop("api_key_env_var", None)
|
||||
else:
|
||||
config["llm"].pop("use_codex_subscription", None)
|
||||
|
||||
if api_base:
|
||||
config["llm"]["api_base"] = api_base
|
||||
else:
|
||||
config["llm"].pop("api_base", None)
|
||||
|
||||
tmp_path = cfg_path.with_name(cfg_path.name + ".tmp")
|
||||
with open(tmp_path, "w", encoding="utf-8") as f:
|
||||
json.dump(config, f, indent=2)
|
||||
tmp_path.replace(cfg_path)
|
||||
print(json.dumps(config, indent=2))
|
||||
" 2>/dev/null
|
||||
PY
|
||||
}
|
||||
|
||||
# Source shell rc file to pick up existing env vars (temporarily disable set -e)
|
||||
@@ -895,26 +1016,36 @@ PREV_MODEL=""
|
||||
PREV_ENV_VAR=""
|
||||
PREV_SUB_MODE=""
|
||||
if [ -f "$HIVE_CONFIG_FILE" ]; then
|
||||
eval "$($PYTHON_CMD -c "
|
||||
import json, sys
|
||||
eval "$(uv run python - 2>/dev/null <<'PY'
|
||||
import json
|
||||
from pathlib import Path
|
||||
|
||||
cfg_path = Path.home() / ".hive" / "configuration.json"
|
||||
try:
|
||||
with open('$HIVE_CONFIG_FILE') as f:
|
||||
with open(cfg_path, encoding="utf-8-sig") as f:
|
||||
c = json.load(f)
|
||||
llm = c.get('llm', {})
|
||||
print(f'PREV_PROVIDER={llm.get(\"provider\", \"\")}')
|
||||
print(f'PREV_MODEL={llm.get(\"model\", \"\")}')
|
||||
print(f'PREV_ENV_VAR={llm.get(\"api_key_env_var\", \"\")}')
|
||||
sub = ''
|
||||
if llm.get('use_claude_code_subscription'): sub = 'claude_code'
|
||||
elif llm.get('use_codex_subscription'): sub = 'codex'
|
||||
elif llm.get('use_kimi_code_subscription'): sub = 'kimi_code'
|
||||
elif llm.get('provider', '') == 'minimax' or 'api.minimax.io' in llm.get('api_base', ''): sub = 'minimax_code'
|
||||
elif llm.get('provider', '') == 'hive' or 'adenhq.com' in llm.get('api_base', ''): sub = 'hive_llm'
|
||||
elif 'api.z.ai' in llm.get('api_base', ''): sub = 'zai_code'
|
||||
print(f'PREV_SUB_MODE={sub}')
|
||||
llm = c.get("llm", {})
|
||||
print(f"PREV_PROVIDER={llm.get(\"provider\", \"\")}")
|
||||
print(f"PREV_MODEL={llm.get(\"model\", \"\")}")
|
||||
print(f"PREV_ENV_VAR={llm.get(\"api_key_env_var\", \"\")}")
|
||||
sub = ""
|
||||
if llm.get("use_claude_code_subscription"):
|
||||
sub = "claude_code"
|
||||
elif llm.get("use_codex_subscription"):
|
||||
sub = "codex"
|
||||
elif llm.get("use_kimi_code_subscription"):
|
||||
sub = "kimi_code"
|
||||
elif llm.get("provider", "") == "minimax" or "api.minimax.io" in llm.get("api_base", ""):
|
||||
sub = "minimax_code"
|
||||
elif llm.get("provider", "") == "hive" or "adenhq.com" in llm.get("api_base", ""):
|
||||
sub = "hive_llm"
|
||||
elif "api.z.ai" in llm.get("api_base", ""):
|
||||
sub = "zai_code"
|
||||
print(f"PREV_SUB_MODE={sub}")
|
||||
except Exception:
|
||||
pass
|
||||
" 2>/dev/null)" || true
|
||||
PY
|
||||
)" || true
|
||||
fi
|
||||
|
||||
# Compute default menu number from previous config (only if credential is still valid)
|
||||
@@ -951,6 +1082,7 @@ if [ -n "$PREV_SUB_MODE" ] || [ -n "$PREV_PROVIDER" ]; then
|
