Compare commits
1937 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
86dd5246c6 | ||
|
|
a1227c88ee | ||
|
|
535d7ab568 | ||
|
|
af10494b31 | ||
|
|
39c1042827 | ||
|
|
16e7dc11f4 | ||
|
|
7a27babefd | ||
|
|
d53ae9d51d | ||
|
|
910cf7727d | ||
|
|
1698605f15 | ||
|
|
eda124a123 | ||
|
|
15e9ce8d2f | ||
|
|
c01dd603d7 | ||
|
|
9d5157d69f | ||
|
|
d78795bdf5 | ||
|
|
ff2b7f473e | ||
|
|
73c9a91811 | ||
|
|
27b765d902 | ||
|
|
fddba419be | ||
|
|
f42d6308e8 | ||
|
|
c167002754 | ||
|
|
ea26ee7d0c | ||
|
|
5280e908b2 | ||
|
|
1c5dd8c664 | ||
|
|
3aca153be5 | ||
|
|
65c8e1653c | ||
|
|
58e4fa918c | ||
|
|
3af13d3f90 | ||
|
|
d2eb86e534 | ||
|
|
48747e20af | ||
|
|
58af593af6 | ||
|
|
450575a927 | ||
|
|
eac2bb19b2 | ||
|
|
756a815bf0 | ||
|
|
23a7b080eb | ||
|
|
bf39bcdec9 | ||
|
|
0276632491 | ||
|
|
ae2993d0d1 | ||
|
|
d14d71f760 | ||
|
|
ef6efc2f55 | ||
|
|
738641d35f | ||
|
|
22f5534f08 | ||
|
|
b79e7eca73 | ||
|
|
28250dc45e | ||
|
|
fe5df6a87a | ||
|
|
07e4b593dd | ||
|
|
497591bf3b | ||
|
|
a2a3e334d6 | ||
|
|
1ccbfaf800 | ||
|
|
a9afa0555c | ||
|
|
83b2183cf0 | ||
|
|
c2dea88398 | ||
|
|
f49e7a760e | ||
|
|
dc95c88da0 | ||
|
|
6e0255ebec | ||
|
|
b51e688d1a | ||
|
|
379d3df46b | ||
|
|
b77a3031fe | ||
|
|
c10eea04ec | ||
|
|
491a3f24da | ||
|
|
c7d70e0fb1 | ||
|
|
d59f8e99cb | ||
|
|
0a91b49417 | ||
|
|
ced64541b9 | ||
|
|
3c30cfe02b | ||
|
|
0d6267bcf1 | ||
|
|
b47175d1df | ||
|
|
6f23a30eed | ||
|
|
ff7b5c7e27 | ||
|
|
69f0ff7ac9 | ||
|
|
c3f13c50eb | ||
|
|
5477408d40 | ||
|
|
9fad385ddf | ||
|
|
cf44ee1d9b | ||
|
|
4ab33a39d6 | ||
|
|
ae19121802 | ||
|
|
b518525418 | ||
|
|
ac3fe38b33 | ||
|
|
3c6a30fcae | ||
|
|
2ced873fb5 | ||
|
|
ab995d8b96 | ||
|
|
c2e560fc07 | ||
|
|
19f7ae862e | ||
|
|
5e9f74744a | ||
|
|
7787179a5a | ||
|
|
b63205b91a | ||
|
|
347bccb9ee | ||
|
|
9d83f0298f | ||
|
|
7f7e8b4dff | ||
|
|
f48a7380f5 | ||
|
|
3c7f129d86 | ||
|
|
4533b27aa1 | ||
|
|
3adf268c29 | ||
|
|
ac8579900f | ||
|
|
abbaaa68f3 | ||
|
|
11089093ef | ||
|
|
99b7cb07d5 | ||
|
|
70d61ae67a | ||
|
|
dd054815a3 | ||
|
|
8e5eaae9dd | ||
|
|
2d0128eb5c | ||
|
|
06f1d4dcef | ||
|
|
0e7b11b5b2 | ||
|
|
291b78f934 | ||
|
|
e196a03972 | ||
|
|
a0abe2685d | ||
|
|
e8f642c8b6 | ||
|
|
6260f628eb | ||
|
|
4a4f17ed40 | ||
|
|
36dcf2025b | ||
|
|
85c70c94e6 | ||
|
|
336e82ba22 | ||
|
|
f2ddd1051d | ||
|
|
2dd60c8d52 | ||
|
|
ff01c1fd99 | ||
|
|
421b25fdb7 | ||
|
|
795c3c33e2 | ||
|
|
97821f4d80 | ||
|
|
505e1e30fd | ||
|
|
3fb2b285fb | ||
|
|
a76109840c | ||
|
|
1db8484402 | ||
|
|
39212350ba | ||
|
|
f3399fe95b | ||
|
|
d02e1155ed | ||
|
|
7ede3ba171 | ||
|
|
cdaec8a837 | ||
|
|
2272491cf5 | ||
|
|
bb38cb974f | ||
|
|
635d2976f4 | ||
|
|
4e1525880d | ||
|
|
b80559df68 | ||
|
|
08d93ef90a | ||
|
|
22bf035522 | ||
|
|
15944a42ab | ||
|
|
8440ec70ba | ||
|
|
eacf2520cf | ||
|
|
def4f62a51 | ||
|
|
b0c5bcd210 | ||
|
|
2fe1343343 | ||
|
|
de0dcff50f | ||
|
|
20427e213a | ||
|
|
1fb5c6337a | ||
|
|
1e74f194a1 | ||
|
|
08157d2bd6 | ||
|
|
ef036257a9 | ||
|
|
16ce984c74 | ||
|
|
1e8b5b96eb | ||
|
|
094ba89f19 | ||
|
|
7008c9f310 | ||
|
|
94d7cbacc2 | ||
|
|
bddc2b413a | ||
|
|
48c8fb7fff | ||
|
|
52b1a3f472 | ||
|
|
079e00c8f7 | ||
|
|
60bba38941 | ||
|
|
ea8e7b11c6 | ||
|
|
3dc2b25b01 | ||
|
|
543b90b34f | ||
|
|
2ad78ec8a2 | ||
|
|
412658e9f2 | ||
|
|
9bfddec322 | ||
|
|
bbd9c10169 | ||
|
|
51fdc4ddde | ||
|
|
04685d33ca | ||
|
|
729a0e0cec | ||
|
|
2bcb0cacee | ||
|
|
44bf191f53 | ||
|
|
993b31f19b | ||
|
|
41b3b9619f | ||
|
|
2a4fe4020c | ||
|
|
9d1f268078 | ||
|
|
2185e127b1 | ||
|
|
99ed885fd0 | ||
|
|
d8a390a685 | ||
|
|
f50cf1735b | ||
|
|
04eb57f54e | ||
|
|
7378408eb8 | ||
|
|
cf05420417 | ||
|
|
f5ed4c7d43 | ||
|
|
5547432b6e | ||
|
|
336557d7c7 | ||
|
|
87c172227c | ||
|
|
c2c4929de8 | ||
|
|
a978338738 | ||
|
|
8eb59b1f66 | ||
|
|
f9d5f95936 | ||
|
|
651e99ffe3 | ||
|
|
2564f1b948 | ||
|
|
c01cd528d2 | ||
|
|
2434c86cdf | ||
|
|
bc194ee4e9 | ||
|
|
c4a5e621aa | ||
|
|
0f5b83d86a | ||
|
|
b5aadcd51e | ||
|
|
290d2f6823 | ||
|
|
2bac100c03 | ||
|
|
425d37f868 | ||
|
|
99b127e2da | ||
|
|
43b759bf61 | ||
|
|
20d8d52f12 | ||
|
|
944567dc31 | ||
|
|
7e09588e4e | ||
|
|
7bf69d2263 | ||
|
|
99d2b0c003 | ||
|
|
8868416baa | ||
|
|
405b120674 | ||
|
|
66a7b43199 | ||
|
|
a8f9d83723 | ||
|
|
d95d5804ca | ||
|
|
674cf05601 | ||
|
|
86349c78d0 | ||
|
|
2232f49191 | ||
|
|
6fa71fa27d | ||
|
|
1ac9ba69d6 | ||
|
|
9e16be8f03 | ||
|
|
8c7065ad37 | ||
|
|
a18ed5bbe6 | ||
|
|
9f3339650d | ||
|
|
d5e5d3e83d | ||
|
|
5ea27dda09 | ||
|
|
6f9066ef20 | ||
|
|
c37185732a | ||
|
|
0c900fb50e | ||
|
|
4d3ac28878 | ||
|
|
270c1f8c50 | ||
|
|
3d0859d06a | ||
|
|
8f55170c1e | ||
|
|
ed3d4bfe33 | ||
|
|
31a98a5f95 | ||
|
|
7667b773f2 | ||
|
|
49560260de | ||
|
|
596ce9878d | ||
|
|
1cc75f89bd | ||
|
|
ffe47c0f71 | ||
|
|
bb3c69cff1 | ||
|
|
70d11f537e | ||
|
|
b15dd2f623 | ||
|
|
ce308312ae | ||
|
|
bf4652db4b | ||
|
|
2acd526b71 | ||
|
|
df71834e4b | ||
|
|
f757c724cc | ||
|
|
a4c758403e | ||
|
|
bc3c5a5899 | ||
|
|
a67563850b | ||
|
|
b48465b778 | ||
|
|
d3baaaab24 | ||
|
|
c764b4dc3b | ||
|
|
ad6077bd7b | ||
|
|
ce2a91b1c0 | ||
|
|
c2e7afeb5e | ||
|
|
0c9680ca89 | ||
|
|
726016d24a | ||
|
|
4895cea08a | ||
|
|
c9723a3ff2 | ||
|
|
6cb73a6fea | ||
|
|
0c7f43f595 | ||
|
|
ea5cfcc5d6 | ||
|
|
34e85019c3 | ||
|
|
8011b72673 | ||
|
|
d87dfca1ab | ||
|
|
c979dba958 | ||
|
|
b4caa045e1 | ||
|
|
b0fd4bc356 | ||
|
|
a79d7de482 | ||
|
|
e5e57302fa | ||
|
|
c69cf1aea5 | ||
|
|
2f4cd8c36f | ||
|
|
6f571e6d00 | ||
|
|
31bc84106f | ||
|
|
bdd6194203 | ||
|
|
fd79dceb0f | ||
|
|
ad50139d67 | ||
|
|
12fb40c110 | ||
|
|
738e469d96 | ||
|
|
80ccbcc827 | ||
|
|
08fac31a9d | ||
|
|
89ccd66fb9 | ||
|
|
7c47e367de | ||
|
|
b8741bf94c | ||
|
|
e82133741c | ||
|
|
c90dcbb32f | ||
|
|
ac3a5f5e93 | ||
|
|
1ccfdbbf7d | ||
|
|
1de37d2747 | ||
|
|
2aefdf5b5f | ||
|
|
5076278dcb | ||
|
|
2398e04e11 | ||
|
|
d00f321627 | ||
|
|
e76b6cb575 | ||
|
|
4caaa79900 | ||
|
|
296089d4cd | ||
|
|
cae5f971cf | ||
|
|
bac716eea3 | ||
|
|
14daf672e8 | ||
|
|
e352ae5145 | ||
|
|
a58ffc2669 | ||
|
|
3fefea52be | ||
|
|
06fd045b3e | ||
|
|
2e43d2af46 | ||
|
|
2c9790c65d | ||
|
|
9700ac71bb | ||
|
|
61ed67b068 | ||
|
|
c3bea8685a | ||
|
|
98c57b795a | ||
|
|
9be1d03b5c | ||
|
|
0d09510539 | ||
|
|
639c37ba17 | ||
|
|
2258c23254 | ||
|
|
9714ea106d | ||
|
|
f4ad500177 | ||
|
|
9154a4d9f8 | ||
|
|
add6efe6f1 | ||
|
|
7ceb1efd02 | ||
|
|
a29ecf8435 | ||
|
|
d0ba5ef4f4 | ||
|
|
860f637491 | ||
|
|
acb2cab317 | ||
|
|
b453806918 | ||
|
|
7ba8a0f51b | ||
|
|
f6f398b6b1 | ||
|
|
c4b22fa5c4 | ||
|
|
0e64f977cd | ||
|
|
f24c9708fc | ||
|
|
bb4436e277 | ||
|
|
795f66c90b | ||
|
|
9ef6d51573 | ||
|
|
3fed4e3409 | ||
|
|
670e69f2ce | ||
|
|
f6c4747905 | ||
|
|
7b78f6c12f | ||
|
|
1c75100f59 | ||
|
|
b325e103c6 | ||
|
|
aef2d2d474 | ||
|
|
95a2b6711e | ||
|
|
7fb5e8145c | ||
|
|
8e45d0df83 | ||
|
|
8d4657c13e | ||
|
|
3d175a6d54 | ||
|
|
b9debaf957 | ||
|
|
bdcbcff6f3 | ||
|
|
d2d7bdc374 | ||
|
|
40e494b15d | ||
|
|
b5e840c0cb | ||
|
|
f3d74c9ae4 | ||
|
|
a22b321692 | ||
|
|
2e7dbad118 | ||
|
|
6183d1b65b | ||
|
|
09931e6d98 | ||
|
|
cb394127d1 | ||
|
|
588fa1f9ea | ||
|
|
73325c280c | ||
|
|
8c5ae8ffa8 | ||
|
|
7389423c70 | ||
|
|
20c15446a7 | ||
|
|
c05c30dd9a | ||
|
|
bcd2fb76bd | ||
|
|
5fb97ab6df | ||
|
|
0224ebc800 | ||
|
|
af88f7299a | ||
|
|
81729706ae | ||
|
|
bbb1b43ebe | ||
|
|
70ed5fa8df | ||
|
|
312db6620d | ||
|
|
93c1fc5488 | ||
|
|
90762f275b | ||
|
|
801443027d | ||
|
|
ca2ead76cd | ||
|
|
d562144a6d | ||
|
|
af7fb7da27 | ||
|
|
c17dd63b4a | ||
|
|
866db289e2 | ||
|
|
b4ac5e9607 | ||
|
|
3ca7af4242 | ||
|
|
2b12a9c91a | ||
|
|
9a94595a42 | ||
|
|
e1540dfaa6 | ||
|
|
4f5ac6d1b1 | ||
|
|
c87d7b13da | ||
|
|
c4acf0b659 | ||
|
|
5e1ab3ca37 | ||
|
|
79c32c9f47 | ||
|
|
35ee29a843 | ||
|
|
573aea1d9c | ||
|
|
6ecbc30293 | ||
|
|
843b1f2e1d | ||
|
|
89f6c8e4ef | ||
|
|
304ac07bd8 | ||
|
|
82f0684b83 | ||
|
|
963c37dc31 | ||
|
|
c02da3ba5a | ||
|
|
7f34e95ec6 | ||
|
|
f2998fe098 | ||
|
|
323a2489b8 | ||
|
|
f6d1cd640e | ||
|
|
ddf89a04fe | ||
|
|
c5dc89f5ee | ||
|
|
6ade34b759 | ||
|
|
09d5f0a9df | ||
|
|
a60d63cca2 | ||
|
|
8616975fc5 | ||
|
|
e5ae919d8f | ||
|
|
8e7f5eaaba | ||
|
|
4d1ff8b054 | ||
|
|
9fa81e8599 | ||
|
|
cf8e19b059 | ||
|
|
dfa3f60fcf | ||
|
|
b795f1b253 | ||
|
|
73423c0dd2 | ||
|
|
3d844e1539 | ||
|
|
b619119eb5 | ||
|
|
b00ed4fc70 | ||
|
|
5ec5fbe998 | ||
|
|
2ed814455a | ||
|
|
ad1a4ef0c3 | ||
|
|
2111c808a9 | ||
|
|
402bb38267 | ||
|
|
0a55928872 | ||
|
|
cdf76ae3b9 | ||
|
|
4ad0d0e077 | ||
|
|
42d0592941 | ||
|
|
1de7cf821d | ||
|
|
4ea8540e25 | ||
|
|
bfa3b8e0f6 | ||
|
|
55eccfd75f | ||
|
|
1e994a77b5 | ||
|
|
d12afeb35d | ||
|
|
b55a77634b | ||
|
|
e84fefd319 | ||
|
|
cba0ec110f | ||
|
|
0256e0c944 | ||
|
|
f7db603922 | ||
|
|
b4a47a12ff | ||
|
|
2228851b16 | ||
|
|
d2b510014d | ||
|
|
ed0a211906 | ||
|
|
63744ddaef | ||
|
|
82331acb77 | ||
|
|
3ed5fda448 | ||
|
|
4d9d0362a0 | ||
|
|
b96bbcaa72 | ||
|
|
edfa49bf7a | ||
|
|
eb9e4ed23c | ||
|
|
fed9e90271 | ||
|
|
f474d0bc8e | ||
|
|
6a0681b9aa | ||
|
|
ca565ae664 | ||
|
|
42ce97e0fc | ||
|
|
bea17b5f79 | ||
|
|
ab0d5ce8d3 | ||
|
|
b374d5119a | ||
|
|
7a467ef9b8 | ||
|
|
9129b4a42e | ||
|
|
c7e634851b | ||
|
|
e906646d49 | ||
|
|
086a532521 | ||
|
|
19dd40ed3a | ||
|
|
196f3d645f | ||
|
|
80fd91d175 | ||
|
|
695410f880 | ||
|
|
009c62dac6 | ||
|
|
27c8904341 | ||
|
|
ddfce58071 | ||
|
|
cdb7155960 | ||
|
|
1bb850bdbe | ||
|
|
5019633ba3 | ||
|
|
b0fd8b83f0 | ||
|
|
2dc58eeeb0 | ||
|
|
50ab55ded5 | ||
|
|
3f7790c26a | ||
|
|
9f656577a2 | ||
|
|
5c87b4b194 | ||
|
|
7f866b24a1 | ||
|
|
5eb623e931 | ||
|
|
5583896429 | ||
|
|
3a8321b975 | ||
|
|
5676b115f4 | ||
|
|
8443ec87a6 | ||
|
|
1e06e87f4c | ||
|
|
e2558e3f95 | ||
|
|
1344d3bb8e | ||
|
|
dc7ec6c058 | ||
|
|
0ba781609a | ||
|
|
61c59d57e8 | ||
|
|
5ce230b0a6 | ||
|
|
ff1527a77a | ||
|
|
252dea0bc3 | ||
|
|
126cbe529f | ||
|
|
207a0a0ca5 | ||
|
|
d9f502173b | ||
|
|
f090ce4d5a | ||
|
|
1f7efcd940 | ||
|
|
fbbbaadd1e | ||
|
|
4de140a170 | ||
|
|
ed5cfb93a4 | ||
|
|
891bf08477 | ||
|
|
37651e534f | ||
|
|
df63c3e781 | ||
|
|
838da4a16e | ||
|
|
e916d573f6 | ||
|
|
08d51bb377 | ||
|
|
fa5ebf19a4 | ||
|
|
17de0efcaf | ||
|
|
4099603a91 | ||
|
|
988a58c1b7 | ||
|
|
cbc7ec3a32 | ||
|
|
07d4bf8044 | ||
|
|
e302e93ac9 | ||
|
|
80f5a363d2 | ||
|
|
7b5b6d2c51 | ||
|
|
0b1fd72e49 | ||
|
|
353f5c31a2 | ||
|
|
ad40b049ae | ||
|
|
42c9a11b1a | ||
|
|
c3fb1885c3 | ||
|
|
bb413bad1f | ||
|
|
afef3cb66a | ||
|
|
b1f3d931cd | ||
|
|
297b24e061 | ||
|
|
775a0fa511 | ||
|
|
77abed89b9 | ||
|
|
e2aeb72d49 | ||
|
|
2b440f84f0 | ||
|
|
8fd66a12c5 | ||
|
|
f23d5a3ff5 | ||
|
|
be8ec867e5 | ||
|
|
b2ba42e541 | ||
|
|
94d0038e03 | ||
|
|
e1bf300e3c | ||
|
|
f36add83f0 | ||
|
|
a57d58e8d4 | ||
|
|
c6b922e831 | ||
|
|
71d12a7904 | ||
|
|
24c25d408c | ||
|
|
2e99fc9fe5 | ||
|
|
c1f066b8ba | ||
|
|
e7a6074800 | ||
|
|
719942d29a | ||
|
|
190450a2b2 | ||
|
|
44d609b719 | ||
|
|
8c9892f9f6 | ||
|
|
85c204a442 | ||
|
|
56075a25a3 | ||
|
|
2b0a6779cc | ||
|
|
b9ddce9d41 | ||
|
|
0c85406bc2 | ||
|
|
1051134594 | ||
|
|
653d24df9d | ||
|
|
b687fa9e94 | ||
|
|
c7f0ab0444 | ||
|
|
93bf373a5b | ||
|
|
2d87042a70 | ||
|
|
8a28abb7b8 | ||
|
|
0cdfbac5a1 | ||
|
|
29a3ae471f | ||
|
|
9c0f56f027 | ||
|
|
462e303a6e | ||
|
|
a84b3c7867 | ||
|
|
606267d053 | ||
|
|
35791ae478 | ||
|
|
10f0002080 | ||
|
|
60bff4107d | ||
|
|
be11fa4b29 | ||
|
|
6ade844722 | ||
|
|
da8bc796d3 | ||
|
|
429619379e | ||
|
|
0fecedbbbf | ||
|
|
a2244ada75 | ||
|
|
7608ba9290 | ||
|
|
b9a3c67fea | ||
|
|
f5f3396d5c | ||
|
|
ed80ae80f0 | ||
|
|
c7a47c71f0 | ||
|
|
219bbe00fc | ||
|
|
b14b8f8c52 | ||
|
|
df1a83d475 | ||
|
|
5b7727cfd1 | ||
|
|
93e270dafb | ||
|
|
be675dbb17 | ||
|
|
1c24848db3 | ||
|
|
ef6af5404f | ||
|
|
b7d57f3d49 | ||
|
|
58c892babb | ||
|
|
4b5ec796bc | ||
|
|
24df4729ca | ||
|
|
9e2004e33b | ||
|
|
1e6538efac | ||
|
|
f9e53f58af | ||
|
|
41388efc31 | ||
|
|
fab5ce6fd0 | ||
|
|
b8be3056ed | ||
|
|
207d6baee5 | ||
|
|
fec72bb2b6 | ||
|
|
39029b82d6 | ||
|
|
232890b970 | ||
|
|
c4c4c24c59 | ||
|
|
13a8e28ae2 | ||
|
|
917c7706ea | ||
|
|
8fadcd5b21 | ||
|
|
2005ba2dca | ||
|
|
34a44aa83c | ||
|
|
557d5fd6e5 | ||
|
|
8468c45dc2 | ||
|
|
79d2a15f95 | ||
|
|
d2c3649566 | ||
|
|
ab32e44128 | ||
|
|
047059f85f | ||
|
|
e8364f616d | ||
|
|
9098c9b6c6 | ||
|
|
84fd9ebac8 | ||
|
|
23d5d76d56 | ||
|
|
b0c86588b6 | ||
|
|
5aff1f9489 | ||
|
|
199cb3d8cc | ||
|
|
a98a4ca0b6 | ||
|
|
c4f49aadfa | ||
|
|
ca5ac389cf | ||
|
|
7a658f7953 | ||
|
|
e05fc99da7 | ||
|
|
787090667e | ||
|
|
80b36b4052 | ||
|
|
0b8ed521c0 | ||
|
|
1ec7c5545f | ||
|
|
cc6b6760c3 | ||
|
|
26aed90ab2 | ||
|
|
1c58ccb0c1 | ||
|
|
79b80fe817 | ||
|
|
c0f3841af7 | ||
|
|
2b7d9bc471 | ||
|
|
98dc493a39 | ||
|
|
cfaa57b28d | ||
|
|
219e603de6 | ||
|
|
7663a5bce8 | ||
|
|
f2841b945d | ||
|
|
faff64c413 | ||
|
|
6fbcdc1d87 | ||
|
|
69a11af949 | ||
|
|
9ef272020e | ||
|
|
71226d9625 | ||
|
|
258cfe7de5 | ||
|
|
0d53b21133 | ||
|
|
9102328d1c | ||
|
|
704a0fd63a | ||
|
|
0ccb28ffab | ||
|
|
bf4101ac38 | ||
|
|
b30b571b44 | ||
|
|
bc44c3a401 | ||
|
|
7fbf57cbb7 | ||
|
|
bc349e8fde | ||
|
|
67d094f51a | ||
|
|
873af04c6e | ||
|
|
2f0439dca8 | ||
|
|
8470c6a980 | ||
|
|
43092ba1d7 | ||
|
|
1920192656 | ||
|
|
61487db481 | ||
|
|
f56feaf821 | ||
|
|
4cbd5a4c6c | ||
|
|
65aa5629e8 | ||
|
|
c42c8ba505 | ||
|
|
7193d09bed | ||
|
|
49f8fae0b4 | ||
|
|
e1a490756e | ||
|
|
c313ea7ee2 | ||
|
|
91bfaf36e3 | ||
|
|
e3ea9212dd | ||
|
|
99d41d8cc6 | ||
|
|
8988c1e760 | ||
|
|
465adf5b1f | ||
|
|
132d00d166 | ||
|
|
b1a5f8e730 | ||
|
|
a604fee3aa | ||
|
|
8018325923 | ||
|
|
3f86bd4009 | ||
|
|
b4cf10214b | ||
|
|
c7818c2c33 | ||
|
|
e421bcc326 | ||
|
|
09e5a4dcc0 | ||
|
|
ce08c44235 | ||
|
|
e743234324 | ||
|
|
9b76ac48b7 | ||
|
|
06a9adb051 | ||
|
|
6ae16345a8 | ||
|
|
8daaf000b1 | ||
|
|
9ce753055c | ||
|
|
0ce87b5155 | ||
|
|
273f411eee | ||
|
|
6929cecf8a | ||
|
|
9221a7ff03 | ||
|
|
a6089c5b3b | ||
|
|
a7ee972b32 | ||
|
|
c817989b99 | ||
|
|
2272a6854c | ||
|
|
040fc1ee8d | ||
|
|
f00b8d7b8c | ||
|
|
6c8c6d7048 | ||
|
|
f27ef52c7a | ||
|
|
0a2ff1db97 | ||
|
|
6da48eac6f | ||
|
|
638ff04e24 | ||
|
|
d7075b459b | ||
|
|
d0e7aa14b6 | ||
|
|
59fee56c54 | ||
|
|
2207306169 | ||
|
|
8ff2e91f2d | ||
|
|
730370a007 | ||
|
|
f87909109c | ||
|
|
d6a6d8b5ef | ||
|
|
57563abfa7 | ||
|
|
61afaa4c8b | ||
|
|
0de47dbc3f | ||
|
|
676ef56134 | ||
|
|
f0899bb35d | ||
|
|
f490038e36 | ||
|
|
cbf220eb00 | ||
|
|
bf0d80ea20 | ||
|
|
3ae889a6f8 | ||
|
|
03ca1067ac | ||
|
|
3cda30a40a | ||
|
|
26934527b9 | ||
|
|
2619acde22 | ||
|
|
b983d3cfd2 | ||
|
|
87a9dd15fe | ||
|
|
4066962ade | ||
|
|
0f26e34f09 | ||
|
|
d76e436e3d | ||
|
|
4ff531dec7 | ||
|
|
4f8b3d7aff | ||
|
|
210fa9c474 | ||
|
|
25361cac8c | ||
|
|
28defebd6d | ||
|
|
c74381619e | ||
|
|
d58f3103dd | ||
|
|
5d1ed35660 | ||
|
|
1f3e305534 | ||
|
|
7d8fdd279c | ||
|
|
cacae9f290 | ||
|
|
bb061b770f | ||
|
|
a8768b9ed6 | ||
|
|
b437aa5f6c | ||
|
|
9248182570 | ||
|
|
511c1a6ed5 | ||
|
|
7c77c7170f | ||
|
|
85fcb6516c | ||
|
|
e8e76d85f7 | ||
|
|
5aaa5ae4d5 | ||
|
|
c3a8ee9c7b | ||
|
|
5d07a8aba5 | ||
|
|
d18e0594b8 | ||
|
|
26dcc86a24 | ||
|
|
e928ad19e5 | ||
|
|
6768aaa575 | ||
|
|
f561aacbfc | ||
|
|
af1ece40c2 | ||
|
|
d9edd7adf7 | ||
|
|
3541fab363 | ||
|
|
1160dceeff | ||
|
|
bbe8efeba2 | ||
|
|
b4a5323009 | ||
|
|
ade8b5b9a7 | ||
|
|
e4ace3d484 | ||
|
|
f3dd25adc5 | ||
|
|
ec251f8168 | ||
|
|
1bb9579dc5 | ||
|
|
7ebf4146ce | ||
|
|
a8db4cb2f5 | ||
|
|
24433396dd | ||
|
|
02bdf17641 | ||
|
|
e0e05f3488 | ||
|
|
c92f2510c8 | ||
|
|
ea1fbe9ee1 | ||
|
|
84a0be0179 | ||
|
|
54f5c0dc91 | ||
|
|
adf1a10318 | ||
|
|
e2a679a265 | ||
|
|
a3916a6932 | ||
|
|
1b5780461e | ||
|
|
c8d35b63a4 | ||
|
|
feb1ebae04 | ||
|
|
efe49d0a5b | ||
|
|
e50a5ea22a | ||
|
|
6382c94d0a | ||
|
|
58ce84c9cc | ||
|
|
08fd6ff765 | ||
|
|
a9cb79909c | ||
|
|
852f8ccd94 | ||
|
|
9388ef3e99 | ||
|
|
04afb0c4bb | ||
|
|
a07fd44de3 | ||
|
|
f6c1b13846 | ||
|
|
654fa3dd1f | ||
|
|
8183449d27 | ||
|
|
a9acfb86ad | ||
|
|
d7d070ac5f | ||
|
|
ead51f1eb6 | ||
|
|
8c01b573ce | ||
|
|
7744f21b9d | ||
|
|
9ed23a235f | ||
|
|
e88328321f | ||
|
|
a4c516bea1 | ||
|
|
1c932a04ef | ||
|
|
76d34be4c2 | ||
|
|
cb0e9ff9ec | ||
|
|
d6e8afe316 | ||
|
|
a04f2bcf99 | ||
|
|
c138e7c638 | ||
|
|
fc08c7007f | ||
|
|
d559bb3446 | ||
|
|
55a8c39e4b | ||
|
|
02d6f10e5f | ||
|
|
77428a91cc | ||
|
|
51403dc276 | ||
|
|
914a07a35d | ||
|
|
3c70d7b424 | ||
|
|
ce1ee4ff17 | ||
|
|
fca41d9bda | ||
|
|
ff889e02f7 | ||
|
|
cbd2c86bbf | ||
|
|
43ab460462 | ||
|
|
caa06e266b | ||
|
|
3622ca78ee | ||
|
|
019e3f9659 | ||
|
|
208cb579a2 | ||
|
|
17de7e4485 | ||
|
|
810616eee1 | ||
|
|
191f583669 | ||
|
|
1d638cc18e | ||
|
|
3efa1f3b88 | ||
|
|
4daa33db09 | ||
|
|
fab2fb0056 | ||
|
|
ce885c120e | ||
|
|
75b53c47ff | ||
|
|
2936f73707 | ||
|
|
e26426b138 | ||
|
|
62cacb8e28 | ||
|
|
f3e37190ce | ||
|
|
0863bbbd2f | ||
|
|
b23fa1daad | ||
|
|
05cc1ce599 | ||
|
|
a1c045fd91 | ||
|
|
e6939f8d51 | ||
|
|
801fef12e1 | ||
|
|
5845629175 | ||
|
|
11b916301a | ||
|
|
aa5d80b1d2 | ||
|
|
aa5f990acd | ||
|
|
9764c82c2a | ||
|
|
f921846879 | ||
|
|
a370403b16 | ||
|
|
543a71eb6c | ||
|
|
8285593c13 | ||
|
|
6fbfe773fb | ||
|
|
a8c54b1e5f | ||
|
|
a5323abfca | ||
|
|
ba4df2d2c4 | ||
|
|
6510633a8c | ||
|
|
9172e5f46b | ||
|
|
ed3e3848c0 | ||
|
|
ee90185d5c | ||
|
|
6eb2633677 | ||
|
|
c1f215dcf2 | ||
|
|
97cc9a1045 | ||
|
|
5f7b02a4b7 | ||
|
|
ad6d504ea4 | ||
|
|
e696b41a0e | ||
|
|
1f9acc6135 | ||
|
|
7e8699cb4b | ||
|
|
fd4fc657d6 | ||
|
|
34403648b9 | ||
|
|
3795d50eb9 | ||
|
|
80515dde5a | ||
|
|
b59094d35f | ||
|
|
efcd296d83 | ||
|
|
802cb292b0 | ||
|
|
8e55f74d73 | ||
|
|
3d810485a0 | ||
|
|
94cfd48661 | ||
|
|
87c8e741f3 | ||
|
|
d0e92ed18d | ||
|
|
88640f9222 | ||
|
|
1927045519 | ||
|
|
68cffb86c9 | ||
|
|
5bec989647 | ||
|
|
66f5d2f36c | ||
|
|
941f815254 | ||
|
|
42afd10518 | ||
|
|
3efa285a59 | ||
|
|
4f2b4172b4 | ||
|
|
0d7de71b94 | ||
|
|
f0f5b4bede | ||
|
|
bfd27e97d3 | ||
|
|
f2def27390 | ||
|
|
b3f7bd6cc0 | ||
|
|
0e8e78dc5b | ||
|
|
b259d85776 | ||
|
|
175d9c3b7c | ||
|
|
a2a810aabf | ||
|
|
175c7cfd51 | ||
|
|
5ada973d38 | ||
|
|
0103276136 | ||
|
|
1d9e8ec138 | ||
|
|
83ac2e71bb | ||
|
|
0b35a729a7 | ||
|
|
56723a519a | ||
|
|
ebff394c76 | ||
|
|
ceecc97bc8 | ||
|
|
313154f880 | ||
|
|
3eb6417cdc | ||
|
|
1b35d6ca0a | ||
|
|
1d89f0ba9d | ||
|
|
864df0e21a | ||
|
|
3f626decc4 | ||
|
|
bf1760b1a9 | ||
|
|
8a58ea6344 | ||
|
|
662ff4c35f | ||
|
|
af02352b49 | ||
|
|
db9f987d46 | ||
|
|
8490ce1389 | ||
|
|
55ea9a56a4 | ||
|
|
bd2381b10d | ||
|
|
443de755bd | ||
|
|
55ec5f14ee | ||
|
|
2e019302c9 | ||
|
|
b1e829644b | ||
|
|
18f773e91b | ||
|
|
987cfee930 | ||
|
|
57f6b8498a | ||
|
|
9f0d35977c | ||
|
|
e5910bbf2f | ||
|
|
0015bf7b38 | ||
|
|
a6b9234abb | ||
|
|
086f3942b8 | ||
|
|
924f4abede | ||
|
|
02be91cb08 | ||
|
|
c2298393ab | ||
|
|
4b8c63bf6e | ||
|
|
e089c3b72c | ||
|
|
a93983b5db | ||
|
|
20f6329004 | ||
|
|
3c2cf71c47 | ||
|
|
56288c3137 | ||
|
|
79188921a5 | ||
|
|
65962ddf58 | ||
|
|
5ab66008ae | ||
|
|
f38c9ee049 | ||
|
|
86f5e71ec2 | ||
|
|
1e15cc8495 | ||
|
|
bba44430c4 | ||
|
|
077d82ad82 | ||
|
|
e4cf7f3da2 | ||
|
|
e3bdc9e8d7 | ||
|
|
f1c1c9aab3 | ||
|
|
97cbcf7658 | ||
|
|
69c71d77fb | ||
|
|
4860739a2f | ||
|
|
791ee40cd6 | ||
|
|
e0191ac52b | ||
|
|
e0724df196 | ||
|
|
2a56294638 | ||
|
|
d5cd557013 | ||
|
|
2a43f23a3d | ||
|
|
69af8f569a | ||
|
|
dcc11c9ea3 | ||
|
|
4b4abb47b0 | ||
|
|
0e86dbcc9b | ||
|
|
92c75aa6f5 | ||
|
|
be41d848e5 | ||
|
|
f7c299f6f0 | ||
|
|
b6a0f65a09 | ||
|
|
1e7b0068ed | ||
|
|
207d2fb911 | ||
|
|
de5105f313 | ||
|
|
c65a99c87d | ||
|
|
b4d7e57250 | ||
|
|
63845a07aa | ||
|
|
68ac73aa55 | ||
|
|
6d32f1bb36 | ||
|
|
9c316cee28 | ||
|
|
6af4f2d6e6 | ||
|
|
bc9a43d5a9 | ||
|
|
7c7b60a5e9 | ||
|
|
3f0b8bff5b | ||
|
|
57651900f1 | ||
|
|
46b0617018 | ||
|
|
91190cf82d | ||
|
|
7b98a6613a | ||
|
|
26481e27a6 | ||
|
|
87a26db779 | ||
|
|
bb227b3d73 | ||
|
|
8a0cf5e0ae | ||
|
|
69218d5699 | ||
|
|
7d1433af21 | ||
|
|
0bfbf1e9c5 | ||
|
|
1ca4f5b22b | ||
|
|
0984e4c1e8 | ||
|
|
7d9bd2e86b | ||
|
|
4cbf5a7434 | ||
|
|
b33178c5be | ||
|
|
dc6a336c60 | ||
|
|
20ef5cb14f | ||
|
|
2c3ec7e74c | ||
|
|
b855336448 | ||
|
|
de021977fd | ||
|
|
cd2b3fcd16 | ||
|
|
b64024ede5 | ||
|
|
a280d23113 | ||
|
|
41785abdba | ||
|
|
de494c7e55 | ||
|
|
5fa0903ea8 | ||
|
|
7bd99fe074 | ||
|
|
c838e1ca6d | ||
|
|
f475923353 | ||
|
|
43f43c92e3 | ||
|
|
5463134322 | ||
|
|
3fbb392103 | ||
|
|
a162da17e1 | ||
|
|
b565134d57 | ||
|
|
3aafc89912 | ||
|
|
93449f92fe | ||
|
|
d766e68d42 | ||
|
|
1d8b1f9774 | ||
|
|
5ea9abae83 | ||
|
|
15957499c5 | ||
|
|
0b50d9e874 | ||
|
|
cce073dbdb | ||
|
|
a1e54922bd | ||
|
|
63c0ca34ea | ||
|
|
135477e516 | ||
|
|
8cac49cd91 | ||
|
|
28dce63682 | ||
|
|
313ac952e0 | ||
|
|
0633d5130b | ||
|
|
995e487b49 | ||
|
|
64b58b57e0 | ||
|
|
c6465908df | ||
|
|
ca96bcc09f | ||
|
|
65ee628fae | ||
|
|
02043614e5 | ||
|
|
212b9bf9d4 | ||
|
|
6070c30a88 | ||
|
|
8a653e51bc | ||
|
|
6a92588264 | ||
|
|
276aad6f0d | ||
|
|
10620bda4f | ||
|
|
c214401a00 | ||
|
|
260ac33324 | ||
|
|
d4cd643860 | ||
|
|
dc16cfda21 | ||
|
|
d562670425 | ||
|
|
677bee6fe5 | ||
|
|
de27bfe76f | ||
|
|
1c1dcb9c33 | ||
|
|
4ba950f155 | ||
|
|
9c3a11d7bb | ||
|
|
b7d357aea2 | ||
|
|
b2fed68346 | ||
|
|
0e996928be | ||
|
|
6ff4ec3643 | ||
|
|
a0eda3e492 | ||
|
|
099f9514ef | ||
|
|
b2096e4a55 | ||
|
|
1bf2164745 | ||
|
|
48205bbde7 | ||
|
|
296aab6ecb | ||
|
|
14182c45fc | ||
|
|
2fa8f4283c | ||
|
|
ad3cec2361 | ||
|
|
eddb628298 | ||
|
|
f63b226d8d | ||
|
|
cc5bd61d86 | ||
|
|
8bd14fb16f | ||
|
|
30b5472e33 | ||
|
|
bc836db0f9 | ||
|
|
bd3b0fb8eb | ||
|
|
7f28474967 | ||
|
|
09460b28bc | ||
|
|
5d8ba1e49c | ||
|
|
ccb394675b | ||
|
|
931487a7d4 | ||
|
|
3654c57f66 | ||
|
|
fb28280ced | ||
|
|
6215441b58 | ||
|
|
52f16d5bb6 | ||
|
|
e5b6c8581a | ||
|
|
e1db3a4af9 | ||
|
|
5dcca99913 | ||
|
|
890b906f15 | ||
|
|
6a8286d4cf | ||
|
|
680024f790 | ||
|
|
6f7bfb92a8 | ||
|
|
335a9603e8 | ||
|
|
5e8a6202e7 | ||
|
|
55a4cdefd7 | ||
|
|
2b63135afb | ||
|
|
49d8c3572d | ||
|
|
4b40962186 | ||
|
|
779b376c6e | ||
|
|
4e2a9a247a | ||
|
|
b1f3d6b155 | ||
|
|
ea28a9d3c3 | ||
|
|
69a03e463f | ||
|
|
e7da62e61c | ||
|
|
7176745e1c | ||
|
|
cce0e26f5c | ||
|
|
641af16dfc | ||
|
|
a335c427ef | ||
|
|
9ea6c959ae | ||
|
|
20efd523c9 | ||
|
|
8fc7fff496 | ||
|
|
edf51e6996 | ||
|
|
6b867883ce | ||
|
|
35a05f4120 | ||
|
|
e0e78a97ce | ||
|
|
ddd30a950d | ||
|
|
e4e476f463 | ||
|
|
3ca0e63d54 | ||
|
|
c4c8917ecb | ||
|
|
1524d2ef00 | ||
|
|
5032834034 | ||
|
|
0b83f6ea99 | ||
|
|
415201f467 | ||
|
|
73005a8498 | ||
|
|
4edb960fbd | ||
|
|
42d11ead01 | ||
|
|
5e18f85b10 | ||
|
|
85b25bf006 | ||
|
|
c1ba108489 | ||
|
|
214098aaae | ||
|
|
241a0b7adc | ||
|
|
9a7b41a4be | ||
|
|
fe918adb16 | ||
|
|
746f026654 | ||
|
|
8294cd3dd9 | ||
|
|
3bbc63b1db | ||
|
|
337fb6d922 | ||
|
|
bda6b18e8a | ||
|
|
d256ff929f | ||
|
|
f71b20cf07 | ||
|
|
db26b0afd6 | ||
|
|
145860f42e | ||
|
|
d9f84648d0 | ||
|
|
9fb7e0bae7 | ||
|
|
b00203702e | ||
|
|
ead85dd41f | ||
|
|
cf5bf6f174 | ||
|
|
46237e7309 | ||
|
|
afa686b47b | ||
|
|
21e02c9e50 | ||
|
|
30a188d7c8 | ||
|
|
355f51b25e | ||
|
|
8e1cde86e8 | ||
|
|
c13b02c7d9 | ||
|
|
9e72801c28 | ||
|
|
3a3d538b73 | ||
|
|
b11bca0c67 | ||
|
|
faf8975b42 | ||
|
|
863168880e | ||
|
|
384a1f0560 | ||
|
|
4bd1b1b9e6 | ||
|
|
8c3866a014 | ||
|
|
61283d9bd6 | ||
|
|
585a7186d4 | ||
|
|
72a31c2a65 | ||
|
|
10d9e54857 | ||
|
|
e68695ee92 | ||
|
|
11379fc0ef | ||
|
|
6d102382bd | ||
|
|
56335927e7 | ||
|
|
a3fe994b22 | ||
|
|
5754bdcc78 | ||
|
|
eef2fa9ffb | ||
|
|
7286907cd4 | ||
|
|
754e33a1ae | ||
|
|
1fbb431f1b | ||
|
|
0ad52b90d8 | ||
|
|
c44b12cc8b | ||
|
|
8381c95617 | ||
|
|
3963855d1d | ||
|
|
51154a3070 | ||
|
|
b11b43bbe1 | ||
|
|
7a7ece1805 | ||
|
|
28a71b70a8 | ||
|
|
33d3a13fde | ||
|
|
5ea278a08d | ||
|
|
fd95f8da28 | ||
|
|
86f4645d1c | ||
|
|
2d05e96cd5 | ||
|
|
c1d5952ad9 | ||
|
|
ebeac68707 | ||
|
|
72673e12fb | ||
|
|
3867d3926b | ||
|
|
0b2b7a2622 | ||
|
|
3951ee1a7d | ||
|
|
1afde51c7b | ||
|
|
cbeef18f0a | ||
|
|
de5fcab933 | ||
|
|
a7a2100472 | ||
|
|
1947d8c3ca | ||
|
|
55c63736ef | ||
|
|
a2b68d893f | ||
|
|
fd06e43d9c | ||
|
|
b550f6efa0 | ||
|
|
47adf88773 | ||
|
|
9c44d3b793 | ||
|
|
9b89ac694e | ||
|
|
8748da38cf | ||
|
|
f697dc99fb | ||
|
|
630d8208cf | ||
|
|
ecb038c955 | ||
|
|
77ff31cec6 | ||
|
|
9b342dc593 | ||
|
|
5ea8677a5d | ||
|
|
ad879de6ff | ||
|
|
97f5b3423f | ||
|
|
4968207eef | ||
|
|
f859e2203a | ||
|
|
fb3dad4354 | ||
|
|
adc82c6a65 | ||