||||
gemini) DEFAULT_CHOICE=9 ;;
|
||||
groq) DEFAULT_CHOICE=10 ;;
|
||||
cerebras) DEFAULT_CHOICE=11 ;;
|
||||
openrouter) DEFAULT_CHOICE=12 ;;
|
||||
minimax) DEFAULT_CHOICE=4 ;;
|
||||
kimi) DEFAULT_CHOICE=5 ;;
|
||||
hive) DEFAULT_CHOICE=6 ;;
|
||||
@@ -1009,10 +1141,10 @@ fi
|
||||
echo ""
|
||||
echo -e " ${CYAN}${BOLD}API key providers:${NC}"
|
||||
|
||||
# 7-11) API key providers — show (credential detected) if key already set
|
||||
PROVIDER_MENU_ENVS=(ANTHROPIC_API_KEY OPENAI_API_KEY GEMINI_API_KEY GROQ_API_KEY CEREBRAS_API_KEY)
|
||||
PROVIDER_MENU_NAMES=("Anthropic (Claude) - Recommended" "OpenAI (GPT)" "Google Gemini - Free tier available" "Groq - Fast, free tier" "Cerebras - Fast, free tier")
|
||||
for idx in 0 1 2 3 4; do
|
||||
# 7-12) API key providers — show (credential detected) if key already set
|
||||
PROVIDER_MENU_ENVS=(ANTHROPIC_API_KEY OPENAI_API_KEY GEMINI_API_KEY GROQ_API_KEY CEREBRAS_API_KEY OPENROUTER_API_KEY)
|
||||
PROVIDER_MENU_NAMES=("Anthropic (Claude) - Recommended" "OpenAI (GPT)" "Google Gemini - Free tier available" "Groq - Fast, free tier" "Cerebras - Fast, free tier" "OpenRouter - Bring any OpenRouter model")
|
||||
for idx in "${!PROVIDER_MENU_ENVS[@]}"; do
|
||||
num=$((idx + 7))
|
||||
env_var="${PROVIDER_MENU_ENVS[$idx]}"
|
||||
if [ -n "${!env_var}" ]; then
|
||||
@@ -1022,7 +1154,8 @@ for idx in 0 1 2 3 4; do
|
||||
fi
|
||||
done
|
||||
|
||||
echo -e " ${CYAN}12)${NC} Skip for now"
|
||||
SKIP_CHOICE=$((7 + ${#PROVIDER_MENU_ENVS[@]}))
|
||||
echo -e " ${CYAN}$SKIP_CHOICE)${NC} Skip for now"
|
||||
echo ""
|
||||
|
||||
if [ -n "$DEFAULT_CHOICE" ]; then
|
||||
@@ -1032,15 +1165,15 @@ fi
|
||||
|
||||
while true; do
|
||||
if [ -n "$DEFAULT_CHOICE" ]; then
|
||||
read -r -p "Enter choice (1-12) [$DEFAULT_CHOICE]: " choice || true
|
||||
read -r -p "Enter choice (1-$SKIP_CHOICE) [$DEFAULT_CHOICE]: " choice || true
|
||||
choice="${choice:-$DEFAULT_CHOICE}"
|
||||
else
|
||||
read -r -p "Enter choice (1-12): " choice || true
|
||||
read -r -p "Enter choice (1-$SKIP_CHOICE): " choice || true
|
||||
fi
|
||||
if [[ "$choice" =~ ^[0-9]+$ ]] && [ "$choice" -ge 1 ] && [ "$choice" -le 12 ]; then
|
||||
if [[ "$choice" =~ ^[0-9]+$ ]] && [ "$choice" -ge 1 ] && [ "$choice" -le "$SKIP_CHOICE" ]; then
|
||||
break
|
||||
fi
|
||||
echo -e "${RED}Invalid choice. Please enter 1-12${NC}"
|
||||
echo -e "${RED}Invalid choice. Please enter 1-$SKIP_CHOICE${NC}"
|
||||
done
|
||||
|
||||
case $choice in
|
||||
@@ -1194,6 +1327,13 @@ case $choice in
|
||||
SIGNUP_URL="https://cloud.cerebras.ai/"
|
||||
;;
|
||||
12)
|
||||
SELECTED_ENV_VAR="OPENROUTER_API_KEY"
|
||||
SELECTED_PROVIDER_ID="openrouter"
|
||||
SELECTED_API_BASE="https://openrouter.ai/api/v1"
|
||||
PROVIDER_NAME="OpenRouter"
|
||||
SIGNUP_URL="https://openrouter.ai/keys"
|
||||
;;
|
||||
"$SKIP_CHOICE")
|
||||
echo ""
|
||||
echo -e "${YELLOW}Skipped.${NC} An LLM API key is required to test and use worker agents."
|
||||
echo -e "Add your API key later by running:"
|
||||
@@ -1234,7 +1374,7 @@ if { [ -z "$SUBSCRIPTION_MODE" ] || [ "$SUBSCRIPTION_MODE" = "minimax_code" ] ||
|
||||
echo -e "${GREEN}⬢${NC} API key saved to $SHELL_RC_FILE"
|
||||
# Health check the new key
|
||||
echo -n " Verifying API key... "
|
||||
if { [ "$SUBSCRIPTION_MODE" = "minimax_code" ] || [ "$SUBSCRIPTION_MODE" = "kimi_code" ] || [ "$SUBSCRIPTION_MODE" = "hive_llm" ]; } && [ -n "${SELECTED_API_BASE:-}" ]; then
|
||||
if [ -n "${SELECTED_API_BASE:-}" ]; then
|
||||
HC_RESULT=$(uv run python "$SCRIPT_DIR/scripts/check_llm_key.py" "$SELECTED_PROVIDER_ID" "$API_KEY" "$SELECTED_API_BASE" 2>/dev/null) || true
|
||||
else
|
||||
HC_RESULT=$(uv run python "$SCRIPT_DIR/scripts/check_llm_key.py" "$SELECTED_PROVIDER_ID" "$API_KEY" 2>/dev/null) || true
|
||||
@@ -1346,20 +1486,28 @@ fi
|
||||
if [ -n "$SELECTED_PROVIDER_ID" ]; then
|
||||
echo ""
|
||||
echo -n " Saving configuration... "
|
||||
SAVE_OK=true
|
||||
if [ "$SUBSCRIPTION_MODE" = "claude_code" ]; then
|
||||
save_configuration "$SELECTED_PROVIDER_ID" "" "$SELECTED_MODEL" "$SELECTED_MAX_TOKENS" "$SELECTED_MAX_CONTEXT_TOKENS" "true" "" > /dev/null
|
||||
save_configuration "$SELECTED_PROVIDER_ID" "" "$SELECTED_MODEL" "$SELECTED_MAX_TOKENS" "$SELECTED_MAX_CONTEXT_TOKENS" "true" "" > /dev/null || SAVE_OK=false
|
||||
elif [ "$SUBSCRIPTION_MODE" = "codex" ]; then
|
||||
save_configuration "$SELECTED_PROVIDER_ID" "" "$SELECTED_MODEL" "$SELECTED_MAX_TOKENS" "$SELECTED_MAX_CONTEXT_TOKENS" "" "" "true" > /dev/null
|
||||
save_configuration "$SELECTED_PROVIDER_ID" "" "$SELECTED_MODEL" "$SELECTED_MAX_TOKENS" "$SELECTED_MAX_CONTEXT_TOKENS" "" "" "true" > /dev/null || SAVE_OK=false
|
||||
elif [ "$SUBSCRIPTION_MODE" = "zai_code" ]; then
|
||||
save_configuration "$SELECTED_PROVIDER_ID" "$SELECTED_ENV_VAR" "$SELECTED_MODEL" "$SELECTED_MAX_TOKENS" "$SELECTED_MAX_CONTEXT_TOKENS" "" "https://api.z.ai/api/coding/paas/v4" > /dev/null
|
||||
save_configuration "$SELECTED_PROVIDER_ID" "$SELECTED_ENV_VAR" "$SELECTED_MODEL" "$SELECTED_MAX_TOKENS" "$SELECTED_MAX_CONTEXT_TOKENS" "" "https://api.z.ai/api/coding/paas/v4" > /dev/null || SAVE_OK=false
|
||||
elif [ "$SUBSCRIPTION_MODE" = "minimax_code" ]; then
|
||||
save_configuration "$SELECTED_PROVIDER_ID" "$SELECTED_ENV_VAR" "$SELECTED_MODEL" "$SELECTED_MAX_TOKENS" "$SELECTED_MAX_CONTEXT_TOKENS" "" "$SELECTED_API_BASE" > /dev/null
|
||||
save_configuration "$SELECTED_PROVIDER_ID" "$SELECTED_ENV_VAR" "$SELECTED_MODEL" "$SELECTED_MAX_TOKENS" "$SELECTED_MAX_CONTEXT_TOKENS" "" "$SELECTED_API_BASE" > /dev/null || SAVE_OK=false
|
||||
elif [ "$SUBSCRIPTION_MODE" = "kimi_code" ]; then
|
||||
save_configuration "$SELECTED_PROVIDER_ID" "$SELECTED_ENV_VAR" "$SELECTED_MODEL" "$SELECTED_MAX_TOKENS" "$SELECTED_MAX_CONTEXT_TOKENS" "" "$SELECTED_API_BASE" > /dev/null
|
||||