|
|
96084fea16 | ||
|
|
6f52026c84 | ||
|
|
3576218ea9 | ||
|
|
4c662db530 | ||
|
|
da1ce4e5a7 | ||
|
|
c4944c5662 | ||
|
|
d892f87651 | ||
|
|
447f23d157 | ||
|
|
aa12f0d295 | ||
|
|
795266aab4 | ||
|
|
4e4ef121f9 | ||
|
|
ddb9126955 | ||
|
|
bac6d6dd68 | ||
|
|
de9226aae0 | ||
|
|
16e1ab1a87 | ||
|
|
54287e06ad | ||
|
|
3451570541 | ||
|
|
b33de5f0e1 | ||
|
|
2d5ef20d4d | ||
|
|
177346b159 | ||
|
|
08819b1609 | ||
|
|
e5e939f344 | ||
|
|
0d51d25482 | ||
|
|
35b1332551 | ||
|
|
52586a024b | ||
|
|
05a314b121 | ||
|
|
a0a5b10df0 | ||
|
|
04bac93c14 | ||
|
|
8e262e2270 | ||
|
|
4961d3ba8c | ||
|
|
733bb4d2dd | ||
|
|
ba31c760a6 | ||
|
|
a388bc6837 | ||
|
|
3f5bbbf1e3 | ||
|
|
002da15375 | ||
|
|
005609da3a | ||
|
|
182d9ca6f9 | ||
|
|
a6b43f8016 | ||
|
|
31700fa8da | ||
|
|
6b475ec1cf | ||
|
|
1b27844c52 | ||
|
|
3a0b91f7ab | ||
|
|
82108e32fa | ||
|
|
28f4fecfb3 | ||
|
|
ff1bb08217 | ||
|
|
10617fee0d | ||
|
|
866103ddf4 | ||
|
|
fcfaca6bd0 | ||
|
|
4c7d9ab0fb | ||
|
|
061aec4b3d | ||
|
|
047f4a1a0c | ||
|
|
f12ab10725 | ||
|
|
0882fa6ce5 | ||
|
|
7994b90dfa | ||
|
|
04b6a80370 | ||
|
|
0b87e4c45d | ||
|
|
9c7e846828 | ||
|
|
30bd0e483a | ||
|
|
13cc93c334 | ||
|
|
564b1bb752 | ||
|
|
2f31a92d31 | ||
|
|
fd89c7f56f | ||
|
|
35738c8279 | ||
|
|
a0d14b8a25 | ||
|
|
9c781ed78e | ||
|
|
460a24e34a | ||
|
|
0f8627f17a | ||
|
|
8ae030e16e | ||
|
|
3c6467c814 | ||
|
|
2f11f0c911 | ||
|
|
c3ae67fb1d | ||
|
|
8c750c7edd | ||
|
|
571838a289 | ||
|
|
dafaaae792 | ||
|
|
b45e14efb4 | ||
|
|
e70cbf26e2 | ||
|
|
daafdc3704 | ||
|
|
6661934fed | ||
|
|
f568728de1 | ||
|
|
263d35bbd6 | ||
|
|
bece21d217 | ||
|
|
d4788e147a | ||
|
|
f4594ecf37 | ||
|
|
8f1462cb79 | ||
|
|
76d4d0de69 | ||
|
|
6ab4e1d641 | ||
|
|
fc0c3e169f | ||
|
|
4760f95bda | ||
|
|
c5d87c99fd | ||
|
|
f53f403022 | ||
|
|
b887b2951e | ||
|
|
842b69b155 | ||
|
|
d6c34106fc | ||
|
|
67cbd31280 | ||
|
|
cd0cf69099 | ||
|
|
cf877f2b49 | ||
|
|
6f34cb2c8a | ||
|
|
a04a8a866d | ||
|
|
b88aa2b53c | ||
|
|
356cab19eb | ||
|
|
7c6d5fa446 | ||
|
|
2dae3e47fd | ||
|
|
6fce789607 | ||
|
|
9bbb5b38e6 | ||
|
|
ac73aa93bf | ||
|
|
52a56e4a10 | ||
|
|
a1cede510d | ||
|
|
682c10e873 | ||
|
|
5605e24a0d | ||
|
|
f7268a44d9 | ||
|
|
af7a4ff4e8 | ||
|
|
60b9c0d763 | ||
|
|
5c550270c6 | ||
|
|
e03fd48e48 | ||
|
|
6420c74c24 | ||
|
|
ad74351530 | ||
|
|
1b5f656429 | ||
|
|
132d84c529 | ||
|
|
a03b378e9b | ||
|
|
74635e1d7d | ||
|
|
893053ede7 | ||
|
|
596ec6fec5 | ||
|
|
5863b83172 | ||
|
|
20c92b197a | ||
|
|
8c9baa62b0 | ||
|
|
ec9c6b4666 | ||
|
|
8a73e5c119 | ||
|
|
717f0eee9a | ||
|
|
09fb47f089 | ||
|
|
b46d943e71 | ||
|
|
262eaa6d84 | ||
|
|
b980d6f6ab | ||
|
|
61f27369ef | ||
|
|
204b0b4744 | ||
|
|
fc1a48f3bc | ||
|
|
060f320cd1 | ||
|
|
1b6ebb1e42 | ||
|
|
bff32bcaa3 | ||
|
|
7dfc75b3e6 | ||
|
|
2920b5ab01 | ||
|
|
81ad0467b0 | ||
|
|
115ca55ea0 | ||
|
|
f2814a26e6 | ||
|
|
4d309950b0 | ||
|
|
39216a4c12 | ||
|
|
c7fa621aeb | ||
|
|
5914d28cbe | ||
|
|
8c3ad3d70a | ||
|
|
9eb3fc6285 | ||
|
|
e95f7e7339 | ||
|
|
d949551399 | ||
|
|
a7dbd85ed4 | ||
|
|
1f288dab1c | ||
|
|
021754d941 | ||
|
|
7412904fbf | ||
|
|
cd1976e2b9 | ||
|
|
5f3e9379a3 | ||
|
|
0e565d6cea | ||
|
|
67b249dcd5 | ||
|
|
bbf1c8c790 | ||
|
|
9744363342 | ||
|
|
6fe8439e94 | ||
|
|
8e61ffe377 | ||
|
|
723476f7a7 | ||
|
|
41cd11d5c9 | ||
|
|
0f253027ae | ||
|
|
6053895a82 | ||
|
|
44a8b453b5 | ||
|
|
26511fe962 | ||
|
|
ce5893216a | ||
|
|
4e821e4dbf | ||
|
|
d11e97de59 | ||
|
|
4b10d3e360 | ||
|
|
e04479930f | ||
|
|
8a8c4cc3f5 | ||
|
|
1e06ff611e | ||
|
|
1edc7bb9c7 | ||
|
|
ceffa38717 | ||
|
|
7b1e0af155 | ||
|
|
7b15616e29 | ||
|
|
ae205fa3f2 | ||
|
|
bd7d2277d8 | ||
|
|
99ed00fd02 | ||
|
|
f7af5f9ee8 | ||
|
|
e5bcc8005f | ||
|
|
352d285212 | ||
|
|
3ef60f9d14 | ||
|
|
a103312127 | ||
|
|
3d0bba4167 | ||
|
|
3df718cc14 | ||
|
|
c7497a180e | ||
|
|
3f39039a21 | ||
|
|
88fbd90fcc | ||
|
|
e0bf09dd78 | ||
|
|
3e158b07af | ||
|
|
5319ed7ee1 | ||
|
|
978904d2a4 | ||
|
|
4d876ecc54 | ||
|
|
ba327d0b9e | ||
|
|
b69cf3523c | ||
|
|
4d8c8e9308 | ||
|
|
669a05892b | ||
|
|
b70885934c | ||
|
|
722b087fc0 | ||
|
|
4898a9759a | ||
|
|
2c2fa25580 | ||
|
|
56496d7dbd | ||
|
|
0c7ea272db | ||
|
|
dd0696e44d | ||
|
|
dcda273e0b | ||
|
|
f3b159c650 | ||
|
|
06df037e28 | ||
|
|
e814e516d1 | ||
|
|
0375e068ed | ||
|
|
34ffc533d3 | ||
|
|
5e4f322fc0 | ||
|
|
c02e45f1aa | ||
|
|
a7217f138c | ||
|
|
ea2ea1a4ae | ||
|
|
9e11947687 | ||
|
|
47117281e1 | ||
|
|
032dd13f5a | ||
|
|
3502f25048 | ||
|
|
13d8ebbeff | ||
|
|
93c026fe31 | ||
|
|
e515977b96 | ||
|
|
045490a097 | ||
|
|
b25903fb7f | ||
|
|
acf4bd5152 | ||
|
|
1f5711e1a1 | ||
|
|
ca2dd90313 | ||
|
|
21e07f3b65 | ||
|
|
e8a06ddd34 | ||
|
|
34cc09904f | ||
|
|
f6bba8b62f | ||
|
|
d241ad60f8 | ||
|
|
5a3fcf9a8a | ||
|
|
1f8a47203f | ||
|
|
7240090274 | ||
|
|
2e6a47c2df | ||
|
|
7f5ecd7913 | ||
|
|
105b98b113 | ||
|
|
114e65ab41 | ||
|
|
0fc13a5cc3 | ||
|
|
2efa0e01df | ||
|
|
e651799e9e | ||
|
|
fcd3e514de | ||
|
|
7ab41de3a2 | ||
|
|
58e023f277 | ||
|
|
a98f2d5b86 | ||
|
|
6044369fdf | ||
|
|
eca43231c0 | ||
|
|
6763077887 | ||
|
|
f85ff8a2f8 | ||
|
|
1a5c3480e6 | ||
|
|
69a7fe7b92 | ||
|
|
a5418d760f | ||
|
|
0deeb87c63 | ||
|
|
d1d5f49c5a | ||
|
|
917e23ccc8 | ||
|
|
988922304f | ||
|
|
ab2bd726c3 | ||
|
|
713fefb163 | ||
|
|
83140a1398 | ||
|
|
cafa6dd930 | ||
|
|
82e1af1a7a | ||
|
|
30c3dc9205 | ||
|
|
9a3c6703e1 | ||
|
|
e26468aa19 | ||
|
|
fe14992696 | ||
|
|
d0775b95c6 | ||
|
|
96121b5757 | ||
|
|
11c003c48d | ||
|
|
fbe72c58ae | ||
|
|
816156e87f | ||
|
|
7bceab3cea | ||
|
|
83d7f56728 | ||
|
|
76deba2a6a | ||
|
|
d9d048b9e3 | ||
|
|
930f417729 | ||
|
|
8e214d06c1 | ||
|
|
63e0348963 | ||
|
|
b46a5f0247 | ||
|
|
79dfd90068 | ||
|
|
f9d5c7c751 | ||
|
|
8958fb2d88 | ||
|
|
40e74e408b | ||
|
|
3c51f2ac36 | ||
|
|
170a0918f7 | ||
|
|
e3da3b619c | ||
|
|
97440f9e8a | ||
|
|
6e32513b79 | ||
|
|
520e1963ee | ||
|
|
843b9b55e2 | ||
|
|
ccd305ff96 | ||
|
|
3bd0d1e48c | ||
|
|
d9bfa8e675 | ||
|
|
27746147e2 | ||
|
|
3a0b642980 | ||
|
|
8c0241f087 | ||
|
|
958d016174 | ||
|
|
913d318ada | ||
|
|
8212920cb7 | ||
|
|
6414be7bd4 | ||
|
|
ac62a82d08 | ||
|
|
a670548a57 | ||
|
|
c4a7463f9d | ||
|
|
edf0ac5270 | ||
|
|
8ff6b76f37 | ||
|
|
c9f9eb365c | ||
|
|
7a17c115d3 | ||
|
|
9a2a11055f | ||
|
|
f21aecd91c | ||
|
|
4aef73c1d7 | ||
|
|
906480a6e8 | ||
|
|
9df147b450 | ||
|
|
b71b4b0fc2 | ||
|
|
1bd2510c52 | ||
|
|
28b81092f9 | ||
|
|
4b9a3abba6 | ||
|
|
0c76b6dcb1 | ||
|
|
090a85b41b | ||
|
|
992d573573 | ||
|
|
9e768e660b | ||
|
|
26b9ed362e | ||
|
|
765f7cae58 | ||
|
|
b455c8a2ad | ||
|
|
976ae75fde | ||
|
|
9da91b5319 | ||
|
|
2493beaf5a | ||
|
|
d63dd021ab | ||
|
|
da25e0ffa5 | ||
|
|
697ba89314 | ||
|
|
b6c65ab5d5 | ||
|
|
162f9a55ad | ||
|
|
e484fdfa51 | ||
|
|
77d9ccf2e4 | ||
|
|
94e39ee09e | ||
|
|
373ad77008 | ||
|
|
661b0c0038 | ||
|
|
8ed38bf0e2 | ||
|
|
4d675dfff7 | ||
|
|
b42a3293f1 | ||
|
|
87e9bf853d | ||
|
|
c56f78422a | ||
|
|
ac311e10ba | ||
|
|
0297520263 | ||
|
|
4803552a7a | ||
|
|
b8d85ff723 | ||
|
|
7d571dfaec | ||
|
|
ba02e53bdd | ||
|
|
153e6142ff | ||
|
|
228449c9d8 | ||
|
|
c65eed8802 | ||
|
|
40d32f2e01 | ||
|
|
c83aac5e12 | ||
|
|
48b9241247 | ||
|
|
7779bc5336 | ||
|
|
beec549f74 | ||
|
|
310698ecc0 | ||
|
|
4f719c4778 | ||
|
|
4cc00f3bdc | ||
|
|
1f9c47fef1 | ||
|
|
80a4980640 | ||
|
|
8dbe424f5a | ||
|
|
ec9bf033e6 | ||
|
|
a2d21ec7bc | ||
|
|
06ccc853ee | ||
|
|
4847332161 | ||
|
|
8c1ee54725 | ||
|
|
5e537d9d55 | ||
|
|
d6b95067a1 | ||
|
|
32cae75ef5 | ||
|
|
21e7554cdb | ||
|
|
e07703c01f | ||
|
|
374442e900 | ||
|
|
a1a0ec5ddb | ||
|
|
1fd56b079c | ||
|
|
a12163d63f | ||
|
|
0cd6f21980 | ||
|
|
a88fc1d75c | ||
|
|
87b0037fcd | ||
|
|
767d32d420 | ||
|
|
e9bde26611 | ||
|
|
c02f40622c | ||
|
|
929dc24e93 | ||
|
|
8cfb533fef | ||
|
|
3328a388b3 | ||
|
|
8f632eb005 | ||
|
|
c8ee961436 | ||
|
|
6fd7efece6 | ||
|
|
bc9f6b0af8 | ||
|
|
7d48f17867 | ||
|
|
776583b3ad | ||
|
|
9c28dae583 | ||
|
|
59a315b90b | ||
|
|
866518f188 | ||
|
|
736ae65a1d | ||
|
|
76c9f7c9a9 | ||
|
|
32ad225d7f | ||
|
|
e5428bec5c | ||
|
|
7ae6f67470 | ||
|
|
faf534511b | ||
|
|
594bceb8f5 | ||
|
|
9dc0f48ec9 | ||
|
|
9d11f834b8 | ||
|
|
a4abf3eb2b | ||
|
|
269d72d073 | ||
|
|
c8f5dccbd2 | ||
|
|
8b797ee73f | ||
|
|
de38adb1e4 | ||
|
|
c169bcc5d8 | ||
|
|
131b72cd0c | ||
|
|
80ea286beb | ||
|
|
ce5a2d4a81 | ||
|
|
3499be782e | ||
|
|
7f489cee46 | ||
|
|
3c2d669a2f | ||
|
|
16603ae49c | ||
|
|
bf6bd9ce7f | ||
|
|
a54c0f6f46 | ||
|
|
beeed11d48 | ||
|
|
ec36e96499 | ||
|
|
9ecd4980e4 | ||
|
|
64446ff9b6 | ||
|
|
e3d2262292 | ||
|
|
891cfa387a | ||
|
|
f0243fddf2 | ||
|
|
85ff8e364b | ||
|
|
75f1afe8e3 | ||
|
|
7b660311e5 | ||
|
|
98a493296d | ||
|
|
bc2a42aed2 | ||
|
|
8b501d9091 | ||
|
|
25331590a7 | ||
|
|
cddae0ed18 | ||
|
|
9dca42be27 | ||
|
|
a1f3fe4d55 | ||
|
|
0304b392b2 | ||
|
|
ae9b4e82fe | ||
|
|
4bac5e4c46 | ||
|
|
c4d3400ec4 | ||
|
|
1da9bb0c0f | ||
|
|
760ed51ad3 | ||
|
|
bff9f8976e | ||
|
|
b71628e211 | ||
|
|
6d0a3b952a | ||
|
|
8c1cb1f55b | ||
|
|
66214384a9 | ||
|
|
6d6646887c | ||
|
|
6f8db0ed08 | ||
|
|
6aaf6836ea | ||
|
|
4f2348f50e | ||
|
|
873fcd5822 | ||
|
|
a08f3a8925 | ||
|
|
2a98d3a489 | ||
|
|
b681ba03b1 | ||
|
|
fe775a36c0 | ||
|
|
2df9adcb43 | ||
|
|
c756cbf6d5 | ||
|
|
d0ac67c9d3 | ||
|
|
47cd55052f | ||
|
|
fb203b5bdf | ||
|
|
6ee47e243d | ||
|
|
c1844b7a9d | ||
|
|
99a29e79e5 | ||
|
|
589a66ef26 | ||
|
|
3f960763cb | ||
|
|
15f8f3783c | ||
|
|
a2b045c7e3 | ||
|
|
055cef2fdc | ||
|
|
6c6c69cbc3 | ||
|
|
6fe0062e6e | ||
|
|
26b8b2f448 | ||
|
|
7e40d6950a | ||
|
|
590bfa92cb | ||
|
|
f0e89a1720 | ||
|
|
575563b1e8 | ||
|
|
82ea0e47ce | ||
|
|
2f57ca10f7 | ||
|
|
75c2d541c4 | ||
|
|
b666f8b50b | ||
|
|
09f9322676 | ||
|
|
f9a864ef93 | ||
|
|
27f28afe9c | ||
|
|
8f85722fef | ||
|
|
5588445a01 | ||
|
|
40529b5722 | ||
|
|
cee632f50c | ||
|
|
3453e3aa05 | ||
|
|
8de637c421 | ||
|
|
6c75de862c | ||
|
|
2971134882 | ||
|
|
6e79860b43 | ||
|
|
3f6bdda2a0 | ||
|
|
74d0287ec5 | ||
|
|
51e81d80fc | ||
|
|
cd014e41e4 | ||
|
|
830f11c47d | ||
|
|
a73239dd98 | ||
|
|
d68783a612 | ||
|
|
a28ea40a7d | ||
|
|
f2492bd4d4 | ||
|
|
b22be7a6cb | ||
|
|
deb7f2f72a | ||
|
|
d989d9c65a | ||
|
|
4173c606ab | ||
|
|
a01430d20f | ||
|
|
2a8f775732 | ||
|
|
5b00445c05 | ||
|
|
5179677e8f | ||
|
|
2c25b2eae7 | ||
|
|
f6705fe2d3 | ||
|
|
c2771fed20 | ||
|
|
fc781eccd9 | ||
|
|
d5a25ae081 | ||
|
|
23b6fb6391 | ||
|
|
433967f0cf | ||
|
|
2a876c2a10 | ||
|
|
ff0adeaba7 | ||
|
|
846edbf256 | ||
|
|
c68dd48f6d | ||
|
|
8b828dd139 | ||
|
|
50c0a5da9e | ||
|
|
2f0e5c42f1 | ||
|
|
903288468a | ||
|
|
9e3bba6f59 | ||
|
|
bc16f0752f | ||
|
|
86badd70fa | ||
|
|
ce5379516c | ||
|
|
a50078bbf2 | ||
|
|
2cef168442 | ||
|
|
0a1a9e3545 | ||
|
|
3c8682d80c | ||
|
|
ecc5a1608f | ||
|
|
bc81b55600 | ||
|
|
28b628c1b4 | ||
|
|
148264ac73 | ||
|
|
4046e4e379 | ||
|
|
28298d9af2 | ||
|
|
9d156325e0 | ||
|
|
221712128d | ||
|
|
e9fc36f2d3 | ||
|
|
305b880b1d | ||
|
|
34782a6b85 | ||
|
|
d25d94e71b | ||
|
|
4a0d9b2855 | ||
|
|
92c65d69ea | ||
|
|
51f1b449cd | ||
|
|
804e47dde4 | ||
|
|
910a8968c4 | ||
|
|
582c810d15 | ||
|
|
cede629718 | ||
|
|
10941dc7fc | ||
|
|
c1c16878e4 | ||
|
|
80a41b434b | ||
|
|
9a8e117f1d | ||
|
|
878603033a | ||
|
|
1c6f17e8db | ||
|
|
8f32ef8064 | ||
|
|
7519c73f2a | ||
|
|
e12bc96e21 | ||
|
|
bf402aaa18 | ||
|
|
2355d3d729 | ||
|
|
a093a59cb0 | ||
|
|
d7917988c3 | ||
|
|
ae566a2027 | ||
|
|
b15473d3f3 | ||
|
|
265bf885ec | ||
|
|
e318281989 | ||
|
|
3e2a11d60d | ||
|
|
4b9f73310e | ||
|
|
cdb4679c5a | ||
|
|
1a9dce89b4 | ||
|
|
b17c26116d | ||
|
|
3114af75e4 | ||
|
|
7a6d10639b | ||
|
|
6ff29ea6aa | ||
|
|
a23f01973a | ||
|
|
0aaa3a3eca | ||
|
|
82f05d1102 | ||
|
|
8ff6d9c8bd | ||
|
|
cf1e4d7f88 | ||
|
|
f2f0b4fc61 | ||
|
|
a2e102fe15 | ||
|
|
119280da1a | ||
|
|
4d49f74d5a | ||
|
|
6a42b9c66b | ||
|
|
fc4a39480a | ||
|
|
b21dd25181 | ||
|
|
04a18bcbe5 | ||
|
|
7f66dd67eb | ||
|
|
b98afb01c8 | ||
|
|
ccd6bb7656 | ||
|
|
ea30e5c631 | ||
|
|
cfa03b89c8 | ||
|
|
9866d7a22b | ||
|
|
d16a3c3b22 | ||
|
|
a03bd78c2e | ||
|
|
3cca41aab1 | ||
|
|
d19aaed946 | ||
|
|
9a7db8cf94 | ||
|
|
f50630c551 | ||
|
|
0ef2e64733 | ||
|
|
3a8e121d43 | ||
|
|
23e249144d | ||
|
|
25014bfa89 | ||
|
|
78ea585779 | ||
|
|
ac13c11f89 | ||
|
|
51d341b88c | ||
|
|
7dd70b8e31 | ||
|
|
331a6e442f | ||
|
|
84b332d989 | ||
|
|
7fae57f311 | ||
|
|
1c2295b2b5 | ||
|
|
fd1826a267 | ||
|
|
bcc6848275 | ||
|
|
75dd053a40 | ||
|
|
20f2aa09f2 | ||
|
|
fb8c810b3d | ||
|
|
b99b6c5cd3 | ||
|
|
1f653969a9 | ||
|
|
ad21cf4243 | ||
|
|
1e45cfff67 | ||
|
|
0280600a47 | ||
|
|
571ad518dc | ||
|
|
fe37a25cf1 | ||
|
|
e06138628c | ||
|
|
1ed0edd158 | ||
|
|
49dbc46082 | ||
|
|
a16a4adc09 | ||
|
|
b4ab1cbd56 | ||
|
|
6faa63f0d0 | ||
|
|
f4737dcfe7 | ||
|
|
2b44af427f | ||
|
|
11f7401bc2 | ||
|
|
db7b5180dd | ||
|
|
5b4e56252c | ||
|
|
e3c71f77de | ||
|
|
b09824faec | ||
|
|
c69bc24598 | ||
|
|
0cf17e1c63 | ||
|
|
feac803491 | ||
|
|
4aacec30d8 | ||
|
|
b459a2f7a9 | ||
|
|
ca7f6d3514 | ||
|
|
ca8ede65f0 | ||
|
|
b033c56ae5 | ||
|
|
9a177c46e1 | ||
|
|
d49e858d32 | ||
|
|
20bea9cd7f | ||
|
|
d7afa5dcf2 | ||
|
|
22e816bf86 | ||
|
|
a7709d489c | ||
|
|
3240616808 | ||
|
|
18dfc997b8 | ||
|
|
92d0b6addf | ||
|
|
b9f83d4d61 | ||
|
|
694feaffd2 | ||
|
|
9c16826ad3 | ||
|
|
eb68e2143b | ||
|
|
f305745295 | ||
|
|
df4d0ad3fd | ||
|
|
9034d1dc71 | ||
|
|
537172d8ce | ||
|
|
20b2e4b3dd | ||
|
|
fc22586752 | ||
|
|
a86043a2ec | ||
|
|
3947da2cf1 | ||
|
|
17caab6563 | ||
|
|
a5ae071a03 | ||
|
|
9c33da7b8d | ||
|
|
94d31743b0 | ||
|
|
70db618c6e | ||
|
|
960a4549ef | ||
|
|
363a650dfa | ||
|
|
b6e2634537 | ||
|
|
9f424f2fc0 | ||
|
|
25989d9f90 | ||
|
|
0715fc5498 | ||
|
|
f9fddd6663 | ||
|
|
684da96a83 | ||
|
|
abae7979cb | ||
|
|
49bce57fcf | ||
|
|
fa43ca3785 | ||
|
|
b4a2c3bd14 | ||
|
|
2d4ec4f462 | ||
|
|
1e8b933da0 | ||
|
|
63d017fc21 | ||
|
|
c52ce6bb49 | ||
|
|
bcddd4ce77 | ||
|
|
017872f71b | ||
|
|
bfb660275e | ||
|
|
d6ae48bc58 | ||
|
|
7e670ce0a8 | ||
|
|
4310852ee6 | ||
|
|
d32308b6d2 | ||
|
|
604d16e353 | ||
|
|
db577785d6 | ||
|
|
c9ae3a0541 | ||
|
|
ed95dab9f3 | ||
|
|
a6536cef94 | ||
|
|
3ccc81e81c | ||
|
|
94197cbcb9 | ||
|
|
853f1e9873 | ||
|
|
3ee6d98905 | ||
|
|
ae5fe84fb2 | ||
|
|
92b538d5ae | ||
|
|
5351703949 | ||
|
|
48b1e0e038 | ||
|
|
7ba8169444 | ||
|
|
d090c954ae | ||
|
|
9bee1666f1 | ||
|
|
fb94637339 | ||
|
|
a96cd546c8 | ||
|
|
eb33d4f1c2 | ||
|
|
4253956326 | ||
|
|
d6b05bf337 |
@@ -1,40 +0,0 @@
|
||||
{
|
||||
"permissions": {
|
||||
"allow": [
|
||||
"Bash(npm install:*)",
|
||||
"Bash(npm test:*)",
|
||||
"Skill(building-agents-construction)",
|
||||
"Skill(building-agents-construction:*)",
|
||||
"Bash(PYTHONPATH=core:exports pytest:*)",
|
||||
"mcp__agent-builder__create_session",
|
||||
"mcp__agent-builder__get_session_status",
|
||||
"mcp__agent-builder__set_goal",
|
||||
"mcp__agent-builder__list_mcp_servers",
|
||||
"mcp__agent-builder__test_node",
|
||||
"mcp__agent-builder__add_node",
|
||||
"mcp__agent-builder__add_edge",
|
||||
"mcp__agent-builder__validate_graph",
|
||||
"Bash(ruff check:*)",
|
||||
"Bash(PYTHONPATH=core:exports python:*)",
|
||||
"mcp__agent-builder__list_tests",
|
||||
"mcp__agent-builder__generate_constraint_tests",
|
||||
"Bash(python -m agent:*)",
|
||||
"Bash(python agent.py:*)",
|
||||
"Bash(python -c:*)",
|
||||
"Bash(done)",
|
||||
"Bash(xargs cat:*)",
|
||||
"mcp__agent-builder__list_mcp_tools",
|
||||
"mcp__agent-builder__add_mcp_server",
|
||||
"mcp__agent-builder__check_missing_credentials",
|
||||
"mcp__agent-builder__store_credential",
|
||||
"mcp__agent-builder__list_stored_credentials",
|
||||
"mcp__agent-builder__delete_stored_credential",
|
||||
"mcp__agent-builder__verify_credentials",
|
||||
"Bash(PYTHONPATH=/home/timothy/oss/hive/core:/home/timothy/oss/hive/exports python:*)",
|
||||
"Bash(PYTHONPATH=core:exports:tools/src python -m hubspot_input:*)",
|
||||
"mcp__agent-builder__export_graph"
|
||||
]
|
||||
},
|
||||
"enabledMcpjsonServers": ["agent-builder", "tools"],
|
||||
"enableAllProjectMcpServers": true
|
||||
}
|
||||
@@ -0,0 +1,16 @@
|
||||
{
|
||||
"permissions": {
|
||||
"allow": [
|
||||
"Bash(git status:*)",
|
||||
"Bash(gh run view:*)",
|
||||
"Bash(uv run:*)",
|
||||
"Bash(env:*)",
|
||||
"Bash(python -m py_compile:*)",
|
||||
"Bash(python -m pytest:*)",
|
||||
"Bash(source:*)",
|
||||
"Bash(find:*)",
|
||||
"Bash(PYTHONPATH=core:exports:tools/src uv run pytest:*)"
|
||||
]
|
||||
},
|
||||
"enabledMcpjsonServers": ["tools"]
|
||||
}
|
||||
@@ -1,463 +0,0 @@
|
||||
---
|
||||
name: agent-workflow
|
||||
description: Complete workflow for building, implementing, and testing goal-driven agents. Orchestrates building-agents-* and testing-agent skills. Use when starting a new agent project, unsure which skill to use, or need end-to-end guidance.
|
||||
license: Apache-2.0
|
||||
metadata:
|
||||
author: hive
|
||||
version: "2.0"
|
||||
type: workflow-orchestrator
|
||||
orchestrates:
|
||||
- building-agents-core
|
||||
- building-agents-construction
|
||||
- building-agents-patterns
|
||||
- testing-agent
|
||||
- setup-credentials
|
||||
---
|
||||
|
||||
# Agent Development Workflow
|
||||
|
||||
Complete Standard Operating Procedure (SOP) for building production-ready goal-driven agents.
|
||||
|
||||
## Overview
|
||||
|
||||
This workflow orchestrates specialized skills to take you from initial concept to production-ready agent:
|
||||
|
||||
1. **Understand Concepts** → `/building-agents-core` (optional)
|
||||
2. **Build Structure** → `/building-agents-construction`
|
||||
3. **Optimize Design** → `/building-agents-patterns` (optional)
|
||||
4. **Setup Credentials** → `/setup-credentials` (if agent uses tools requiring API keys)
|
||||
5. **Test & Validate** → `/testing-agent`
|
||||
|
||||
## When to Use This Workflow
|
||||
|
||||
Use this meta-skill when:
|
||||
- Starting a new agent from scratch
|
||||
- Unclear which skill to use first
|
||||
- Need end-to-end guidance for agent development
|
||||
- Want consistent, repeatable agent builds
|
||||
|
||||
**Skip this workflow** if:
|
||||
- You only need to test an existing agent → use `/testing-agent` directly
|
||||
- You know exactly which phase you're in → use specific skill directly
|
||||
|
||||
## Quick Decision Tree
|
||||
|
||||
```
|
||||
"Need to understand agent concepts" → building-agents-core
|
||||
"Build a new agent" → building-agents-construction
|
||||
"Optimize my agent design" → building-agents-patterns
|
||||
"Set up API keys for my agent" → setup-credentials
|
||||
"Test my agent" → testing-agent
|
||||
"Not sure what I need" → Read phases below, then decide
|
||||
"Agent has structure but needs implementation" → See agent directory STATUS.md
|
||||
```
|
||||
|
||||
## Phase 0: Understand Concepts (Optional)
|
||||
|
||||
**Duration**: 5-10 minutes
|
||||
**Skill**: `/building-agents-core`
|
||||
**Input**: Questions about agent architecture
|
||||
|
||||
### When to Use
|
||||
|
||||
- First time building an agent
|
||||
- Need to understand node types, edges, goals
|
||||
- Want to validate tool availability
|
||||
- Learning about pause/resume architecture
|
||||
|
||||
### What This Phase Provides
|
||||
|
||||
- Architecture overview (Python packages, not JSON)
|
||||
- Core concepts (Goal, Node, Edge, Pause/Resume)
|
||||
- Tool discovery and validation procedures
|
||||
- Workflow overview
|
||||
|
||||
**Skip this phase** if you already understand agent fundamentals.
|
||||
|
||||
## Phase 1: Build Agent Structure
|
||||
|
||||
**Duration**: 15-30 minutes
|
||||
**Skill**: `/building-agents-construction`
|
||||
**Input**: User requirements ("Build an agent that...")
|
||||
|
||||
### What This Phase Does
|
||||
|
||||
Creates the complete agent architecture:
|
||||
- Package structure (`exports/agent_name/`)
|
||||
- Goal with success criteria and constraints
|
||||
- Workflow graph (nodes and edges)
|
||||
- Node specifications
|
||||
- CLI interface
|
||||
- Documentation
|
||||
|
||||
### Process
|
||||
|
||||
1. **Create package** - Directory structure with skeleton files
|
||||
2. **Define goal** - Success criteria and constraints written to agent.py
|
||||
3. **Design nodes** - Each node approved and written incrementally
|
||||
4. **Connect edges** - Workflow graph with conditional routing
|
||||
5. **Finalize** - Agent class, exports, and documentation
|
||||
|
||||
### Outputs
|
||||
|
||||
- ✅ `exports/agent_name/` package created
|
||||
- ✅ Goal defined in agent.py
|
||||
- ✅ 3-5 success criteria defined
|
||||
- ✅ 1-5 constraints defined
|
||||
- ✅ 5-10 nodes specified in nodes/__init__.py
|
||||
- ✅ 8-15 edges connecting workflow
|
||||
- ✅ Validated structure (passes `python -m agent_name validate`)
|
||||
- ✅ README.md with usage instructions
|
||||
- ✅ CLI commands (info, validate, run, shell)
|
||||
|
||||
### Success Criteria
|
||||
|
||||
You're ready for Phase 2 when:
|
||||
- Agent structure validates without errors
|
||||
- All nodes and edges are defined
|
||||
- CLI commands work (info, validate)
|
||||
- You see: "Agent complete: exports/agent_name/"
|
||||
|
||||
### Common Outputs
|
||||
|
||||
The building-agents-construction skill produces:
|
||||
```
|
||||
exports/agent_name/
|
||||
├── __init__.py (package exports)
|
||||
├── __main__.py (CLI interface)
|
||||
├── agent.py (goal, graph, agent class)
|
||||
├── nodes/__init__.py (node specifications)
|
||||
├── config.py (configuration)
|
||||
├── implementations.py (may be created for Python functions)
|
||||
└── README.md (documentation)
|
||||
```
|
||||
|
||||
### Next Steps
|
||||
|
||||
**If structure complete and validated:**
|
||||
→ Check `exports/agent_name/STATUS.md` or `IMPLEMENTATION_GUIDE.md`
|
||||
→ These files explain implementation options
|
||||
→ You may need to add Python functions or MCP tools (not covered by current skills)
|
||||
|
||||
**If want to optimize design:**
|
||||
→ Proceed to Phase 1.5 (building-agents-patterns)
|
||||
|
||||
**If ready to test:**
|
||||
→ Proceed to Phase 2
|
||||
|
||||
## Phase 1.5: Optimize Design (Optional)
|
||||
|
||||
**Duration**: 10-15 minutes
|
||||
**Skill**: `/building-agents-patterns`
|
||||
**Input**: Completed agent structure
|
||||
|
||||
### When to Use
|
||||
|
||||
- Want to add pause/resume functionality
|
||||
- Need error handling patterns
|
||||
- Want to optimize performance
|
||||
- Need examples of complex routing
|
||||
- Want best practices guidance
|
||||
|
||||
### What This Phase Provides
|
||||
|
||||
- Practical examples and patterns
|
||||
- Pause/resume architecture
|
||||
- Error handling strategies
|
||||
- Anti-patterns to avoid
|
||||
- Performance optimization techniques
|
||||
|
||||
**Skip this phase** if your agent design is straightforward.
|
||||
|
||||
## Phase 2: Test & Validate
|
||||
|
||||
**Duration**: 20-40 minutes
|
||||
**Skill**: `/testing-agent`
|
||||
**Input**: Working agent from Phase 1
|
||||
|
||||
### What This Phase Does
|
||||
|
||||
Creates comprehensive test suite:
|
||||
- Constraint tests (verify hard requirements)
|
||||
- Success criteria tests (measure goal achievement)
|
||||
- Edge case tests (handle failures gracefully)
|
||||
- Integration tests (end-to-end workflows)
|
||||
|
||||
### Process
|
||||
|
||||
1. **Analyze agent** - Read goal, constraints, success criteria
|
||||
2. **Generate tests** - Create pytest files in `exports/agent_name/tests/`
|
||||
3. **User approval** - Review and approve each test
|
||||
4. **Run evaluation** - Execute tests and collect results
|
||||
5. **Debug failures** - Identify and fix issues
|
||||
6. **Iterate** - Repeat until all tests pass
|
||||
|
||||
### Outputs
|
||||
|
||||
- ✅ Test files in `exports/agent_name/tests/`
|
||||
- ✅ Test report with pass/fail metrics
|
||||
- ✅ Coverage of all success criteria
|
||||
- ✅ Coverage of all constraints
|
||||
- ✅ Edge case handling verified
|
||||
|
||||
### Success Criteria
|
||||
|
||||
You're done when:
|
||||
- All tests pass
|
||||
- All success criteria validated
|
||||
- All constraints verified
|
||||
- Agent handles edge cases
|
||||
- Test coverage is comprehensive
|
||||
|
||||
### Next Steps
|
||||
|
||||
**Agent ready for:**
|
||||
- Production deployment
|
||||
- Integration into larger systems
|
||||
- Documentation and handoff
|
||||
- Continuous monitoring
|
||||
|
||||
## Phase Transitions
|
||||
|
||||
### From Phase 1 to Phase 2
|
||||
|
||||
**Trigger signals:**
|
||||
- "Agent complete: exports/..."