save_configuration "$SELECTED_PROVIDER_ID" "$SELECTED_ENV_VAR" "$SELECTED_MODEL" "$SELECTED_MAX_TOKENS" "$SELECTED_MAX_CONTEXT_TOKENS" "" "$SELECTED_API_BASE" > /dev/null || SAVE_OK=false
|
||||
elif [ "$SUBSCRIPTION_MODE" = "hive_llm" ]; then
|
||||
save_configuration "$SELECTED_PROVIDER_ID" "$SELECTED_ENV_VAR" "$SELECTED_MODEL" "$SELECTED_MAX_TOKENS" "$SELECTED_MAX_CONTEXT_TOKENS" "" "$SELECTED_API_BASE" > /dev/null
|
||||
save_configuration "$SELECTED_PROVIDER_ID" "$SELECTED_ENV_VAR" "$SELECTED_MODEL" "$SELECTED_MAX_TOKENS" "$SELECTED_MAX_CONTEXT_TOKENS" "" "$SELECTED_API_BASE" > /dev/null || SAVE_OK=false
|
||||
elif [ "$SELECTED_PROVIDER_ID" = "openrouter" ]; then
|
||||
save_configuration "$SELECTED_PROVIDER_ID" "$SELECTED_ENV_VAR" "$SELECTED_MODEL" "$SELECTED_MAX_TOKENS" "$SELECTED_MAX_CONTEXT_TOKENS" "" "$SELECTED_API_BASE" > /dev/null || SAVE_OK=false
|
||||
else
|
||||
save_configuration "$SELECTED_PROVIDER_ID" "$SELECTED_ENV_VAR" "$SELECTED_MODEL" "$SELECTED_MAX_TOKENS" "$SELECTED_MAX_CONTEXT_TOKENS" > /dev/null
|
||||
save_configuration "$SELECTED_PROVIDER_ID" "$SELECTED_ENV_VAR" "$SELECTED_MODEL" "$SELECTED_MAX_TOKENS" "$SELECTED_MAX_CONTEXT_TOKENS" > /dev/null || SAVE_OK=false
|
||||
fi
|
||||
if [ "$SAVE_OK" = false ]; then
|
||||
echo -e "${RED}failed${NC}"
|
||||
echo -e "${YELLOW} Could not write ~/.hive/configuration.json. Please rerun quickstart.${NC}"
|
||||
exit 1
|
||||
fi
|
||||
echo -e "${GREEN}⬢${NC}"
|
||||
echo -e " ${DIM}~/.hive/configuration.json${NC}"
|
||||
@@ -1375,22 +1523,44 @@ echo -e "${GREEN}⬢${NC} Browser automation enabled"
|
||||
|
||||
# Patch gcu_enabled into configuration.json
|
||||
if [ -f "$HIVE_CONFIG_FILE" ]; then
|
||||
uv run python -c "
|
||||
if ! uv run python - <<'PY'
|
||||
import json
|
||||
with open('$HIVE_CONFIG_FILE') as f:
|
||||
from pathlib import Path
|
||||
|
||||
cfg_path = Path.home() / ".hive" / "configuration.json"
|
||||
with open(cfg_path, encoding="utf-8-sig") as f:
|
||||
config = json.load(f)
|
||||
config['gcu_enabled'] = True
|
||||
with open('$HIVE_CONFIG_FILE', 'w') as f:
|
||||
config["gcu_enabled"] = True
|
||||
tmp_path = cfg_path.with_name(cfg_path.name + ".tmp")
|
||||
with open(tmp_path, "w", encoding="utf-8") as f:
|
||||
json.dump(config, f, indent=2)
|
||||
"
|
||||
tmp_path.replace(cfg_path)
|
||||
PY
|
||||
then
|
||||
echo -e "${RED}failed${NC}"
|
||||
echo -e "${YELLOW} Could not update ~/.hive/configuration.json with browser automation settings.${NC}"
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
mkdir -p "$HIVE_CONFIG_DIR"
|
||||
uv run python -c "
|
||||
if ! uv run python - "$(date -u +"%Y-%m-%dT%H:%M:%S+00:00")" <<'PY'
|
||||
import json
|
||||
config = {'gcu_enabled': True, 'created_at': '$(date -u +"%Y-%m-%dT%H:%M:%S+00:00")'}
|
||||
with open('$HIVE_CONFIG_FILE', 'w') as f:
|
||||
import sys
|
||||
from pathlib import Path
|
||||
|
||||
cfg_path = Path.home() / ".hive" / "configuration.json"
|
||||
cfg_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
config = {
|
||||
"gcu_enabled": True,
|
||||
"created_at": sys.argv[1],
|
||||
}
|
||||
with open(cfg_path, "w", encoding="utf-8") as f:
|
||||
json.dump(config, f, indent=2)
|
||||
"
|
||||
PY
|
||||
then
|
||||
echo -e "${RED}failed${NC}"
|
||||
echo -e "${YELLOW} Could not create ~/.hive/configuration.json for browser automation settings.${NC}"
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo ""
|
||||
@@ -1591,6 +1761,9 @@ if [ -n "$SELECTED_PROVIDER_ID" ]; then
|
||||
elif [ "$SUBSCRIPTION_MODE" = "minimax_code" ]; then
|
||||
echo -e " ${GREEN}⬢${NC} MiniMax Coding Key → ${DIM}$SELECTED_MODEL${NC}"
|
||||
echo -e " ${DIM}API: api.minimax.io/v1 (OpenAI-compatible)${NC}"
|
||||
elif [ "$SELECTED_PROVIDER_ID" = "openrouter" ]; then
|
||||
echo -e " ${GREEN}⬢${NC} OpenRouter API Key → ${DIM}$SELECTED_MODEL${NC}"
|
||||
echo -e " ${DIM}API: openrouter.ai/api/v1 (OpenAI-compatible)${NC}"
|
||||
else
|
||||
echo -e " ${CYAN}$SELECTED_PROVIDER_ID${NC} → ${DIM}$SELECTED_MODEL${NC}"
|
||||
fi
|
||||
@@ -1635,40 +1808,29 @@ if [ "$CODEX_AVAILABLE" = true ]; then
|
||||
echo ""
|
||||
fi
|
||||
|
||||
# Auto-launch dashboard if frontend was built
|
||||
if [ "$FRONTEND_BUILT" = true ]; then
|
||||
echo -e "${BOLD}Launching dashboard...${NC}"
|
||||
echo ""
|
||||
echo -e " ${DIM}Starting server on http://localhost:8787${NC}"
|
||||
echo -e " ${DIM}Press Ctrl+C to stop${NC}"
|
||||
echo ""
|
||||
echo -e " ${DIM}Tip: You can restart the dashboard anytime with:${NC} ${CYAN}hive open${NC}"
|
||||
echo ""
|
||||
# exec replaces the quickstart process with hive open
|
||||
exec "$SCRIPT_DIR/hive" open
|
||||
else
|
||||
# No frontend — show manual instructions
|
||||
echo -e "${YELLOW}━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━${NC}"
|
||||
echo -e "${BOLD}⚠️ IMPORTANT: Load your new configuration${NC}"
|
||||
echo -e "${YELLOW}━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━${NC}"
|
||||
echo ""
|
||||
echo -e " Your API keys have been saved to ${CYAN}$SHELL_RC_FILE${NC}"
|
||||
echo -e " To use them, either:"
|
||||
echo ""
|
||||
echo -e " ${GREEN}Option 1:${NC} Source your shell config now:"
|
||||
echo -e " ${CYAN}source $SHELL_RC_FILE${NC}"
|
||||
echo ""
|
||||
echo -e " ${GREEN}Option 2:${NC} Open a new terminal window"
|
||||
echo ""
|
||||
echo -e "${YELLOW}━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━${NC}"
|
||||
echo ""
|
||||
echo -e "${YELLOW}━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━${NC}"
|
||||
echo -e "${BOLD}IMPORTANT: Load your new configuration${NC}"
|
||||
echo -e "${YELLOW}━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━${NC}"
|
||||
echo ""
|
||||
echo -e " Your API keys have been saved to ${CYAN}$SHELL_RC_FILE${NC}"
|
||||
echo -e " To use them, either:"
|
||||
echo ""
|
||||
echo -e " ${GREEN}Option 1:${NC} Source your shell config now:"
|
||||
echo -e " ${CYAN}source $SHELL_RC_FILE${NC}"
|
||||
echo ""
|
||||