|
||||
- Structure validation passes
|
||||
- README indicates implementation complete
|
||||
|
||||
**Before proceeding:**
|
||||
- Verify agent can be imported: `from exports.agent_name import default_agent`
|
||||
- Check if implementation is needed (see STATUS.md or IMPLEMENTATION_GUIDE.md)
|
||||
- Confirm agent executes without import errors
|
||||
|
||||
### Skipping Phases
|
||||
|
||||
**When to skip Phase 1:**
|
||||
- Agent structure already exists
|
||||
- Only need to add tests
|
||||
- Modifying existing agent
|
||||
|
||||
**When to skip Phase 2:**
|
||||
- Prototyping or exploring
|
||||
- Agent not production-bound
|
||||
- Manual testing sufficient
|
||||
|
||||
## Common Patterns
|
||||
|
||||
### Pattern 1: Complete New Build (Simple)
|
||||
|
||||
```
|
||||
User: "Build an agent that monitors files"
|
||||
→ Use /building-agents-construction
|
||||
→ Agent structure created
|
||||
→ Use /testing-agent
|
||||
→ Tests created and passing
|
||||
→ Done: Production-ready agent
|
||||
```
|
||||
|
||||
### Pattern 1b: Complete New Build (With Learning)
|
||||
|
||||
```
|
||||
User: "Build an agent (first time)"
|
||||
→ Use /building-agents-core (understand concepts)
|
||||
→ Use /building-agents-construction (build structure)
|
||||
→ Use /building-agents-patterns (optimize design)
|
||||
→ Use /testing-agent (validate)
|
||||
→ Done: Production-ready agent
|
||||
```
|
||||
|
||||
### Pattern 2: Test Existing Agent
|
||||
|
||||
```
|
||||
User: "Test my agent at exports/my_agent"
|
||||
→ Skip Phase 1
|
||||
→ Use /testing-agent directly
|
||||
→ Tests created
|
||||
→ Done: Validated agent
|
||||
```
|
||||
|
||||
### Pattern 3: Iterative Development
|
||||
|
||||
```
|
||||
User: "Build an agent"
|
||||
→ Use /building-agents-construction (Phase 1)
|
||||
→ Implementation needed (see STATUS.md)
|
||||
→ [User implements functions]
|
||||
→ Use /testing-agent (Phase 2)
|
||||
→ Tests reveal bugs
|
||||
→ [Fix bugs manually]
|
||||
→ Re-run tests
|
||||
→ Done: Working agent
|
||||
```
|
||||
|
||||
### Pattern 4: Complex Agent with Patterns
|
||||
|
||||
```
|
||||
User: "Build an agent with multi-turn conversations"
|
||||
→ Use /building-agents-core (learn pause/resume)
|
||||
→ Use /building-agents-construction (build structure)
|
||||
→ Use /building-agents-patterns (implement pause/resume pattern)
|
||||
→ Use /testing-agent (validate conversation flows)
|
||||
→ Done: Complex conversational agent
|
||||
```
|
||||
|
||||
## Skill Dependencies
|
||||
|
||||
```
|
||||
agent-workflow (meta-skill)
|
||||
│
|
||||
├── building-agents-core (foundational)
|
||||
│ ├── Architecture concepts
|
||||
│ ├── Node/Edge/Goal definitions
|
||||
│ ├── Tool discovery procedures
|
||||
│ └── Workflow overview
|
||||
│
|
||||
├── building-agents-construction (procedural)
|
||||
│ ├── Creates package structure
|
||||
│ ├── Defines goal
|
||||
│ ├── Adds nodes incrementally
|
||||
│ ├── Connects edges
|
||||
│ ├── Finalizes agent class
|
||||
│ └── Requires: building-agents-core
|
||||
│
|
||||
├── building-agents-patterns (reference)
|
||||
│ ├── Best practices
|
||||
│ ├── Pause/resume patterns
|
||||
│ ├── Error handling
|
||||
│ ├── Anti-patterns
|
||||
│ └── Performance optimization
|
||||
│
|
||||
└── testing-agent
|
||||
├── Reads agent goal
|
||||
├── Generates tests
|
||||
├── Runs evaluation
|
||||
└── Reports results
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### "Agent structure won't validate"
|
||||
|
||||
- Check node IDs match between nodes/__init__.py and agent.py
|
||||
- Verify all edges reference valid node IDs
|
||||
- Ensure entry_node exists in nodes list
|
||||
- Run: `PYTHONPATH=core:exports python -m agent_name validate`
|
||||
|
||||
### "Agent has structure but won't run"
|
||||
|
||||
- Check for STATUS.md or IMPLEMENTATION_GUIDE.md in agent directory
|
||||
- Implementation may be needed (Python functions or MCP tools)
|
||||
- This is expected - building-agents-construction creates structure, not implementation
|
||||
- See implementation guide for completion options
|
||||
|
||||
### "Tests are failing"
|
||||
|
||||
- Review test output for specific failures
|
||||
- Check agent goal and success criteria
|
||||
- Verify constraints are met
|
||||
- Use `/testing-agent` to debug and iterate
|
||||
- Fix agent code and re-run tests
|
||||
|
||||
### "Not sure which phase I'm in"
|
||||
|
||||
Run these checks:
|
||||
|
||||
```bash
|
||||
# Check if agent structure exists
|
||||
ls exports/my_agent/agent.py
|
||||
|
||||
# Check if it validates
|
||||
PYTHONPATH=core:exports python -m my_agent validate
|
||||
|
||||
# Check if tests exist
|
||||
ls exports/my_agent/tests/
|
||||
|
||||
# If structure exists and validates → Phase 2 (testing)
|
||||
# If structure doesn't exist → Phase 1 (building)
|
||||
# If tests exist but failing → Debug phase
|
||||
```
|
||||
|
||||
## Best Practices
|
||||
|
||||
### For Phase 1 (Building)
|
||||
|
||||
1. **Start with clear requirements** - Know what the agent should do
|
||||
2. **Define success criteria early** - Measurable goals drive design
|
||||
3. **Keep nodes focused** - One responsibility per node
|
||||
4. **Use descriptive names** - Node IDs should explain purpose
|
||||
5. **Validate incrementally** - Check structure after each major addition
|
||||
|
||||
### For Phase 2 (Testing)
|
||||
|
||||
1. **Test constraints first** - Hard requirements must pass
|
||||
2. **Mock external dependencies** - Use mock mode for LLMs/APIs
|
||||
3. **Cover edge cases** - Test failures, not just success paths
|
||||
4. **Iterate quickly** - Fix one test at a time
|
||||
5. **Document test patterns** - Future tests follow same structure
|
||||
|
||||
### General Workflow
|
||||
|
||||
1. **Use version control** - Git commit after each phase
|
||||
2. **Document decisions** - Update README with changes
|
||||
3. **Keep iterations small** - Build → Test → Fix → Repeat
|
||||
4. **Preserve working states** - Tag successful iterations
|
||||
5. **Learn from failures** - Failed tests reveal design issues
|
||||
|
||||
## Exit Criteria
|
||||
|
||||
You're done with the workflow when:
|
||||
|
||||
✅ Agent structure validates
|
||||
✅ All tests pass
|
||||
✅ Success criteria met
|
||||
✅ Constraints verified
|
||||
✅ Documentation complete
|
||||
✅ Agent ready for deployment
|
||||
|
||||
## Additional Resources
|
||||
|
||||
- **building-agents-core**: See `.claude/skills/building-agents-core/SKILL.md`
|
||||
- **building-agents-construction**: See `.claude/skills/building-agents-construction/SKILL.md`
|
||||
- **building-agents-patterns**: See `.claude/skills/building-agents-patterns/SKILL.md`
|
||||
- **testing-agent**: See `.claude/skills/testing-agent/SKILL.md`
|
||||
- **Agent framework docs**: See `core/README.md`
|
||||
- **Example agents**: See `exports/` directory
|
||||
|
||||
## Summary
|
||||
|
||||
This workflow provides a proven path from concept to production-ready agent:
|
||||
|
||||
1. **Learn** with `/building-agents-core` → Understand fundamentals (optional)
|
||||
2. **Build** with `/building-agents-construction` → Get validated structure
|
||||
3. **Optimize** with `/building-agents-patterns` → Apply best practices (optional)
|
||||
4. **Test** with `/testing-agent` → Get verified functionality
|
||||
|
||||
The workflow is **flexible** - skip phases as needed, iterate freely, and adapt to your specific requirements. The goal is **production-ready agents** built with **consistent, repeatable processes**.
|
||||
|
||||
## Skill Selection Guide
|
||||
|
||||
**Choose building-agents-core when:**
|
||||
- First time building agents
|
||||
- Need to understand architecture
|
||||
- Validating tool availability
|
||||
- Learning about node types and edges
|
||||
|
||||
**Choose building-agents-construction when:**
|
||||
- Actually building an agent
|
||||
- Have clear requirements
|
||||
- Ready to write code
|
||||
- Want step-by-step guidance
|
||||
|
||||
**Choose building-agents-patterns when:**
|
||||
- Agent structure complete
|
||||
- Need advanced patterns
|
||||
- Implementing pause/resume
|
||||
- Optimizing performance
|
||||
- Want best practices
|
||||
|
||||
**Choose testing-agent when:**
|
||||
- Agent structure complete
|
||||
- Ready to validate functionality
|
||||
- Need comprehensive test coverage
|
||||
- Debugging agent behavior
|
||||
@@ -1,199 +0,0 @@
|
||||
# Example: File Monitor Agent
|
||||
|
||||
This example shows the complete agent-workflow in action for building a file monitoring agent.
|
||||
|
||||
## Initial Request
|
||||
|
||||
```
|
||||
User: "Build an agent that monitors ~/Downloads and copies new files to ~/Documents"
|
||||
```
|
||||
|
||||
## Phase 1: Building (20 minutes)
|
||||
|
||||
### Step 1: Create Structure
|
||||
|
||||
Agent invokes `/building-agents` skill and:
|
||||
|
||||
1. Creates `exports/file_monitor_agent/` package
|
||||
2. Writes skeleton files (__init__.py, __main__.py, agent.py, etc.)
|
||||
|
||||
**Output**: Package structure visible immediately
|
||||
|
||||
### Step 2: Define Goal
|
||||
|
||||
```python
|
||||
goal = Goal(
|
||||
id="file-monitor-copy",
|
||||
name="Automated File Monitor & Copy",
|
||||
success_criteria=[
|
||||
# 100% detection rate
|
||||
# 100% copy success
|
||||
# 100% conflict resolution
|
||||
# >99% uptime
|
||||
],
|
||||
constraints=[
|
||||
# Preserve originals
|
||||
# Handle errors gracefully
|
||||
# Track state
|
||||
# Respect permissions
|
||||
]
|
||||
)
|
||||
```
|
||||
|
||||
**Output**: Goal written to agent.py
|
||||
|
||||
### Step 3: Design Nodes
|
||||
|
||||
7 nodes approved and written incrementally:
|
||||
|
||||
1. `initialize-state` - Set up tracking
|
||||
2. `list-downloads` - Scan directory
|
||||
3. `identify-new-files` - Find new files
|
||||
4. `check-for-new-files` - Router
|
||||
5. `copy-files` - Copy with conflict resolution
|
||||
6. `update-state` - Mark as processed
|
||||
7. `wait-interval` - Sleep between cycles
|
||||
|
||||
**Output**: All nodes in nodes/__init__.py
|
||||
|
||||
### Step 4: Connect Edges
|
||||
|
||||
8 edges connecting the workflow loop:
|
||||
|
||||
```
|
||||
initialize → list → identify → check
|
||||
↓ ↓
|
||||
copy wait
|
||||
↓ ↑
|
||||
update ↓
|
||||
↓ ↓
|
||||
wait → list (loop)
|
||||
```
|
||||
|
||||
**Output**: Edges written to agent.py
|
||||
|
||||
### Step 5: Finalize
|
||||
|
||||
```bash
|
||||
$ PYTHONPATH=core:exports python -m file_monitor_agent validate
|
||||
✓ Agent is valid
|
||||
|
||||
$ PYTHONPATH=core:exports python -m file_monitor_agent info
|
||||
Agent: File Monitor & Copy Agent
|
||||
Nodes: 7
|
||||
Edges: 8
|
||||
```
|
||||
|
||||
**Phase 1 Complete**: Structure validated ✅
|
||||
|
||||
### Status After Phase 1
|
||||
|
||||
```
|
||||
exports/file_monitor_agent/
|
||||
├── __init__.py ✅ (exports)
|
||||
├── __main__.py ✅ (CLI)
|
||||
├── agent.py ✅ (goal, graph, agent class)
|
||||
├── nodes/__init__.py ✅ (7 nodes)
|
||||
├── config.py ✅ (configuration)
|
||||
├── implementations.py ✅ (Python functions)
|
||||
├── README.md ✅ (documentation)
|
||||
├── IMPLEMENTATION_GUIDE.md ✅ (next steps)
|
||||
└── STATUS.md ✅ (current state)
|
||||
```
|
||||
|
||||
**Note**: Implementation gap exists - data flow needs connection (covered in STATUS.md)
|
||||
|
||||
## Phase 2: Testing (25 minutes)
|
||||
|
||||
### Step 1: Analyze Agent
|
||||
|
||||
Agent invokes `/testing-agent` skill and:
|
||||
|
||||
1. Reads goal from `exports/file_monitor_agent/agent.py`
|
||||
2. Identifies 4 success criteria to test
|
||||
3. Identifies 4 constraints to verify
|
||||
4. Plans test coverage
|
||||
|
||||
### Step 2: Generate Tests
|
||||
|
||||
Creates test files:
|
||||
|
||||
```
|
||||
exports/file_monitor_agent/tests/
|
||||
├── conftest.py (fixtures)
|
||||
├── test_constraints.py (4 constraint tests)
|
||||
├── test_success_criteria.py (4 success tests)
|
||||
└── test_edge_cases.py (error handling)
|
||||
```
|
||||
|
||||
Tests approved incrementally by user.
|
||||
|
||||
### Step 3: Run Tests
|
||||
|
||||
```bash
|
||||
$ PYTHONPATH=core:exports pytest exports/file_monitor_agent/tests/
|
||||
|
||||
test_constraints.py::test_preserves_originals PASSED
|
||||
test_constraints.py::test_handles_errors PASSED
|
||||
test_constraints.py::test_tracks_state PASSED
|
||||
test_constraints.py::test_respects_permissions PASSED
|
||||
|
||||
test_success_criteria.py::test_detects_all_files PASSED
|
||||
test_success_criteria.py::test_copies_all_files PASSED
|
||||
test_success_criteria.py::test_resolves_conflicts PASSED
|
||||
test_success_criteria.py::test_continuous_run PASSED
|
||||
|
||||
test_edge_cases.py::test_empty_directory PASSED
|
||||
test_edge_cases.py::test_permission_denied PASSED
|
||||
test_edge_cases.py::test_disk_full PASSED
|
||||
test_edge_cases.py::test_large_files PASSED
|
||||
|
||||
========================== 12 passed in 3.42s ==========================
|
||||
```
|
||||
|
||||
**Phase 2 Complete**: All tests pass ✅
|
||||
|
||||
## Final Output
|
||||
|
||||
**Production-Ready Agent:**
|
||||
|
||||
```bash
|
||||
# Run the agent
|
||||
./RUN_AGENT.sh
|
||||
|
||||
# Or manually
|
||||
PYTHONPATH=core:exports:tools/src python -m file_monitor_agent run
|
||||
```
|
||||
|
||||
**Capabilities:**
|
||||
- Monitors ~/Downloads continuously
|
||||
- Copies new files to ~/Documents
|
||||
- Resolves conflicts with timestamps
|
||||
- Handles errors gracefully
|
||||
- Tracks processed files
|
||||
- Runs as background service
|
||||
|
||||
**Total Time**: ~45 minutes from concept to production
|
||||
|
||||
## Key Learnings
|
||||
|
||||
1. **Incremental building** - Files written immediately, visible throughout
|
||||
2. **Validation early** - Structure validated before moving to implementation
|
||||
3. **Test-driven** - Tests reveal real behavior
|
||||
4. **Documentation included** - README, STATUS, and guides auto-generated
|
||||
5. **Repeatable process** - Same workflow for any agent type
|
||||
|
||||
## Variations
|
||||
|
||||
**For simpler agents:**
|
||||
- Fewer nodes (3-5 instead of 7)
|
||||
- Simpler workflow (linear instead of looping)
|
||||
- Faster build time (10-15 minutes)
|
||||
|
||||
**For complex agents:**
|
||||
- More nodes (10-15+)
|
||||
- Multiple subgraphs
|
||||
- Pause/resume points for human-in-the-loop
|
||||
- Longer build time (45-60 minutes)
|
||||
|
||||
The workflow scales to your needs!
|
||||
@@ -1,361 +0,0 @@
|
||||
---
|
||||
name: building-agents-construction
|
||||
description: Step-by-step guide for building goal-driven agents. Creates package structure, defines goals, adds nodes, connects edges, and finalizes agent class. Use when actively building an agent.
|
||||
license: Apache-2.0
|
||||
metadata:
|
||||
author: hive
|
||||
version: "2.0"
|
||||
type: procedural
|
||||
part_of: building-agents
|
||||
requires: building-agents-core
|
||||
---
|
||||
|
||||
# Agent Construction - EXECUTE THESE STEPS
|
||||
|
||||
**THIS IS AN EXECUTABLE WORKFLOW. DO NOT DISPLAY THIS FILE. EXECUTE THE STEPS BELOW.**
|
||||
|
||||
When this skill is loaded, IMMEDIATELY begin executing Step 1. Do not explain what you will do - just do it.
|
||||
|
||||
---
|
||||
|
||||
## STEP 1: Initialize Build Environment
|
||||
|
||||
**EXECUTE THESE TOOL CALLS NOW:**
|
||||
|
||||
1. Register the hive-tools MCP server:
|
||||
|
||||
```
|
||||
mcp__agent-builder__add_mcp_server(
|
||||
name="hive-tools",
|
||||
transport="stdio",
|
||||
command="python",
|
||||
args='["mcp_server.py", "--stdio"]',
|
||||
cwd="tools",
|
||||
description="Hive tools MCP server"
|
||||
)
|
||||
```
|
||||
|
||||
2. Create a build session (replace AGENT_NAME with the user's requested agent name in snake_case):
|
||||
|
||||
```
|
||||
mcp__agent-builder__create_session(name="AGENT_NAME")
|
||||
```
|
||||
|
||||
3. Discover available tools:
|
||||
|
||||
```
|
||||
mcp__agent-builder__list_mcp_tools()
|
||||
```
|
||||
|
||||
4. Create the package directory:
|
||||
|
||||
```
|
||||
mkdir -p exports/AGENT_NAME/nodes
|
||||
```
|
||||
|
||||
**AFTER completing these calls**, tell the user:
|
||||
|
||||
> ✅ Build environment initialized
|
||||
>
|
||||
> - Session created
|
||||
> - Available tools: [list the tools from step 3]
|
||||
>
|
||||
> Proceeding to define the agent goal...
|
||||
|
||||
**THEN immediately proceed to STEP 2.**
|
||||
|
||||
---
|
||||
|
||||
## STEP 2: Define and Approve Goal
|
||||
|
||||
**PROPOSE a goal to the user.** Based on what they asked for, propose:
|
||||
|
||||
- Goal ID (kebab-case)
|
||||
- Goal name
|
||||
- Goal description
|
||||
- 3-5 success criteria (each with: id, description, metric, target, weight)
|
||||
- 2-4 constraints (each with: id, description, constraint_type, category)
|
||||
|
||||
**FORMAT your proposal as a clear summary, then ask for approval:**
|
||||
|
||||
> **Proposed Goal: [Name]**
|
||||
>
|
||||
> [Description]
|
||||
>
|
||||
> **Success Criteria:**
|
||||
>
|
||||
> 1. [criterion 1]
|
||||
> 2. [criterion 2]
|
||||
> ...
|
||||
>
|
||||
> **Constraints:**
|
||||
>
|
||||
> 1. [constraint 1]
|
||||
> 2. [constraint 2]
|
||||
> ...
|
||||
|
||||
**THEN call AskUserQuestion:**
|
||||
|
||||
```
|
||||
AskUserQuestion(questions=[{
|
||||
"question": "Do you approve this goal definition?",
|
||||
"header": "Goal",
|
||||
"options": [
|
||||
{"label": "Approve", "description": "Goal looks good, proceed"},
|
||||
{"label": "Modify", "description": "I want to change something"}
|
||||
],
|
||||
"multiSelect": false
|
||||
}])
|
||||
```
|
||||
|
||||
**WAIT for user response.**
|
||||
|
||||
- If **Approve**: Call `mcp__agent-builder__set_goal(...)` with the goal details, then proceed to STEP 3
|
||||
- If **Modify**: Ask what they want to change, update proposal, ask again
|
||||
|
||||
---
|
||||
|
||||
## STEP 3: Design Node Workflow
|
||||
|
||||
**BEFORE designing nodes**, review the available tools from Step 1. Nodes can ONLY use tools that exist.
|
||||
|
||||
**DESIGN the workflow** as a series of nodes. For each node, determine:
|
||||
|
||||
- node_id (kebab-case)
|
||||
- name
|
||||
- description
|
||||
- node_type: `"llm_generate"` (no tools) or `"llm_tool_use"` (uses tools)
|
||||
- input_keys (what data this node receives)
|
||||
- output_keys (what data this node produces)
|
||||
- tools (ONLY tools that exist - empty list for llm_generate)
|
||||
- system_prompt
|
||||
|
||||
**PRESENT the workflow to the user:**
|
||||
|
||||
> **Proposed Workflow: [N] nodes**
|
||||
>
|
||||
> 1. **[node-id]** - [description]
|
||||
>
|
||||
> - Type: [llm_generate/llm_tool_use]
|
||||
> - Input: [keys]
|
||||
> - Output: [keys]
|
||||
> - Tools: [tools or "none"]
|
||||
>
|
||||
> 2. **[node-id]** - [description]
|
||||
> ...
|
||||
>
|
||||
> **Flow:** node1 → node2 → node3 → ...
|
||||
|
||||
**THEN call AskUserQuestion:**
|
||||
|
||||
```
|
||||
AskUserQuestion(questions=[{
|
||||
"question": "Do you approve this workflow design?",
|
||||
"header": "Workflow",
|
||||
"options": [
|
||||
{"label": "Approve", "description": "Workflow looks good, proceed to build nodes"},
|
||||
{"label": "Modify", "description": "I want to change the workflow"}
|
||||
],
|
||||
"multiSelect": false
|
||||
}])
|
||||
```
|
||||
|
||||
**WAIT for user response.**
|
||||
|
||||
- If **Approve**: Proceed to STEP 4
|
||||
- If **Modify**: Ask what they want to change, update design, ask again
|
||||
|
||||
---
|
||||
|
||||
## STEP 4: Build Nodes One by One
|
||||
|
||||
**FOR EACH node in the approved workflow:**
|
||||
|
||||
1. **Call** `mcp__agent-builder__add_node(...)` with the node details
|
||||
|
||||
- input_keys and output_keys must be JSON strings: `'["key1", "key2"]'`
|
||||
- tools must be a JSON string: `'["tool1"]'` or `'[]'`
|
||||
|
||||
2. **Call** `mcp__agent-builder__test_node(...)` to validate:
|
||||
|
||||
```
|
||||
mcp__agent-builder__test_node(
|
||||
node_id="the-node-id",
|
||||
test_input='{"key": "test value"}',
|
||||
mock_llm_response='{"output_key": "test output"}'
|
||||
)
|
||||
```
|
||||
|
||||
3. **Check result:**
|
||||
|
||||
- If valid: Tell user "✅ Node [id] validated" and continue to next node
|
||||
- If invalid: Show errors, fix the node, re-validate
|
||||
|
||||
4. **Show progress** after each node:
|
||||
|
||||
```
|
||||
mcp__agent-builder__get_session_status()
|
||||
```
|
||||
|
||||
> ✅ Node [X] of [Y] complete: [node-id]
|
||||
|
||||
**AFTER all nodes are added and validated**, proceed to STEP 5.
|
||||
|
||||
---
|
||||
|
||||
## STEP 5: Connect Edges
|
||||
|
||||
**DETERMINE the edges** based on the workflow flow. For each connection:
|
||||
|
||||
- edge_id (kebab-case)
|
||||
- source (node that outputs)
|
||||
- target (node that receives)
|
||||
- condition: `"on_success"`, `"always"`, `"on_failure"`, or `"conditional"`
|
||||
- condition_expr (Python expression, only if conditional)
|
||||
- priority (integer, lower = higher priority)
|
||||
|
||||
**FOR EACH edge, call:**
|
||||
|
||||
```
|
||||
mcp__agent-builder__add_edge(
|
||||
edge_id="source-to-target",
|
||||
source="source-node-id",
|
||||
target="target-node-id",
|
||||
condition="on_success",
|
||||
condition_expr="",
|
||||
priority=1
|
||||
)
|
||||
```
|
||||
|
||||
**AFTER all edges are added, validate the graph:**
|
||||
|
||||
```
|
||||
mcp__agent-builder__validate_graph()
|
||||
```
|
||||
|
||||
- If valid: Tell user "✅ Graph structure validated" and proceed to STEP 6
|
||||
- If invalid: Show errors, fix edges, re-validate
|
||||
|
||||
---
|
||||
|
||||
## STEP 6: Generate Agent Package
|
||||
|
||||
**EXPORT the graph data:**
|
||||
|
||||
```
|
||||
mcp__agent-builder__export_graph()
|
||||
```
|
||||
|
||||
This returns JSON with all the goal, nodes, edges, and MCP server configurations.
|
||||
|
||||
**THEN write the Python package files** using the exported data. Create these files in `exports/AGENT_NAME/`:
|
||||
|
||||
1. `config.py` - Runtime configuration with model settings
|
||||
2. `nodes/__init__.py` - All NodeSpec definitions
|
||||
3. `agent.py` - Goal, edges, graph config, and agent class
|
||||
4. `__init__.py` - Package exports
|
||||
5. `__main__.py` - CLI interface
|
||||
6. `mcp_servers.json` - MCP server configurations
|
||||
7. `README.md` - Usage documentation
|
||||
|
||||
**IMPORTANT entry_points format:**
|
||||
|
||||
- MUST be: `{"start": "first-node-id"}`
|
||||
- NOT: `{"first-node-id": ["input_keys"]}` (WRONG)
|
||||
- NOT: `{"first-node-id"}` (WRONG - this is a set)
|
||||
|
||||
**Use the example agent** at `.claude/skills/building-agents-construction/examples/online_research_agent/` as a template for file structure and patterns.
|
||||
|
||||
**AFTER writing all files, tell the user:**
|
||||
|
||||
> ✅ Agent package created: `exports/AGENT_NAME/`
|
||||
>
|
||||
> **Files generated:**
|
||||
>
|
||||
> - `__init__.py` - Package exports
|
||||
> - `agent.py` - Goal, nodes, edges, agent class
|
||||
> - `config.py` - Runtime configuration
|
||||
> - `__main__.py` - CLI interface
|
||||
> - `nodes/__init__.py` - Node definitions
|
||||
> - `mcp_servers.json` - MCP server config
|
||||
> - `README.md` - Usage documentation
|
||||
>
|
||||
> **Test your agent:**
|
||||
>
|
||||
> ```bash
|
||||
> cd /home/timothy/oss/hive
|
||||
> PYTHONPATH=core:exports python -m AGENT_NAME validate
|
||||
> PYTHONPATH=core:exports python -m AGENT_NAME info
|
||||
> ```
|
||||
|
||||
---
|
||||
|
||||
## STEP 7: Verify and Test
|
||||
|
||||
**RUN validation:**
|
||||
|
||||
```bash
|
||||
cd /home/timothy/oss/hive && PYTHONPATH=core:exports python -m AGENT_NAME validate
|
||||
```
|
||||
|
||||
- If valid: Agent is complete!
|
||||
- If errors: Fix the issues and re-run
|
||||
|
||||
**SHOW final session summary:**
|
||||
|
||||
```
|
||||
mcp__agent-builder__get_session_status()
|
||||
```
|
||||
|
||||
**TELL the user the agent is ready** and suggest next steps:
|
||||
|
||||
- Run with mock mode to test without API calls
|
||||
- Use `/testing-agent` skill for comprehensive testing
|
||||
- Use `/setup-credentials` if the agent needs API keys
|
||||
|
||||
---
|
||||
|
||||
## REFERENCE: Node Types
|
||||
|
||||
| Type | tools param | Use when |
|
||||
| -------------- | ---------------------- | ---------------------------------------------- |
|
||||
| `llm_generate` | `'[]'` | Pure reasoning, JSON output, no external calls |
|
||||
| `llm_tool_use` | `'["tool1", "tool2"]'` | Needs to call MCP tools |
|
||||
|
||||
---
|
||||
|
||||
## REFERENCE: Edge Conditions
|
||||
|
||||
| Condition | When edge is followed |
|
||||
| ------------- | ------------------------------------- |
|
||||
| `on_success` | Source node completed successfully |
|
||||
| `on_failure` | Source node failed |
|
||||
| `always` | Always, regardless of success/failure |
|
||||
| `conditional` | When condition_expr evaluates to True |
|
||||
|
||||
---
|
||||
|
||||
## REFERENCE: System Prompt Best Practice
|
||||
|
||||
For nodes with JSON output, include this in the system_prompt:
|
||||
|
||||
```
|
||||
CRITICAL: Return ONLY raw JSON. NO markdown, NO code blocks.
|
||||
Just the JSON object starting with { and ending with }.
|
||||
|
||||
Return this exact structure:
|
||||
{
|
||||
"key1": "...",
|
||||
"key2": "..."
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## COMMON MISTAKES TO AVOID
|
||||
|
||||
1. **Using tools that don't exist** - Always check `mcp__agent-builder__list_mcp_tools()` first
|
||||
2. **Wrong entry_points format** - Must be `{"start": "node-id"}`, NOT a set or list
|
||||
3. **Skipping validation** - Always validate nodes and graph before proceeding
|
||||
4. **Not waiting for approval** - Always ask user before major steps
|
||||
5. **Displaying this file** - Execute the steps, don't show documentation
|
||||
@@ -1,80 +0,0 @@
|
||||
# Online Research Agent
|
||||
|
||||
Deep-dive research agent that searches 10+ sources and produces comprehensive narrative reports with citations.
|
||||
|
||||
## Features
|
||||
|
||||
- Generates multiple search queries from a topic
|
||||
- Searches and fetches 15+ web sources
|
||||
- Evaluates and ranks sources by relevance
|
||||
- Synthesizes findings into themes
|
||||
- Writes narrative report with numbered citations
|
||||
- Quality checks for uncited claims
|
||||
- Saves report to local markdown file
|
||||
|
||||
## Usage
|
||||
|
||||
### CLI
|
||||
|
||||
```bash
|
||||
# Show agent info
|
||||
python -m online_research_agent info
|
||||
|
||||
# Validate structure
|
||||
python -m online_research_agent validate
|
||||
|
||||
# Run research on a topic
|
||||
python -m online_research_agent run --topic "impact of AI on healthcare"
|
||||
|
||||
# Interactive shell
|
||||
python -m online_research_agent shell
|
||||
```
|
||||
|
||||
### Python API
|
||||
|
||||
```python
|
||||
from online_research_agent import default_agent
|
||||
|
||||
# Simple usage
|
||||
result = await default_agent.run({"topic": "climate change solutions"})
|
||||
|
||||
# Check output
|
||||
if result.success:
|
||||
print(f"Report saved to: {result.output['file_path']}")
|
||||
print(result.output['final_report'])
|
||||
```
|
||||
|
||||
## Workflow
|
||||
|
||||
```
|
||||
parse-query → search-sources → fetch-content → evaluate-sources
|
||||
↓
|
||||
write-report ← synthesize-findings
|
||||
↓
|
||||
quality-check → save-report
|
||||
```
|
||||
|
||||
## Output
|
||||
|
||||
Reports are saved to `./research_reports/` as markdown files with:
|
||||
|
||||
1. Executive Summary
|
||||
2. Introduction
|
||||
3. Key Findings (by theme)
|
||||
4. Analysis
|
||||
5. Conclusion
|
||||
6. References
|
||||
|
||||
## Requirements
|
||||
|
||||
- Python 3.11+
|
||||
- LLM provider API key (Groq, Cerebras, etc.)
|
||||
- Internet access for web search/fetch
|
||||
|
||||
## Configuration
|
||||
|
||||
Edit `config.py` to change:
|
||||
|
||||
- `model`: LLM model (default: groq/moonshotai/kimi-k2-instruct-0905)
|
||||
- `temperature`: Generation temperature (default: 0.7)
|
||||
- `max_tokens`: Max tokens per response (default: 16384)
|
||||
-23
@@ -1,23 +0,0 @@
|
||||
"""
|
||||
Online Research Agent - Deep-dive research with narrative reports.
|
||||
|
||||
Research any topic by searching multiple sources, synthesizing information,
|
||||
and producing a well-structured narrative report with citations.
|
||||
"""
|
||||
|
||||
from .agent import OnlineResearchAgent, default_agent, goal, nodes, edges
|
||||
from .config import RuntimeConfig, AgentMetadata, default_config, metadata
|
||||
|
||||
__version__ = "1.0.0"
|
||||
|
||||
__all__ = [
|
||||
"OnlineResearchAgent",
|
||||
"default_agent",
|
||||
"goal",
|
||||
"nodes",
|
||||
"edges",
|
||||
"RuntimeConfig",
|
||||
"AgentMetadata",
|
||||
"default_config",
|
||||
"metadata",
|
||||
]
|
||||
@@ -1,429 +0,0 @@
|
||||
"""Agent graph construction for Online Research Agent."""
|
||||
|
||||
from framework.graph import EdgeSpec, EdgeCondition, Goal, SuccessCriterion, Constraint
|
||||
from framework.graph.edge import GraphSpec
|
||||
from framework.graph.executor import ExecutionResult
|
||||
from framework.runtime.agent_runtime import AgentRuntime, create_agent_runtime
|
||||
from framework.runtime.execution_stream import EntryPointSpec
|
||||
from framework.llm import LiteLLMProvider
|
||||
from framework.runner.tool_registry import ToolRegistry
|
||||
|
||||
from .config import default_config, metadata
|
||||
from .nodes import (
|
||||
parse_query_node,
|
||||
search_sources_node,
|
||||
fetch_content_node,
|
||||
evaluate_sources_node,
|
||||
synthesize_findings_node,
|
||||
write_report_node,
|
||||
quality_check_node,
|
||||
save_report_node,
|
||||
)
|
||||
|
||||
# Goal definition
|
||||
goal = Goal(
|
||||
id="comprehensive-online-research",
|
||||
name="Comprehensive Online Research",
|
||||
description="Research any topic by searching multiple sources, synthesizing information, and producing a well-structured narrative report with citations.",
|
||||
success_criteria=[
|
||||
SuccessCriterion(
|
||||
id="source-coverage",
|
||||
description="Query 10+ diverse sources",
|
||||
metric="source_count",
|
||||
target=">=10",
|
||||
weight=0.20,
|
||||
),
|
||||
SuccessCriterion(
|
||||
id="relevance",
|
||||
description="All sources directly address the query",
|
||||
metric="relevance_score",
|
||||
target="90%",
|
||||
weight=0.25,
|
||||
),
|
||||
SuccessCriterion(
|
||||
id="synthesis",
|
||||
description="Synthesize findings into coherent narrative",
|
||||
metric="coherence_score",
|
||||
target="85%",
|
||||
weight=0.25,
|
||||
),
|
||||
SuccessCriterion(
|
||||
id="citations",
|
||||
description="Include citations for all claims",
|
||||
metric="citation_coverage",
|
||||
target="100%",
|
||||
weight=0.15,
|
||||
),
|
||||
SuccessCriterion(
|
||||
id="actionable",
|
||||
description="Report answers the user's question",
|
||||
metric="answer_completeness",
|
||||
target="90%",
|
||||
weight=0.15,
|
||||
),
|
||||
],
|
||||
constraints=[
|
||||
Constraint(
|
||||
id="no-hallucination",
|
||||
description="Only include information found in sources",
|
||||
constraint_type="quality",
|
||||
category="accuracy",
|
||||
),
|
||||
Constraint(
|
||||
id="source-attribution",
|
||||
description="Every factual claim must cite its source",
|
||||
constraint_type="quality",
|
||||
category="accuracy",
|
||||
),
|
||||
Constraint(
|
||||
id="recency-preference",
|
||||
description="Prefer recent sources when relevant",
|
||||
constraint_type="quality",
|
||||
category="relevance",
|
||||
),
|
||||
Constraint(
|
||||
id="no-paywalled",
|
||||
description="Avoid sources that require payment to access",
|
||||
constraint_type="functional",
|
||||
category="accessibility",
|
||||
),
|
||||
],
|
||||
)
|
||||
|
||||
# Node list
|
||||
nodes = [
|
||||
parse_query_node,
|
||||
search_sources_node,
|
||||
fetch_content_node,
|
||||
evaluate_sources_node,
|
||||
synthesize_findings_node,
|
||||
write_report_node,
|
||||
quality_check_node,
|
||||
save_report_node,
|
||||
]
|
||||
|
||||
# Edge definitions
|
||||
edges = [
|
||||
EdgeSpec(
|
||||
id="parse-to-search",
|
||||
source="parse-query",
|
||||
target="search-sources",
|
||||
condition=EdgeCondition.ON_SUCCESS,
|
||||
priority=1,
|
||||
),
|
||||
EdgeSpec(
|
||||
id="search-to-fetch",
|
||||
source="search-sources",
|
||||
target="fetch-content",
|
||||
condition=EdgeCondition.ON_SUCCESS,
|
||||
priority=1,
|
||||
),
|
||||
EdgeSpec(
|
||||
id="fetch-to-evaluate",
|
||||
source="fetch-content",
|
||||
target="evaluate-sources",
|
||||
condition=EdgeCondition.ON_SUCCESS,
|
||||
priority=1,
|
||||
),
|
||||
EdgeSpec(
|
||||
id="evaluate-to-synthesize",
|
||||
source="evaluate-sources",
|
||||
target="synthesize-findings",
|
||||
condition=EdgeCondition.ON_SUCCESS,
|
||||
priority=1,
|
||||
),
|
||||
EdgeSpec(
|
||||
id="synthesize-to-write",
|
||||
source="synthesize-findings",
|
||||
target="write-report",
|
||||
condition=EdgeCondition.ON_SUCCESS,
|
||||
priority=1,
|
||||
),
|
||||
EdgeSpec(
|
||||
id="write-to-quality",
|
||||
source="write-report",
|
||||
target="quality-check",
|
||||
condition=EdgeCondition.ON_SUCCESS,
|
||||
priority=1,
|
||||
),
|
||||
EdgeSpec(
|
||||
id="quality-to-save",
|
||||
source="quality-check",
|
||||
target="save-report",
|
||||
condition=EdgeCondition.ON_SUCCESS,
|
||||
priority=1,
|
||||
),
|
||||
]
|
||||
|
||||
# Graph configuration
|
||||
entry_node = "parse-query"
|
||||
entry_points = {"start": "parse-query"}
|
||||
pause_nodes = []
|
||||
terminal_nodes = ["save-report"]
|
||||
|
||||
|
||||
class OnlineResearchAgent:
|
||||
"""
|
||||
Online Research Agent - Deep-dive research with narrative reports.
|
||||
|
||||
Uses AgentRuntime for multi-entrypoint support with HITL pause/resume.
|
||||
"""
|
||||
|
||||
def __init__(self, config=None):
|
||||
self.config = config or default_config
|
||||
self.goal = goal
|
||||
self.nodes = nodes
|
||||
self.edges = edges
|
||||
self.entry_node = entry_node
|
||||
self.entry_points = entry_points
|
||||
self.pause_nodes = pause_nodes
|
||||
self.terminal_nodes = terminal_nodes
|
||||
self._runtime: AgentRuntime | None = None
|
||||
self._graph: GraphSpec | None = None
|
||||
|
||||
def _build_entry_point_specs(self) -> list[EntryPointSpec]:
|
||||
"""Convert entry_points dict to EntryPointSpec list."""
|
||||
specs = []
|
||||
for ep_id, node_id in self.entry_points.items():
|
||||
if ep_id == "start":
|
||||
trigger_type = "manual"
|
||||
name = "Start"
|
||||
elif "_resume" in ep_id:
|
||||
trigger_type = "resume"
|
||||
name = f"Resume from {ep_id.replace('_resume', '')}"
|
||||
else:
|
||||
trigger_type = "manual"
|
||||
name = ep_id.replace("-", " ").title()
|
||||
|
||||
specs.append(
|
||||
EntryPointSpec(
|
||||
id=ep_id,
|
||||
name=name,
|
||||
entry_node=node_id,
|
||||
trigger_type=trigger_type,
|
||||
isolation_level="shared",
|
||||
)
|
||||
)
|
||||
return specs
|
||||
|
||||
def _create_runtime(self, mock_mode=False) -> AgentRuntime:
|
||||
"""Create AgentRuntime instance."""
|
||||
import json
|
||||
from pathlib import Path
|
||||
|
||||
# Persistent storage in ~/.hive for telemetry and run history
|
||||
storage_path = Path.home() / ".hive" / "online_research_agent"
|
||||
storage_path.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
tool_registry = ToolRegistry()
|
||||
|
||||
# Load MCP servers (always load, needed for tool validation)
|
||||
agent_dir = Path(__file__).parent
|
||||
mcp_config_path = agent_dir / "mcp_servers.json"
|
||||
|
||||
if mcp_config_path.exists():
|
||||
with open(mcp_config_path) as f:
|
||||
mcp_servers = json.load(f)
|
||||
|
||||
for server_config in mcp_servers.get("servers", []):
|
||||
# Resolve relative cwd paths
|
||||
cwd = server_config.get("cwd")
|
||||
if cwd and not Path(cwd).is_absolute():
|
||||
server_config["cwd"] = str(agent_dir / cwd)
|
||||
tool_registry.register_mcp_server(server_config)
|
||||
|
||||
llm = None
|
||||
if not mock_mode:
|
||||
# LiteLLMProvider uses environment variables for API keys
|
||||
llm = LiteLLMProvider(
|
||||
model=self.config.model,
|
||||
api_key=self.config.api_key,
|
||||
api_base=self.config.api_base,
|
||||
)
|
||||
|
||||
self._graph = GraphSpec(
|
||||
id="online-research-agent-graph",
|
||||
goal_id=self.goal.id,
|
||||
version="1.0.0",
|
||||
entry_node=self.entry_node,
|
||||
entry_points=self.entry_points,
|
||||
terminal_nodes=self.terminal_nodes,
|
||||
pause_nodes=self.pause_nodes,
|
||||
nodes=self.nodes,
|
||||
edges=self.edges,
|
||||
default_model=self.config.model,
|
||||
max_tokens=self.config.max_tokens,
|
||||
)
|
||||
|
||||
# Create AgentRuntime with all entry points
|
||||
self._runtime = create_agent_runtime(
|
||||
graph=self._graph,
|
||||
goal=self.goal,
|
||||
storage_path=storage_path,
|
||||
entry_points=self._build_entry_point_specs(),
|
||||
llm=llm,
|
||||
tools=list(tool_registry.get_tools().values()),
|
||||
tool_executor=tool_registry.get_executor(),
|
||||
)
|
||||
|
||||
return self._runtime
|
||||
|
||||
async def start(self, mock_mode=False) -> None:
|
||||
"""Start the agent runtime."""
|
||||
if self._runtime is None:
|
||||
self._create_runtime(mock_mode=mock_mode)
|
||||
await self._runtime.start()
|
||||
|
||||
async def stop(self) -> None:
|
||||
"""Stop the agent runtime."""
|
||||
if self._runtime is not None:
|
||||
await self._runtime.stop()
|
||||
|
||||
async def trigger(
|
||||
self,
|
||||
entry_point: str,
|
||||
input_data: dict,
|
||||
correlation_id: str | None = None,
|
||||
session_state: dict | None = None,
|
||||
) -> str:
|
||||
"""
|
||||
Trigger execution at a specific entry point (non-blocking).
|
||||
|
||||
Args:
|
||||
entry_point: Entry point ID (e.g., "start", "pause-node_resume")
|
||||
input_data: Input data for the execution
|
||||
correlation_id: Optional ID to correlate related executions
|
||||
session_state: Optional session state to resume from (with paused_at, memory)
|
||||
|
||||
Returns:
|
||||
Execution ID for tracking
|
||||
"""
|
||||
if self._runtime is None or not self._runtime.is_running:
|
||||
raise RuntimeError("Agent runtime not started. Call start() first.")
|
||||
return await self._runtime.trigger(
|
||||
entry_point, input_data, correlation_id, session_state=session_state
|
||||
)
|
||||
|
||||
async def trigger_and_wait(
|
||||
self,
|
||||
entry_point: str,
|
||||
input_data: dict,
|
||||
timeout: float | None = None,
|
||||
session_state: dict | None = None,
|
||||
) -> ExecutionResult | None:
|
||||
"""
|
||||
Trigger execution and wait for completion.