echo -e " ${GREEN}Option 2:${NC} Open a new terminal window"
|
||||
echo ""
|
||||
echo -e "${YELLOW}━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━${NC}"
|
||||
echo ""
|
||||
|
||||
echo -e "${BOLD}Run an Agent:${NC}"
|
||||
echo ""
|
||||
echo -e " Launch the interactive dashboard to browse and run agents:"
|
||||
echo -e " You can start an example agent or an agent built by yourself:"
|
||||
echo -e " ${CYAN}hive open${NC}"
|
||||
echo ""
|
||||
echo -e "${DIM}Run ./quickstart.sh again to reconfigure.${NC}"
|
||||
echo ""
|
||||
echo -e "${BOLD}Run an Agent:${NC}"
|
||||
echo ""
|
||||
if [ "$FRONTEND_BUILT" = true ]; then
|
||||
echo -e " Quickstart only sets things up. Launch the dashboard when you're ready:"
|
||||
else
|
||||
echo -e " Frontend build was skipped or failed. Once the dashboard is available, launch it with:"
|
||||
fi
|
||||
echo -e " ${CYAN}hive open${NC}"
|
||||
echo ""
|
||||
echo -e "${DIM}Run ./quickstart.sh again to reconfigure.${NC}"
|
||||
echo ""
|
||||
|
||||
+198
-3
@@ -1,7 +1,7 @@
|
||||
"""Validate an LLM API key without consuming tokens.
|
||||
|
||||
Usage:
|
||||
python scripts/check_llm_key.py <provider_id> <api_key> [api_base]
|
||||
python scripts/check_llm_key.py <provider_id> <api_key> [api_base] [model]
|
||||
|
||||
Exit codes:
|
||||
0 = valid key
|
||||
@@ -12,13 +12,125 @@ Output: single JSON line {"valid": bool, "message": str}
|
||||
"""
|
||||
|
||||
import json
|
||||
import re
|
||||
import sys
|
||||
import unicodedata
|
||||
from difflib import get_close_matches
|
||||
|
||||
import httpx
|
||||
|
||||
from framework.config import HIVE_LLM_ENDPOINT
|
||||
|
||||
TIMEOUT = 10.0
|
||||
OPENROUTER_SEPARATOR_TRANSLATION = str.maketrans(
|
||||
{
|
||||
"\u2010": "-",
|
||||
"\u2011": "-",
|
||||
"\u2012": "-",
|
||||
"\u2013": "-",
|
||||
"\u2014": "-",
|
||||
"\u2015": "-",
|
||||
"\u2212": "-",
|
||||
"\u2044": "/",
|
||||
"\u2215": "/",
|
||||
"\u29F8": "/",
|
||||
"\uFF0F": "/",
|
||||
}
|
||||
)
|
||||
|
||||
|
||||
def _extract_error_message(response: httpx.Response) -> str:
|
||||
"""Best-effort extraction of a provider error message."""
|
||||
try:
|
||||
payload = response.json()
|
||||
except Exception:
|
||||
text = (response.text or "").strip()
|
||||
return text[:240] if text else ""
|
||||
|
||||
if isinstance(payload, dict):
|
||||
error_value = payload.get("error")
|
||||
if isinstance(error_value, dict):
|
||||
message = error_value.get("message")
|
||||
if isinstance(message, str) and message.strip():
|
||||
return message.strip()
|
||||
if isinstance(error_value, str) and error_value.strip():
|
||||
return error_value.strip()
|
||||
message = payload.get("message")
|
||||
if isinstance(message, str) and message.strip():
|
||||
return message.strip()
|
||||
|
||||
return ""
|
||||
|
||||
|
||||
def _sanitize_openrouter_model_id(value: str) -> str:
|
||||
"""Sanitize pasted OpenRouter model IDs into a comparable slug."""
|
||||
normalized = unicodedata.normalize("NFKC", value or "")
|
||||
normalized = "".join(
|
||||
ch
|
||||
for ch in normalized
|
||||
if unicodedata.category(ch) not in {"Cc", "Cf"}
|
||||
)
|
||||
normalized = normalized.translate(OPENROUTER_SEPARATOR_TRANSLATION)
|
||||
normalized = re.sub(r"\s+", "", normalized)
|
||||
if normalized.casefold().startswith("openrouter/"):
|
||||
normalized = normalized.split("/", 1)[1]
|
||||
return normalized
|
||||
|
||||
|
||||
def _normalize_openrouter_model_id(value: str) -> str:
|
||||
"""Normalize OpenRouter model IDs for exact/alias matching."""
|
||||
return _sanitize_openrouter_model_id(value).casefold()
|
||||
|
||||
|
||||
def _extract_openrouter_model_lookup(payload: object) -> dict[str, str]:
|
||||
"""Map normalized model IDs/aliases to a preferred canonical display slug."""
|
||||
if not isinstance(payload, dict):
|
||||
return {}
|
||||
|
||||
data = payload.get("data")
|
||||
if not isinstance(data, list):
|
||||
return {}
|
||||
|
||||
lookup: dict[str, str] = {}
|
||||
for item in data:
|
||||
if not isinstance(item, dict):
|
||||
continue
|
||||
|
||||
model_id = item.get("id")
|
||||
canonical_slug = item.get("canonical_slug")
|
||||
candidates = [
|
||||
_sanitize_openrouter_model_id(value)
|
||||
for value in (model_id, canonical_slug)
|
||||
if isinstance(value, str) and _sanitize_openrouter_model_id(value)
|
||||
]
|
||||
if not candidates:
|
||||
continue
|
||||
|
||||
preferred_slug = candidates[-1]
|
||||
for candidate in candidates:
|
||||
lookup[_normalize_openrouter_model_id(candidate)] = preferred_slug
|
||||
|
||||
return lookup
|
||||
|
||||
|
||||
def _format_openrouter_model_unavailable_message(
|
||||
model: str, available_model_lookup: dict[str, str]
|
||||
) -> str:
|
||||
"""Return a helpful not-found message with close-match suggestions."""
|
||||
suggestions = [
|
||||
available_model_lookup[key]
|
||||
for key in get_close_matches(
|
||||
_normalize_openrouter_model_id(model),
|
||||
list(available_model_lookup),
|
||||
n=1,
|
||||
cutoff=0.6,
|
||||
)
|
||||
]
|
||||
|
||||
base = f"OpenRouter model is not available for this key/settings: {model}"
|
||||
if suggestions:
|
||||
return f"{base}. Closest matches: {', '.join(suggestions)}"
|
||||
return base
|
||||
|
||||
|
||||
def check_anthropic(api_key: str, **_: str) -> dict:
|
||||
@@ -58,6 +170,79 @@ def check_openai_compatible(api_key: str, endpoint: str, name: str) -> dict:
|
||||
return {"valid": False, "message": f"{name} API returned status {r.status_code}"}
|
||||
|
||||
|
||||
def check_openrouter(
|
||||
api_key: str, api_base: str = "https://openrouter.ai/api/v1", **_: str
|
||||
) -> dict:
|
||||
"""Validate OpenRouter key against GET /models."""
|
||||
endpoint = f"{api_base.rstrip('/')}/models"
|
||||
with httpx.Client(timeout=TIMEOUT) as client:
|
||||
r = client.get(endpoint, headers={"Authorization": f"Bearer {api_key}"})
|
||||
if r.status_code in (200, 429):
|
||||
return {"valid": True, "message": "OpenRouter API key valid"}
|
||||
if r.status_code == 401:
|
||||
return {"valid": False, "message": "Invalid OpenRouter API key"}
|
||||
if r.status_code == 403:
|
||||
return {"valid": False, "message": "OpenRouter API key lacks permissions"}
|
||||
return {"valid": False, "message": f"OpenRouter API returned status {r.status_code}"}
|
||||
|
||||
|
||||
def check_openrouter_model(
|
||||
api_key: str,
|
||||
model: str,
|
||||
api_base: str = "https://openrouter.ai/api/v1",
|
||||
**_: str,
|
||||
) -> dict:
|
||||
"""Validate that an OpenRouter model ID is available to this key/settings."""