|
||||
|
||||
Args:
|
||||
entry_point: Entry point ID
|
||||
input_data: Input data for the execution
|
||||
timeout: Maximum time to wait (seconds)
|
||||
session_state: Optional session state to resume from (with paused_at, memory)
|
||||
|
||||
Returns:
|
||||
ExecutionResult or None if timeout
|
||||
"""
|
||||
if self._runtime is None or not self._runtime.is_running:
|
||||
raise RuntimeError("Agent runtime not started. Call start() first.")
|
||||
return await self._runtime.trigger_and_wait(
|
||||
entry_point, input_data, timeout, session_state=session_state
|
||||
)
|
||||
|
||||
async def run(
|
||||
self, context: dict, mock_mode=False, session_state=None
|
||||
) -> ExecutionResult:
|
||||
"""
|
||||
Run the agent (convenience method for simple single execution).
|
||||
|
||||
For more control, use start() + trigger_and_wait() + stop().
|
||||
"""
|
||||
await self.start(mock_mode=mock_mode)
|
||||
try:
|
||||
# Determine entry point based on session_state
|
||||
if session_state and "paused_at" in session_state:
|
||||
paused_node = session_state["paused_at"]
|
||||
resume_key = f"{paused_node}_resume"
|
||||
if resume_key in self.entry_points:
|
||||
entry_point = resume_key
|
||||
else:
|
||||
entry_point = "start"
|
||||
else:
|
||||
entry_point = "start"
|
||||
|
||||
result = await self.trigger_and_wait(
|
||||
entry_point, context, session_state=session_state
|
||||
)
|
||||
return result or ExecutionResult(success=False, error="Execution timeout")
|
||||
finally:
|
||||
await self.stop()
|
||||
|
||||
async def get_goal_progress(self) -> dict:
|
||||
"""Get goal progress across all executions."""
|
||||
if self._runtime is None:
|
||||
raise RuntimeError("Agent runtime not started")
|
||||
return await self._runtime.get_goal_progress()
|
||||
|
||||
def get_stats(self) -> dict:
|
||||
"""Get runtime statistics."""
|
||||
if self._runtime is None:
|
||||
return {"running": False}
|
||||
return self._runtime.get_stats()
|
||||
|
||||
def info(self):
|
||||
"""Get agent information."""
|
||||
return {
|
||||
"name": metadata.name,
|
||||
"version": metadata.version,
|
||||
"description": metadata.description,
|
||||
"goal": {
|
||||
"name": self.goal.name,
|
||||
"description": self.goal.description,
|
||||
},
|
||||
"nodes": [n.id for n in self.nodes],
|
||||
"edges": [e.id for e in self.edges],
|
||||
"entry_node": self.entry_node,
|
||||
"entry_points": self.entry_points,
|
||||
"pause_nodes": self.pause_nodes,
|
||||
"terminal_nodes": self.terminal_nodes,
|
||||
"multi_entrypoint": True,
|
||||
}
|
||||
|
||||
def validate(self):
|
||||
"""Validate agent structure."""
|
||||
errors = []
|
||||
warnings = []
|
||||
|
||||
node_ids = {node.id for node in self.nodes}
|
||||
for edge in self.edges:
|
||||
if edge.source not in node_ids:
|
||||
errors.append(f"Edge {edge.id}: source '{edge.source}' not found")
|
||||
if edge.target not in node_ids:
|
||||
errors.append(f"Edge {edge.id}: target '{edge.target}' not found")
|
||||
|
||||
if self.entry_node not in node_ids:
|
||||
errors.append(f"Entry node '{self.entry_node}' not found")
|
||||
|
||||
for terminal in self.terminal_nodes:
|
||||
if terminal not in node_ids:
|
||||
errors.append(f"Terminal node '{terminal}' not found")
|
||||
|
||||
for pause in self.pause_nodes:
|
||||
if pause not in node_ids:
|
||||
errors.append(f"Pause node '{pause}' not found")
|
||||
|
||||
# Validate entry points
|
||||
for ep_id, node_id in self.entry_points.items():
|
||||
if node_id not in node_ids:
|
||||
errors.append(
|
||||
f"Entry point '{ep_id}' references unknown node '{node_id}'"
|
||||
)
|
||||
|
||||
return {
|
||||
"valid": len(errors) == 0,
|
||||
"errors": errors,
|
||||
"warnings": warnings,
|
||||
}
|
||||
|
||||
|
||||
# Create default instance
|
||||
default_agent = OnlineResearchAgent()
|
||||
-396
@@ -1,396 +0,0 @@
|
||||
"""Node definitions for Online Research Agent."""
|
||||
|
||||
from framework.graph import NodeSpec
|
||||
|
||||
# Node 1: Parse Query
|
||||
parse_query_node = NodeSpec(
|
||||
id="parse-query",
|
||||
name="Parse Query",
|
||||
description="Analyze the research topic and generate 3-5 diverse search queries to cover different aspects",
|
||||
node_type="llm_generate",
|
||||
input_keys=["topic"],
|
||||
output_keys=["search_queries", "research_focus", "key_aspects"],
|
||||
output_schema={
|
||||
"research_focus": {
|
||||
"type": "string",
|
||||
"required": True,
|
||||
"description": "Brief statement of what we're researching",
|
||||
},
|
||||
"key_aspects": {
|
||||
"type": "array",
|
||||
"required": True,
|
||||
"description": "List of 3-5 key aspects to investigate",
|
||||
},
|
||||
"search_queries": {
|
||||
"type": "array",
|
||||
"required": True,
|
||||
"description": "List of 3-5 search queries",
|
||||
},
|
||||
},
|
||||
system_prompt="""\
|
||||
You are a research query strategist. Given a research topic, analyze it and generate search queries.
|
||||
|
||||
Your task:
|
||||
1. Understand the core research question
|
||||
2. Identify 3-5 key aspects to investigate
|
||||
3. Generate 3-5 diverse search queries that will find comprehensive information
|
||||
|
||||
CRITICAL: Return ONLY raw JSON. NO markdown, NO code blocks.
|
||||
|
||||
Return this JSON structure:
|
||||
{
|
||||
"research_focus": "Brief statement of what we're researching",
|
||||
"key_aspects": ["aspect1", "aspect2", "aspect3"],
|
||||
"search_queries": [
|
||||
"query 1 - broad overview",
|
||||
"query 2 - specific angle",
|
||||
"query 3 - recent developments",
|
||||
"query 4 - expert opinions",
|
||||
"query 5 - data/statistics"
|
||||
]
|
||||
}
|
||||
""",
|
||||
tools=[],
|
||||
max_retries=3,
|
||||
)
|
||||
|
||||
# Node 2: Search Sources
|
||||
search_sources_node = NodeSpec(
|
||||
id="search-sources",
|
||||
name="Search Sources",
|
||||
description="Execute web searches using the generated queries to find 15+ source URLs",
|
||||
node_type="llm_tool_use",
|
||||
input_keys=["search_queries", "research_focus"],
|
||||
output_keys=["source_urls", "search_results_summary"],
|
||||
output_schema={
|
||||
"source_urls": {
|
||||
"type": "array",
|
||||
"required": True,
|
||||
"description": "List of source URLs found",
|
||||
},
|
||||
"search_results_summary": {
|
||||
"type": "string",
|
||||
"required": True,
|
||||
"description": "Brief summary of what was found",
|
||||
},
|
||||
},
|
||||
system_prompt="""\
|
||||
You are a research assistant executing web searches. Use the web_search tool to find sources.
|
||||
|
||||
Your task:
|
||||
1. Execute each search query using web_search tool
|
||||
2. Collect URLs from search results
|
||||
3. Aim for 15+ diverse sources
|
||||
|
||||
After searching, return JSON with found sources:
|
||||
{
|
||||
"source_urls": ["url1", "url2", ...],
|
||||
"search_results_summary": "Brief summary of what was found"
|
||||
}
|
||||
""",
|
||||
tools=["web_search"],
|
||||
max_retries=3,
|
||||
)
|
||||
|
||||
# Node 3: Fetch Content
|
||||
fetch_content_node = NodeSpec(
|
||||
id="fetch-content",
|
||||
name="Fetch Content",
|
||||
description="Fetch and extract content from the discovered source URLs",
|
||||
node_type="llm_tool_use",
|
||||
input_keys=["source_urls", "research_focus"],
|
||||
output_keys=["fetched_sources", "fetch_errors"],
|
||||
output_schema={
|
||||
"fetched_sources": {
|
||||
"type": "array",
|
||||
"required": True,
|
||||
"description": "List of fetched source objects with url, title, content",
|
||||
},
|
||||
"fetch_errors": {
|
||||
"type": "array",
|
||||
"required": True,
|
||||
"description": "List of URLs that failed to fetch",
|
||||
},
|
||||
},
|
||||
system_prompt="""\
|
||||
You are a content fetcher. Use web_scrape tool to retrieve content from URLs.
|
||||
|
||||
Your task:
|
||||
1. Fetch content from each source URL using web_scrape tool
|
||||
2. Extract the main content relevant to the research focus
|
||||
3. Track any URLs that failed to fetch
|
||||
|
||||
After fetching, return JSON:
|
||||
{
|
||||
"fetched_sources": [
|
||||
{"url": "...", "title": "...", "content": "extracted text..."},
|
||||
...
|
||||
],
|
||||
"fetch_errors": ["url that failed", ...]
|
||||
}
|
||||
""",
|
||||
tools=["web_scrape"],
|
||||
max_retries=3,
|
||||
)
|
||||
|
||||
# Node 4: Evaluate Sources
|
||||
evaluate_sources_node = NodeSpec(
|
||||
id="evaluate-sources",
|
||||
name="Evaluate Sources",
|
||||
description="Score sources for relevance and quality, filter to top 10",
|
||||
node_type="llm_generate",
|
||||
input_keys=["fetched_sources", "research_focus", "key_aspects"],
|
||||
output_keys=["ranked_sources", "source_analysis"],
|
||||
output_schema={
|
||||
"ranked_sources": {
|
||||
"type": "array",
|
||||
"required": True,
|
||||
"description": "List of ranked sources with scores",
|
||||
},
|
||||
"source_analysis": {
|
||||
"type": "string",
|
||||
"required": True,
|
||||
"description": "Overview of source quality and coverage",
|
||||
},
|
||||
},
|
||||
system_prompt="""\
|
||||
You are a source evaluator. Assess each source for quality and relevance.
|
||||
|
||||
Scoring criteria:
|
||||
- Relevance to research focus (1-10)
|
||||
- Source credibility (1-10)
|
||||
- Information depth (1-10)
|
||||
- Recency if relevant (1-10)
|
||||
|
||||
Your task:
|
||||
1. Score each source
|
||||
2. Rank by combined score
|
||||
3. Select top 10 sources
|
||||
4. Note what each source uniquely contributes
|
||||
|
||||
Return JSON:
|
||||
{
|
||||
"ranked_sources": [
|
||||
{"url": "...", "title": "...", "content": "...", "score": 8.5, "unique_value": "..."},
|
||||
...
|
||||
],
|
||||
"source_analysis": "Overview of source quality and coverage"
|
||||
}
|
||||
""",
|
||||
tools=[],
|
||||
max_retries=3,
|
||||
)
|
||||
|
||||
# Node 5: Synthesize Findings
|
||||
synthesize_findings_node = NodeSpec(
|
||||
id="synthesize-findings",
|
||||
name="Synthesize Findings",
|
||||
description="Extract key facts from sources and identify common themes",
|
||||
node_type="llm_generate",
|
||||
input_keys=["ranked_sources", "research_focus", "key_aspects"],
|
||||
output_keys=["key_findings", "themes", "source_citations"],
|
||||
output_schema={
|
||||
"key_findings": {
|
||||
"type": "array",
|
||||
"required": True,
|
||||
"description": "List of key findings with sources and confidence",
|
||||
},
|
||||
"themes": {
|
||||
"type": "array",
|
||||
"required": True,
|
||||
"description": "List of themes with descriptions and supporting sources",
|
||||
},
|
||||
"source_citations": {
|
||||
"type": "object",
|
||||
"required": True,
|
||||
"description": "Map of facts to supporting URLs",
|
||||
},
|
||||
},
|
||||
system_prompt="""\
|
||||
You are a research synthesizer. Analyze multiple sources to extract insights.
|
||||
|
||||
Your task:
|
||||
1. Identify key facts from each source
|
||||
2. Find common themes across sources
|
||||
3. Note contradictions or debates
|
||||
4. Build a citation map (fact -> source URL)
|
||||
|
||||
Return JSON:
|
||||
{
|
||||
"key_findings": [
|
||||
{"finding": "...", "sources": ["url1", "url2"], "confidence": "high/medium/low"},
|
||||
...
|
||||
],
|
||||
"themes": [
|
||||
{"theme": "...", "description": "...", "supporting_sources": ["url1", ...]},
|
||||
...
|
||||
],
|
||||
"source_citations": {
|
||||
"fact or claim": ["supporting url1", "url2"],
|
||||
...
|
||||
}
|
||||
}
|
||||
""",
|
||||
tools=[],
|
||||
max_retries=3,
|
||||
)
|
||||
|
||||
# Node 6: Write Report
|
||||
write_report_node = NodeSpec(
|
||||
id="write-report",
|
||||
name="Write Report",
|
||||
description="Generate a narrative report with proper citations",
|
||||
node_type="llm_generate",
|
||||
input_keys=[
|
||||
"key_findings",
|
||||
"themes",
|
||||
"source_citations",
|
||||
"research_focus",
|
||||
"ranked_sources",
|
||||
],
|
||||
output_keys=["report_content", "references"],
|
||||
output_schema={
|
||||
"report_content": {
|
||||
"type": "string",
|
||||
"required": True,
|
||||
"description": "Full markdown report text with citations",
|
||||
},
|
||||
"references": {
|
||||
"type": "array",
|
||||
"required": True,
|
||||
"description": "List of reference objects with number, url, title",
|
||||
},
|
||||
},
|
||||
system_prompt="""\
|
||||
You are a research report writer. Create a well-structured narrative report.
|
||||
|
||||
Report structure:
|
||||
1. Executive Summary (2-3 paragraphs)
|
||||
2. Introduction (context and scope)
|
||||
3. Key Findings (organized by theme)
|
||||
4. Analysis (synthesis and implications)
|
||||
5. Conclusion
|
||||
6. References (numbered list of all sources)
|
||||
|
||||
Citation format: Use numbered citations like [1], [2] that correspond to the References section.
|
||||
|
||||
IMPORTANT:
|
||||
- Every factual claim MUST have a citation
|
||||
- Write in clear, professional prose
|
||||
- Be objective and balanced
|
||||
- Highlight areas of consensus and debate
|
||||
|
||||
Return JSON:
|
||||
{
|
||||
"report_content": "Full markdown report text with citations...",
|
||||
"references": [
|
||||
{"number": 1, "url": "...", "title": "..."},
|
||||
...
|
||||
]
|
||||
}
|
||||
""",
|
||||
tools=[],
|
||||
max_retries=3,
|
||||
)
|
||||
|
||||
# Node 7: Quality Check
|
||||
quality_check_node = NodeSpec(
|
||||
id="quality-check",
|
||||
name="Quality Check",
|
||||
description="Verify all claims have citations and report is coherent",
|
||||
node_type="llm_generate",
|
||||
input_keys=["report_content", "references", "source_citations"],
|
||||
output_keys=["quality_score", "issues", "final_report"],
|
||||
output_schema={
|
||||
"quality_score": {
|
||||
"type": "number",
|
||||
"required": True,
|
||||
"description": "Quality score 0-1",
|
||||
},
|
||||
"issues": {
|
||||
"type": "array",
|
||||
"required": True,
|
||||
"description": "List of issues found and fixed",
|
||||
},
|
||||
"final_report": {
|
||||
"type": "string",
|
||||
"required": True,
|
||||
"description": "Corrected full report",
|
||||
},
|
||||
},
|
||||
system_prompt="""\
|
||||
You are a quality assurance reviewer. Check the research report for issues.
|
||||
|
||||
Check for:
|
||||
1. Uncited claims (factual statements without [n] citation)
|
||||
2. Broken citations (references to non-existent numbers)
|
||||
3. Coherence (logical flow between sections)
|
||||
4. Completeness (all key aspects covered)
|
||||
5. Accuracy (claims match source content)
|
||||
|
||||
If issues found, fix them in the final report.
|
||||
|
||||
Return JSON:
|
||||
{
|
||||
"quality_score": 0.95,
|
||||
"issues": [
|
||||
{"type": "uncited_claim", "location": "paragraph 3", "fixed": true},
|
||||
...
|
||||
],
|
||||
"final_report": "Corrected full report with all issues fixed..."
|
||||
}
|
||||
""",
|
||||
tools=[],
|
||||
max_retries=3,
|
||||
)
|
||||
|
||||
# Node 8: Save Report
|
||||
save_report_node = NodeSpec(
|
||||
id="save-report",
|
||||
name="Save Report",
|
||||
description="Write the final report to a local markdown file",
|
||||
node_type="llm_tool_use",
|
||||
input_keys=["final_report", "references", "research_focus"],
|
||||
output_keys=["file_path", "save_status"],
|
||||
output_schema={
|
||||
"file_path": {
|
||||
"type": "string",
|
||||
"required": True,
|
||||
"description": "Path where report was saved",
|
||||
},
|
||||
"save_status": {
|
||||
"type": "string",
|
||||
"required": True,
|
||||
"description": "Status of save operation",
|
||||
},
|
||||
},
|
||||
system_prompt="""\
|
||||
You are a file manager. Save the research report to disk.
|
||||
|
||||
Your task:
|
||||
1. Generate a filename from the research focus (slugified, with date)
|
||||
2. Use the write_to_file tool to save the report as markdown
|
||||
3. Save to the ./research_reports/ directory
|
||||
|
||||
Filename format: research_YYYY-MM-DD_topic-slug.md
|
||||
|
||||
Return JSON:
|
||||
{
|
||||
"file_path": "research_reports/research_2026-01-23_topic-name.md",
|
||||
"save_status": "success"
|
||||
}
|
||||
""",
|
||||
tools=["write_to_file"],
|
||||
max_retries=3,
|
||||
)
|
||||
|
||||
__all__ = [
|
||||
"parse_query_node",
|
||||
"search_sources_node",
|
||||
"fetch_content_node",
|
||||
"evaluate_sources_node",
|
||||
"synthesize_findings_node",
|
||||
"write_report_node",
|
||||
"quality_check_node",
|
||||
"save_report_node",
|
||||
]
|
||||
@@ -1,303 +0,0 @@
|
||||
---
|
||||
name: building-agents-core
|
||||
description: Core concepts for goal-driven agents - architecture, node types, tool discovery, and workflow overview. Use when starting agent development or need to understand agent fundamentals.
|
||||
license: Apache-2.0
|
||||
metadata:
|
||||
author: hive
|
||||
version: "1.0"
|
||||
type: foundational
|
||||
part_of: building-agents
|
||||
---
|
||||
|
||||
# Building Agents - Core Concepts
|
||||
|
||||
Foundational knowledge for building goal-driven agents as Python packages.
|
||||
|
||||
## Architecture: Python Services (Not JSON Configs)
|
||||
|
||||
Agents are built as Python packages:
|
||||
|
||||
```
|
||||
exports/my_agent/
|
||||
├── __init__.py # Package exports
|
||||
├── __main__.py # CLI (run, info, validate, shell)
|
||||
├── agent.py # Graph construction (goal, edges, agent class)
|
||||
├── nodes/__init__.py # Node definitions (NodeSpec)
|
||||
├── config.py # Runtime config
|
||||
└── README.md # Documentation
|
||||
```
|
||||
|
||||
**Key Principle: Agent is visible and editable during build**
|
||||
|
||||
- ✅ Files created immediately as components are approved
|
||||
- ✅ User can watch files grow in their editor
|
||||
- ✅ No session state - just direct file writes
|
||||
- ✅ No "export" step - agent is ready when build completes
|
||||
|
||||
## Core Concepts
|
||||
|
||||
### Goal
|
||||
|
||||
Success criteria and constraints (written to agent.py)
|
||||
|
||||
```python
|
||||
goal = Goal(
|
||||
id="research-goal",
|
||||
name="Technical Research Agent",
|
||||
description="Research technical topics thoroughly",
|
||||
success_criteria=[
|
||||
SuccessCriterion(
|
||||
id="completeness",
|
||||
description="Cover all aspects of topic",
|
||||
metric="coverage_score",
|
||||
target=">=0.9",
|
||||
weight=0.4,
|
||||
),
|
||||
# 3-5 success criteria total
|
||||
],
|
||||
constraints=[
|
||||
Constraint(
|
||||
id="accuracy",
|
||||
description="All information must be verified",
|
||||
constraint_type="hard",
|
||||
category="quality",
|
||||
),
|
||||
# 1-5 constraints total
|
||||
],
|
||||
)
|
||||
```
|
||||
|
||||
### Node
|
||||
|
||||
Unit of work (written to nodes/__init__.py)
|
||||
|
||||
**Node Types:**
|
||||
|
||||
- `llm_generate` - Text generation, parsing
|
||||
- `llm_tool_use` - Actions requiring tools
|
||||
- `router` - Conditional branching
|
||||
- `function` - Deterministic operations
|
||||
|
||||
```python
|
||||
search_node = NodeSpec(
|
||||
id="search-web",
|
||||
name="Search Web",
|
||||
description="Search for information online",
|
||||
node_type="llm_tool_use",
|
||||
input_keys=["query"],
|
||||
output_keys=["search_results"],
|
||||
system_prompt="Search the web for: {query}",
|
||||
tools=["web_search"],
|
||||
max_retries=3,
|
||||
)
|
||||
```
|
||||
|
||||
### Edge
|
||||
|
||||
Connection between nodes (written to agent.py)
|
||||
|
||||
**Edge Conditions:**
|
||||
|
||||
- `on_success` - Proceed if node succeeds
|
||||
- `on_failure` - Handle errors
|
||||
- `always` - Always proceed
|
||||
- `conditional` - Based on expression
|
||||
|
||||
```python
|
||||
EdgeSpec(
|
||||
id="search-to-analyze",
|
||||
source="search-web",
|
||||
target="analyze-results",
|
||||
condition=EdgeCondition.ON_SUCCESS,
|
||||
priority=1,
|
||||
)
|
||||
```
|
||||
|
||||
### Pause/Resume
|
||||
|
||||
Multi-turn conversations
|
||||
|
||||
- **Pause nodes** - Stop execution, wait for user input
|
||||
- **Resume entry points** - Continue from pause with user's response
|
||||
|
||||
```python
|
||||
# Example pause/resume configuration
|
||||
pause_nodes = ["request-clarification"]
|
||||
entry_points = {
|
||||
"start": "analyze-request",
|
||||
"request-clarification_resume": "process-clarification"
|
||||
}
|
||||
```
|
||||
|
||||
## Tool Discovery & Validation
|
||||
|
||||
**CRITICAL:** Before adding a node with tools, you MUST verify the tools exist.
|
||||
|
||||
Tools are provided by MCP servers. Never assume a tool exists - always discover dynamically.
|
||||
|
||||
### Step 1: Register MCP Server (if not already done)
|
||||
|
||||
```python
|
||||
mcp__agent-builder__add_mcp_server(
|
||||
name="tools",
|
||||
transport="stdio",
|
||||
command="python",
|
||||
args='["mcp_server.py", "--stdio"]',
|
||||
cwd="../tools"
|
||||
)
|
||||
```
|
||||
|
||||
### Step 2: Discover Available Tools
|
||||
|
||||
```python
|
||||
# List all tools from all registered servers
|
||||
mcp__agent-builder__list_mcp_tools()
|
||||
|
||||
# Or list tools from a specific server
|
||||
mcp__agent-builder__list_mcp_tools(server_name="tools")
|
||||
```
|
||||
|
||||
This returns available tools with their descriptions and parameters:
|
||||
|
||||
```json
|
||||
{
|
||||
"success": true,
|
||||
"tools_by_server": {
|
||||
"tools": [
|
||||
{
|
||||
"name": "web_search",
|
||||
"description": "Search the web...",
|
||||
"parameters": ["query"]
|
||||
},
|
||||
{
|
||||
"name": "web_scrape",
|
||||
"description": "Scrape a URL...",
|
||||
"parameters": ["url"]
|
||||
}
|
||||
]
|
||||
},
|
||||
"total_tools": 14
|
||||
}
|
||||
```
|
||||
|
||||
### Step 3: Validate Before Adding Nodes
|
||||
|
||||
Before writing a node with `tools=[...]`:
|
||||
|
||||
1. Call `list_mcp_tools()` to get available tools
|
||||
2. Check each tool in your node exists in the response
|
||||
3. If a tool doesn't exist:
|
||||
- **DO NOT proceed** with the node
|
||||
- Inform the user: "The tool 'X' is not available. Available tools are: ..."
|
||||
- Ask if they want to use an alternative or proceed without the tool
|
||||
|
||||
### Tool Validation Anti-Patterns
|
||||
|
||||
❌ **Never assume a tool exists** - always call `list_mcp_tools()` first
|
||||
❌ **Never write a node with unverified tools** - validate before writing
|
||||
❌ **Never silently drop tools** - if a tool doesn't exist, inform the user
|
||||
❌ **Never guess tool names** - use exact names from discovery response
|
||||
|
||||
### Example Validation Flow
|
||||
|
||||
```python
|
||||
# 1. User requests: "Add a node that searches the web"
|
||||
# 2. Discover available tools
|
||||
tools_response = mcp__agent-builder__list_mcp_tools()
|
||||
|
||||
# 3. Check if web_search exists
|
||||
available = [t["name"] for tools in tools_response["tools_by_server"].values() for t in tools]
|
||||
if "web_search" not in available:
|
||||
# Inform user and ask how to proceed
|
||||
print("❌ 'web_search' not available. Available tools:", available)
|
||||
else:
|
||||
# Proceed with node creation
|
||||
# ...
|
||||
```
|
||||
|
||||
## Workflow Overview: Incremental File Construction
|
||||
|
||||
```
|
||||
1. CREATE PACKAGE → mkdir + write skeletons
|
||||
2. DEFINE GOAL → Write to agent.py + config.py
|
||||
3. FOR EACH NODE:
|
||||
- Propose design
|
||||
- User approves
|
||||
- Write to nodes/__init__.py IMMEDIATELY ← FILE WRITTEN
|
||||
- (Optional) Validate with test_node ← MCP VALIDATION
|
||||
- User can open file and see it
|
||||
4. CONNECT EDGES → Update agent.py ← FILE WRITTEN
|
||||
- (Optional) Validate with validate_graph ← MCP VALIDATION
|
||||
5. FINALIZE → Write agent class to agent.py ← FILE WRITTEN
|
||||
6. DONE - Agent ready at exports/my_agent/
|
||||
```
|
||||
|
||||
**Files written immediately. MCP tools optional for validation/testing bookkeeping.**
|
||||
|
||||
### The Key Difference
|
||||
|
||||
**OLD (Bad):**
|
||||
|
||||
```
|
||||
MCP add_node → Session State → MCP add_node → Session State → ...
|
||||
↓
|
||||
MCP export_graph
|
||||
↓
|
||||
Files appear
|
||||
```
|
||||
|
||||
**NEW (Good):**
|
||||
|
||||
```
|
||||
Write node to file → (Optional: MCP test_node) → Write node to file → ...
|
||||
↓ ↓
|
||||
File visible File visible
|
||||
immediately immediately
|
||||
```
|
||||
|
||||
**Bottom line:** Use Write/Edit for construction, MCP for validation if needed.
|
||||
|
||||
## When to Use This Skill
|
||||
|
||||
Use building-agents-core when:
|
||||
- Starting a new agent project and need to understand fundamentals
|
||||
- Need to understand agent architecture before building
|
||||
- Want to validate tool availability before proceeding
|
||||
- Learning about node types, edges, and graph execution
|
||||
|
||||
**Next Steps:**
|
||||
- Ready to build? → Use `building-agents-construction` skill
|
||||
- Need patterns and examples? → Use `building-agents-patterns` skill
|
||||
|
||||
## MCP Tools for Validation
|
||||
|
||||
After writing files, optionally use MCP tools for validation:
|
||||
|
||||
**test_node** - Validate node configuration with mock inputs
|
||||
```python
|
||||
mcp__agent-builder__test_node(
|
||||
node_id="search-web",
|
||||
test_input='{"query": "test query"}',
|
||||
mock_llm_response='{"results": "mock output"}'
|
||||
)
|
||||
```
|
||||
|
||||
**validate_graph** - Check graph structure
|
||||
```python
|
||||
mcp__agent-builder__validate_graph()
|
||||
# Returns: unreachable nodes, missing connections, etc.
|
||||
```
|
||||
|
||||
**create_session** - Track session state for bookkeeping
|
||||
```python
|
||||
mcp__agent-builder__create_session(session_name="my-build")
|
||||
```
|
||||
|
||||
**Key Point:** Files are written FIRST. MCP tools are for validation only.
|
||||
|
||||
## Related Skills
|
||||
|
||||
- **building-agents-construction** - Step-by-step building process
|
||||
- **building-agents-patterns** - Best practices and examples
|
||||
- **agent-workflow** - Complete workflow orchestrator
|
||||
- **testing-agent** - Test and validate completed agents
|
||||
@@ -1,497 +0,0 @@
|
||||
---
|
||||
name: building-agents-patterns
|
||||
description: Best practices, patterns, and examples for building goal-driven agents. Includes pause/resume architecture, hybrid workflows, anti-patterns, and handoff to testing. Use when optimizing agent design.
|
||||
license: Apache-2.0
|
||||
metadata:
|
||||
author: hive
|
||||
version: "1.0"
|
||||
type: reference
|
||||
part_of: building-agents
|
||||
---
|
||||
|
||||
# Building Agents - Patterns & Best Practices
|
||||
|
||||
Design patterns, examples, and best practices for building robust goal-driven agents.
|
||||
|
||||
**Prerequisites:** Complete agent structure using `building-agents-construction`.
|
||||
|
||||
## Practical Example: Hybrid Workflow
|
||||
|
||||
How to build a node using both direct file writes and optional MCP validation:
|
||||
|
||||
```python
|
||||
# 1. WRITE TO FILE FIRST (Primary - makes it visible)
|
||||
node_code = '''
|
||||
search_node = NodeSpec(
|
||||
id="search-web",
|
||||
node_type="llm_tool_use",
|
||||
input_keys=["query"],
|
||||
output_keys=["search_results"],
|
||||
system_prompt="Search the web for: {query}",
|
||||
tools=["web_search"],
|
||||
)
|
||||
'''
|
||||
|
||||
Edit(
|
||||
file_path="exports/research_agent/nodes/__init__.py",
|
||||
old_string="# Nodes will be added here",
|
||||
new_string=node_code
|
||||
)
|
||||
|
||||
print("✅ Added search_node to nodes/__init__.py")
|
||||
print("📁 Open exports/research_agent/nodes/__init__.py to see it!")
|
||||
|
||||
# 2. OPTIONALLY VALIDATE WITH MCP (Secondary - bookkeeping)
|
||||
validation = mcp__agent-builder__test_node(
|
||||
node_id="search-web",
|
||||
test_input='{"query": "python tutorials"}',
|
||||
mock_llm_response='{"search_results": [...mock results...]}'
|
||||
)
|
||||
|
||||
print(f"✓ Validation: {validation['success']}")
|
||||
```
|
||||
|
||||
**User experience:**
|
||||
|
||||
- Immediately sees node in their editor (from step 1)
|
||||
- Gets validation feedback (from step 2)
|
||||
- Can edit the file directly if needed
|
||||
|
||||
This combines visibility (files) with validation (MCP tools).
|
||||
|
||||
## Pause/Resume Architecture
|
||||
|
||||
For agents needing multi-turn conversations with user interaction:
|
||||
|
||||
### Basic Pause/Resume Flow
|
||||
|
||||
```python
|
||||
# Define pause nodes - execution stops at these nodes
|
||||
pause_nodes = ["request-clarification", "await-approval"]
|
||||
|
||||
# Define entry points - where to resume from each pause
|
||||
entry_points = {
|
||||
"start": "analyze-request", # Initial entry
|
||||
"request-clarification_resume": "process-clarification", # Resume from clarification
|
||||
"await-approval_resume": "execute-action", # Resume from approval
|
||||
}
|
||||
```
|
||||
|
||||
### Example: Multi-Turn Research Agent
|
||||
|
||||
```python
|
||||
# Nodes
|
||||
nodes = [
|
||||
NodeSpec(id="analyze-request", ...),
|
||||
NodeSpec(id="request-clarification", ...), # PAUSE NODE
|
||||
NodeSpec(id="process-clarification", ...),
|
||||
NodeSpec(id="generate-results", ...),
|
||||
NodeSpec(id="await-approval", ...), # PAUSE NODE
|
||||
NodeSpec(id="execute-action", ...),
|
||||
]
|
||||
|
||||
# Edges with resume flows
|
||||
edges = [
|
||||
EdgeSpec(
|
||||
id="analyze-to-clarify",
|
||||
source="analyze-request",
|
||||
target="request-clarification",
|
||||
condition=EdgeCondition.CONDITIONAL,
|
||||
condition_expr="needs_clarification == true",
|
||||
),
|
||||
# When resumed, goes to process-clarification
|
||||
EdgeSpec(
|
||||
id="clarify-to-process",
|
||||
source="request-clarification",
|
||||
target="process-clarification",
|
||||
condition=EdgeCondition.ALWAYS,
|
||||
),
|
||||
EdgeSpec(
|
||||
id="results-to-approval",
|
||||
source="generate-results",
|
||||
target="await-approval",
|
||||
condition=EdgeCondition.ALWAYS,
|
||||
),
|
||||
# When resumed, goes to execute-action
|
||||
EdgeSpec(
|
||||
id="approval-to-execute",
|
||||
source="await-approval",
|
||||
target="execute-action",
|
||||
condition=EdgeCondition.ALWAYS,
|
||||
),
|
||||
]
|
||||
|
||||
# Configuration
|
||||
pause_nodes = ["request-clarification", "await-approval"]
|
||||
entry_points = {
|
||||
"start": "analyze-request",
|
||||
"request-clarification_resume": "process-clarification",
|
||||
"await-approval_resume": "execute-action",
|
||||
}
|
||||
```
|
||||
|
||||
### Running Pause/Resume Agents
|
||||
|
||||
```python
|
||||
# Initial run - will pause at first pause node
|
||||
result1 = await agent.run(
|
||||
context={"query": "research topic"},
|
||||
session_state=None
|
||||
)
|
||||
|
||||
# Check if paused
|
||||
if result1.paused_at:
|
||||
print(f"Paused at: {result1.paused_at}")
|
||||
|
||||
# Resume with user input
|
||||
result2 = await agent.run(
|
||||
context={"user_response": "clarification details"},
|
||||
session_state=result1.session_state # Pass previous state
|
||||
)
|
||||
```
|
||||
|
||||
## Anti-Patterns
|
||||
|
||||
### What NOT to Do
|
||||
|
||||
❌ **Don't rely on `export_graph`** - Write files immediately, not at end
|
||||
```python
|
||||
# BAD: Building in session state, exporting at end
|
||||
mcp__agent-builder__add_node(...)
|
||||
mcp__agent-builder__add_node(...)
|
||||
mcp__agent-builder__export_graph() # Files appear only now
|
||||
|
||||
# GOOD: Writing files immediately
|
||||
Write(file_path="...", content=node_code) # File visible now
|
||||
Write(file_path="...", content=node_code) # File visible now
|
||||
```
|
||||
|
||||
❌ **Don't hide code in session** - Write to files as components approved
|
||||
```python
|
||||
# BAD: Accumulating changes invisibly
|
||||
session.add_component(component1)
|
||||
session.add_component(component2)
|
||||
# User can't see anything yet
|
||||
|
||||
# GOOD: Incremental visibility
|
||||
Edit(file_path="...", ...) # User sees change 1
|
||||
Edit(file_path="...", ...) # User sees change 2
|
||||
```
|
||||
|
||||
❌ **Don't wait to write files** - Agent visible from first step
|
||||
```python
|
||||
# BAD: Building everything before writing
|
||||
design_all_nodes()
|
||||
design_all_edges()
|
||||
write_everything_at_once()
|
||||
|
||||
# GOOD: Write as you go
|
||||
write_package_structure() # Visible
|
||||
write_goal() # Visible
|
||||
write_node_1() # Visible
|
||||
write_node_2() # Visible
|
||||
```
|
||||
|
||||
❌ **Don't batch everything** - Write incrementally
|
||||
```python
|
||||
# BAD: Batching all nodes
|
||||
nodes = [design_node_1(), design_node_2(), ...]
|
||||
write_all_nodes(nodes)
|
||||
|
||||
# GOOD: One at a time with user feedback
|
||||
write_node_1() # User approves
|
||||
write_node_2() # User approves
|
||||
write_node_3() # User approves
|
||||
```
|
||||
|
||||
### MCP Tools - Correct Usage
|
||||
|
||||
**MCP tools OK for:**
|
||||
✅ `test_node` - Validate node configuration with mock inputs
|
||||
✅ `validate_graph` - Check graph structure
|
||||
✅ `create_session` - Track session state for bookkeeping
|
||||
✅ Other validation tools
|
||||
|
||||
**Just don't:** Use MCP as the primary construction method or rely on export_graph
|
||||
|
||||
## Best Practices
|
||||
|
||||
### 1. Show Progress After Each Write
|
||||
|
||||
```python
|
||||
# After writing a node
|
||||
print("✅ Added analyze_request_node to nodes/__init__.py")
|
||||
print("📊 Progress: 1/6 nodes added")
|
||||
print("📁 Open exports/my_agent/nodes/__init__.py to see it!")
|
||||
```
|
||||
|
||||
### 2. Let User Open Files During Build
|
||||
|
||||
```python
|
||||
# Encourage file inspection
|
||||
print("✅ Goal written to agent.py")
|
||||
print("")
|
||||
print("💡 Tip: Open exports/my_agent/agent.py in your editor to see the goal!")
|
||||
```
|
||||
|
||||
### 3. Write Incrementally - One Component at a Time
|
||||
|
||||
```python
|
||||
# Good flow
|
||||
write_package_structure()
|
||||
show_user("Package created")
|
||||
|
||||
write_goal()
|
||||
show_user("Goal written")
|
||||
|
||||
for node in nodes:
|
||||
get_approval(node)
|
||||
write_node(node)
|
||||
show_user(f"Node {node.id} written")
|
||||
```
|
||||
|
||||
### 4. Test As You Build
|
||||
|
||||
```python
|
||||
# After adding several nodes
|
||||
print("💡 You can test current state with:")
|
||||
print(" PYTHONPATH=core:exports python -m my_agent validate")
|
||||
print(" PYTHONPATH=core:exports python -m my_agent info")
|
||||
```
|
||||
|
||||
### 5. Keep User Informed
|
||||
|
||||
```python
|
||||
# Clear status updates
|
||||
print("🔨 Creating package structure...")