|
||||
requested_model = _sanitize_openrouter_model_id(model)
|
||||
endpoint = f"{api_base.rstrip('/')}/models/user"
|
||||
with httpx.Client(timeout=TIMEOUT) as client:
|
||||
r = client.get(
|
||||
endpoint,
|
||||
headers={"Authorization": f"Bearer {api_key}"},
|
||||
)
|
||||
if r.status_code == 200:
|
||||
available_model_lookup = _extract_openrouter_model_lookup(r.json())
|
||||
matched_model = available_model_lookup.get(
|
||||
_normalize_openrouter_model_id(requested_model)
|
||||
)
|
||||
if matched_model:
|
||||
return {
|
||||
"valid": True,
|
||||
"message": f"OpenRouter model is available: {matched_model}",
|
||||
"model": matched_model,
|
||||
}
|
||||
|
||||
return {
|
||||
"valid": False,
|
||||
"message": _format_openrouter_model_unavailable_message(
|
||||
requested_model, available_model_lookup
|
||||
),
|
||||
}
|
||||
if r.status_code == 429:
|
||||
return {
|
||||
"valid": True,
|
||||
"message": "OpenRouter model check rate-limited; assuming model is reachable",
|
||||
}
|
||||
if r.status_code == 401:
|
||||
return {"valid": False, "message": "Invalid OpenRouter API key"}
|
||||
if r.status_code == 403:
|
||||
return {"valid": False, "message": "OpenRouter API key lacks permissions"}
|
||||
|
||||
detail = _extract_error_message(r)
|
||||
if r.status_code in (400, 404, 422):
|
||||
base = (
|
||||
"OpenRouter model is not available for this key/settings: "
|
||||
f"{requested_model}"
|
||||
)
|
||||
return {"valid": False, "message": f"{base}. {detail}" if detail else base}
|
||||
|
||||
suffix = f": {detail}" if detail else ""
|
||||
return {
|
||||
"valid": False,
|
||||
"message": f"OpenRouter model check returned status {r.status_code}{suffix}",
|
||||
}
|
||||
|
||||
|
||||
def check_minimax(
|
||||
api_key: str, api_base: str = "https://api.minimax.io/v1", **_: str
|
||||
) -> dict:
|
||||
@@ -131,6 +316,7 @@ PROVIDERS = {
|
||||
"cerebras": lambda key, **kw: check_openai_compatible(
|
||||
key, "https://api.cerebras.ai/v1/models", "Cerebras"
|
||||
),
|
||||
"openrouter": lambda key, **kw: check_openrouter(key, **kw),
|
||||
"minimax": lambda key, **kw: check_minimax(key),
|
||||
# Kimi For Coding uses an Anthropic-compatible endpoint; check via /v1/messages
|
||||
# with empty messages (same as check_anthropic, triggers 400 not 401).
|
||||
@@ -150,7 +336,7 @@ def main() -> None:
|
||||
json.dumps(
|
||||
{
|
||||
"valid": False,
|
||||
"message": "Usage: check_llm_key.py <provider> <key> [api_base]",
|
||||
"message": "Usage: check_llm_key.py <provider> <key> [api_base] [model]",
|
||||
}
|
||||
)
|
||||
)
|
||||
@@ -159,10 +345,19 @@ def main() -> None:
|
||||
provider_id = sys.argv[1]
|
||||
api_key = sys.argv[2]
|
||||
api_base = sys.argv[3] if len(sys.argv) > 3 else ""
|
||||
model = sys.argv[4] if len(sys.argv) > 4 else ""
|
||||
|
||||
try:
|
||||
if api_base and provider_id == "minimax":
|
||||
if provider_id == "openrouter" and model:
|
||||
result = check_openrouter_model(
|
||||
api_key,
|
||||
model=model,
|
||||
api_base=(api_base or "https://openrouter.ai/api/v1"),
|
||||
)
|
||||
elif api_base and provider_id == "minimax":
|
||||
result = check_minimax(api_key, api_base)
|
||||
elif api_base and provider_id == "openrouter":
|
||||
result = check_openrouter(api_key, api_base)
|
||||
elif api_base and provider_id == "kimi":
|
||||
# Kimi uses an Anthropic-compatible endpoint; check via /v1/messages
|
||||
result = check_anthropic_compatible(
|
||||
|
||||
Reference in New Issue
Block a user