|
||||
print("✅ Package created: exports/my_agent/")
|
||||
print("")
|
||||
print("📝 Next: Define agent goal")
|
||||
```
|
||||
|
||||
## Continuous Monitoring Agents
|
||||
|
||||
For agents that run continuously without terminal nodes:
|
||||
|
||||
```python
|
||||
# No terminal nodes - loops forever
|
||||
terminal_nodes = []
|
||||
|
||||
# Workflow loops back to start
|
||||
edges = [
|
||||
EdgeSpec(id="monitor-to-check", source="monitor", target="check-condition"),
|
||||
EdgeSpec(id="check-to-wait", source="check-condition", target="wait"),
|
||||
EdgeSpec(id="wait-to-monitor", source="wait", target="monitor"), # Loop
|
||||
]
|
||||
|
||||
# Entry node only
|
||||
entry_node = "monitor"
|
||||
entry_points = {"start": "monitor"}
|
||||
pause_nodes = []
|
||||
```
|
||||
|
||||
**Example: File Monitor**
|
||||
|
||||
```python
|
||||
nodes = [
|
||||
NodeSpec(id="list-files", ...),
|
||||
NodeSpec(id="check-new-files", node_type="router", ...),
|
||||
NodeSpec(id="process-files", ...),
|
||||
NodeSpec(id="wait-interval", node_type="function", ...),
|
||||
]
|
||||
|
||||
edges = [
|
||||
EdgeSpec(id="list-to-check", source="list-files", target="check-new-files"),
|
||||
EdgeSpec(
|
||||
id="check-to-process",
|
||||
source="check-new-files",
|
||||
target="process-files",
|
||||
condition=EdgeCondition.CONDITIONAL,
|
||||
condition_expr="new_files_count > 0",
|
||||
),
|
||||
EdgeSpec(
|
||||
id="check-to-wait",
|
||||
source="check-new-files",
|
||||
target="wait-interval",
|
||||
condition=EdgeCondition.CONDITIONAL,
|
||||
condition_expr="new_files_count == 0",
|
||||
),
|
||||
EdgeSpec(id="process-to-wait", source="process-files", target="wait-interval"),
|
||||
EdgeSpec(id="wait-to-list", source="wait-interval", target="list-files"), # Loop back
|
||||
]
|
||||
|
||||
terminal_nodes = [] # No terminal - runs forever
|
||||
```
|
||||
|
||||
## Complex Routing Patterns
|
||||
|
||||
### Multi-Condition Router
|
||||
|
||||
```python
|
||||
router_node = NodeSpec(
|
||||
id="decision-router",
|
||||
node_type="router",
|
||||
input_keys=["analysis_result"],
|
||||
output_keys=["decision"],
|
||||
system_prompt="""
|
||||
Based on the analysis result, decide the next action:
|
||||
- If confidence > 0.9: route to "execute"
|
||||
- If 0.5 <= confidence <= 0.9: route to "review"
|
||||
- If confidence < 0.5: route to "clarify"
|
||||
|
||||
Return: {"decision": "execute|review|clarify"}
|
||||
""",
|
||||
)
|
||||
|
||||
# Edges for each route
|
||||
edges = [
|
||||
EdgeSpec(
|
||||
id="router-to-execute",
|
||||
source="decision-router",
|
||||
target="execute-action",
|
||||
condition=EdgeCondition.CONDITIONAL,
|
||||
condition_expr="decision == 'execute'",
|
||||
priority=1,
|
||||
),
|
||||
EdgeSpec(
|
||||
id="router-to-review",
|
||||
source="decision-router",
|
||||
target="human-review",
|
||||
condition=EdgeCondition.CONDITIONAL,
|
||||
condition_expr="decision == 'review'",
|
||||
priority=2,
|
||||
),
|
||||
EdgeSpec(
|
||||
id="router-to-clarify",
|
||||
source="decision-router",
|
||||
target="request-clarification",
|
||||
condition=EdgeCondition.CONDITIONAL,
|
||||
condition_expr="decision == 'clarify'",
|
||||
priority=3,
|
||||
),
|
||||
]
|
||||
```
|
||||
|
||||
## Error Handling Patterns
|
||||
|
||||
### Graceful Failure with Fallback
|
||||
|
||||
```python
|
||||
# Primary node with error handling
|
||||
nodes = [
|
||||
NodeSpec(id="api-call", max_retries=3, ...),
|
||||
NodeSpec(id="fallback-cache", ...),
|
||||
NodeSpec(id="report-error", ...),
|
||||
]
|
||||
|
||||
edges = [
|
||||
# Success path
|
||||
EdgeSpec(
|
||||
id="api-success",
|
||||
source="api-call",
|
||||
target="process-results",
|
||||
condition=EdgeCondition.ON_SUCCESS,
|
||||
),
|
||||
# Fallback on failure
|
||||
EdgeSpec(
|
||||
id="api-to-fallback",
|
||||
source="api-call",
|
||||
target="fallback-cache",
|
||||
condition=EdgeCondition.ON_FAILURE,
|
||||
priority=1,
|
||||
),
|
||||
# Report if fallback also fails
|
||||
EdgeSpec(
|
||||
id="fallback-to-error",
|
||||
source="fallback-cache",
|
||||
target="report-error",
|
||||
condition=EdgeCondition.ON_FAILURE,
|
||||
priority=1,
|
||||
),
|
||||
]
|
||||
```
|
||||
|
||||
## Performance Optimization
|
||||
|
||||
### Parallel Node Execution
|
||||
|
||||
```python
|
||||
# Use multiple edges from same source for parallel execution
|
||||
edges = [
|
||||
EdgeSpec(
|
||||
id="start-to-search1",
|
||||
source="start",
|
||||
target="search-source-1",
|
||||
condition=EdgeCondition.ALWAYS,
|
||||
),
|
||||
EdgeSpec(
|
||||
id="start-to-search2",
|
||||
source="start",
|
||||
target="search-source-2",
|
||||
condition=EdgeCondition.ALWAYS,
|
||||
),
|
||||
EdgeSpec(
|
||||
id="start-to-search3",
|
||||
source="start",
|
||||
target="search-source-3",
|
||||
condition=EdgeCondition.ALWAYS,
|
||||
),
|
||||
# Converge results
|
||||
EdgeSpec(
|
||||
id="search1-to-merge",
|
||||
source="search-source-1",
|
||||
target="merge-results",
|
||||
),
|
||||
EdgeSpec(
|
||||
id="search2-to-merge",
|
||||
source="search-source-2",
|
||||
target="merge-results",
|
||||
),
|
||||
EdgeSpec(
|
||||
id="search3-to-merge",
|
||||
source="search-source-3",
|
||||
target="merge-results",
|
||||
),
|
||||
]
|
||||
```
|
||||
|
||||
## Handoff to Testing
|
||||
|
||||
When agent is complete, transition to testing phase:
|
||||
|
||||
```python
|
||||
print("""
|
||||
✅ Agent complete: exports/my_agent/
|
||||
|
||||
Next steps:
|
||||
1. Switch to testing-agent skill
|
||||
2. Generate and approve tests
|
||||
3. Run evaluation
|
||||
4. Debug any failures
|
||||
|
||||
Command: "Test the agent at exports/my_agent/"
|
||||
""")
|
||||
```
|
||||
|
||||
### Pre-Testing Checklist
|
||||
|
||||
Before handing off to testing-agent:
|
||||
|
||||
- [ ] Agent structure validates: `python -m agent_name validate`
|
||||
- [ ] All nodes defined in nodes/__init__.py
|
||||
- [ ] All edges connect valid nodes
|
||||
- [ ] Entry node specified
|
||||
- [ ] Agent can be imported: `from exports.agent_name import default_agent`
|
||||
- [ ] README.md with usage instructions
|
||||
- [ ] CLI commands work (info, validate)
|
||||
|
||||
## Related Skills
|
||||
|
||||
- **building-agents-core** - Fundamental concepts
|
||||
- **building-agents-construction** - Step-by-step building
|
||||
- **testing-agent** - Test and validate agents
|
||||
- **agent-workflow** - Complete workflow orchestrator
|
||||
|
||||
---
|
||||
|
||||
**Remember: Agent is actively constructed, visible the whole time. No hidden state. No surprise exports. Just transparent, incremental file building.**
|
||||
@@ -1,572 +0,0 @@
|
||||
---
|
||||
name: setup-credentials
|
||||
description: Set up and install credentials for an agent. Detects missing credentials from agent config, collects them from the user, and stores them securely in the encrypted credential store at ~/.hive/credentials.
|
||||
license: Apache-2.0
|
||||
metadata:
|
||||
author: hive
|
||||
version: "2.1"
|
||||
type: utility
|
||||
---
|
||||
|
||||
# Setup Credentials
|
||||
|
||||
Interactive credential setup for agents with multiple authentication options. Detects what's missing, offers auth method choices, validates with health checks, and stores credentials securely.
|
||||
|
||||
## When to Use
|
||||
|
||||
- Before running or testing an agent for the first time
|
||||
- When `AgentRunner.run()` fails with "missing required credentials"
|
||||
- When a user asks to configure credentials for an agent
|
||||
- After building a new agent that uses tools requiring API keys
|
||||
|
||||
## Workflow
|
||||
|
||||
### Step 1: Identify the Agent
|
||||
|
||||
Determine which agent needs credentials. The user will either:
|
||||
|
||||
- Name the agent directly (e.g., "set up credentials for hubspot-agent")
|
||||
- Have an agent directory open (check `exports/` for agent dirs)
|
||||
- Be working on an agent in the current session
|
||||
|
||||
Locate the agent's directory under `exports/{agent_name}/`.
|
||||
|
||||
### Step 2: Detect Required Credentials
|
||||
|
||||
Read the agent's configuration to determine which tools and node types it uses:
|
||||
|
||||
```python
|
||||
from core.framework.runner import AgentRunner
|
||||
|
||||
runner = AgentRunner.load("exports/{agent_name}")
|
||||
validation = runner.validate()
|
||||
|
||||
# validation.missing_credentials contains env var names
|
||||
# validation.warnings contains detailed messages with help URLs
|
||||
```
|
||||
|
||||
Alternatively, check the credential store directly:
|
||||
|
||||
```python
|
||||
from core.framework.credentials import CredentialStore
|
||||
|
||||
# Use encrypted storage (default: ~/.hive/credentials)
|
||||
store = CredentialStore.with_encrypted_storage()
|
||||
|
||||
# Check what's available
|
||||
available = store.list_credentials()
|
||||
print(f"Available credentials: {available}")
|
||||
|
||||
# Check if specific credential exists
|
||||
if store.is_available("hubspot"):
|
||||
print("HubSpot credential found")
|
||||
else:
|
||||
print("HubSpot credential missing")
|
||||
```
|
||||
|
||||
To see all known credential specs (for help URLs and setup instructions):
|
||||
|
||||
```python
|
||||
from aden_tools.credentials import CREDENTIAL_SPECS
|
||||
|
||||
for name, spec in CREDENTIAL_SPECS.items():
|
||||
print(f"{name}: env_var={spec.env_var}, aden={spec.aden_supported}")
|
||||
```
|
||||
|
||||
### Step 3: Present Auth Options for Each Missing Credential
|
||||
|
||||
For each missing credential, check what authentication methods are available:
|
||||
|
||||
```python
|
||||
from aden_tools.credentials import CREDENTIAL_SPECS
|
||||
|
||||
spec = CREDENTIAL_SPECS.get("hubspot")
|
||||
if spec:
|
||||
# Determine available auth options
|
||||
auth_options = []
|
||||
if spec.aden_supported:
|
||||
auth_options.append("aden")
|
||||
if spec.direct_api_key_supported:
|
||||
auth_options.append("direct")
|
||||
auth_options.append("custom") # Always available
|
||||
|
||||
# Get setup info
|
||||
setup_info = {
|
||||
"env_var": spec.env_var,
|
||||
"description": spec.description,
|
||||
"help_url": spec.help_url,
|
||||
"api_key_instructions": spec.api_key_instructions,
|
||||
}
|
||||
```
|
||||
|
||||
Present the available options using AskUserQuestion:
|
||||
|
||||
```
|
||||
Choose how to configure HUBSPOT_ACCESS_TOKEN:
|
||||
|
||||
1) Aden Authorization Server (Recommended)
|
||||
Secure OAuth2 flow via integration.adenhq.com
|
||||
- Quick setup with automatic token refresh
|
||||
- No need to manage API keys manually
|
||||
|
||||
2) Direct API Key
|
||||
Enter your own API key manually
|
||||
- Requires creating a HubSpot Private App
|
||||
- Full control over scopes and permissions
|
||||
|
||||
3) Custom Credential Store (Advanced)
|
||||
Programmatic configuration for CI/CD
|
||||
- For automated deployments
|
||||
- Requires manual API calls
|
||||
```
|
||||
|
||||
### Step 4: Execute Auth Flow Based on User Choice
|
||||
|
||||
#### Option 1: Aden Authorization Server
|
||||
|
||||
This is the recommended flow for supported integrations (HubSpot, etc.).
|
||||
|
||||
**How Aden OAuth Works:**
|
||||
|
||||
The ADEN_API_KEY represents a user who has already completed OAuth authorization on Aden's platform. When users sign up and connect integrations on Aden, those OAuth tokens are stored server-side. Having an ADEN_API_KEY means:
|
||||
|
||||
1. User has an Aden account
|
||||
2. User has already authorized integrations (HubSpot, etc.) via OAuth on Aden
|
||||
3. We just need to sync those credentials down to the local credential store
|
||||
|
||||
**4.1a. Check for ADEN_API_KEY**
|
||||
|
||||
```python
|
||||
import os
|
||||
aden_key = os.environ.get("ADEN_API_KEY")
|
||||
```
|
||||
|
||||
If not set, guide user to get one from Aden (this is where they do OAuth):
|
||||
|
||||
```python
|
||||
from aden_tools.credentials import open_browser, get_aden_setup_url
|
||||
|
||||
# Open browser to Aden - user will sign up and connect integrations there
|
||||
url = get_aden_setup_url() # https://integration.adenhq.com/setup
|
||||
success, msg = open_browser(url)
|
||||
|
||||
print("Please sign in to Aden and connect your integrations (HubSpot, etc.).")
|
||||
print("Once done, copy your API key and return here.")
|
||||
```
|
||||
|
||||
Ask user to provide the ADEN_API_KEY they received.
|
||||
|
||||
**4.1b. Save ADEN_API_KEY to Shell Config**
|
||||
|
||||
With user approval, persist ADEN_API_KEY to their shell config:
|
||||
|
||||
```python
|
||||
from aden_tools.credentials import (
|
||||
detect_shell,
|
||||
add_env_var_to_shell_config,
|
||||
get_shell_source_command,
|
||||
)
|
||||
|
||||
shell_type = detect_shell() # 'bash', 'zsh', or 'unknown'
|
||||
|
||||
# Ask user for approval before modifying shell config
|
||||
# If approved:
|
||||
success, config_path = add_env_var_to_shell_config(
|
||||
"ADEN_API_KEY",
|
||||
user_provided_key,
|
||||
comment="Aden authorization server API key"
|
||||
)
|
||||
|
||||
if success:
|
||||
source_cmd = get_shell_source_command()
|
||||
print(f"Saved to {config_path}")
|
||||
print(f"Run: {source_cmd}")
|
||||
```
|
||||
|
||||
Also save to `~/.hive/configuration.json` for the framework:
|
||||
|
||||
```python
|
||||
import json
|
||||
from pathlib import Path
|
||||
|
||||
config_path = Path.home() / ".hive" / "configuration.json"
|
||||
config = json.loads(config_path.read_text()) if config_path.exists() else {}
|
||||
|
||||
config["aden"] = {
|
||||
"api_key_configured": True,
|
||||
"api_url": "https://api.adenhq.com"
|
||||
}
|
||||
|
||||
config_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
config_path.write_text(json.dumps(config, indent=2))
|
||||
```
|
||||
|
||||
**4.1c. Sync Credentials from Aden Server**
|
||||
|
||||
Since the user has already authorized integrations on Aden, use the one-liner factory method:
|
||||
|
||||
```python
|
||||
from core.framework.credentials import CredentialStore
|
||||
|
||||
# This single call handles everything:
|
||||
# - Creates encrypted local storage at ~/.hive/credentials
|
||||
# - Configures Aden client from ADEN_API_KEY env var
|
||||
# - Syncs all credentials from Aden server automatically
|
||||
store = CredentialStore.with_aden_sync(
|
||||
base_url="https://api.adenhq.com",
|
||||
auto_sync=True, # Syncs on creation
|
||||
)
|
||||
|
||||
# Check what was synced
|
||||
synced = store.list_credentials()
|
||||
print(f"Synced credentials: {synced}")
|
||||
|
||||
# If the required credential wasn't synced, the user hasn't authorized it on Aden yet
|
||||
if "hubspot" not in synced:
|
||||
print("HubSpot not found in your Aden account.")
|
||||
print("Please visit https://integration.adenhq.com to connect HubSpot, then try again.")
|
||||
```
|
||||
|
||||
For more control over the sync process:
|
||||
|
||||
```python
|
||||
from core.framework.credentials import CredentialStore
|
||||
from core.framework.credentials.aden import (
|
||||
AdenCredentialClient,
|
||||
AdenClientConfig,
|
||||
AdenSyncProvider,
|
||||
)
|
||||
|
||||
# Create client (API key loaded from ADEN_API_KEY env var)
|
||||
client = AdenCredentialClient(AdenClientConfig(
|
||||
base_url="https://api.adenhq.com",
|
||||
))
|
||||
|
||||
# Create provider and store
|
||||
provider = AdenSyncProvider(client=client)
|
||||
store = CredentialStore.with_encrypted_storage()
|
||||
|
||||
# Manual sync
|
||||
synced_count = provider.sync_all(store)
|
||||
print(f"Synced {synced_count} credentials from Aden")
|
||||
```
|
||||
|
||||
**4.1d. Run Health Check**
|
||||
|
||||
```python
|
||||
from aden_tools.credentials import check_credential_health
|
||||
|
||||
# Get the token from the store
|
||||
cred = store.get_credential("hubspot")
|
||||
token = cred.keys["access_token"].value.get_secret_value()
|
||||
|
||||
result = check_credential_health("hubspot", token)
|
||||
if result.valid:
|
||||
print("HubSpot credentials validated successfully!")
|
||||
else:
|
||||
print(f"Validation failed: {result.message}")
|
||||
# Offer to retry the OAuth flow
|
||||
```
|
||||
|
||||
#### Option 2: Direct API Key
|
||||
|
||||
For users who prefer manual API key management.
|
||||
|
||||
**4.2a. Show Setup Instructions**
|
||||
|
||||
```python
|
||||
from aden_tools.credentials import CREDENTIAL_SPECS
|
||||
|
||||
spec = CREDENTIAL_SPECS.get("hubspot")
|
||||
if spec and spec.api_key_instructions:
|
||||
print(spec.api_key_instructions)
|
||||
# Output:
|
||||
# To get a HubSpot Private App token:
|
||||
# 1. Go to HubSpot Settings > Integrations > Private Apps
|
||||
# 2. Click "Create a private app"
|
||||
# 3. Name your app (e.g., "Hive Agent")
|
||||
# ...
|
||||
|
||||
if spec and spec.help_url:
|
||||
print(f"More info: {spec.help_url}")
|
||||
```
|
||||
|
||||
**4.2b. Collect API Key from User**
|
||||
|
||||
Use AskUserQuestion to securely collect the API key:
|
||||
|
||||
```
|
||||
Please provide your HubSpot access token:
|
||||
(This will be stored securely in ~/.hive/credentials)
|
||||
```
|
||||
|
||||
**4.2c. Run Health Check Before Storing**
|
||||
|
||||
```python
|
||||
from aden_tools.credentials import check_credential_health
|
||||
|
||||
result = check_credential_health("hubspot", user_provided_token)
|
||||
if not result.valid:
|
||||
print(f"Warning: {result.message}")
|
||||
# Ask user if they want to:
|
||||
# 1. Try a different token
|
||||
# 2. Continue anyway (not recommended)
|
||||
```
|
||||
|
||||
**4.2d. Store in Encrypted Credential Store**
|
||||
|
||||
```python
|
||||
from core.framework.credentials import CredentialStore, CredentialObject, CredentialKey
|
||||
from pydantic import SecretStr
|
||||
|
||||
store = CredentialStore.with_encrypted_storage()
|
||||
|
||||
cred = CredentialObject(
|
||||
id="hubspot",
|
||||
name="HubSpot Access Token",
|
||||
keys={
|
||||
"access_token": CredentialKey(
|
||||
name="access_token",
|
||||
value=SecretStr(user_provided_token),
|
||||
)
|
||||
},
|
||||
)
|
||||
store.save_credential(cred)
|
||||
```
|
||||
|
||||
**4.2e. Export to Current Session**
|
||||
|
||||
```bash
|
||||
export HUBSPOT_ACCESS_TOKEN="the-value"
|
||||
```
|
||||
|
||||
#### Option 3: Custom Credential Store (Advanced)
|
||||
|
||||
For programmatic/CI/CD setups.
|
||||
|
||||
**4.3a. Show Documentation**
|
||||
|
||||
```
|
||||
For advanced credential management, you can use the CredentialStore API directly:
|
||||
|
||||
from core.framework.credentials import CredentialStore, CredentialObject, CredentialKey
|
||||
from pydantic import SecretStr
|
||||
|
||||
store = CredentialStore.with_encrypted_storage()
|
||||
|
||||
cred = CredentialObject(
|
||||
id="hubspot",
|
||||
name="HubSpot Access Token",
|
||||
keys={"access_token": CredentialKey(name="access_token", value=SecretStr("..."))}
|
||||
)
|
||||
store.save_credential(cred)
|
||||
|
||||
For CI/CD environments:
|
||||
- Set HIVE_CREDENTIAL_KEY for encryption
|
||||
- Pre-populate ~/.hive/credentials programmatically
|
||||
- Or use environment variables directly (HUBSPOT_ACCESS_TOKEN)
|
||||
|
||||
Documentation: See core/framework/credentials/README.md
|
||||
```
|
||||
|
||||
### Step 5: Record Configuration Method
|
||||
|
||||
Track which auth method was used for each credential in `~/.hive/configuration.json`:
|
||||
|
||||
```python
|
||||
import json
|
||||
from pathlib import Path
|
||||
from datetime import datetime
|
||||
|
||||
config_path = Path.home() / ".hive" / "configuration.json"
|
||||
config = json.loads(config_path.read_text()) if config_path.exists() else {}
|
||||
|
||||
if "credential_methods" not in config:
|
||||
config["credential_methods"] = {}
|
||||
|
||||
config["credential_methods"]["hubspot"] = {
|
||||
"method": "aden", # or "direct" or "custom"
|
||||
"configured_at": datetime.now().isoformat(),
|
||||
}
|
||||
|
||||
config_path.write_text(json.dumps(config, indent=2))
|
||||
```
|
||||
|
||||
### Step 6: Verify All Credentials
|
||||
|
||||
Run validation again to confirm everything is set:
|
||||
|
||||
```python
|
||||
runner = AgentRunner.load("exports/{agent_name}")
|
||||
validation = runner.validate()
|
||||
assert not validation.missing_credentials, "Still missing credentials!"
|
||||
```
|
||||
|
||||
Report the result to the user.
|
||||
|
||||
## Health Check Reference
|
||||
|
||||
Health checks validate credentials by making lightweight API calls:
|
||||
|
||||
| Credential | Endpoint | What It Checks |
|
||||
| -------------- | --------------------------------------- | --------------------------------- |
|
||||
| `hubspot` | `GET /crm/v3/objects/contacts?limit=1` | Bearer token validity, CRM scopes |
|
||||
| `brave_search` | `GET /res/v1/web/search?q=test&count=1` | API key validity |
|
||||
|
||||
```python
|
||||
from aden_tools.credentials import check_credential_health, HealthCheckResult
|
||||
|
||||
result: HealthCheckResult = check_credential_health("hubspot", token_value)
|
||||
# result.valid: bool
|
||||
# result.message: str
|
||||
# result.details: dict (status_code, rate_limited, etc.)
|
||||
```
|
||||
|
||||
## Encryption Key (HIVE_CREDENTIAL_KEY)
|
||||
|
||||
The encrypted credential store requires `HIVE_CREDENTIAL_KEY` to encrypt/decrypt credentials.
|
||||
|
||||
- If the user doesn't have one, `EncryptedFileStorage` will auto-generate one and log it
|
||||
- The user MUST persist this key (e.g., in `~/.bashrc` or a secrets manager)
|
||||
- Without this key, stored credentials cannot be decrypted
|
||||
- This is the ONLY secret that should live in `~/.bashrc` or environment config
|
||||
|
||||
If `HIVE_CREDENTIAL_KEY` is not set:
|
||||
|
||||
1. Let the store generate one
|
||||
2. Tell the user to save it: `export HIVE_CREDENTIAL_KEY="{generated_key}"`
|
||||
3. Recommend adding it to `~/.bashrc` or their shell profile
|
||||
|
||||
## Security Rules
|
||||
|
||||
- **NEVER** log, print, or echo credential values in tool output
|
||||
- **NEVER** store credentials in plaintext files, git-tracked files, or agent configs
|
||||
- **NEVER** hardcode credentials in source code
|
||||
- **ALWAYS** use `SecretStr` from Pydantic when handling credential values in Python
|
||||
- **ALWAYS** use the encrypted credential store (`~/.hive/credentials`) for persistence
|
||||
- **ALWAYS** run health checks before storing credentials (when possible)
|
||||
- **ALWAYS** verify credentials were stored by re-running validation, not by reading them back
|
||||
- When modifying `~/.bashrc` or `~/.zshrc`, confirm with the user first
|
||||
|
||||
## Credential Sources Reference
|
||||
|
||||
All credential specs are defined in `tools/src/aden_tools/credentials/`:
|
||||
|
||||
| File | Category | Credentials | Aden Supported |
|
||||
| ----------------- | ------------- | --------------------------------------------- | -------------- |
|
||||
| `llm.py` | LLM Providers | `anthropic` | No |
|
||||
| `search.py` | Search Tools | `brave_search`, `google_search`, `google_cse` | No |
|
||||
| `integrations.py` | Integrations | `hubspot` | Yes |
|
||||
|
||||
**Note:** Additional LLM providers (Cerebras, Groq, OpenAI) are handled by LiteLLM via environment
|
||||
variables (`CEREBRAS_API_KEY`, `GROQ_API_KEY`, `OPENAI_API_KEY`) but are not yet in CREDENTIAL_SPECS.
|
||||
Add them to `llm.py` as needed.
|
||||
|
||||
To check what's registered:
|
||||
|
||||
```python
|
||||
from aden_tools.credentials import CREDENTIAL_SPECS
|
||||
for name, spec in CREDENTIAL_SPECS.items():
|
||||
print(f"{name}: aden={spec.aden_supported}, direct={spec.direct_api_key_supported}")
|
||||
```
|
||||
|
||||
## Migration: CredentialManager → CredentialStore
|
||||
|
||||
**CredentialManager is deprecated.** Use CredentialStore instead.
|
||||
|
||||
| Old (Deprecated) | New (Recommended) |
|
||||
| ----------------------------------------- | -------------------------------------------------------------------- |
|
||||
| `CredentialManager()` | `CredentialStore.with_encrypted_storage()` |
|
||||
| `creds.get("hubspot")` | `store.get("hubspot")` or `store.get_key("hubspot", "access_token")` |
|
||||
| `creds.validate_for_tools(tools)` | Use `store.is_available(cred_id)` per credential |
|
||||
| `creds.get_auth_options("hubspot")` | Check `CREDENTIAL_SPECS["hubspot"].aden_supported` |
|
||||
| `creds.get_setup_instructions("hubspot")` | Access `CREDENTIAL_SPECS["hubspot"]` directly |
|
||||
|
||||
**Why migrate?**
|
||||
|
||||
- **CredentialStore** supports encrypted storage, multi-key credentials, template resolution, and automatic token refresh
|
||||
- **CredentialManager** only reads from environment variables and .env files (no encryption, no refresh)
|
||||
- **CredentialStoreAdapter** exists for backward compatibility during migration
|
||||
|
||||
```python
|
||||
# Old way (deprecated)
|
||||
from aden_tools.credentials import CredentialManager
|
||||
creds = CredentialManager()
|
||||
token = creds.get("hubspot")
|
||||
|
||||
# New way (recommended)
|
||||
from core.framework.credentials import CredentialStore
|
||||
store = CredentialStore.with_encrypted_storage()
|
||||
token = store.get("hubspot")
|
||||
|
||||
# With Aden sync (recommended for OAuth integrations)
|
||||
store = CredentialStore.with_aden_sync()
|
||||
token = store.get_key("hubspot", "access_token")
|
||||
```
|
||||
|
||||
## Example Session
|
||||
|
||||
```
|
||||
User: /setup-credentials for my hubspot-agent
|
||||
|
||||
Agent: Let me check what credentials your hubspot-agent needs.
|
||||
|
||||
[Runs validation, finds ANTHROPIC_API_KEY and HUBSPOT_ACCESS_TOKEN missing]
|
||||
|
||||
Agent: Your hubspot-agent requires 2 credentials:
|
||||
|
||||
1. ANTHROPIC_API_KEY - Anthropic API key for LLM calls
|
||||
2. HUBSPOT_ACCESS_TOKEN - HubSpot access token
|
||||
|
||||
Let's set these up one at a time.
|
||||
|
||||
--- Setting up ANTHROPIC_API_KEY ---
|
||||
|
||||
This credential only supports direct API key entry.
|
||||
|
||||
[Shows instructions for getting Anthropic API key]
|
||||
[AskUserQuestion: "Please provide your Anthropic API key:"]
|
||||
[User provides key]
|
||||
[Stores in credential store, exports to env]
|
||||
|
||||
--- Setting up HUBSPOT_ACCESS_TOKEN ---
|
||||
|
||||
[AskUserQuestion with 3 options]
|
||||
|
||||
Choose how to configure HUBSPOT_ACCESS_TOKEN:
|
||||
1) Aden Authorization Server (Recommended)
|
||||
2) Direct API Key
|
||||
3) Custom Credential Store (Advanced)
|
||||
|
||||
User: 1 (Aden)
|
||||
|
||||
Agent: Great! Let me check if you have an Aden API key configured...
|
||||
|
||||
[Checks for ADEN_API_KEY, not found]
|
||||
[Opens browser to integration.adenhq.com/setup]
|
||||
|
||||
Agent: I've opened Aden's setup page. Please:
|
||||
1. Sign in or create an account
|
||||
2. Connect your HubSpot account (OAuth happens on Aden's site)
|
||||
3. Copy the API key shown after setup
|
||||
|
||||
[AskUserQuestion: "Please provide your Aden API key:"]
|
||||
[User provides key]
|
||||
|
||||
Agent: Would you like me to save this to your shell config (~/.zshrc) for future sessions?
|
||||
|
||||
[User approves]
|
||||
[Saves to ~/.zshrc and ~/.hive/configuration.json]
|
||||
|
||||
Agent: Let me sync your credentials from Aden...
|
||||
|
||||
[Syncs credentials from Aden server - OAuth already done on Aden's side]
|
||||
[Runs health check]
|
||||
|
||||
Agent: HubSpot credentials validated successfully!
|
||||
|
||||
All credentials are now configured:
|
||||
- ANTHROPIC_API_KEY: Stored in encrypted credential store
|
||||
- HUBSPOT_ACCESS_TOKEN: Synced from Aden (OAuth completed on Aden)
|
||||
- Validation passed - your agent is ready to run!
|
||||
```
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,351 +0,0 @@
|
||||
# Example: Testing a YouTube Research Agent
|
||||
|
||||
This example walks through testing a YouTube research agent that finds relevant videos based on a topic.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Agent built with building-agents skill at `exports/youtube-research/`
|
||||
- Goal defined with success criteria and constraints
|
||||
|
||||
## Step 1: Load the Goal
|
||||
|
||||
First, load the goal that was defined during the Goal stage:
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "youtube-research",
|
||||
"name": "YouTube Research Agent",
|
||||
"description": "Find relevant YouTube videos on a given topic",
|
||||
"success_criteria": [
|
||||
{
|
||||
"id": "find_videos",
|
||||
"description": "Find 3-5 relevant videos",
|
||||
"metric": "video_count",
|
||||
"target": "3-5",
|
||||
"weight": 1.0
|
||||
},
|
||||
{
|
||||
"id": "relevance",
|
||||
"description": "Videos must be relevant to the topic",
|
||||
"metric": "relevance_score",
|
||||
"target": ">0.8",
|
||||
"weight": 0.8
|
||||
}
|
||||
],
|
||||
"constraints": [
|
||||
{
|
||||
"id": "api_limits",
|
||||
"description": "Must not exceed YouTube API rate limits",
|
||||
"constraint_type": "hard",
|
||||
"category": "technical"
|
||||
},
|
||||
{
|
||||
"id": "content_safety",
|
||||
"description": "Must filter out inappropriate content",
|
||||
"constraint_type": "hard",
|
||||
"category": "safety"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## Step 2: Get Constraint Test Guidelines
|
||||
|
||||
During the Goal stage (or early Eval), get test guidelines for constraints:
|
||||
|
||||
```python
|
||||
result = generate_constraint_tests(
|
||||
goal_id="youtube-research",
|
||||
goal_json='<goal JSON above>',
|
||||
agent_path="exports/youtube-research"
|
||||
)
|
||||
```
|
||||
|
||||
**The result contains guidelines (not generated tests):**
|
||||
- `output_file`: Where to write tests
|
||||
- `file_header`: Imports and fixtures to use
|
||||
- `test_template`: Format for test functions
|
||||
- `constraints_formatted`: The constraints to test
|
||||
- `test_guidelines`: Rules for writing tests
|
||||
|
||||
## Step 3: Write Constraint Tests
|
||||
|
||||
Using the guidelines, write tests directly with the Write tool:
|
||||
|
||||
```python
|
||||
# Write constraint tests using the provided file_header and guidelines
|
||||
Write(
|
||||
file_path="exports/youtube-research/tests/test_constraints.py",
|
||||
content='''
|
||||
"""Constraint tests for youtube-research agent."""
|
||||
|
||||
import os
|
||||
import pytest
|
||||
from exports.youtube_research import default_agent
|
||||
|
||||
|
||||
pytestmark = pytest.mark.skipif(
|
||||
not os.environ.get("ANTHROPIC_API_KEY") and not os.environ.get("MOCK_MODE"),
|
||||
reason="API key required for real testing."
|
||||
)
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_constraint_api_limits_respected():
|
||||
"""Verify API rate limits are not exceeded."""
|
||||
import time
|
||||
mock_mode = bool(os.environ.get("MOCK_MODE"))
|
||||
|
||||
for i in range(10):
|
||||
result = await default_agent.run({"topic": f"test_{i}"}, mock_mode=mock_mode)
|
||||
time.sleep(0.1)
|
||||
|
||||
# Should complete without rate limit errors
|
||||
assert "rate limit" not in str(result).lower()
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_constraint_content_safety_filter():
|
||||
"""Verify inappropriate content is filtered."""
|
||||
mock_mode = bool(os.environ.get("MOCK_MODE"))
|
||||
result = await default_agent.run({"topic": "general topic"}, mock_mode=mock_mode)
|
||||
|
||||
for video in result.videos:
|
||||
assert video.safe_for_work is True
|
||||
assert video.age_restricted is False
|
||||
'''
|
||||
)
|
||||
```
|
||||
|
||||
## Step 4: Get Success Criteria Test Guidelines
|
||||
|
||||
After the agent is built, get success criteria test guidelines:
|
||||
|
||||
```python
|
||||
result = generate_success_tests(
|
||||
goal_id="youtube-research",
|
||||
goal_json='<goal JSON>',
|
||||
node_names="search_node,filter_node,rank_node,format_node",
|
||||
tool_names="youtube_search,video_details,channel_info",
|
||||
agent_path="exports/youtube-research"
|
||||
)
|
||||
```
|
||||
|
||||
## Step 5: Write Success Criteria Tests
|
||||
|
||||
Using the guidelines, write success criteria tests:
|
||||
|
||||
```python
|
||||
Write(
|
||||
file_path="exports/youtube-research/tests/test_success_criteria.py",
|
||||
content='''
|
||||
"""Success criteria tests for youtube-research agent."""
|
||||
|
||||
import os
|
||||
import pytest
|
||||
from exports.youtube_research import default_agent
|
||||
|
||||
|
||||
pytestmark = pytest.mark.skipif(
|
||||
not os.environ.get("ANTHROPIC_API_KEY") and not os.environ.get("MOCK_MODE"),
|
||||
reason="API key required for real testing."
|
||||
)
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_find_videos_happy_path():
|
||||
"""Test finding videos for a common topic."""
|
||||
mock_mode = bool(os.environ.get("MOCK_MODE"))
|
||||
result = await default_agent.run({"topic": "machine learning"}, mock_mode=mock_mode)
|
||||
|
||||
assert result.success
|
||||
assert 3 <= len(result.videos) <= 5
|
||||
assert all(v.title for v in result.videos)
|
||||
assert all(v.video_id for v in result.videos)
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_find_videos_minimum_boundary():
|
||||
"""Test at minimum threshold (3 videos)."""
|
||||
mock_mode = bool(os.environ.get("MOCK_MODE"))
|
||||
result = await default_agent.run({"topic": "niche topic xyz"}, mock_mode=mock_mode)
|
||||
|
||||
assert len(result.videos) >= 3
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_relevance_score_threshold():
|
||||
"""Test relevance scoring meets threshold."""
|
||||
mock_mode = bool(os.environ.get("MOCK_MODE"))
|
||||
result = await default_agent.run({"topic": "python programming"}, mock_mode=mock_mode)
|
||||
|
||||
for video in result.videos:
|
||||
assert video.relevance_score > 0.8
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_find_videos_no_results_graceful():
|
||||
"""Test graceful handling of no results."""
|
||||
mock_mode = bool(os.environ.get("MOCK_MODE"))
|
||||
result = await default_agent.run({"topic": "xyznonexistent123"}, mock_mode=mock_mode)
|
||||
|
||||
# Should not crash, return empty or message
|
||||
assert result.videos == [] or result.message
|
||||
'''
|
||||
)
|
||||
```
|
||||
|
||||
## Step 6: Run All Tests
|
||||
|
||||
Execute all tests:
|
||||
|
||||
```python
|
||||
result = run_tests(
|
||||
goal_id="youtube-research",
|
||||
agent_path="exports/youtube-research",
|
||||
test_types='["all"]',
|
||||
parallel=4
|
||||
)
|
||||
```
|
||||
|
||||
**Results:**
|
||||
|
||||
```json
|
||||
{
|
||||
"goal_id": "youtube-research",
|
||||
"overall_passed": false,
|
||||
"summary": {
|
||||
"total": 6,
|
||||
"passed": 5,
|
||||
"failed": 1,
|
||||
"pass_rate": "83.3%"
|
||||
},
|
||||
"duration_ms": 4521,
|
||||
"results": [
|
||||
{"test_id": "test_constraint_api_001", "passed": true, "duration_ms": 1234},
|
||||
{"test_id": "test_constraint_content_001", "passed": true, "duration_ms": 456},
|
||||
{"test_id": "test_success_001", "passed": true, "duration_ms": 789},
|
||||
{"test_id": "test_success_002", "passed": true, "duration_ms": 654},
|
||||
{"test_id": "test_success_003", "passed": true, "duration_ms": 543},
|
||||
{"test_id": "test_success_004", "passed": false, "duration_ms": 845,
|
||||
"error_category": "IMPLEMENTATION_ERROR",
|
||||
"error_message": "TypeError: 'NoneType' object has no attribute 'videos'"}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## Step 7: Debug the Failed Test
|
||||
|
||||
```python
|
||||
result = debug_test(
|
||||
goal_id="youtube-research",
|
||||
test_name="test_find_videos_no_results_graceful",
|
||||
agent_path="exports/youtube-research"
|
||||
)
|
||||
```
|
||||
|
||||
**Debug Output:**
|
||||
|
||||
```json
|
||||
{
|
||||
"test_id": "test_success_004",
|
||||
"test_name": "test_find_videos_no_results_graceful",
|
||||
"input": {"topic": "xyznonexistent123"},
|
||||
"expected": "Empty list or message",
|
||||
"actual": {"error": "TypeError: 'NoneType' object has no attribute 'videos'"},
|
||||
"passed": false,
|
||||
"error_message": "TypeError: 'NoneType' object has no attribute 'videos'",
|
||||
"error_category": "IMPLEMENTATION_ERROR",
|
||||
"stack_trace": "Traceback (most recent call last):\n File \"filter_node.py\", line 42\n for video in result.videos:\nTypeError: 'NoneType' object has no attribute 'videos'",
|
||||
"logs": [
|
||||
{"timestamp": "2026-01-20T10:00:01", "node": "search_node", "level": "INFO", "msg": "Searching for: xyznonexistent123"},
|
||||
{"timestamp": "2026-01-20T10:00:02", "node": "search_node", "level": "WARNING", "msg": "No results found"},
|
||||
{"timestamp": "2026-01-20T10:00:02", "node": "filter_node", "level": "ERROR", "msg": "NoneType error"}
|
||||
],
|
||||
"runtime_data": {
|
||||
"execution_path": ["start", "search_node", "filter_node"],
|
||||
"node_outputs": {
|
||||
"search_node": null
|
||||
}
|
||||
},
|
||||
"suggested_fix": "Add null check in filter_node before accessing .videos attribute",
|
||||
"iteration_guidance": {
|
||||
"stage": "Agent",
|
||||
"action": "Fix the code in nodes/edges",
|
||||
"restart_required": false,
|
||||
"description": "The goal is correct, but filter_node doesn't handle null results from search_node."
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Step 8: Iterate Based on Category
|
||||
|
||||
Since this is an **IMPLEMENTATION_ERROR**, we:
|
||||
|
||||
1. **Don't restart** the Goal → Agent → Eval flow
|
||||
2. **Fix the agent** using building-agents skill:
|
||||
- Modify `filter_node` to handle null results
|
||||
3. **Re-run Eval** (tests only)
|
||||
|
||||
### Fix in building-agents:
|
||||
|
||||
```python
|
||||
# Update the filter_node to handle null
|
||||
add_node(
|
||||
node_id="filter_node",
|
||||
name="Filter Node",
|
||||
description="Filter and rank videos",
|
||||
node_type="function",
|
||||
input_keys=["search_results"],
|
||||
output_keys=["filtered_videos"],
|
||||
system_prompt="""
|
||||
Filter videos by relevance.
|
||||
IMPORTANT: Handle case where search_results is None or empty.
|
||||
Return empty list if no results.
|
||||
"""
|
||||
)
|
||||
```
|
||||
|
||||
### Re-export and re-test:
|
||||
|
||||
```python
|
||||
# Re-export the fixed agent
|
||||
export_graph(path="exports/youtube-research")
|
||||
|
||||
# Re-run tests
|
||||
result = run_tests(
|
||||
goal_id="youtube-research",
|
||||
agent_path="exports/youtube-research",
|
||||
test_types='["all"]'
|
||||
)
|
||||
```
|
||||
|
||||
**Updated Results:**
|
||||
|
||||
```json
|
||||
{
|
||||
"goal_id": "youtube-research",
|
||||
"overall_passed": true,
|
||||
"summary": {
|
||||
"total": 6,
|
||||
"passed": 6,
|
||||
"failed": 0,
|
||||
"pass_rate": "100.0%"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Summary
|
||||
|
||||
1. **Got guidelines** for constraint tests during Goal stage
|
||||
2. **Wrote** constraint tests using Write tool
|
||||
3. **Got guidelines** for success criteria tests during Eval stage
|
||||
4. **Wrote** success criteria tests using Write tool
|
||||
5. **Ran** tests in parallel
|
||||
6. **Debugged** the one failure
|
||||
7. **Categorized** as IMPLEMENTATION_ERROR
|
||||
8. **Fixed** the agent (not the goal)
|
||||
9. **Re-ran** Eval only (didn't restart full flow)
|
||||
10. **Passed** all tests
|
||||
|
||||
The agent is now validated and ready for production use.
|
||||
@@ -1,20 +0,0 @@
|
||||
{
|
||||
"mcpServers": {
|
||||
"agent-builder": {
|
||||
"command": "python",
|
||||
"args": ["-m", "framework.mcp.agent_builder_server"],
|
||||
"cwd": "core",
|
||||
"env": {
|
||||
"PYTHONPATH": "../tools/src"
|
||||
}
|
||||
},
|
||||
"tools": {
|
||||
"command": "python",
|
||||
"args": ["mcp_server.py", "--stdio"],
|
||||
"cwd": "tools",
|
||||
"env": {
|
||||
"PYTHONPATH": "src"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -1 +0,0 @@
|
||||
../../.claude/skills/agent-workflow
|
||||
@@ -1 +0,0 @@
|
||||
../../.claude/skills/building-agents-construction
|
||||
@@ -1 +0,0 @@
|
||||
../../.claude/skills/building-agents-core
|
||||
@@ -1 +0,0 @@
|
||||
../../.claude/skills/building-agents-patterns
|
||||
@@ -1 +0,0 @@
|
||||
../../.claude/skills/testing-agent
|
||||
@@ -1,9 +1,10 @@
|
||||
---
|
||||
name: Bug Report
|
||||
about: Report a bug to help us improve
|
||||
title: '[Bug]: '
|
||||
labels: bug
|
||||
title: "[Bug]: "
|
||||
labels: bug, enhancement
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
## Describe the Bug
|
||||
|
||||
@@ -1,9 +1,10 @@
|
||||
---
|
||||
name: Feature Request
|
||||
about: Suggest a new feature or enhancement
|
||||
title: '[Feature]: '
|
||||
title: "[Feature]: "
|
||||
labels: enhancement
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
## Problem Statement
|
||||
|
||||
@@ -0,0 +1,89 @@
|
||||
name: Integration Bounty
|
||||
description: A bounty task for the integration contribution program
|
||||
title: "[Bounty]: "
|
||||
labels: []
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
## Integration Bounty
|
||||
|
||||
This issue is part of the [Integration Bounty Program](../../docs/bounty-program/README.md).
|
||||
**Claim this bounty** by commenting below — a maintainer will assign you within 24 hours.
|
||||
|
||||
- type: dropdown
|
||||
id: bounty-type
|
||||
attributes:
|
||||
label: Bounty Type
|
||||
options:
|
||||
- "Test a Tool (20 pts)"
|
||||
- "Write Docs (20 pts)"
|
||||
- "Code Contribution (30 pts)"
|
||||
- "New Integration (75 pts)"
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: dropdown
|
||||
id: difficulty
|
||||
attributes:
|
||||
label: Difficulty
|
||||
options:
|
||||
- Easy
|
||||
- Medium
|
||||
- Hard
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: input
|
||||
id: tool-name
|
||||
attributes:
|
||||
label: Tool Name
|
||||
description: The integration this bounty targets (e.g., `airtable`, `salesforce`)
|
||||
placeholder: e.g., airtable
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: textarea
|
||||
id: description
|
||||
attributes:
|
||||
label: Description
|
||||
description: What needs to be done to complete this bounty.
|
||||
placeholder: |
|
||||
Describe the specific task, including:
|
||||
- What the contributor needs to do
|
||||
- Links to relevant files in the repo
|
||||
- Any setup requirements (API keys, accounts, etc.)
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: textarea
|
||||
id: acceptance-criteria
|
||||
attributes:
|
||||
label: Acceptance Criteria
|
||||
description: What "done" looks like. The PR or report must meet all criteria.
|
||||
placeholder: |
|
||||
- [ ] Criterion 1
|
||||
- [ ] Criterion 2
|
||||
- [ ] CI passes
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: textarea
|
||||
id: relevant-files
|
||||
attributes:
|
||||
label: Relevant Files
|
||||
description: Links to tool directory, credential spec, health check file, etc.
|
||||
placeholder: |
|
||||
- Tool: `tools/src/aden_tools/tools/{tool_name}/`
|
||||
- Credential spec: `tools/src/aden_tools/credentials/{category}.py`
|
||||
- Health checks: `tools/src/aden_tools/credentials/health_check.py`
|
||||
|
||||
- type: textarea
|
||||
id: resources
|
||||
attributes:
|
||||
label: Resources
|
||||
description: Links to API docs, examples, or guides that will help the contributor.
|
||||
placeholder: |
|
||||
- [Building Tools Guide](../../tools/BUILDING_TOOLS.md)
|
||||
- [Tool README Template](../../docs/bounty-program/templates/tool-readme-template.md)
|
||||
- API docs: https://...
|
||||
@@ -0,0 +1,71 @@
|
||||
---
|
||||
name: Integration Request
|
||||
about: Suggest a new integration
|
||||
title: "[Integration]:"
|
||||
labels: ''
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
## Service
|
||||
|
||||
Name and brief description of the service and what it enables agents to do.
|
||||
|
||||
**Description:** [e.g., "API key for Slack Bot" — short one-liner for the credential spec]
|
||||
|
||||
## Credential Identity
|
||||
|
||||
- **credential_id:** [e.g., `slack`]
|
||||
- **env_var:** [e.g., `SLACK_BOT_TOKEN`]
|
||||
- **credential_key:** [e.g., `access_token`, `api_key`, `bot_token`]
|
||||
|
||||
## Tools
|
||||
|
||||
Tool function names that require this credential:
|
||||
|
||||
- [e.g., `slack_send_message`]
|
||||
- [e.g., `slack_list_channels`]
|
||||
|
||||
## Auth Methods
|
||||
|
||||
- **Direct API key supported:** Yes / No
|
||||
- **Aden OAuth supported:** Yes / No
|
||||
|
||||
If Aden OAuth is supported, describe the OAuth scopes/permissions required.
|
||||
|
||||
## How to Get the Credential
|
||||
|
||||
Link where users obtain the key/token:
|
||||
|
||||
[e.g., https://api.slack.com/apps]
|
||||
|
||||
Step-by-step instructions:
|
||||
|
||||
1. Go to ...
|
||||
2. Create a ...
|
||||
3. Select scopes/permissions: ...
|
||||
4. Copy the key/token
|
||||
|
||||
## Health Check
|
||||
|
||||
A lightweight API call to validate the credential (no writes, no charges).
|
||||
|
||||
- **Endpoint:** [e.g., `https://slack.com/api/auth.test`]
|
||||
- **Method:** [e.g., `GET` or `POST`]
|
||||
- **Auth header:** [e.g., `Authorization: Bearer {token}` or `X-Api-Key: {key}`]
|
||||
- **Parameters (if any):** [e.g., `?limit=1`]
|
||||
- **200 means:** [e.g., key is valid]
|
||||
- **401 means:** [e.g., invalid or expired]
|
||||
- **429 means:** [e.g., rate limited but key is valid]
|
||||
|
||||
## Credential Group
|
||||
|
||||
Does this require multiple credentials configured together? (e.g., Google Custom Search needs
|
||||
both an API key and a CSE ID)
|
||||
|
||||
- [ ] No, single credential
|
||||
- [ ] Yes — list the other credential IDs in the group:
|
||||
|
||||
## Additional Context
|
||||
|
||||
Links to API docs, rate limits, free tier availability, or anything else relevant.
|
||||
@@ -0,0 +1,78 @@
|
||||
name: Standard Bounty
|
||||
description: A bounty task for general framework contributions (not integration-specific)
|
||||
title: "[Bounty]: "
|
||||
labels: []
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
## Standard Bounty
|
||||
|
||||
This issue is part of the [Bounty Program](../../docs/bounty-program/README.md).
|
||||
**Claim this bounty** by commenting below — a maintainer will assign you within 24 hours.
|
||||
|
||||
- type: dropdown
|
||||
id: bounty-size
|
||||
attributes:
|
||||
label: Bounty Size
|
||||
options:
|
||||
- "Small (10 pts)"
|
||||
- "Medium (30 pts)"
|
||||
- "Large (75 pts)"
|
||||
- "Extreme (150 pts)"
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: dropdown
|
||||
id: difficulty
|
||||
attributes:
|
||||
label: Difficulty
|
||||
options:
|
||||
- Easy
|
||||
- Medium
|
||||
- Hard
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: textarea
|
||||
id: description
|
||||
attributes:
|
||||
label: Description
|
||||
description: What needs to be done to complete this bounty.
|
||||
placeholder: |
|
||||
Describe the specific task, including:
|
||||
- What the contributor needs to do
|
||||
- Links to relevant files in the repo
|
||||
- Any context or motivation for the change
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: textarea
|
||||
id: acceptance-criteria
|
||||
attributes:
|
||||
label: Acceptance Criteria
|
||||
description: What "done" looks like. The PR must meet all criteria.
|
||||
placeholder: |
|
||||
- [ ] Criterion 1
|
||||
- [ ] Criterion 2
|
||||
- [ ] CI passes
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: textarea
|
||||
id: relevant-files
|
||||
attributes:
|
||||
label: Relevant Files
|
||||
description: Links to files or directories related to this bounty.
|
||||
placeholder: |
|
||||
- `path/to/file.py`
|
||||
- `path/to/directory/`
|
||||
|
||||
- type: textarea
|
||||
id: resources
|
||||
attributes:
|
||||
label: Resources
|
||||
description: Links to docs, issues, or external references that will help.
|
||||
placeholder: |
|
||||
- Related issue: #XXXX
|
||||
- Docs: https://...
|
||||
@@ -0,0 +1,37 @@
|
||||
name: Bounty completed
|
||||
description: Awards points and notifies Discord when a bounty PR is merged
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
types: [closed]
|
||||
|
||||
jobs:
|
||||
bounty-notify:
|
||||
if: >
|
||||
github.event.pull_request.merged == true &&
|
||||
contains(join(github.event.pull_request.labels.*.name, ','), 'bounty:')
|
||||
runs-on: ubuntu-latest
|
||||
timeout-minutes: 5
|
||||
permissions:
|
||||
contents: read
|
||||
pull-requests: read
|
||||
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Setup Bun
|
||||
uses: oven-sh/setup-bun@v2
|
||||
with:
|
||||
bun-version: latest
|
||||
|
||||
- name: Award XP and notify Discord
|
||||
run: bun run scripts/bounty-tracker.ts notify
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
GITHUB_REPOSITORY_OWNER: ${{ github.repository_owner }}
|
||||
GITHUB_REPOSITORY_NAME: ${{ github.event.repository.name }}
|
||||
DISCORD_WEBHOOK_URL: ${{ secrets.DISCORD_BOUNTY_WEBHOOK_URL }}
|
||||
LURKR_API_KEY: ${{ secrets.LURKR_API_KEY }}
|
||||
LURKR_GUILD_ID: ${{ secrets.LURKR_GUILD_ID }}
|
||||
PR_NUMBER: ${{ github.event.pull_request.number }}
|
||||
+36
-29
@@ -5,7 +5,7 @@ on:
|
||||
branches: [main]
|
||||
pull_request:
|
||||
branches: [main]
|
||||
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.ref }}
|
||||
cancel-in-progress: true
|
||||
@@ -21,23 +21,24 @@ jobs:
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.11'
|
||||
cache: 'pip'
|
||||
|
||||
- name: Install uv
|
||||
uses: astral-sh/setup-uv@v4
|
||||
with:
|
||||
enable-cache: true
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
cd core
|
||||
pip install -e .
|
||||
pip install -r requirements-dev.txt
|
||||
run: uv sync --project core --group dev
|
||||
|
||||
- name: Ruff lint
|
||||
run: |
|
||||
ruff check core/
|
||||
ruff check tools/
|
||||
uv run --project core ruff check core/
|
||||
uv run --project core ruff check tools/
|
||||
|
||||
- name: Ruff format
|
||||
run: |
|
||||
ruff format --check core/
|
||||
ruff format --check tools/
|
||||
uv run --project core ruff format --check core/
|
||||
uv run --project core ruff format --check tools/
|
||||
|
||||
test:
|
||||
name: Test Python Framework
|
||||
@@ -52,22 +53,24 @@ jobs:
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.11'
|
||||
cache: 'pip'
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
cd core
|
||||
pip install -e .
|
||||
pip install -r requirements-dev.txt
|
||||
- name: Install uv
|
||||
uses: astral-sh/setup-uv@v4
|
||||
with:
|
||||
enable-cache: true
|
||||
|
||||
- name: Run tests
|
||||
- name: Install dependencies and run tests
|
||||
working-directory: core
|
||||
run: |
|
||||
cd core
|
||||
pytest tests/ -v
|
||||
uv sync
|
||||
uv run pytest tests/ -v
|
||||
|
||||
test-tools:
|
||||
name: Test Tools
|
||||
runs-on: ubuntu-latest
|
||||
name: Test Tools (${{ matrix.os }})
|
||||
runs-on: ${{ matrix.os }}
|
||||
strategy:
|
||||
matrix:
|
||||
os: [ubuntu-latest, windows-latest]
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
@@ -78,13 +81,14 @@ jobs:
|
||||
|
||||
- name: Install uv
|
||||
uses: astral-sh/setup-uv@v4
|
||||
with:
|
||||
enable-cache: true
|
||||
|
||||
- name: Install dependencies and run tests
|
||||
working-directory: tools
|
||||
run: |
|
||||
cd tools
|
||||
uv sync --extra dev
|
||||
uv pip install --python .venv/bin/python -e ../core
|
||||
uv run --extra dev pytest tests/ -v
|
||||
uv run pytest tests/ -v
|
||||
|
||||
validate:
|
||||
name: Validate Agent Exports
|
||||
@@ -97,13 +101,16 @@ jobs:
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.11'
|
||||
cache: 'pip'
|
||||
|
||||
- name: Install uv
|
||||
uses: astral-sh/setup-uv@v4
|
||||
with:
|
||||
enable-cache: true
|
||||
|
||||
- name: Install dependencies
|
||||
working-directory: core
|
||||
run: |
|
||||
cd core
|
||||
pip install -e .
|
||||
pip install -r requirements-dev.txt
|
||||
uv sync
|
||||
|
||||
- name: Validate exported agents
|
||||
run: |
|
||||
@@ -126,7 +133,7 @@ jobs:
|
||||
for agent_dir in "${agent_dirs[@]}"; do
|
||||
if [ -f "$agent_dir/agent.json" ]; then
|
||||
echo "Validating $agent_dir"
|
||||
python -c "import json; json.load(open('$agent_dir/agent.json'))"
|
||||
uv run python -c "import json; json.load(open('$agent_dir/agent.json'))"
|
||||
validated=$((validated + 1))
|
||||
fi
|
||||
done
|
||||
|
||||
@@ -80,7 +80,13 @@ jobs:
|
||||
- help wanted: Extra attention is needed (if issue needs community input)
|
||||
- backlog: Tracked for the future, but not currently planned or prioritized
|
||||
|
||||
You may apply multiple labels if appropriate (e.g., "bug" and "help wanted").
|
||||
### 6. Estimate size (if NOT a duplicate, spam, or invalid)
|
||||
Apply exactly ONE size label to help contributors match their capacity to the task:
|
||||
- "size: small": Docs, typos, single-file fixes, config changes
|
||||
- "size: medium": Bug fixes with tests, adding a single tool, changes within one package
|
||||
- "size: large": Cross-package changes (core + tools), new modules, complex logic, architectural refactors
|
||||
|
||||
You may apply multiple labels if appropriate (e.g., "bug", "size: small", and "good first issue").
|
||||
|
||||
## Tools Available:
|
||||
- mcp__github__get_issue: Get issue details
|
||||
|
||||
@@ -0,0 +1,126 @@
|
||||
name: Link Discord account
|
||||
description: Auto-creates a PR to add contributor to contributors.yml when a link-discord issue is opened
|
||||
|
||||
on:
|
||||
issues:
|
||||
types: [opened]
|
||||
|
||||
jobs:
|
||||
link-discord:
|
||||
if: contains(github.event.issue.labels.*.name, 'link-discord')
|
||||
runs-on: ubuntu-latest
|
||||
timeout-minutes: 2
|
||||
permissions:
|
||||
contents: write
|
||||
issues: write
|
||||
pull-requests: write
|
||||
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Parse issue and update contributors.yml
|
||||
uses: actions/github-script@v7
|
||||
with:
|
||||
script: |
|
||||
const fs = require('fs');
|
||||
|
||||
const issue = context.payload.issue;
|
||||
const githubUsername = issue.user.login;
|
||||
|
||||
// Parse the issue body for form fields
|
||||
const body = issue.body || '';
|
||||
|
||||
// Extract Discord ID — look for the numeric value after the "Discord User ID" heading
|
||||
const discordMatch = body.match(/### Discord User ID\s*\n\s*(\d{17,20})/);
|
||||
if (!discordMatch) {
|
||||
await github.rest.issues.createComment({
|
||||
...context.repo,
|
||||
issue_number: issue.number,
|
||||
body: `Could not find a valid Discord ID in the issue body. Please make sure you entered a numeric ID (17-20 digits), not a username.\n\nExample: \`123456789012345678\``
|
||||
});
|
||||
await github.rest.issues.update({
|
||||
...context.repo,
|
||||
issue_number: issue.number,
|
||||
state: 'closed',
|
||||
state_reason: 'not_planned'
|
||||
});
|
||||
return;
|
||||
}
|
||||
const discordId = discordMatch[1];
|
||||
|
||||
// Extract display name (optional)
|
||||
const nameMatch = body.match(/### Display Name \(optional\)\s*\n\s*(.+)/);
|
||||
const displayName = nameMatch ? nameMatch[1].trim() : '';
|
||||
|
||||
// Check if user already exists
|
||||
const yml = fs.readFileSync('contributors.yml', 'utf-8');
|
||||
if (yml.includes(`github: ${githubUsername}`)) {
|
||||
await github.rest.issues.createComment({
|
||||
...context.repo,
|
||||
issue_number: issue.number,
|
||||
body: `@${githubUsername} is already in \`contributors.yml\`. If you need to update your Discord ID, please edit the file directly via PR.`
|
||||
});
|
||||
await github.rest.issues.update({
|
||||
...context.repo,
|
||||
issue_number: issue.number,
|
||||
state: 'closed',
|
||||
state_reason: 'completed'
|
||||
});
|
||||
return;
|
||||
}
|
||||
|
||||
// Append entry to contributors.yml
|
||||
let entry = ` - github: ${githubUsername}\n discord: "${discordId}"`;
|
||||
if (displayName && displayName !== '_No response_') {
|
||||
entry += `\n name: ${displayName}`;
|
||||
}
|
||||
entry += '\n';
|
||||
|
||||
const updated = yml.trimEnd() + '\n' + entry;
|
||||
fs.writeFileSync('contributors.yml', updated);
|
||||
|
||||
// Set outputs for commit step
|
||||
core.exportVariable('GITHUB_USERNAME', githubUsername);
|
||||
core.exportVariable('DISCORD_ID', discordId);
|
||||
core.exportVariable('ISSUE_NUMBER', issue.number.toString());
|
||||
|
||||
- name: Create PR
|
||||
run: |
|
||||
# Check if there are changes
|
||||
if git diff --quiet contributors.yml; then
|
||||
echo "No changes to contributors.yml"
|
||||
exit 0
|
||||
fi
|
||||
|
||||
BRANCH="docs/link-discord-${GITHUB_USERNAME}"
|
||||
git config user.name "github-actions[bot]"
|
||||
git config user.email "41898282+github-actions[bot]@users.noreply.github.com"
|
||||
git checkout -b "$BRANCH"
|
||||
git add contributors.yml
|
||||
git commit -m "docs: link @${GITHUB_USERNAME} to Discord"
|
||||
git push origin "$BRANCH"
|
||||
|
||||
gh pr create \
|
||||
--title "docs: link @${GITHUB_USERNAME} to Discord" \
|
||||
--body "Adds @${GITHUB_USERNAME} (Discord \`${DISCORD_ID}\`) to \`contributors.yml\` for bounty XP tracking.
|
||||
|
||||
Closes #${ISSUE_NUMBER}" \
|
||||
--base main \
|
||||
--head "$BRANCH" \
|
||||
--label "link-discord"
|
||||
env:
|
||||
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Notify on issue
|
||||
uses: actions/github-script@v7
|
||||
with:
|
||||
script: |
|
||||
const username = process.env.GITHUB_USERNAME;
|
||||
const issueNumber = parseInt(process.env.ISSUE_NUMBER);
|
||||
|
||||
await github.rest.issues.createComment({
|
||||
...context.repo,
|
||||
issue_number: issueNumber,
|
||||
body: `A PR has been created to link your account. A maintainer will merge it shortly — once merged, you'll receive XP and Discord pings when your bounty PRs are merged.`
|
||||
});
|
||||
@@ -0,0 +1,54 @@
|
||||
# Closes PRs that still have the `pr-requirements-warning` label
|
||||
# after contributors were warned in pr-requirements.yml.
|
||||
name: PR Requirements Enforcement
|
||||
on:
|
||||
schedule:
|
||||
- cron: "0 0 * * *" # runs every day once at midnight
|
||||
jobs:
|
||||
enforce:
|
||||
name: Close PRs still failing contribution requirements
|
||||
runs-on: ubuntu-latest
|
||||
permissions:
|
||||
pull-requests: write
|
||||
issues: write
|
||||
steps:
|
||||
- name: Close PRs still failing requirements
|
||||
uses: actions/github-script@v7
|
||||
with:
|
||||
script: |
|
||||
const { owner, repo } = context.repo;
|
||||
const prs = await github.paginate(github.rest.pulls.list, {
|
||||
owner,
|
||||
repo,
|
||||
state: "open",
|
||||
per_page: 100
|
||||
});
|
||||
for (const pr of prs) {
|
||||
// Skip draft PRs — author may still be actively working toward compliance
|
||||
if (pr.draft) continue;
|
||||
const labels = pr.labels.map(l => l.name);
|
||||
if (!labels.includes("pr-requirements-warning")) continue;
|
||||
const gracePeriod = 24 * 60 * 60 * 1000;
|
||||
const lastUpdated = new Date(pr.created_at);
|
||||
const now = new Date();
|
||||
if (now - lastUpdated < gracePeriod) {
|
||||
console.log(`Skipping PR #${pr.number} — still within grace period`);
|
||||
continue;
|
||||
}
|
||||
const prNumber = pr.number;
|
||||
const prAuthor = pr.user.login;
|
||||
await github.rest.issues.createComment({
|
||||
owner,
|
||||
repo,
|
||||
issue_number: prNumber,
|
||||
body: `Closing PR because the contribution requirements were not resolved within the 24-hour grace period.
|
||||
If this was closed in error, feel free to reopen the PR after fixing the requirements.`
|
||||
});
|
||||
await github.rest.pulls.update({
|
||||
owner,
|
||||
repo,
|
||||
pull_number: prNumber,
|
||||
state: "closed"
|
||||
});
|
||||
console.log(`Closed PR #${prNumber} by ${prAuthor} (PR requirements were not met)`);
|
||||
}
|
||||
@@ -43,9 +43,10 @@ jobs:
|
||||
console.log(` Found issue references: ${issueNumbers.length > 0 ? issueNumbers.join(', ') : 'none'}`);
|
||||
|
||||
if (issueNumbers.length === 0) {
|
||||
const message = `## PR Closed - Requirements Not Met
|
||||
const message = `## PR Requirements Warning
|
||||
|
||||
This PR has been automatically closed because it doesn't meet the requirements.
|
||||
This PR does not meet the contribution requirements.
|
||||
If the issue is not fixed within ~24 hours, it may be automatically closed.
|
||||
|
||||
**Missing:** No linked issue found.
|
||||
|
||||
@@ -67,14 +68,15 @@ jobs:
|
||||
|
||||
**Why is this required?** See #472 for details.`;
|
||||
|
||||
const comments = await github.rest.issues.listComments({
|
||||
const comments = await github.paginate(github.rest.issues.listComments, {
|
||||
owner: context.repo.owner,
|
||||
repo: context.repo.repo,
|
||||
issue_number: prNumber,
|
||||
per_page: 100,
|
||||
});
|
||||
|
||||
const botComment = comments.data.find(
|
||||
(c) => c.user.type === 'Bot' && c.body.includes('PR Closed - Requirements Not Met')
|
||||
const botComment = comments.find(
|
||||
(c) => c.user.type === 'Bot' && c.body.includes('PR Requirements Warning')
|
||||
);
|
||||
|
||||
if (!botComment) {
|
||||
@@ -86,11 +88,11 @@ jobs:
|
||||
});
|
||||
}
|
||||
|
||||
await github.rest.pulls.update({
|
||||
await github.rest.issues.addLabels({
|
||||
owner: context.repo.owner,
|
||||
repo: context.repo.repo,
|
||||
pull_number: prNumber,
|
||||
state: 'closed',
|
||||
issue_number: prNumber,
|
||||
labels: ['pr-requirements-warning'],
|
||||
});
|
||||
|
||||
core.setFailed('PR must reference an issue');
|
||||
@@ -132,9 +134,10 @@ jobs:
|
||||
`#${i.number} (assignees: ${i.assignees.length > 0 ? i.assignees.join(', ') : 'none'})`
|
||||
).join(', ');
|
||||
|
||||
const message = `## PR Closed - Requirements Not Met
|
||||
const message = `## PR Requirements Warning
|
||||
|
||||
This PR has been automatically closed because it doesn't meet the requirements.
|
||||
This PR does not meet the contribution requirements.
|
||||
If the issue is not fixed within ~24 hours, it may be automatically closed.
|
||||
|
||||
**PR Author:** @${prAuthor}
|
||||
**Found issues:** ${issueList}
|
||||
@@ -157,14 +160,15 @@ jobs:
|
||||
|
||||
**Why is this required?** See #472 for details.`;
|
||||
|
||||
const comments = await github.rest.issues.listComments({
|
||||
const comments = await github.paginate(github.rest.issues.listComments, {
|
||||
owner: context.repo.owner,
|
||||
repo: context.repo.repo,
|
||||
issue_number: prNumber,
|
||||
per_page: 100,
|
||||
});
|
||||
|
||||
const botComment = comments.data.find(
|
||||
(c) => c.user.type === 'Bot' && c.body.includes('PR Closed - Requirements Not Met')
|
||||
const botComment = comments.find(
|
||||
(c) => c.user.type === 'Bot' && c.body.includes('PR Requirements Warning')
|
||||
);
|
||||
|
||||
if (!botComment) {
|
||||
@@ -176,14 +180,24 @@ jobs:
|
||||
});
|
||||
}
|
||||
|
||||
await github.rest.pulls.update({
|
||||
await github.rest.issues.addLabels({
|
||||
owner: context.repo.owner,
|
||||
repo: context.repo.repo,
|
||||
pull_number: prNumber,
|
||||
state: 'closed',
|
||||
issue_number: prNumber,
|
||||
labels: ['pr-requirements-warning'],
|
||||
});
|
||||
|
||||
core.setFailed('PR author must be assigned to the linked issue');
|
||||
} else {
|
||||
console.log(`PR requirements met! Issue #${issueWithAuthorAssigned} has ${prAuthor} as assignee.`);
|
||||
}
|
||||
try {
|
||||
await github.rest.issues.removeLabel({
|
||||
owner: context.repo.owner,
|
||||
repo: context.repo.repo,
|
||||
issue_number: prNumber,
|
||||
name: "pr-requirements-warning"
|
||||
});
|
||||
}catch (error){
|
||||
//ignore if label doesn't exist
|
||||
}
|
||||
}
|
||||
@@ -21,18 +21,19 @@ jobs:
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.11'
|
||||
cache: 'pip'
|
||||
|
||||
- name: Install uv
|
||||
uses: astral-sh/setup-uv@v4
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
cd core
|
||||
pip install -e .
|
||||
pip install -r requirements-dev.txt
|
||||
uv sync
|
||||
|
||||
- name: Run tests
|
||||
run: |
|
||||
cd core
|
||||
pytest tests/ -v
|
||||
uv run pytest tests/ -v
|
||||
|
||||
- name: Generate changelog
|
||||
id: changelog
|
||||
|
||||
@@ -0,0 +1,40 @@
|
||||
name: Weekly bounty leaderboard
|
||||
description: Posts the integration bounty leaderboard to Discord every Monday
|
||||
|
||||
on:
|
||||
schedule:
|
||||
# Every Monday at 9:00 UTC
|
||||
- cron: "0 9 * * 1"
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
since_date:
|
||||
description: "Only count PRs merged after this date (YYYY-MM-DD). Leave empty for all-time."
|
||||
required: false
|
||||
|
||||
jobs:
|
||||
leaderboard:
|
||||
runs-on: ubuntu-latest
|
||||
timeout-minutes: 5
|
||||
permissions:
|
||||
contents: read
|
||||
pull-requests: read
|
||||
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Setup Bun
|
||||
uses: oven-sh/setup-bun@v2
|
||||
with:
|
||||
bun-version: latest
|
||||
|
||||
- name: Post leaderboard to Discord
|
||||
run: bun run scripts/bounty-tracker.ts leaderboard
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
GITHUB_REPOSITORY_OWNER: ${{ github.repository_owner }}
|
||||
GITHUB_REPOSITORY_NAME: ${{ github.event.repository.name }}
|
||||
DISCORD_WEBHOOK_URL: ${{ secrets.DISCORD_BOUNTY_WEBHOOK_URL }}
|
||||
LURKR_API_KEY: ${{ secrets.LURKR_API_KEY }}
|
||||
LURKR_GUILD_ID: ${{ secrets.LURKR_GUILD_ID }}
|
||||
SINCE_DATE: ${{ github.event.inputs.since_date || '' }}
|
||||
+10
-3
@@ -46,6 +46,7 @@ coverage/
|
||||
|
||||
# TypeScript
|
||||
*.tsbuildinfo
|
||||
vite.config.d.ts
|
||||
|
||||
# Python
|
||||
__pycache__/
|
||||
@@ -54,7 +55,6 @@ __pycache__/
|
||||
*.egg-info/
|
||||
.eggs/
|
||||
*.egg
|
||||
uv.lock
|
||||
|
||||
# Generated runtime data
|
||||
core/data/
|
||||
@@ -67,6 +67,13 @@ temp/
|
||||
|
||||
exports/*
|
||||
|
||||
.agent-builder-sessions/*
|
||||
.claude/settings.local.json
|
||||
|
||||
.venv
|
||||
.venv
|
||||
|
||||
docs/github-issues/*
|
||||
core/tests/*dumps/*
|
||||
|
||||
screenshots/*
|
||||
|
||||
.gemini/*
|
||||
|
||||
@@ -1,20 +1,3 @@
|
||||
{
|
||||
"mcpServers": {
|
||||
"agent-builder": {
|
||||
"command": ".venv/bin/python",
|
||||
"args": ["-m", "framework.mcp.agent_builder_server"],
|
||||
"cwd": "core",
|
||||
"env": {
|
||||
"PYTHONPATH": "../tools/src"
|
||||
}
|
||||
},
|
||||
"tools": {
|
||||
"command": ".venv/bin/python",
|
||||
"args": ["mcp_server.py", "--stdio"],
|
||||
"cwd": "tools",
|
||||
"env": {
|
||||
"PYTHONPATH": "src:../core"
|
||||
}
|
||||
}
|
||||
}
|
||||
"mcpServers": {}
|
||||
}
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
repos:
|
||||
- repo: https://github.com/astral-sh/ruff-pre-commit
|
||||
rev: v0.8.6
|
||||
rev: v0.15.0
|
||||
hooks:
|
||||
- id: ruff
|
||||
name: ruff lint (core)
|
||||
|
||||
Vendored
-7
@@ -1,7 +0,0 @@
|
||||
{
|
||||
"recommendations": [
|
||||
"charliermarsh.ruff",
|
||||
"editorconfig.editorconfig",
|
||||
"ms-python.python"
|
||||
]
|
||||
}
|
||||
@@ -0,0 +1,30 @@
|
||||
# Repository Guidelines
|
||||
|
||||
Shared agent instructions for this workspace.
|
||||
|
||||
## Coding Agent Notes
|
||||
|
||||
-
|
||||
- When working on a GitHub Issue or PR, print the full URL at the end of the task.
|
||||
- When answering questions, respond with high-confidence answers only: verify in code; do not guess.
|
||||
- Do not update dependencies casually. Version bumps, patched dependencies, overrides, or vendored dependency changes require explicit approval.
|
||||
- Add brief comments for tricky logic. Keep files reasonably small when practical; split or refactor large files instead of growing them indefinitely.
|
||||
- If shared guardrails are available locally, review them; otherwise follow this repo's guidance.
|
||||
- Use `uv` for Python execution and package management. Do not use `python` or `python3` directly unless the user explicitly asks for it.
|
||||
- Prefer `uv run` for scripts and tests, and `uv pip` for package operations.
|
||||
|
||||
|
||||
## Multi-Agent Safety
|
||||
|
||||
- Do not create, apply, or drop `git stash` entries unless explicitly requested.
|
||||
- Do not create, remove, or modify `git worktree` checkouts unless explicitly requested.
|
||||
- Do not switch branches or check out a different branch unless explicitly requested.
|
||||
- When the user says `push`, you may `git pull --rebase` to integrate latest changes, but never discard other in-progress work.
|
||||
- When the user says `commit`, commit only your changes. When the user says `commit all`, commit everything in grouped chunks.
|
||||
- When you see unrecognized files or unrelated changes, keep going and focus on your scoped changes.
|
||||
|
||||
## Change Hygiene
|
||||
|
||||
- If staged and unstaged diffs are formatting-only, resolve them without asking.
|
||||
- If a commit or push was already requested, include formatting-only follow-up changes in that same commit when practical.
|
||||
- Only stop to ask for confirmation when changes are semantic and may alter behavior.
|
||||
+317
-28
@@ -1,41 +1,330 @@
|
||||
# Changelog
|
||||
# Release Notes
|
||||
|
||||
All notable changes to this project will be documented in this file.
|
||||
## v0.7.1
|
||||
|
||||
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.1.0/),
|
||||
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
|
||||
**Release Date:** March 13, 2026
|
||||
**Tag:** v0.7.1
|
||||
|
||||
## [Unreleased]
|
||||
### Chrome-Native Browser Control
|
||||
|
||||
### Added
|
||||
- Initial project structure
|
||||
- React frontend (honeycomb) with Vite and TypeScript
|
||||
- Node.js backend (hive) with Express and TypeScript
|
||||
- Docker Compose configuration for local development
|
||||
- Configuration system via `config.yaml`
|
||||
- GitHub Actions CI/CD workflows
|
||||
- Comprehensive documentation
|
||||
v0.7.1 replaces Playwright with direct Chrome DevTools Protocol (CDP) integration. The GCU now launches the user's system Chrome via `open -n` on macOS, connects over CDP, and manages browser lifecycle end-to-end -- no extra browser binary required.
|
||||
|
||||
### Changed
|
||||
- N/A
|
||||
---
|
||||
|
||||
### Deprecated
|
||||
- N/A
|
||||
### Highlights
|
||||
|
||||
### Removed
|
||||
- N/A
|
||||
#### System Chrome via CDP
|
||||
|
||||
The entire GCU browser stack has been rewritten:
|
||||
|
||||
### Fixed
|
||||
- tools: Fixed web_scrape tool attempting to parse non-HTML content (PDF, JSON) as HTML (#487)
|
||||
- **Chrome finder & launcher** -- New `chrome_finder.py` discovers installed Chrome and `chrome_launcher.py` manages process lifecycle with `--remote-debugging-port`
|
||||
- **Coexist with user's browser** -- `open -n` on macOS launches a separate Chrome instance so the user's tabs stay untouched
|
||||
- **Dynamic viewport sizing** -- Viewport auto-sizes to the available display area, suppressing Chrome warning bars
|
||||
- **Orphan cleanup** -- Chrome processes are killed on GCU server shutdown to prevent leaks
|
||||
- **`--no-startup-window`** -- Chrome launches headlessly by default until a page is needed
|
||||
|
||||
### Security
|
||||
- N/A
|
||||
#### Per-Subagent Browser Isolation
|
||||
|
||||
## [0.1.0] - 2025-01-13
|
||||
Each GCU subagent gets its own Chrome user-data directory, preventing cookie/session cross-contamination:
|
||||
|
||||
### Added
|
||||
- Initial release
|
||||
- Unique browser profiles injected per subagent
|
||||
- Profiles cleaned up after top-level GCU node execution
|
||||
- Tab origin and age metadata tracked per subagent
|
||||
|
||||
[Unreleased]: https://github.com/adenhq/hive/compare/v0.1.0...HEAD
|
||||
[0.1.0]: https://github.com/adenhq/hive/releases/tag/v0.1.0
|
||||
#### Dummy Agent Testing Framework
|
||||
|
||||
A comprehensive test suite for validating agent graph patterns without LLM calls:
|
||||
|
||||
- 8 test modules covering echo, pipeline, branch, parallel merge, retry, feedback loop, worker, and GCU subagent patterns
|
||||
- Shared fixtures and a `run_all.py` runner for CI integration
|
||||
- Subagent lifecycle tests
|
||||
|
||||
---
|
||||
|
||||
### What's New
|
||||
|
||||
#### GCU Browser
|
||||
|
||||
- **Switch from Playwright to system Chrome via CDP** -- Direct CDP connection replaces Playwright dependency. (@bryanadenhq)
|
||||
- **Chrome finder and launcher modules** -- `chrome_finder.py` and `chrome_launcher.py` for cross-platform Chrome discovery and process management. (@bryanadenhq)
|
||||
- **Dynamic viewport sizing** -- Auto-size viewport and suppress Chrome warning bar. (@bryanadenhq)
|
||||
- **Per-subagent browser profile isolation** -- Unique user-data directories per subagent with cleanup. (@bryanadenhq)
|
||||
- **Tab origin/age metadata** -- Track which subagent opened each tab and when. (@bryanadenhq)
|
||||
- **`browser_close_all` tool** -- Bulk tab cleanup for agents managing many pages. (@bryanadenhq)
|
||||
- **Auto-track popup pages** -- Popups are automatically captured and tracked. (@bryanadenhq)
|
||||
- **Auto-snapshot from browser interactions** -- Browser interaction tools return screenshots automatically. (@bryanadenhq)
|
||||
- **Kill orphaned Chrome processes** -- GCU server shutdown cleans up lingering Chrome instances. (@bryanadenhq)
|
||||
- **`--no-startup-window` Chrome flag** -- Prevent empty window on launch. (@bryanadenhq)
|
||||
- **Launch Chrome via `open -n` on macOS** -- Coexist with the user's running browser. (@bryanadenhq)
|
||||
|
||||
#### Framework & Runtime
|
||||
|
||||
- **Session resume fix for new agents** -- Correctly resume sessions when a new agent is loaded. (@bryanadenhq)
|
||||
- **Queen upsert fix** -- Prevent duplicate queen entries on session restore. (@bryanadenhq)
|
||||
- **Anchor worker monitoring to queen's session ID on cold-restore** -- Worker monitors reconnect to the correct queen after restart. (@bryanadenhq)
|
||||
- **Update meta.json when loading workers** -- Worker metadata stays in sync with runtime state. (@RichardTang-Aden)
|
||||
- **Generate worker MCP file correctly** -- Fix MCP config generation for spawned workers. (@RichardTang-Aden)
|
||||
- **Share event bus so tool events are visible to parent** -- Tool execution events propagate up to parent graphs. (@bryanadenhq)
|
||||
- **Subagent activity tracking in queen status** -- Queen instructions include live subagent status. (@bryanadenhq)
|
||||
- **GCU system prompt updates** -- Auto-snapshots, batching, popup tracking, and close_all guidance. (@bryanadenhq)
|
||||
|
||||
#### Frontend
|
||||
|
||||
- **Loading spinner in draft panel** -- Shows spinner during planning phase instead of blank panel. (@bryanadenhq)
|
||||
- **Fix credential modal errors** -- Modal no longer eats errors; banner stays visible. (@bryanadenhq)
|
||||
- **Fix credentials_required loop** -- Stop clearing the flag on modal close to prevent infinite re-prompting. (@bryanadenhq)
|
||||
- **Fix "Add tab" dropdown overflow** -- Dropdown no longer hidden when many agents are open. (@prasoonmhwr)
|
||||
|
||||
#### Testing
|
||||
|
||||
- **Dummy agent test framework** -- 8 test modules (echo, pipeline, branch, parallel merge, retry, feedback loop, worker, GCU subagent) with shared fixtures and CI runner. (@bryanadenhq)
|
||||
- **Subagent lifecycle tests** -- Validate subagent spawn and completion flows. (@bryanadenhq)
|
||||
|
||||
#### Documentation & Infrastructure
|
||||
|
||||
- **MCP integration PRD** -- Product requirements for MCP server registry. (@TimothyZhang7)
|
||||
- **Skills registry PRD** -- Product requirements for skill registry system. (@bryanadenhq)
|
||||
- **Bounty program updates** -- Standard bounty issue template and updated contributor guide. (@bryanadenhq)
|
||||
- **Windows quickstart** -- Add default context limit for PowerShell setup. (@bryanadenhq)
|
||||
- **Remove deprecated files** -- Clean up `setup_mcp.py`, `verify_mcp.py`, `antigravity-setup.md`, and `setup-antigravity-mcp.sh`. (@bryanadenhq)
|
||||
|
||||
---
|
||||
|
||||
### Bug Fixes
|
||||
|
||||
- Fix credential modal eating errors and banner staying open
|
||||
- Stop clearing `credentials_required` on modal close to prevent infinite loop
|
||||
- Share event bus so tool events are visible to parent graph
|
||||
- Use lazy %-formatting in subagent completion log to avoid f-string in logger
|
||||
- Anchor worker monitoring to queen's session ID on cold-restore
|
||||
- Update meta.json when loading workers
|
||||
- Generate worker MCP file correctly
|
||||
- Fix "Add tab" dropdown partially hidden when creating multiple agents
|
||||
|
||||
---
|
||||
|
||||
### Community Contributors
|
||||
|
||||
- **Prasoon Mahawar** (@prasoonmhwr) -- Fix UI overflow on agent tab dropdown
|
||||
- **Richard Tang** (@RichardTang-Aden) -- Worker MCP generation and meta.json fixes
|
||||
|
||||
---
|
||||
|
||||
### Upgrading
|
||||
|
||||
```bash
|
||||
git pull origin main
|
||||
uv sync
|
||||
```
|
||||
|
||||
The Playwright dependency is no longer required for GCU browser operations. Chrome must be installed on the host system.
|
||||
|
||||
---
|
||||
|
||||
## v0.7.0
|
||||
|
||||
**Release Date:** March 5, 2026
|
||||
**Tag:** v0.7.0
|
||||
|
||||
Session management refactor release.
|
||||
|
||||
---
|
||||
|
||||
## v0.5.1
|
||||
|
||||
**Release Date:** February 18, 2026
|
||||
**Tag:** v0.5.1
|
||||
|
||||
### The Hive Gets a Brain
|
||||
|
||||
v0.5.1 is our most ambitious release yet. Hive agents can now **build other agents** -- the new Hive Coder meta-agent writes, tests, and fixes agent packages from natural language. The runtime grows multi-graph support so one session can orchestrate multiple agents simultaneously. The TUI gets a complete overhaul with an in-app agent picker, live streaming, and seamless escalation to the Coder. And we're now provider-agnostic: Claude Code subscriptions, OpenAI-compatible endpoints, and any LiteLLM-supported model work out of the box.
|
||||
|
||||
---
|
||||
|
||||
### Highlights
|
||||
|
||||
#### Hive Coder -- The Agent That Builds Agents
|
||||
|
||||
A native meta-agent that lives inside the framework at `core/framework/agents/hive_coder/`. Give it a natural-language specification and it produces a complete agent package -- goal definition, node prompts, edge routing, MCP tool wiring, tests, and all boilerplate files.
|
||||
|
||||
```bash
|
||||
# Launch the Coder directly
|
||||
hive code
|
||||
|
||||
# Or escalate from any running agent (TUI)
|
||||
Ctrl+E # or /coder in chat
|
||||
```
|
||||
|
||||
The Coder ships with:
|
||||
|
||||
- **Reference documentation** -- anti-patterns, construction guide, and design patterns baked into its system prompt
|
||||
- **Guardian watchdog** -- an event-driven monitor that catches agent failures and triggers automatic remediation
|
||||
- **Coder Tools MCP server** -- file I/O, fuzzy-match editing, git snapshots, and sandboxed shell execution (`tools/coder_tools_server.py`)
|
||||
- **Test generation** -- structural tests for forever-alive agents that don't hang on `runner.run()`
|
||||
|
||||
#### Multi-Graph Agent Runtime
|
||||
|
||||
`AgentRuntime` now supports loading, managing, and switching between multiple agent graphs within a single session. Six new lifecycle tools give agents (and the TUI) full control:
|
||||
|
||||
```python
|
||||
# Load a second agent into the runtime
|
||||
await runtime.add_graph("exports/deep_research_agent")
|
||||
|
||||
# Tools available to agents:
|
||||
# load_agent, unload_agent, start_agent, restart_agent, list_agents, get_user_presence
|
||||
```
|
||||
|
||||
The Hive Coder uses multi-graph internally -- when you escalate from a worker agent, the Coder loads as a separate graph while the worker stays alive in the background.
|
||||
|
||||
#### TUI Revamp
|
||||
|
||||
The Terminal UI gets a ground-up rebuild with five major additions:
|
||||
|
||||
- **Agent Picker** (Ctrl+A) -- tabbed modal screen for browsing Your Agents, Framework agents, and Examples with metadata badges (node count, tool count, session count, tags)
|
||||
- **Runtime-optional startup** -- TUI launches without a pre-loaded agent, showing the picker on first open
|
||||
- **Live streaming pane** -- dedicated RichLog widget shows LLM tokens as they arrive, replacing the old one-token-per-line display
|
||||
- **PDF attachments** -- `/attach` and `/detach` commands with native OS file dialog (macOS, Linux, Windows)
|
||||
- **Multi-graph commands** -- `/graphs`, `/graph <id>`, `/load <path>`, `/unload <id>` for managing agent graphs in-session
|
||||
|
||||
#### Provider-Agnostic LLM Support
|
||||
|
||||
Hive is no longer Anthropic-only. v0.5.1 adds first-class support for:
|
||||
|
||||
- **Claude Code subscriptions** -- `use_claude_code_subscription: true` in `~/.hive/configuration.json` reads OAuth tokens from `~/.claude/.credentials.json` with automatic refresh
|
||||
- **OpenAI-compatible endpoints** -- `api_base` config routes traffic through any compatible API (Azure OpenAI, vLLM, Ollama, etc.)
|
||||
- **Any LiteLLM model** -- `RuntimeConfig` now passes `api_key`, `api_base`, and `extra_kwargs` through to LiteLLM
|
||||
|
||||
The quickstart script auto-detects Claude Code subscriptions and ZAI Code installations.
|
||||
|
||||
---
|
||||
|
||||
### What's New
|
||||
|
||||
#### Architecture & Runtime
|
||||
|
||||
- **Hive Coder meta-agent** -- Natural-language agent builder with reference docs, guardian watchdog, and `hive code` CLI command. (@TimothyZhang7)
|
||||
- **Multi-graph agent sessions** -- `add_graph`/`remove_graph` on AgentRuntime with 6 lifecycle tools (`load_agent`, `unload_agent`, `start_agent`, `restart_agent`, `list_agents`, `get_user_presence`). (@TimothyZhang7)
|
||||
- **Claude Code subscription support** -- OAuth token refresh via `use_claude_code_subscription` config, auto-detection in quickstart, LiteLLM header patching. (@TimothyZhang7)
|
||||
- **OpenAI-compatible endpoint support** -- `api_base` and `extra_kwargs` in `RuntimeConfig` for any OpenAI-compatible API. (@TimothyZhang7)
|
||||
- **Remove deprecated node types** -- Delete `FlexibleGraphExecutor`, `WorkerNode`, `HybridJudge`, `CodeSandbox`, `Plan`, `FunctionNode`, `LLMNode`, `RouterNode`. Deprecated types (`llm_tool_use`, `llm_generate`, `function`, `router`, `human_input`) now raise `RuntimeError` with migration guidance. (@TimothyZhang7)
|
||||
- **Interactive credential setup** -- Guided `CredentialSetupSession` with health checks and encrypted storage, accessible via `hive setup-credentials` or automatic prompting on credential errors. (@RichardTang-Aden)
|
||||
- **Pre-start confirmation prompt** -- Interactive prompt before agent execution allowing credential updates or abort. (@RichardTang-Aden)
|
||||
- **Event bus multi-graph support** -- `graph_id` on events, `filter_graph` on subscriptions, `ESCALATION_REQUESTED` event type, `exclude_own_graph` filter. (@TimothyZhang7)
|
||||
|
||||
#### TUI Improvements
|
||||
|
||||
- **In-app agent picker** (Ctrl+A) -- Tabbed modal for browsing agents with metadata badges (nodes, tools, sessions, tags). (@TimothyZhang7)
|
||||
- **Runtime-optional TUI startup** -- Launches without a pre-loaded agent, shows agent picker on startup. (@TimothyZhang7)
|
||||
- **Hive Coder escalation** (Ctrl+E) -- Escalate to Hive Coder and return; also available via `/coder` and `/back` chat commands. (@TimothyZhang7)
|
||||
- **PDF attachment support** -- `/attach` and `/detach` commands with native OS file dialog. (@TimothyZhang7)
|
||||
- **Streaming output pane** -- Dedicated RichLog widget for live LLM token streaming. (@TimothyZhang7)
|
||||
- **Multi-graph TUI commands** -- `/graphs`, `/graph <id>`, `/load <path>`, `/unload <id>`. (@TimothyZhang7)
|
||||
- **Agent Guardian watchdog** -- Event-driven monitor that catches secondary agent failures and triggers automatic remediation, with `--no-guardian` CLI flag. (@TimothyZhang7)
|
||||
|
||||
#### New Tool Integrations
|
||||
|
||||
| Tool | Description | Contributor |
|
||||
| ---------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------ |
|
||||
| **Discord** | 4 MCP tools (`discord_list_guilds`, `discord_list_channels`, `discord_send_message`, `discord_get_messages`) with rate-limit retry and channel filtering | @mishrapravin114 |
|
||||
| **Exa Search API** | 4 AI-powered search tools (`exa_search`, `exa_find_similar`, `exa_get_contents`, `exa_answer`) with neural/keyword search, domain filters, and citation-backed answers | @JeetKaria06 |
|
||||
| **Razorpay** | 6 payment processing tools for payments, invoices, payment links, and refunds with HTTP Basic Auth | @shivamshahi07 |
|
||||
| **Google Docs** | Document creation, reading, and editing with OAuth credential support | @haliaeetusvocifer |
|
||||
| **Gmail enhancements** | Expanded mail operations for inbox management | @bryanadenhq |
|
||||
|
||||
#### Infrastructure
|
||||
|
||||
- **Default node type → `event_loop`** -- `NodeSpec.node_type` defaults to `"event_loop"` instead of `"llm_tool_use"`. (@TimothyZhang7)
|
||||
- **Default `max_node_visits` → 0 (unlimited)** -- Nodes default to unlimited visits, reducing friction for feedback loops and forever-alive agents. (@TimothyZhang7)
|
||||
- **Remove `function` field from NodeSpec** -- Follows deprecation of `FunctionNode`. (@TimothyZhang7)
|
||||
- **LiteLLM OAuth patch** -- Correct header construction for OAuth tokens (remove `x-api-key` when Bearer token is present). (@TimothyZhang7)
|
||||
- **Orchestrator config centralization** -- Reads `api_key`, `api_base`, `extra_kwargs` from centralized `~/.hive/configuration.json`. (@TimothyZhang7)
|
||||
- **System prompt datetime injection** -- All system prompts now include current date/time for time-aware agent behavior. (@TimothyZhang7)
|
||||
- **Utils module exports** -- Proper `__init__.py` exports for the utils module. (@Siddharth2624)
|
||||
- **Increased default max_tokens** -- Opus 4.6 defaults to 32768, Sonnet 4.5 to 16384 (up from 8192). (@TimothyZhang7)
|
||||
|
||||
---
|
||||
|
||||
### Bug Fixes
|
||||
|
||||
- Flush WIP accumulator outputs on cancel/failure so edge conditions see correct values on resume
|
||||
- Stall detection state preserved across resume (no more resets on checkpoint restore)
|
||||
- Skip client-facing blocking for event-triggered executions (timer/webhook)
|
||||
- Executor retry override scoped to actual EventLoopNode instances only
|
||||
- Add `_awaiting_input` flag to EventLoopNode to prevent input injection race conditions
|
||||
- Fix TUI streaming display (tokens no longer appear one-per-line)
|
||||
- Fix `_return_from_escalation` crash when ChatRepl widgets not yet mounted
|
||||
- Fix tools registration problems for Google Docs credentials (@RichardTang-Aden)
|
||||
- Fix email agent version conflicts (@RichardTang-Aden)
|
||||
- Fix coder tool timeouts (120s for tests, 300s cap for commands)
|
||||
|
||||
### Documentation
|
||||
|
||||
- Clarify installation and prevent root pip install misuse (@paarths-collab)
|
||||
|
||||
---
|
||||
|
||||
### Agent Updates
|
||||
|
||||
- **Email Inbox Management** -- Consolidate `gmail_inbox_guardian` and `inbox_management` into a single unified agent with updated prompts and config. (@RichardTang-Aden, @bryanadenhq)
|
||||
- **Job Hunter** -- Updated node prompts, config, and agent metadata; added PDF resume selection. (@bryanadenhq)
|
||||
- **Deep Research Agent** -- Revised node implementations with updated prompts and output handling.
|
||||
- **Tech News Reporter** -- Revised node prompts for improved output quality.
|
||||
- **Vulnerability Assessment** -- Expanded prompts with more detailed assessment instructions. (@bryanadenhq)
|
||||
|
||||
---
|
||||
|
||||
### Breaking Changes
|
||||
|
||||
- **Deprecated node types raise `RuntimeError`** -- `llm_tool_use`, `llm_generate`, `function`, `router`, `human_input` now fail instead of warning. Migrate to `event_loop`.
|
||||
- **`NodeSpec.node_type` defaults to `"event_loop"`** (was `"llm_tool_use"`)
|
||||
- **`NodeSpec.max_node_visits` defaults to `0` / unlimited** (was `1`)
|
||||
- **`NodeSpec.function` field removed** -- `FunctionNode` is deleted; use event_loop nodes with tools instead.
|
||||
|
||||
---
|
||||
|
||||
### Community Contributors
|
||||
|
||||
A huge thank you to everyone who contributed to this release:
|
||||
|
||||
- **Richard Tang** (@RichardTang-Aden) -- Interactive credential setup, pre-start confirmation, email agent consolidation, tool registration fixes, lint and formatting
|
||||
- **Pravin Mishra** (@mishrapravin114) -- Discord integration with 4 MCP tools
|
||||
- **Jeet Karia** (@JeetKaria06) -- Exa Search API integration with 4 AI-powered search tools
|
||||
- **Shivam Shahi** (@shivamshahi07) -- Razorpay payment processing integration
|
||||
- **Siddharth Varshney** (@Siddharth2624) -- Utils module exports
|
||||
- **@haliaeetusvocifer** -- Google Docs integration with OAuth support
|
||||
- **Bryan** (@bryanadenhq) -- PDF selection, inbox agent fixes, Job Hunter and Vulnerability Assessment updates
|
||||
- **@paarths-collab** -- Documentation improvements
|
||||
|
||||
---
|
||||
|
||||
### Upgrading
|
||||
|
||||
```bash
|
||||
git pull origin main
|
||||
uv sync
|
||||
```
|
||||
|
||||
#### Migration Guide
|
||||
|
||||
If your agents use deprecated node types, update them:
|
||||
|
||||
```python
|
||||
# Before (v0.5.0) -- these now raise RuntimeError
|
||||
NodeSpec(node_type="llm_tool_use", ...)
|
||||
NodeSpec(node_type="function", function=my_func, ...)
|
||||
|
||||
# After (v0.5.1) -- use event_loop for everything
|
||||
NodeSpec(node_type="event_loop", ...) # or just omit node_type (it's the default now)
|
||||
```
|
||||
|
||||
If your agents set `max_node_visits=1` explicitly, they'll still work. The only change is the _default_ -- new agents without an explicit value now get unlimited visits.
|
||||
|
||||
To try the new Hive Coder:
|
||||
|
||||
```bash
|
||||
# Launch Coder directly
|
||||
hive code
|
||||
|
||||
# Or from TUI -- press Ctrl+E to escalate
|
||||
hive tui
|
||||
```
|
||||
|
||||
+1046
-27
File diff suppressed because it is too large
Load Diff
@@ -1,495 +0,0 @@
|
||||
# Agent Development Environment Setup
|
||||
|
||||
Complete setup guide for building and running goal-driven agents with the Aden Agent Framework.
|
||||
|
||||
## Quick Setup
|
||||
|
||||
```bash
|
||||
# Run the automated setup script
|
||||
./quickstart.sh
|
||||
```
|
||||
|
||||
> **Note for Windows Users:**
|
||||
> Running the setup script on native Windows shells (PowerShell / Git Bash) may sometimes fail due to Python App Execution Aliases.
|
||||
> It is **strongly recommended to use WSL (Windows Subsystem for Linux)** for a smoother setup experience.
|
||||
|
||||
This will:
|
||||
|
||||
- Check Python version (requires 3.11+)
|
||||
- Install the core framework package (`framework`)
|
||||
- Install the tools package (`aden_tools`)
|
||||
- Fix package compatibility issues (openai + litellm)
|
||||
- Verify all installations
|
||||
|
||||
## Alpine Linux Setup
|
||||
|
||||
If you are using Alpine Linux (e.g., inside a Docker container), you must install system dependencies and use a virtual environment before running the setup script:
|
||||
|
||||
1. Install System Dependencies:
|
||||
```bash
|
||||
apk update
|
||||
apk add bash git python3 py3-pip nodejs npm curl build-base python3-dev linux-headers libffi-dev
|
||||
```
|
||||
2. Set up Virtual Environment (Required for Python 3.12+):
|
||||
```
|
||||
python3 -m venv venv
|
||||
source venv/bin/activate
|
||||
pip install --upgrade pip setuptools wheel
|
||||
```
|
||||
3. Run the Quickstart Script:
|
||||
```
|
||||
./quickstart.sh
|
||||
```
|
||||
|
||||
## Manual Setup (Alternative)
|
||||
|
||||
If you prefer to set up manually or the script fails:
|
||||
|
||||
### 1. Install Core Framework
|
||||
|
||||
```bash
|
||||
cd core
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
### 2. Install Tools Package
|
||||
|
||||
```bash
|
||||
cd tools
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
### 3. Upgrade OpenAI Package
|
||||
|
||||
```bash
|
||||
# litellm requires openai >= 1.0.0
|
||||
pip install --upgrade "openai>=1.0.0"
|
||||
```
|
||||
|
||||
### 4. Verify Installation
|
||||
|
||||
```bash
|
||||
python -c "import framework; print('✓ framework OK')"
|
||||
python -c "import aden_tools; print('✓ aden_tools OK')"
|
||||
python -c "import litellm; print('✓ litellm OK')"
|
||||
```
|
||||
|
||||
> **Windows Tip:**
|
||||
> On Windows, if the verification commands fail, ensure you are running them in **WSL** or after **disabling Python App Execution Aliases** in Windows Settings → Apps → App Execution Aliases.
|
||||
|
||||
## Requirements
|
||||
|
||||
### Python Version
|
||||
|
||||
- **Minimum:** Python 3.11
|
||||
- **Recommended:** Python 3.11 or 3.12
|
||||
- **Tested on:** Python 3.11, 3.12, 3.13
|
||||
|
||||
### System Requirements
|
||||
|
||||
- pip (latest version)
|
||||
- 2GB+ RAM
|
||||
- Internet connection (for LLM API calls)
|
||||
- For Windows users: WSL 2 is recommended for full compatibility.
|
||||
|
||||
### API Keys (Optional)
|
||||
|
||||
For running agents with real LLMs:
|
||||
|
||||
```bash
|
||||
export ANTHROPIC_API_KEY="your-key-here"
|
||||
```
|
||||
|
||||
## Running Agents
|
||||
|
||||
All agent commands must be run from the project root with `PYTHONPATH` set:
|
||||
|
||||
```bash
|
||||
# From /hive/ directory
|
||||
PYTHONPATH=core:exports python -m agent_name COMMAND
|
||||
```
|
||||
|
||||
### Example Commands
|
||||
|
||||
After building an agent via `/building-agents-construction`, use these commands:
|
||||
|
||||
```bash
|
||||
# Validate agent structure
|
||||
PYTHONPATH=core:exports python -m your_agent_name validate
|
||||
|
||||
# Show agent information
|
||||
PYTHONPATH=core:exports python -m your_agent_name info
|
||||
|
||||
# Run agent with input
|
||||
PYTHONPATH=core:exports python -m your_agent_name run --input '{
|
||||
"task": "Your input here"
|
||||
}'
|
||||
|
||||
# Run in mock mode (no LLM calls)
|
||||
PYTHONPATH=core:exports python -m your_agent_name run --mock --input '{...}'
|
||||
```
|
||||
|
||||
## Building New Agents and Run Flow
|
||||
|
||||
Build and run an agent using Claude Code CLI with the agent building skills:
|
||||
|
||||
### 1. Install Claude Skills (One-time)
|
||||
|
||||
```bash
|
||||
./quickstart.sh
|
||||
```
|
||||
|
||||
This verifies agent-related Claude Code skills are available:
|
||||
|
||||
- `/building-agents-construction` - Step-by-step build guide
|
||||
- `/building-agents-core` - Fundamental concepts
|
||||
- `/building-agents-patterns` - Best practices
|
||||
- `/testing-agent` - Test and validate agents
|
||||
- `/agent-workflow` - Complete workflow
|
||||
|
||||
### 2. Build an Agent
|
||||
|
||||
```
|
||||
claude> /building-agents-construction
|
||||
```
|
||||
|
||||
Follow the prompts to:
|
||||
|
||||
1. Define your agent's goal
|
||||
2. Design the workflow nodes
|
||||
3. Connect nodes with edges
|
||||
4. Generate the agent package under `exports/`
|
||||
|
||||
This step creates the initial agent structure required for further development.
|
||||
|
||||
### 3. Define Agent Logic
|
||||
|
||||
```
|
||||
claude> /building-agents-core
|
||||
```
|
||||
|
||||
Follow the prompts to:
|
||||
|
||||
1. Understand the agent architecture and file structure
|
||||
2. Define the agent's goal, success criteria, and constraints
|
||||
3. Learn node types (LLM, tool-use, router, function)
|
||||
4. Discover and validate available tools before use
|
||||
|
||||
This step establishes the core concepts and rules needed before building an agent.
|
||||
|
||||
### 4. Apply Agent Patterns
|
||||
|
||||
```
|
||||
claude> /building-agents-patterns
|
||||
```
|
||||
|
||||
Follow the prompts to:
|
||||
|
||||
1. Apply best-practice agent design patterns
|
||||
2. Add pause/resume flows for multi-turn interactions
|
||||
3. Improve robustness with routing, fallbacks, and retries
|
||||
4. Avoid common anti-patterns during agent construction
|
||||
|
||||
This step helps optimize agent design before final testing.
|
||||
|
||||
### 5. Test Your Agent
|
||||
|
||||
```
|
||||
claude> /testing-agent
|
||||
```
|
||||
Follow the prompts to:
|
||||
|
||||
1. Generate test guidelines for constraints and success criteria
|
||||
2. Write agent tests directly under `exports/{agent}/tests/`
|
||||
3. Run goal-based evaluation tests
|
||||
4. Debug failing tests and iterate on agent improvements
|
||||
|
||||
This step verifies that the agent meets its goals before production use.
|
||||
|
||||
### 6. Agent Development Workflow (End-to-End)
|
||||
|
||||
```
|
||||
claude> /agent-workflow
|
||||
```
|
||||
|
||||
Follow the guided flow to:
|
||||
|
||||
1. Understand core agent concepts (optional)
|
||||
2. Build the agent structure step by step
|
||||
3. Apply best-practice design patterns (optional)
|
||||
4. Test and validate the agent against its goals
|
||||
|
||||
This workflow orchestrates all agent-building skills to take you from idea → production-ready agent.
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### "externally-managed-environment" error (PEP 668)
|
||||
|
||||
**Cause:** Python 3.12+ on macOS/Homebrew, WSL, or some Linux distros prevents system-wide pip installs.
|
||||
|
||||
**Solution:** Create and use a virtual environment:
|
||||
|
||||
```bash
|
||||
# Create virtual environment
|
||||
python3 -m venv .venv
|
||||
|
||||
# Activate it
|
||||
source .venv/bin/activate # macOS/Linux
|
||||
# .venv\Scripts\activate # Windows
|
||||
|
||||
# Then run setup
|
||||
./quickstart.sh
|
||||
```
|
||||
|
||||
Always activate the venv before running agents:
|
||||
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
PYTHONPATH=core:exports python -m your_agent_name demo
|
||||
```
|
||||
|
||||
### "ModuleNotFoundError: No module named 'framework'"
|
||||
|
||||
**Solution:** Install the core package:
|
||||
|
||||
```bash
|
||||
cd core && pip install -e .
|
||||
```
|
||||
|
||||
### "ModuleNotFoundError: No module named 'aden_tools'"
|
||||
|
||||
**Solution:** Install the tools package:
|
||||
|
||||
```bash
|
||||
cd tools && pip install -e .
|
||||
```
|
||||
|
||||
Or run the setup script:
|
||||
|
||||
```bash
|
||||
./quickstart.sh
|
||||
```
|
||||
|
||||
### "ModuleNotFoundError: No module named 'openai.\_models'"
|
||||
|
||||
**Cause:** Outdated `openai` package (0.27.x) incompatible with `litellm`
|
||||
|
||||
**Solution:** Upgrade openai:
|
||||
|
||||
```bash
|
||||
pip install --upgrade "openai>=1.0.0"
|
||||
```
|
||||
|
||||
### "No module named 'your_agent_name'"
|
||||
|
||||
**Cause:** Not running from project root, missing PYTHONPATH, or agent not yet created
|
||||
|
||||
**Solution:** Ensure you're in the project root directory, have built an agent, and use:
|
||||
|
||||
```bash
|
||||
PYTHONPATH=core:exports python -m your_agent_name validate
|
||||
```
|
||||
|
||||
### Agent imports fail with "broken installation"
|
||||
|
||||
**Symptom:** `pip list` shows packages pointing to non-existent directories
|
||||
|
||||
**Solution:** Reinstall packages properly:
|
||||
|
||||
```bash
|
||||
# Remove broken installations
|
||||
pip uninstall -y framework tools
|
||||
|
||||
# Reinstall correctly
|
||||
./quickstart.sh
|
||||
```
|
||||
|
||||
## Package Structure
|
||||
|
||||
The Hive framework consists of three Python packages:
|
||||
|
||||
```
|
||||
hive/
|
||||
├── core/ # Core framework (runtime, graph executor, LLM providers)
|
||||
│ ├── framework/
|
||||
│ ├── .venv/ # Created by quickstart.sh
|
||||
│ └── pyproject.toml
|
||||
│
|
||||
├── tools/ # Tools and MCP servers
|
||||
│ ├── src/
|
||||
│ │ └── aden_tools/ # Actual package location
|
||||
│ ├── .venv/ # Created by quickstart.sh
|
||||
│ └── pyproject.toml
|
||||
│
|
||||
└── exports/ # Agent packages (user-created, gitignored)
|
||||
└── your_agent_name/ # Created via /building-agents-construction
|
||||
```
|
||||
|
||||
## Separate Virtual Environments
|
||||
|
||||
The project uses **separate virtual environments** for `core` and `tools` packages to:
|
||||
|
||||
- Isolate dependencies and avoid conflicts
|
||||
- Allow independent development and testing of each package
|
||||
- Enable MCP servers to run with their specific dependencies
|
||||
|
||||
### How It Works
|
||||
|
||||
When you run `./quickstart.sh` or `uv sync` in each directory:
|
||||
|
||||
1. **core/.venv/** - Contains the `framework` package and its dependencies (anthropic, litellm, mcp, etc.)
|
||||
2. **tools/.venv/** - Contains the `aden_tools` package and its dependencies (beautifulsoup4, pandas, etc.)
|
||||
|
||||
### Cross-Package Imports
|
||||
|
||||
The `core` and `tools` packages are **intentionally independent**:
|
||||
|
||||
- **No cross-imports**: `framework` does not import `aden_tools` directly, and vice versa
|
||||
- **Communication via MCP**: Tools are exposed to agents through MCP servers, not direct Python imports
|
||||
- **Runtime integration**: The agent runner loads tools via the MCP protocol at runtime
|
||||
|
||||
If you need to use both packages in a single script (e.g., for testing), you have two options:
|
||||
|
||||
```bash
|
||||
# Option 1: Install both in a shared environment
|
||||
python -m venv .venv
|
||||
source .venv/bin/activate
|
||||
pip install -e core/ -e tools/
|
||||
|
||||
# Option 2: Use PYTHONPATH (for quick testing)
|
||||
PYTHONPATH=core:tools/src python your_script.py
|
||||
```
|
||||
|
||||
### MCP Server Configuration
|
||||
|
||||
The `.mcp.json` at project root configures MCP servers to use their respective virtual environments:
|
||||
|
||||
```json
|
||||
{
|
||||
"mcpServers": {
|
||||
"agent-builder": {
|
||||
"command": "core/.venv/bin/python",
|
||||
"args": ["-m", "framework.mcp.agent_builder_server"]
|
||||
},
|
||||
"tools": {
|
||||
"command": "tools/.venv/bin/python",
|
||||
"args": ["-m", "aden_tools.mcp_server", "--stdio"]
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This ensures each MCP server runs with its correct dependencies.
|
||||
|
||||
### Why PYTHONPATH is Required
|
||||
|
||||
The packages are installed in **editable mode** (`pip install -e`), which means:
|
||||
|
||||
- `framework` and `aden_tools` are globally importable (no PYTHONPATH needed)
|
||||
- `exports` is NOT installed as a package (PYTHONPATH required)
|
||||
|
||||
This design allows agents in `exports/` to be:
|
||||
|
||||
- Developed independently
|
||||
- Version controlled separately
|
||||
- Deployed as standalone packages
|
||||
|
||||
## Development Workflow
|
||||
|
||||
### 1. Setup (Once)
|
||||
|
||||
```bash
|
||||
./quickstart.sh
|
||||
```
|
||||
|
||||
### 2. Build Agent (Claude Code)
|
||||
|
||||
```
|
||||
claude> /building-agents-construction
|
||||
Enter goal: "Build an agent that processes customer support tickets"
|
||||
```
|
||||
|
||||
### 3. Validate Agent
|
||||
|
||||
```bash
|
||||
PYTHONPATH=core:exports python -m your_agent_name validate
|
||||
```
|
||||
|
||||
### 4. Test Agent
|
||||
|
||||
```
|
||||
claude> /testing-agent
|
||||
```
|
||||
|
||||
### 5. Run Agent
|
||||
|
||||
```bash
|
||||
PYTHONPATH=core:exports python -m your_agent_name run --input '{...}'
|
||||
```
|
||||
|
||||
## IDE Setup
|
||||
|
||||
### VSCode
|
||||
|
||||
Add to `.vscode/settings.json`:
|
||||
|
||||
```json
|
||||
{
|
||||
"python.analysis.extraPaths": [
|
||||
"${workspaceFolder}/core",
|
||||
"${workspaceFolder}/exports"
|
||||
],
|
||||
"python.autoComplete.extraPaths": [
|
||||
"${workspaceFolder}/core",
|
||||
"${workspaceFolder}/exports"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### PyCharm
|
||||
|
||||
1. Open Project Settings → Project Structure
|
||||
2. Mark `core` as Sources Root
|
||||
3. Mark `exports` as Sources Root
|
||||
|
||||
## Environment Variables
|
||||
|
||||
### Required for LLM Operations
|
||||
|
||||
```bash
|
||||
export ANTHROPIC_API_KEY="sk-ant-..."
|
||||
```
|
||||
|
||||
### Optional Configuration
|
||||
|
||||
```bash
|
||||
# Credentials storage location (default: ~/.aden/credentials)
|
||||
export ADEN_CREDENTIALS_PATH="/custom/path"
|
||||
|
||||
# Agent storage location (default: /tmp)
|
||||
export AGENT_STORAGE_PATH="/custom/storage"
|
||||
```
|
||||
|
||||
## Additional Resources
|
||||
|
||||
- **Framework Documentation:** [core/README.md](core/README.md)
|
||||
- **Tools Documentation:** [tools/README.md](tools/README.md)
|
||||
- **Example Agents:** [exports/](exports/)
|
||||
- **Agent Building Guide:** [.claude/skills/building-agents-construction/SKILL.md](.claude/skills/building-agents-construction/SKILL.md)
|
||||
- **Testing Guide:** [.claude/skills/testing-agent/SKILL.md](.claude/skills/testing-agent/SKILL.md)
|
||||
|
||||
## Contributing
|
||||
|
||||
When contributing agent packages:
|
||||
|
||||
1. Place agents in `exports/agent_name/`
|
||||
2. Follow the standard agent structure (see existing agents)
|
||||
3. Include README.md with usage instructions
|
||||
4. Add tests if using `/testing-agent`
|
||||
5. Document required environment variables
|
||||
|
||||
## Support
|
||||
|
||||
- **Issues:** https://github.com/adenhq/hive/issues
|
||||
- **Discord:** https://discord.com/invite/MXE49hrKDk
|
||||
- **Documentation:** https://docs.adenhq.com/
|
||||
@@ -1,26 +1,56 @@
|
||||
.PHONY: lint format check test install-hooks help
|
||||
.PHONY: lint format check test test-tools test-live test-all install-hooks help frontend-install frontend-dev frontend-build
|
||||
|
||||
# ── Ensure uv is findable in Git Bash on Windows ──────────────────────────────
|
||||
# uv installs to ~/.local/bin on Windows/Linux/macOS. Git Bash may not include
|
||||
# this in PATH by default, so we prepend it here.
|
||||
export PATH := $(HOME)/.local/bin:$(PATH)
|
||||
|
||||
# ── Targets ───────────────────────────────────────────────────────────────────
|
||||
|
||||
help: ## Show this help
|
||||
@grep -E '^[a-zA-Z_-]+:.*?## .*$$' $(MAKEFILE_LIST) | \
|
||||
awk 'BEGIN {FS = ":.*?## "}; {printf " \033[36m%-15s\033[0m %s\n", $$1, $$2}'
|
||||
|
||||
lint: ## Run ruff linter (with auto-fix)
|
||||
cd core && ruff check --fix .
|
||||
cd tools && ruff check --fix .
|
||||
lint: ## Run ruff linter and formatter (with auto-fix)
|
||||
cd core && uv run ruff check --fix .
|
||||
cd tools && uv run ruff check --fix .
|
||||
cd core && uv run ruff format .
|
||||
cd tools && uv run ruff format .
|
||||
|
||||
format: ## Run ruff formatter
|
||||
cd core && ruff format .
|
||||
cd tools && ruff format .
|
||||
cd core && uv run ruff format .
|
||||
cd tools && uv run ruff format .
|
||||
|
||||
check: ## Run all checks without modifying files (CI-safe)
|
||||
cd core && ruff check .
|
||||
cd tools && ruff check .
|
||||
cd core && ruff format --check .
|
||||
cd tools && ruff format --check .
|
||||
cd core && uv run ruff check .
|
||||
cd tools && uv run ruff check .
|
||||
cd core && uv run ruff format --check .
|
||||
cd tools && uv run ruff format --check .
|
||||
|
||||
test: ## Run all tests
|
||||
cd core && python -m pytest tests/ -v
|
||||
test: ## Run all tests (core + tools, excludes live)
|
||||
cd core && uv run python -m pytest tests/ -v
|
||||
cd tools && uv run python -m pytest -v
|
||||
|
||||
test-tools: ## Run tool tests only (mocked, no credentials needed)
|
||||
cd tools && uv run python -m pytest -v
|
||||
|
||||
test-live: ## Run live integration tests (requires real API credentials)
|
||||
cd tools && uv run python -m pytest -m live -s -o "addopts=" --log-cli-level=INFO
|
||||
|
||||
test-all: ## Run everything including live tests
|
||||
cd core && uv run python -m pytest tests/ -v
|
||||
cd tools && uv run python -m pytest -v
|
||||
cd tools && uv run python -m pytest -m live -s -o "addopts=" --log-cli-level=INFO
|
||||
|
||||
install-hooks: ## Install pre-commit hooks
|
||||
pip install pre-commit
|
||||
uv pip install pre-commit
|
||||
pre-commit install
|
||||
|
||||
frontend-install: ## Install frontend npm packages
|
||||
cd core/frontend && npm install
|
||||
|
||||
frontend-dev: ## Start frontend dev server
|
||||
cd core/frontend && npm run dev
|
||||
|
||||
frontend-build: ## Build frontend for production
|
||||
cd core/frontend && npm run build
|
||||
@@ -1,51 +0,0 @@
|
||||
## Summary
|
||||
- **Added HubSpot integration** — new HubSpot MCP tool with search, get, create, and update operations for contacts, companies, and deals. Includes OAuth2 provider for HubSpot credentials and credential store adapter for the tools layer.
|
||||
- **Replaced web_scrape tool with Playwright + stealth** — swapped httpx/BeautifulSoup for a headless Chromium browser using `playwright` (async API) and `playwright-stealth`, enabling JS-rendered page scraping and bot detection evasion
|
||||
- **Added empty response retry logic** — LLM provider now detects empty responses (e.g. Gemini returning 200 with no content on rate limit) and retries with exponential backoff, preventing hallucinated output from the cleanup LLM
|
||||
- **Added context-aware input compaction** — LLM nodes now estimate input token count before calling the model and progressively truncate the largest values if they exceed the context window budget
|
||||
- **Increased rate limit retries to 10** with verbose `[retry]` and `[compaction]` logging that includes model name, finish reason, and attempt count
|
||||
- **Updated setup scripts** — `scripts/setup-python.sh` now installs Playwright Chromium browser automatically for web scraping support
|
||||
- **Interactive quickstart onboarding** — `quickstart.sh` rewritten as bee-themed interactive wizard that detects existing API keys (including Claude Code subscription), lets user pick ONE default LLM provider, and saves configuration to `~/.hive/configuration.json`
|
||||
- **Fixed lint errors** across `hubspot_tool.py` (line length) and `agent_builder_server.py` (unused variable)
|
||||
|
||||
## Changed files
|
||||
|
||||
### HubSpot Integration
|
||||
- `tools/src/aden_tools/tools/hubspot_tool/` — New MCP tool: contacts, companies, and deals CRUD
|
||||
- `tools/src/aden_tools/tools/__init__.py` — Registered HubSpot tools
|
||||
- `tools/src/aden_tools/credentials/integrations.py` — HubSpot credential integration
|
||||
- `tools/src/aden_tools/credentials/__init__.py` — Updated credential exports
|
||||
- `core/framework/credentials/oauth2/hubspot_provider.py` — HubSpot OAuth2 provider
|
||||
- `core/framework/credentials/oauth2/__init__.py` — Registered HubSpot OAuth2 provider
|
||||
- `core/framework/runner/runner.py` — Updated runner for credential support
|
||||
|
||||
### Web Scrape Rewrite
|
||||
- `tools/src/aden_tools/tools/web_scrape_tool/web_scrape_tool.py` — Playwright async rewrite
|
||||
- `tools/src/aden_tools/tools/web_scrape_tool/README.md` — Updated docs
|
||||
- `tools/pyproject.toml` — Added `playwright`, `playwright-stealth` deps
|
||||
- `tools/Dockerfile` — Added `playwright install chromium --with-deps`
|
||||
- `scripts/setup-python.sh` — Added Playwright Chromium browser install step
|
||||
|
||||
### LLM Reliability
|
||||
- `core/framework/llm/litellm.py` — Empty response retry + max retries 10 + verbose logging
|
||||
- `core/framework/graph/node.py` — Input compaction via `_compact_inputs()`, `_estimate_tokens()`, `_get_context_limit()`
|
||||
|
||||
### Quickstart & Setup
|
||||
- `quickstart.sh` — Interactive bee-themed onboarding wizard with single provider selection
|
||||
- `~/.hive/configuration.json` — New user config file for default LLM provider/model
|
||||
|
||||
### Fixes
|
||||
- `core/framework/mcp/agent_builder_server.py` — Removed unused variable
|
||||
- `tools/src/aden_tools/tools/hubspot_tool/hubspot_tool.py` — Fixed E501 line length violations
|
||||
|
||||
## Test plan
|
||||
- [ ] Run `make lint` — passes clean
|
||||
- [ ] Run `./quickstart.sh` and verify interactive flow works, config saved to `~/.hive/configuration.json`
|
||||
- [ ] Run `./scripts/setup-python.sh` and verify Playwright Chromium installs
|
||||
- [ ] Run `pytest tests/tools/test_web_scrape_tool.py -v`
|
||||
- [ ] Run agent against a JS-heavy site and verify `web_scrape` returns rendered content
|
||||
- [ ] Set `HUBSPOT_ACCESS_TOKEN` and verify HubSpot tool CRUD operations work
|
||||
- [ ] Trigger rate limit and verify `[retry]` logs appear with correct attempt counts
|
||||
- [ ] Run agent with large inputs and verify `[compaction]` logs show truncation
|
||||
|
||||
🤖 Generated with [Claude Code](https://claude.com/claude-code)
|
||||
@@ -1,5 +1,5 @@
|
||||
<p align="center">
|
||||
<img width="100%" alt="Hive Banner" src="https://storage.googleapis.com/aden-prod-assets/website/aden-title-card.png" />
|
||||
<img width="100%" alt="Hive Banner" src="https://github.com/user-attachments/assets/a027429b-5d3c-4d34-88e4-0feaeaabbab3" />
|
||||
</p>
|
||||
|
||||
<p align="center">
|
||||
@@ -13,112 +13,142 @@
|
||||
<a href="docs/i18n/ko.md">한국어</a>
|
||||
</p>
|
||||
|
||||
[](https://github.com/adenhq/hive/blob/main/LICENSE)
|
||||
[](https://www.ycombinator.com/companies/aden)
|
||||
[](https://hub.docker.com/u/adenhq)
|
||||
[](https://discord.com/invite/MXE49hrKDk)
|
||||
[](https://x.com/aden_hq)
|
||||
[](https://www.linkedin.com/company/teamaden/)
|
||||
<p align="center">
|
||||
<a href="https://github.com/aden-hive/hive/blob/main/LICENSE"><img src="https://img.shields.io/badge/License-Apache%202.0-blue.svg" alt="Apache 2.0 License" /></a>
|
||||
<a href="https://www.ycombinator.com/companies/aden"><img src="https://img.shields.io/badge/Y%20Combinator-Aden-orange" alt="Y Combinator" /></a>
|
||||
<a href="https://discord.com/invite/MXE49hrKDk"><img src="https://img.shields.io/discord/1172610340073242735?logo=discord&labelColor=%235462eb&logoColor=%23f5f5f5&color=%235462eb" alt="Discord" /></a>
|
||||
<a href="https://x.com/aden_hq"><img src="https://img.shields.io/twitter/follow/teamaden?logo=X&color=%23f5f5f5" alt="Twitter Follow" /></a>
|
||||
<a href="https://www.linkedin.com/company/teamaden/"><img src="https://custom-icon-badges.demolab.com/badge/LinkedIn-0A66C2?logo=linkedin-white&logoColor=fff" alt="LinkedIn" /></a>
|
||||
<img src="https://img.shields.io/badge/MCP-102_Tools-00ADD8?style=flat-square" alt="MCP" />
|
||||
</p>
|
||||
|
||||
<p align="center">
|
||||
<img src="https://img.shields.io/badge/AI_Agents-Self--Improving-brightgreen?style=flat-square" alt="AI Agents" />
|
||||
<img src="https://img.shields.io/badge/Multi--Agent-Systems-blue?style=flat-square" alt="Multi-Agent" />
|
||||
<img src="https://img.shields.io/badge/Goal--Driven-Development-purple?style=flat-square" alt="Goal-Driven" />
|
||||
<img src="https://img.shields.io/badge/Headless-Development-purple?style=flat-square" alt="Headless" />
|
||||
<img src="https://img.shields.io/badge/Human--in--the--Loop-orange?style=flat-square" alt="HITL" />
|
||||
<img src="https://img.shields.io/badge/Production--Ready-red?style=flat-square" alt="Production" />
|
||||
<img src="https://img.shields.io/badge/Browser-Use-red?style=flat-square" alt="Browser Use" />
|
||||
</p>
|
||||
<p align="center">
|
||||
<img src="https://img.shields.io/badge/OpenAI-supported-412991?style=flat-square&logo=openai" alt="OpenAI" />
|
||||
<img src="https://img.shields.io/badge/Anthropic-supported-d4a574?style=flat-square" alt="Anthropic" />
|
||||
<img src="https://img.shields.io/badge/Google_Gemini-supported-4285F4?style=flat-square&logo=google" alt="Gemini" />
|
||||
<img src="https://img.shields.io/badge/MCP-19_Tools-00ADD8?style=flat-square" alt="MCP" />
|
||||
</p>
|
||||
|
||||
## Overview
|
||||
|
||||
Build reliable, self-improving AI agents without hardcoding workflows. Define your goal through conversation with a coding agent, and the framework generates a node graph with dynamically created connection code. When things break, the framework captures failure data, evolves the agent through the coding agent, and redeploys. Built-in human-in-the-loop nodes, credential management, and real-time monitoring give you control without sacrificing adaptability.
|
||||
Generate a swarm of worker agents with a coding agent(queen) that control them. Define your goal through conversation with hive queen, and the framework generates a node graph with dynamically created connection code. When things break, the framework captures failure data, evolves the agent through the coding agent, and redeploys. Built-in human-in-the-loop nodes, browser use, credential management, and real-time monitoring give you control without sacrificing adaptability.
|
||||
|
||||
Visit [adenhq.com](https://adenhq.com) for complete documentation, examples, and guides.
|
||||
|
||||
## What is Aden
|
||||
[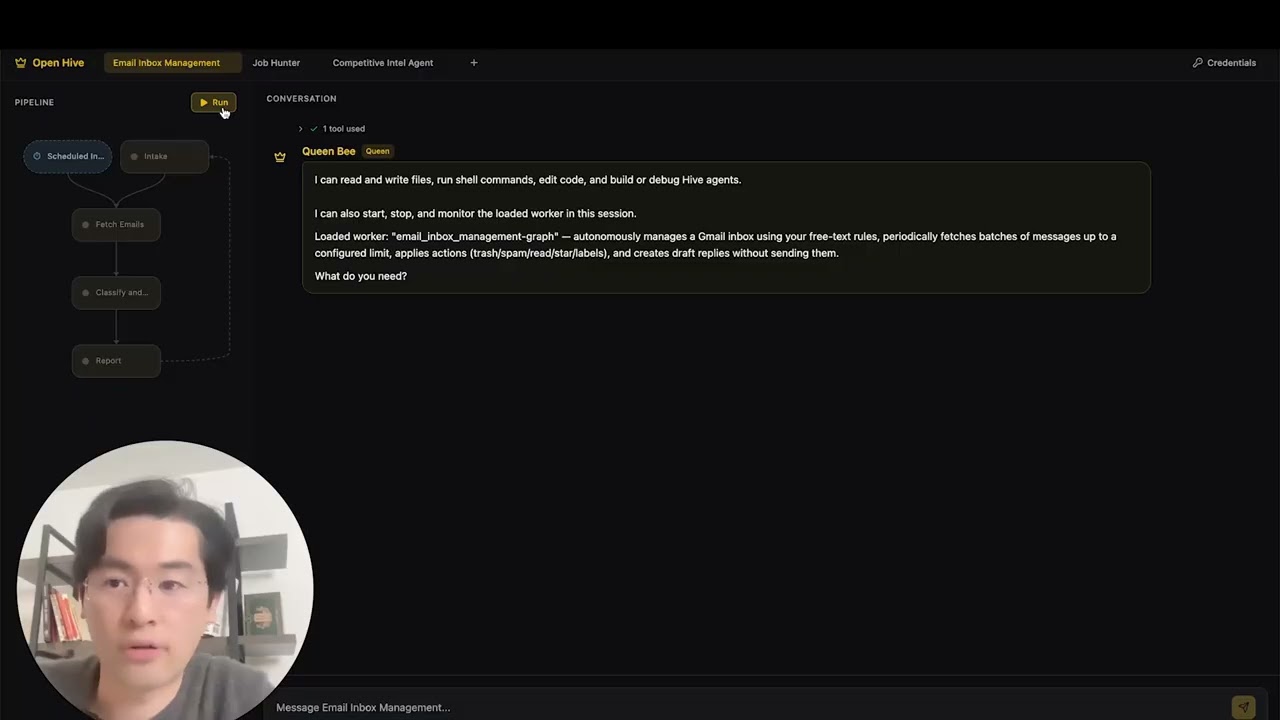](https://www.youtube.com/watch?v=XDOG9fOaLjU)
|
||||
|
||||
<p align="center">
|
||||
<img width="100%" alt="Aden Architecture" src="docs/assets/aden-architecture-diagram.jpg" />
|
||||
</p>
|
||||
## Who Is Hive For?
|
||||
|
||||
Aden is a platform for building, deploying, operating, and adapting AI agents:
|
||||
Hive is designed for developers and teams who want to build many **autonomous AI agents** fast without manually wiring complex workflows.
|
||||
|
||||
- **Build** - A Coding Agent generates specialized Worker Agents (Sales, Marketing, Ops) from natural language goals
|
||||
- **Deploy** - Headless deployment with CI/CD integration and full API lifecycle management
|
||||
- **Operate** - Real-time monitoring, observability, and runtime guardrails keep agents reliable
|
||||
- **Adapt** - Continuous evaluation, supervision, and adaptation ensure agents improve over time
|
||||
- **Infra** - Shared memory, LLM integrations, tools, and skills power every agent
|
||||
Hive is a good fit if you:
|
||||
|
||||
- Want AI agents that **execute real business processes**, not demos
|
||||
- Need **fast or high volume agent execution** over open workflow
|
||||
- Need **self-healing and adaptive agents** that improve over time
|
||||
- Require **human-in-the-loop control**, observability, and cost limits
|
||||
- Plan to run agents in **production environments**
|
||||
|
||||
Hive may not be the best fit if you’re only experimenting with simple agent chains or one-off scripts.
|
||||
|
||||
## When Should You Use Hive?
|
||||
|
||||
Use Hive when you need:
|
||||
|
||||
- Long-running, autonomous agents
|
||||
- Strong guardrails, process, and controls
|
||||
- Continuous improvement based on failures
|
||||
- Multi-agent coordination
|
||||
- A framework that evolves with your goals
|
||||
|
||||
## Quick Links
|
||||
|
||||
- **[Documentation](https://docs.adenhq.com/)** - Complete guides and API reference
|
||||
- **[Self-Hosting Guide](https://docs.adenhq.com/getting-started/quickstart)** - Deploy Hive on your infrastructure
|
||||
- **[Changelog](https://github.com/adenhq/hive/releases)** - Latest updates and releases
|
||||
<!-- - **[Roadmap](https://adenhq.com/roadmap)** - Upcoming features and plans -->
|
||||
- **[Changelog](https://github.com/aden-hive/hive/releases)** - Latest updates and releases
|
||||
- **[Roadmap](docs/roadmap.md)** - Upcoming features and plans
|
||||
- **[Report Issues](https://github.com/adenhq/hive/issues)** - Bug reports and feature requests
|
||||
- **[Contributing](CONTRIBUTING.md)** - How to contribute and submit PRs
|
||||
|
||||
## Quick Start
|
||||
|
||||
### Prerequisites
|
||||
|
||||
- [Python 3.11+](https://www.python.org/downloads/) for agent development
|
||||
- Claude Code or Cursor for utilizing agent skills
|
||||
- Python 3.11+ for agent development
|
||||
- An LLM provider that powers the agents
|
||||
- **ripgrep (optional, recommended on Windows):** The `search_files` tool uses ripgrep for faster file search. If not installed, a Python fallback is used. On Windows: `winget install BurntSushi.ripgrep` or `scoop install ripgrep`
|
||||
|
||||
> **Windows Users:** Native Windows is supported via `quickstart.ps1` and `hive.ps1`. Run these in PowerShell 5.1+. WSL is also an option but not required.
|
||||
|
||||
### Installation
|
||||
|
||||
> **Note**
|
||||
> Hive uses a `uv` workspace layout and is not installed with `pip install`.
|
||||
> Running `pip install -e .` from the repository root will create a placeholder package and Hive will not function correctly.
|
||||
> Please use the quickstart script below to set up the environment.
|
||||
|
||||
```bash
|
||||
# Clone the repository
|
||||
git clone https://github.com/adenhq/hive.git
|
||||
git clone https://github.com/aden-hive/hive.git
|
||||
cd hive
|
||||
|
||||
|
||||
# Run quickstart setup
|
||||
./quickstart.sh
|
||||
```
|
||||
|
||||
This sets up:
|
||||
|
||||
- **framework** - Core agent runtime and graph executor (in `core/.venv`)
|
||||
- **aden_tools** - MCP tools for agent capabilities (in `tools/.venv`)
|
||||
- All required Python dependencies
|
||||
- **credential store** - Encrypted API key storage (`~/.hive/credentials`)
|
||||
- **LLM provider** - Interactive default model configuration
|
||||
- All required Python dependencies with `uv`
|
||||
|
||||
- Finally, it will open the Hive interface in your browser
|
||||
|
||||
> **Tip:** To reopen the dashboard later, run `hive open` from the project directory.
|
||||
|
||||
### Build Your First Agent
|
||||
|
||||
```bash
|
||||
# Build an agent using Claude Code
|
||||
claude> /building-agents-construction
|
||||
Type the agent you want to build in the home input box. The queen is going to ask you questions and work out a solution with you.
|
||||
|
||||
# Test your agent
|
||||
claude> /testing-agent
|
||||
<img width="2500" height="1214" alt="Image" src="https://github.com/user-attachments/assets/1ce19141-a78b-46f5-8d64-dbf987e048f4" />
|
||||
|
||||
# Run your agent
|
||||
PYTHONPATH=core:exports python -m your_agent_name run --input '{...}'
|
||||
```
|
||||
### Use Template Agents
|
||||
|
||||
**[📖 Complete Setup Guide](ENVIRONMENT_SETUP.md)** - Detailed instructions for agent development
|
||||
Click "Try a sample agent" and check the templates. You can run a template directly or choose to build your version on top of the existing template.
|
||||
|
||||
### Cursor IDE Support
|
||||
### Run Agents
|
||||
|
||||
Skills are also available in Cursor. To enable:
|
||||
Now you can run an agent by selecting the agent (either an existing agent or example agent). You can click the Run button on the top left, or talk to the queen agent and it can run the agent for you.
|
||||
|
||||
1. Open Command Palette (`Cmd+Shift+P` / `Ctrl+Shift+P`)
|
||||
2. Run `MCP: Enable` to enable MCP servers
|
||||
3. Restart Cursor to load the MCP servers from `.cursor/mcp.json`
|
||||
4. Type `/` in Agent chat and search for skills (e.g., `/building-agents-construction`)
|
||||
<img width="2549" height="1174" alt="Screenshot 2026-03-12 at 9 27 36 PM" src="https://github.com/user-attachments/assets/7c7d30fa-9ceb-4c23-95af-b1caa405547d" />
|
||||
|
||||
## Features
|
||||
|
||||
- **Goal-Driven Development** - Define objectives in natural language; the coding agent generates the agent graph and connection code to achieve them
|
||||
- **Adaptiveness** - Framework captures failures, calibrates according to the objectives, and evolves the agent graph
|
||||
- **Dynamic Node Connections** - No predefined edges; connection code is generated by any capable LLM based on your goals
|
||||
- **Browser-Use** - Control the browser on your computer to achieve hard tasks
|
||||
- **Parallel Execution** - Execute the generated graph in parallel. This way you can have multiple agents completing the jobs for you
|
||||
- **[Goal-Driven Generation](docs/key_concepts/goals_outcome.md)** - Define objectives in natural language; the coding agent generates the agent graph and connection code to achieve them
|
||||
- **[Adaptiveness](docs/key_concepts/evolution.md)** - Framework captures failures, calibrates according to the objectives, and evolves the agent graph
|
||||
- **[Dynamic Node Connections](docs/key_concepts/graph.md)** - No predefined edges; connection code is generated by any capable LLM based on your goals
|
||||
- **SDK-Wrapped Nodes** - Every node gets shared memory, local RLM memory, monitoring, tools, and LLM access out of the box
|
||||
- **Human-in-the-Loop** - Intervention nodes that pause execution for human input with configurable timeouts and escalation
|
||||
- **[Human-in-the-Loop](docs/key_concepts/graph.md#human-in-the-loop)** - Intervention nodes that pause execution for human input with configurable timeouts and escalation
|
||||
- **Real-time Observability** - WebSocket streaming for live monitoring of agent execution, decisions, and node-to-node communication
|
||||
- **Cost & Budget Control** - Set spending limits, throttles, and automatic model degradation policies
|
||||
- **Production-Ready** - Self-hostable, built for scale and reliability
|
||||
|
||||
## Integration
|
||||
|
||||
<a href="https://github.com/aden-hive/hive/tree/main/tools/src/aden_tools/tools"><img width="100%" alt="Integration" src="https://github.com/user-attachments/assets/a1573f93-cf02-4bb8-b3d5-b305b05b1e51" /></a>
|
||||
Hive is built to be model-agnostic and system-agnostic.
|
||||
|
||||
- **LLM flexibility** - Hive Framework is designed to support various types of LLMs, including hosted and local models through LiteLLM-compatible providers.
|
||||
- **Business system connectivity** - Hive Framework is designed to connect to all kinds of business systems as tools, such as CRM, support, messaging, data, file, and internal APIs via MCP.
|
||||
|
||||
## Why Aden
|
||||
|
||||
@@ -156,161 +186,161 @@ flowchart LR
|
||||
style V6 fill:#fff,stroke:#ed8c00,stroke-width:1px,color:#cc5d00
|
||||
```
|
||||
|
||||
### The Aden Advantage
|
||||
### The Hive Advantage
|
||||
|
||||
| Traditional Frameworks | Aden |
|
||||
| Traditional Frameworks | Hive |
|
||||
| -------------------------- | -------------------------------------- |
|
||||
| Hardcode agent workflows | Describe goals in natural language |
|
||||
| Manual graph definition | Auto-generated agent graphs |
|
||||
| Reactive error handling | Outcome-evaluation and adaptiveness |
|
||||
| Reactive error handling | Outcome-evaluation and adaptiveness |
|
||||
| Static tool configurations | Dynamic SDK-wrapped nodes |
|
||||
| Separate monitoring setup | Built-in real-time observability |
|
||||
| DIY budget management | Integrated cost controls & degradation |
|
||||
|
||||
### How It Works
|
||||
|
||||
1. **Define Your Goal** → Describe what you want to achieve in plain English
|
||||
2. **Coding Agent Generates** → Creates the agent graph, connection code, and test cases
|
||||
3. **Workers Execute** → SDK-wrapped nodes run with full observability and tool access
|
||||
1. **[Define Your Goal](docs/key_concepts/goals_outcome.md)** → Describe what you want to achieve in plain English
|
||||
2. **Coding Agent Generates** → Creates the [agent graph](docs/key_concepts/graph.md), connection code, and test cases
|
||||
3. **[Workers Execute](docs/key_concepts/worker_agent.md)** → SDK-wrapped nodes run with full observability and tool access
|
||||
4. **Control Plane Monitors** → Real-time metrics, budget enforcement, policy management
|
||||
5. **Adaptiveness** → On failure, the system evolves the graph and redeploys automatically
|
||||
|
||||
## Run pre-built Agents (Coming Soon)
|
||||
|
||||
### Run a sample agent
|
||||
Aden Hive provides a list of featured agents that you can use and build on top of.
|
||||
|
||||
### Run an agent shared by others
|
||||
Put the agent in `exports/` and run `PYTHONPATH=core:exports python -m your_agent_name run --input '{...}'`
|
||||
|
||||
|
||||
For building and running goal-driven agents with the framework:
|
||||
|
||||
```bash
|
||||
# One-time setup
|
||||
./quickstart.sh
|
||||
|
||||
# This sets up:
|
||||
# - framework package (core runtime)
|
||||
# - aden_tools package (MCP tools)
|
||||
# - All Python dependencies
|
||||
|
||||
# Build new agents using Claude Code skills
|
||||
claude> /building-agents-construction
|
||||
|
||||
# Test agents
|
||||
claude> /testing-agent
|
||||
|
||||
# Run agents
|
||||
PYTHONPATH=core:exports python -m agent_name run --input '{...}'
|
||||
```
|
||||
|
||||
See [ENVIRONMENT_SETUP.md](ENVIRONMENT_SETUP.md) for complete setup instructions.
|
||||
5. **[Adaptiveness](docs/key_concepts/evolution.md)** → On failure, the system evolves the graph and redeploys automatically
|
||||
|
||||
## Documentation
|
||||
|
||||
- **[Developer Guide](DEVELOPER.md)** - Comprehensive guide for developers
|
||||
- **[Developer Guide](docs/developer-guide.md)** - Comprehensive guide for developers
|
||||
- [Getting Started](docs/getting-started.md) - Quick setup instructions
|
||||
- [Configuration Guide](docs/configuration.md) - All configuration options
|
||||
- [Architecture Overview](docs/architecture/README.md) - System design and structure
|
||||
|
||||
## Roadmap
|
||||
|
||||
Aden Hive Agent Framework aims to help developers build outcome-oriented, self-adaptive agents. See [ROADMAP.md](ROADMAP.md) for details.
|
||||
Aden Hive Agent Framework aims to help developers build outcome-oriented, self-adaptive agents. See [roadmap.md](docs/roadmap.md) for details.
|
||||
|
||||
```mermaid
|
||||
flowchart TD
|
||||
subgraph Foundation
|
||||
direction LR
|
||||
subgraph arch["Architecture"]
|
||||
a1["Node-Based Architecture"]:::done
|
||||
a2["Python SDK"]:::done
|
||||
a3["LLM Integration"]:::done
|
||||
a4["Communication Protocol"]:::done
|
||||
end
|
||||
subgraph ca["Coding Agent"]
|
||||
b1["Goal Creation Session"]:::done
|
||||
b2["Worker Agent Creation"]
|
||||
b3["MCP Tools"]:::done
|
||||
end
|
||||
subgraph wa["Worker Agent"]
|
||||
c1["Human-in-the-Loop"]:::done
|
||||
c2["Callback Handlers"]:::done
|
||||
c3["Intervention Points"]:::done
|
||||
c4["Streaming Interface"]
|
||||
end
|
||||
subgraph cred["Credentials"]
|
||||
d1["Setup Process"]:::done
|
||||
d2["Pluggable Sources"]:::done
|
||||
d3["Enterprise Secrets"]
|
||||
d4["Integration Tools"]:::done
|
||||
end
|
||||
subgraph tools["Tools"]
|
||||
e1["File Use"]:::done
|
||||
e2["Memory STM/LTM"]:::done
|
||||
e3["Web Search/Scraper"]:::done
|
||||
e4["CSV/PDF"]:::done
|
||||
e5["Excel/Email"]
|
||||
end
|
||||
subgraph core["Core"]
|
||||
f1["Eval System"]
|
||||
f2["Pydantic Validation"]:::done
|
||||
f3["Documentation"]:::done
|
||||
f4["Adaptiveness"]
|
||||
f5["Sample Agents"]
|
||||
end
|
||||
end
|
||||
flowchart TB
|
||||
%% Main Entity
|
||||
User([User])
|
||||
|
||||
subgraph Expansion
|
||||
direction LR
|
||||
subgraph intel["Intelligence"]
|
||||
g1["Guardrails"]
|
||||
g2["Streaming Mode"]
|
||||
g3["Image Generation"]
|
||||
g4["Semantic Search"]
|
||||
%% =========================================
|
||||
%% EXTERNAL EVENT SOURCES
|
||||
%% =========================================
|
||||
subgraph ExtEventSource [External Event Source]
|
||||
E_Sch["Schedulers"]
|
||||
E_WH["Webhook"]
|
||||
E_SSE["SSE"]
|
||||
end
|
||||
subgraph mem["Memory Iteration"]
|
||||
h1["Message Model & Sessions"]
|
||||
h2["Storage Migration"]
|
||||
h3["Context Building"]
|
||||
h4["Proactive Compaction"]
|
||||
h5["Token Tracking"]
|
||||
end
|
||||
subgraph evt["Event System"]
|
||||
i1["Event Bus for Nodes"]
|
||||
end
|
||||
subgraph cas["Coding Agent Support"]
|
||||
j1["Claude Code"]
|
||||
j2["Cursor"]
|
||||
j3["Opencode"]
|
||||
j4["Antigravity"]
|
||||
end
|
||||
subgraph plat["Platform"]
|
||||
k1["JavaScript/TypeScript SDK"]
|
||||
k2["Custom Tool Integrator"]
|
||||
k3["Windows Support"]
|
||||
end
|
||||
subgraph dep["Deployment"]
|
||||
l1["Self-Hosted"]
|
||||
l2["Cloud Services"]
|
||||
l3["CI/CD Pipeline"]
|
||||
end
|
||||
subgraph tmpl["Templates"]
|
||||
m1["Sales Agent"]
|
||||
m2["Marketing Agent"]
|
||||
m3["Analytics Agent"]
|
||||
m4["Training Agent"]
|
||||
m5["Smart Form Agent"]
|
||||
end
|
||||
end
|
||||
|
||||
classDef done fill:#9e9e9e,color:#fff,stroke:#757575
|
||||
%% =========================================
|
||||
%% SYSTEM NODES
|
||||
%% =========================================
|
||||
subgraph WorkerBees [Worker Bees]
|
||||
WB_C["Conversation"]
|
||||
WB_SP["System prompt"]
|
||||
|
||||
subgraph Graph [Graph]
|
||||
direction TB
|
||||
N1["Node"] --> N2["Node"] --> N3["Node"]
|
||||
N1 -.-> AN["Active Node"]
|
||||
N2 -.-> AN
|
||||
N3 -.-> AN
|
||||
|
||||
%% Nested Event Loop Node
|
||||
subgraph EventLoopNode [Event Loop Node]
|
||||
ELN_L["listener"]
|
||||
ELN_SP["System Prompt<br/>(Task)"]
|
||||
ELN_EL["Event loop"]
|
||||
ELN_C["Conversation"]
|
||||
end
|
||||
end
|
||||
end
|
||||
|
||||
subgraph JudgeNode [Judge]
|
||||
J_C["Criteria"]
|
||||
J_P["Principles"]
|
||||
J_EL["Event loop"] <--> J_S["Scheduler"]
|
||||
end
|
||||
|
||||
subgraph QueenBee [Queen Bee]
|
||||
QB_SP["System prompt"]
|
||||
QB_EL["Event loop"]
|
||||
QB_C["Conversation"]
|
||||
end
|
||||
|
||||
subgraph Infra [Infra]
|
||||
SA["Sub Agent"]
|
||||
TR["Tool Registry"]
|
||||
WTM["Write through Conversation Memory<br/>(Logs/RAM/Harddrive)"]
|
||||
SM["Shared Memory<br/>(State/Harddrive)"]
|
||||
EB["Event Bus<br/>(RAM)"]
|
||||
CS["Credential Store<br/>(Harddrive/Cloud)"]
|
||||
end
|
||||
|
||||
subgraph PC [PC]
|
||||
B["Browser"]
|
||||
CB["Codebase<br/>v 0.0.x ... v n.n.n"]
|
||||
end
|
||||
|
||||
%% =========================================
|
||||
%% CONNECTIONS & DATA FLOW
|
||||
%% =========================================
|
||||
|
||||
%% External Event Routing
|
||||
E_Sch --> ELN_L
|
||||
E_WH --> ELN_L
|
||||
E_SSE --> ELN_L
|
||||
ELN_L -->|"triggers"| ELN_EL
|
||||
|
||||
%% User Interactions
|
||||
User -->|"Talk"| WB_C
|
||||
User -->|"Talk"| QB_C
|
||||
User -->|"Read/Write Access"| CS
|
||||
|
||||
%% Inter-System Logic
|
||||
ELN_C <-->|"Mirror"| WB_C
|
||||
WB_C -->|"Focus"| AN
|
||||
|
||||
WorkerBees -->|"Inquire"| JudgeNode
|
||||
JudgeNode -->|"Approve"| WorkerBees
|
||||
|
||||
%% Judge Alignments
|
||||
J_C <-.->|"aligns"| WB_SP
|
||||
J_P <-.->|"aligns"| QB_SP
|
||||
|
||||
%% Escalate path
|
||||
J_EL -->|"Report (Escalate)"| QB_EL
|
||||
|
||||
%% Pub/Sub Logic
|
||||
AN -->|"publish"| EB
|
||||
EB -->|"subscribe"| QB_C
|
||||
|
||||
%% Infra and Process Spawning
|
||||
ELN_EL -->|"Spawn"| SA
|
||||
SA -->|"Inform"| ELN_EL
|
||||
SA -->|"Starts"| B
|
||||
B -->|"Report"| ELN_EL
|
||||
TR -->|"Assigned"| ELN_EL
|
||||
CB -->|"Modify Worker Bee"| WB_C
|
||||
|
||||
%% =========================================
|
||||
%% SHARED MEMORY & LOGS ACCESS
|
||||
%% =========================================
|
||||
|
||||
%% Worker Bees Access (link to node inside Graph subgraph)
|
||||
AN <-->|"Read/Write"| WTM
|
||||
AN <-->|"Read/Write"| SM
|
||||
|
||||
%% Queen Bee Access
|
||||
QB_C <-->|"Read/Write"| WTM
|
||||
QB_EL <-->|"Read/Write"| SM
|
||||
|
||||
%% Credentials Access
|
||||
CS -->|"Read Access"| QB_C
|
||||
```
|
||||
|
||||
## Contributing
|
||||
We welcome contributions from the community! We’re especially looking for help building tools, integrations, and example agents for the framework ([check #2805](https://github.com/aden-hive/hive/issues/2805)). If you’re interested in extending its functionality, this is the perfect place to start. Please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
|
||||
|
||||
We welcome contributions from the community! We’re especially looking for help building tools, integrations, and example agents for the framework ([check #2805](https://github.com/adenhq/hive/issues/2805)). If you’re interested in extending its functionality, this is the perfect place to start. Please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
|
||||
|
||||
**Important:** Please get assigned to an issue before submitting a PR. Comment on an issue to claim it, and a maintainer will assign you. Issues with reproducible steps and proposals are prioritized. This helps prevent duplicate work.
|
||||
**Important:** Please get assigned to an issue before submitting a PR. Comment on an issue to claim it, and a maintainer will assign you. Issues with reproducible steps and proposals are prioritized. This helps prevent duplicate work.
|
||||
|
||||
1. Find or create an issue and get assigned
|
||||
2. Fork the repository
|
||||
@@ -343,13 +373,9 @@ This project is licensed under the Apache License 2.0 - see the [LICENSE](LICENS
|
||||
|
||||
## Frequently Asked Questions (FAQ)
|
||||
|
||||
**Q: Does Hive depend on LangChain or other agent frameworks?**
|
||||
|
||||
No. Hive is built from the ground up with no dependencies on LangChain, CrewAI, or other agent frameworks. The framework is designed to be lean and flexible, generating agent graphs dynamically rather than relying on predefined components.
|
||||
|
||||
**Q: What LLM providers does Hive support?**
|
||||
|
||||
Hive supports 100+ LLM providers through LiteLLM integration, including OpenAI (GPT-4, GPT-4o), Anthropic (Claude models), Google Gemini, DeepSeek, Mistral, Groq, and many more. Simply set the appropriate API key environment variable and specify the model name.
|
||||
Hive supports 100+ LLM providers through LiteLLM integration, including OpenAI (GPT-4, GPT-4o), Anthropic (Claude models), Google Gemini, DeepSeek, Mistral, Groq, and many more. Simply set the appropriate API key environment variable and specify the model name. We recommend using Claude, GLM and Gemini as they have the best performance.
|
||||
|
||||
**Q: Can I use Hive with local AI models like Ollama?**
|
||||
|
||||
@@ -357,37 +383,21 @@ Yes! Hive supports local models through LiteLLM. Simply use the model name forma
|
||||
|
||||
**Q: What makes Hive different from other agent frameworks?**
|
||||
|
||||
Hive generates your entire agent system from natural language goals using a coding agent—you don't hardcode workflows or manually define graphs. When agents fail, the framework automatically captures failure data, evolves the agent graph, and redeploys. This self-improving loop is unique to Aden.
|
||||
Hive generates your entire agent system from natural language goals using a coding agent—you don't hardcode workflows or manually define graphs. When agents fail, the framework automatically captures failure data, [evolves the agent graph](docs/key_concepts/evolution.md), and redeploys. This self-improving loop is unique to Aden.
|
||||
|
||||
**Q: Is Hive open-source?**
|
||||
|
||||
Yes, Hive is fully open-source under the Apache License 2.0. We actively encourage community contributions and collaboration.
|
||||
|
||||
**Q: Does Hive collect data from users?**
|
||||
|
||||
Hive collects telemetry data for monitoring and observability purposes, including token usage, latency metrics, and cost tracking. Content capture (prompts and responses) is configurable and stored with team-scoped data isolation. All data stays within your infrastructure when self-hosted.
|
||||
|
||||
**Q: What deployment options does Hive support?**
|
||||
|
||||
Hive supports self-hosted deployments via Python packages. See the [Environment Setup Guide](ENVIRONMENT_SETUP.md) for installation instructions. Cloud deployment options and Kubernetes-ready configurations are on the roadmap.
|
||||
|
||||
**Q: Can Hive handle complex, production-scale use cases?**
|
||||
|
||||
Yes. Hive is explicitly designed for production environments with features like automatic failure recovery, real-time observability, cost controls, and horizontal scaling support. The framework handles both simple automations and complex multi-agent workflows.
|
||||
|
||||
**Q: Does Hive support human-in-the-loop workflows?**
|
||||
|
||||
Yes, Hive fully supports human-in-the-loop workflows through intervention nodes that pause execution for human input. These include configurable timeouts and escalation policies, allowing seamless collaboration between human experts and AI agents.
|
||||
|
||||
**Q: What monitoring and debugging tools does Hive provide?**
|
||||
|
||||
Hive includes comprehensive observability features: real-time WebSocket streaming for live agent execution monitoring, TimescaleDB-powered analytics for cost and performance metrics, health check endpoints for Kubernetes integration, and MCP tools for agent execution, including file operations, web search, data processing, and more.
|
||||
Yes, Hive fully supports [human-in-the-loop](docs/key_concepts/graph.md#human-in-the-loop) workflows through intervention nodes that pause execution for human input. These include configurable timeouts and escalation policies, allowing seamless collaboration between human experts and AI agents.
|
||||
|
||||
**Q: What programming languages does Hive support?**
|
||||
|
||||
The Hive framework is built in Python. A JavaScript/TypeScript SDK is on the roadmap.
|
||||
|
||||
**Q: Can Aden agents interact with external tools and APIs?**
|
||||
**Q: Can Hive agents interact with external tools and APIs?**
|
||||
|
||||
Yes. Aden's SDK-wrapped nodes provide built-in tool access, and the framework supports flexible tool ecosystems. Agents can integrate with external APIs, databases, and services through the node architecture.
|
||||
|
||||
@@ -397,23 +407,21 @@ Hive provides granular budget controls including spending limits, throttles, and
|
||||
|
||||
**Q: Where can I find examples and documentation?**
|
||||
|
||||
Visit [docs.adenhq.com](https://docs.adenhq.com/) for complete guides, API reference, and getting started tutorials. The repository also includes documentation in the `docs/` folder and a comprehensive [DEVELOPER.md](DEVELOPER.md) guide.
|
||||
Visit [docs.adenhq.com](https://docs.adenhq.com/) for complete guides, API reference, and getting started tutorials. The repository also includes documentation in the `docs/` folder and a comprehensive [developer guide](docs/developer-guide.md).
|
||||
|
||||
**Q: How can I contribute to Aden?**
|
||||
|
||||
Contributions are welcome! Fork the repository, create your feature branch, implement your changes, and submit a pull request. See [CONTRIBUTING.md](CONTRIBUTING.md) for detailed guidelines.
|
||||
|
||||
**Q: When will my team start seeing results from Aden's adaptive agents?**
|
||||
## Star History
|
||||
|
||||
Aden's adaptation loop begins working from the first execution. When an agent fails, the framework captures the failure data, helping developers evolve the agent graph through the coding agent. How quickly this translates to measurable results depends on the complexity of your use case, the quality of your goal definitions, and the volume of executions generating feedback.
|
||||
|
||||
**Q: How does Hive compare to other agent frameworks?**
|
||||
|
||||
Hive focuses on generating agents that run real business processes, rather than generic agents. This vision emphasizes outcome-driven design, adaptability, and an easy-to-use set of tools and integrations.
|
||||
|
||||
**Q: Does Aden offer enterprise support?**
|
||||
|
||||
For enterprise inquiries, contact the Aden team through [adenhq.com](https://adenhq.com) or join our [Discord community](https://discord.com/invite/MXE49hrKDk) for support and discussions.
|
||||
<a href="https://star-history.com/#aden-hive/hive&Date">
|
||||
<picture>
|
||||
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=aden-hive/hive&type=Date&theme=dark" />
|
||||
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=aden-hive/hive&type=Date" />
|
||||
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=aden-hive/hive&type=Date" />
|
||||
</picture>
|
||||
</a>
|
||||
|
||||
---
|
||||
|
||||
|
||||
-299
@@ -1,299 +0,0 @@
|
||||
# Product Roadmap
|
||||
|
||||
Aden Agent Framework aims to help developers build outcome oriented, self-adaptive agents. Please find our roadmap here
|
||||
|
||||
```mermaid
|
||||
flowchart TD
|
||||
subgraph Foundation
|
||||
direction LR
|
||||
subgraph arch["Architecture"]
|
||||
a1["Node-Based Architecture"]:::done
|
||||
a2["Python SDK"]:::done
|
||||
a3["LLM Integration"]:::done
|
||||
a4["Communication Protocol"]:::done
|
||||
end
|
||||
subgraph ca["Coding Agent"]
|
||||
b1["Goal Creation Session"]:::done
|
||||
b2["Worker Agent Creation"]
|
||||
b3["MCP Tools"]:::done
|
||||
end
|
||||
subgraph wa["Worker Agent"]
|
||||
c1["Human-in-the-Loop"]:::done
|
||||
c2["Callback Handlers"]:::done
|
||||
c3["Intervention Points"]:::done
|
||||
c4["Streaming Interface"]
|
||||
end
|
||||
subgraph cred["Credentials"]
|
||||
d1["Setup Process"]:::done
|
||||
d2["Pluggable Sources"]:::done
|
||||
d3["Enterprise Secrets"]
|
||||
d4["Integration Tools"]:::done
|
||||
end
|
||||
subgraph tools["Tools"]
|
||||
e1["File Use"]:::done
|
||||
e2["Memory STM/LTM"]:::done
|
||||
e3["Web Search/Scraper"]:::done
|
||||
e4["CSV/PDF"]:::done
|
||||
e5["Excel/Email"]
|
||||
end
|
||||
subgraph core["Core"]
|
||||
f1["Eval System"]
|
||||
f2["Pydantic Validation"]:::done
|
||||
f3["Documentation"]:::done
|
||||
f4["Adaptiveness"]
|
||||
f5["Sample Agents"]
|
||||
end
|
||||
end
|
||||
|
||||
subgraph Expansion
|
||||
direction LR
|
||||
subgraph intel["Intelligence"]
|
||||
g1["Guardrails"]
|
||||
g2["Streaming Mode"]
|
||||
g3["Image Generation"]
|
||||
g4["Semantic Search"]
|
||||
end
|
||||
subgraph mem["Memory Iteration"]
|
||||
h1["Message Model & Sessions"]
|
||||
h2["Storage Migration"]
|
||||
h3["Context Building"]
|
||||
h4["Proactive Compaction"]
|
||||
h5["Token Tracking"]
|
||||
end
|
||||
subgraph evt["Event System"]
|
||||
i1["Event Bus for Nodes"]
|
||||
end
|
||||
subgraph cas["Coding Agent Support"]
|
||||
j1["Claude Code"]
|
||||
j2["Cursor"]
|
||||
j3["Opencode"]
|
||||
j4["Antigravity"]
|
||||
end
|
||||
subgraph plat["Platform"]
|
||||
k1["JavaScript/TypeScript SDK"]
|
||||
k2["Custom Tool Integrator"]
|
||||
k3["Windows Support"]
|
||||
end
|
||||
subgraph dep["Deployment"]
|
||||
l1["Self-Hosted"]
|
||||
l2["Cloud Services"]
|
||||
l3["CI/CD Pipeline"]
|
||||
end
|
||||
subgraph tmpl["Templates"]
|
||||
m1["Sales Agent"]
|
||||
m2["Marketing Agent"]
|
||||
m3["Analytics Agent"]
|
||||
m4["Training Agent"]
|
||||
m5["Smart Form Agent"]
|
||||
end
|
||||
end
|
||||
|
||||
classDef done fill:#9e9e9e,color:#fff,stroke:#757575
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Phase 1: Foundation
|
||||
|
||||
### Backbone Architecture
|
||||
- [ ] **Node-Based Architecture (Agent as a node)**
|
||||
- [x] Object schema definition
|
||||
- [x] Node wrapper SDK
|
||||
- [x] Shared memory access
|
||||
- [ ] Default monitoring hooks
|
||||
- [x] Tool access layer
|
||||
- [x] LLM integration layer (Natively supports all mainstream LLMs through LiteLLM)
|
||||
- [x] Anthropic
|
||||
- [x] OpenAI
|
||||
- [x] Google
|
||||
- [x] **Communication protocol between nodes**
|
||||
- [x] **[Coding Agent] Goal Creation Session** (separate from coding session)
|
||||
- [x] Instruction back and forth
|
||||
- [x] Goal Object schema definition
|
||||
- [x] Being able to generate the test cases
|
||||
- [x] Test case validation for worker agent (Outcome driven)
|
||||
- [ ] **[Coding Agent] Worker Agent Creation**
|
||||
- [x] Coding Agent tools
|
||||
- [ ] Use Template Agent as a start
|
||||
- [x] Use our MCP tools
|
||||
- [ ] **[Worker Agent] Human-in-the-Loop**
|
||||
- [x] Worker Agents request with questions and options
|
||||
- [x] Callback Handler System to receive events throughout execution
|
||||
- [x] Tool-Based Intervention Points (tool to pause execution and request human input)
|
||||
- [x] Multiple entrypoint for different event source (e.g. Human input, webhook)
|
||||
- [ ] Streaming Interface for Real-time Monitoring
|
||||
- [x] Request State Management
|
||||
|
||||
### Credential Management
|
||||
- [x] **Credentials Setup Process**
|
||||
- [x] Install Credential MCP
|
||||
- [x] **Pluggable Credential Sources**
|
||||
- [x] **Abstraction & Local Sources**
|
||||
- [x] Introduce `CredentialSource` base class
|
||||
- [x] Refactor existing logic into `EnvVarSource`
|
||||
- [x] Implementation of Source Priority Chain mechanism
|
||||
- [ ] Foundation unit tests
|
||||
- [ ] **Enterprise Secret Managers**
|
||||
- [x] `VaultSource` (HashiCorp Vault)
|
||||
- [ ] `AWSSecretsSource` (AWS Secrets Manager)
|
||||
- [ ] `AzureKeyVaultSource` (Azure Key Vault)
|
||||
- [ ] Management of optional provider dependencies
|
||||
- [ ] **Advanced Features**
|
||||
- [x] Credential expiration and auto-refresh
|
||||
- [ ] Audit logging for compliance/tracking
|
||||
- [ ] Per-environment configuration support
|
||||
- [ ] **Documentation & DX**
|
||||
- [ ] Comprehensive source documentation
|
||||
- [ ] Example configurations for all providers
|
||||
- [x] **Integration as tools coverage**
|
||||
- [x] Gsuite Tools
|
||||
- [x] Social Media
|
||||
- [ ] Twitter(X)
|
||||
- [x] Github
|
||||
- [ ] Instagram
|
||||
- [ ] SAAS
|
||||
- [ ] Hubspot
|
||||
- [ ] Slack
|
||||
- [ ] Teams
|
||||
- [ ] Zoom
|
||||
- [ ] Stripe
|
||||
- [ ] Salesforce
|
||||
|
||||
> [!IMPORTANT]
|
||||
> **Community Contribution Wanted**: We appreciate help from the community to expand the "Integration as tools" capability. Leave an issue of the integration you want to support via Hive!
|
||||
|
||||
### Essential Tools
|
||||
- [x] **File Use Tool Kit**
|
||||
- [X] **Memory Tools**
|
||||
- [x] STM Layer Tool (state-based short-term memory)
|
||||
- [x] LTM Layer Tool (RLM - long-term memory)
|
||||
- [ ] **Infrastructure Tools**
|
||||
- [x] Runtime Log Tool (logs for coding agent)
|
||||
- [x] Web Search
|
||||
- [x] Web Scraper
|
||||
- [x] CSV tools
|
||||
- [x] PDF tools
|
||||
- [ ] Excel tools
|
||||
- [ ] Email Tools
|
||||
- [ ] Recipe for "Add your own tools"
|
||||
|
||||
### Memory & File System
|
||||
- [x] DB for long-term persistent memory (Filesystem as durable scratchpad pattern)
|
||||
- [x] Session Local memory isolation
|
||||
|
||||
### Eval System (Basic)
|
||||
- [x] Test Driven - Run test case for all agent iteration
|
||||
- [ ] Failure recording mechanism
|
||||
- [ ] SDK for defining failure conditions
|
||||
- [ ] Basic observability hooks
|
||||
- [ ] User-driven log analysis (OSS approach)
|
||||
|
||||
### Data Validation
|
||||
- [x] Natively Support data validation of LLMs output with Pydantic
|
||||
|
||||
### Developer Experience
|
||||
- [ ] **MVP Features**
|
||||
- [ ] Debugging mode
|
||||
- [ ] CLI tools for memory management
|
||||
- [ ] CLI tools for credential management
|
||||
- [ ] **MVP Resources & Documentation**
|
||||
- [x] Quick start guide
|
||||
- [x] Goal creation guide
|
||||
- [x] Agent creation guide
|
||||
- [x] GitHub Page setup
|
||||
- [x] README with examples
|
||||
- [x] Contributing guidelines
|
||||
- [ ] Introduction Video
|
||||
|
||||
### Adaptiveness
|
||||
- [ ] Runtime data feedback loop
|
||||
- [ ] Instant Developer Feedback for improvement
|
||||
|
||||
### Sample Agents
|
||||
- [ ] Knowledge Agent
|
||||
- [ ] Blog Writer Agent
|
||||
- [ ] SDR Agent
|
||||
|
||||
---
|
||||
|
||||
## Phase 2: Expansion
|
||||
|
||||
### Basic Guardrails
|
||||
- [ ] Support Basic Monitoring from Agent node SDK
|
||||
- [ ] SDK guardrail implementation (in node)
|
||||
- [ ] Guardrail type support (Determined Condition as Guardrails)
|
||||
|
||||
### Agent Capability
|
||||
- [ ] Streaming mode support
|
||||
- [ ] Image Generation support
|
||||
- [ ] Take end user input Image and flatfile understand capability
|
||||
|
||||
### Event-loop For Nodes (Opencode-style)
|
||||
- [ ] **Event bus**
|
||||
|
||||
### Memory System Iteration
|
||||
- [ ] **Message Model & Session Management**
|
||||
- [ ] Introduce `Message` class with structured content types
|
||||
- [ ] Implement `Session` classes for conversation state
|
||||
- [ ] **Storage Migration**
|
||||
- [ ] Implement granular per-message file persistence (`/message/[agentID]/...`)
|
||||
- [ ] Migrate from monolithic run storage
|
||||
- [ ] **Context Building & Conversation Loop**
|
||||
- [ ] Implement `Message.stream(sessionID)`
|
||||
- [ ] Update `LLMNode.execute()` for full context building
|
||||
- [ ] Implement `Message.toModelMessages()` conversion
|
||||
- [ ] **Proactive Compaction**
|
||||
- [ ] Implement proactive overflow detection
|
||||
- [ ] Develop backward-scanning pruning strategy (e.g., clearing old tool outputs)
|
||||
- [ ] **Enhanced Token Tracking**
|
||||
- [ ] Extend `LLMResponse` to track reasoning and cache tokens
|
||||
- [ ] Integrate granular token metrics into compaction logic
|
||||
|
||||
### Coding Agent Support
|
||||
- [ ] Claude Code
|
||||
- [ ] Cursor
|
||||
- [ ] Opencode
|
||||
- [ ] Antigravity
|
||||
|
||||
### File System Enhancement
|
||||
- [ ] Semantic Search integration
|
||||
- [ ] Interactive File System in product (frontend integration)
|
||||
|
||||
### More Worker Tools
|
||||
- [ ] Custom Tool Integrator
|
||||
- [ ] Integration as a tool (Credential Store & Support)
|
||||
- [ ] **Core Agent Tools**
|
||||
- [ ] Node Discovery Tool (find other agents in the graph)
|
||||
- [ ] HITL Tool (pause execution for human approval)
|
||||
- [ ] Wake-up Tool (resume agent tasks)
|
||||
|
||||
### Deployment (Self-Hosted)
|
||||
- [ ] Docker container standardization
|
||||
- [ ] Headless backend execution
|
||||
- [ ] Exposed API for frontend attachment
|
||||
- [ ] Local monitoring & observability
|
||||
- [ ] Basic lifecycle APIs (Start, Stop, Pause, Resume)
|
||||
|
||||
### Deployment (Cloud)
|
||||
- [ ] Cloud Service Options
|
||||
- [ ] Support deployment to 3rd-party platforms
|
||||
- [ ] Self-deploy + orchestrator connection
|
||||
- [ ] **CI/CD Pipeline**
|
||||
- [ ] Automated test execution
|
||||
- [ ] Agent version control
|
||||
- [ ] All tests must pass for deployment
|
||||
|
||||
### Developer Experience Enhancement
|
||||
- [ ] Tool usage documentation
|
||||
- [ ] Discord Support Channel
|
||||
|
||||
### More Agent Templates
|
||||
- [ ] GTM Sales Agent (workflow)
|
||||
- [ ] GTM Marketing Agent (workflow)
|
||||
- [ ] Analytics Agent
|
||||
- [ ] Training Agent
|
||||
- [ ] Smart Entry / Form Agent (self-evolution emphasis)
|
||||
|
||||
### Cross-Platform
|
||||
- [ ] JavaScript / TypeScript Version SDK
|
||||
- [ ] Better windows support
|
||||
+2
-2
@@ -39,8 +39,8 @@ We consider security research conducted in accordance with this policy to be:
|
||||
## Security Best Practices for Users
|
||||
|
||||
1. **Keep Updated**: Always run the latest version
|
||||
2. **Secure Configuration**: Review `config.yaml` settings, especially in production
|
||||
3. **Environment Variables**: Never commit `.env` files or `config.yaml` with secrets
|
||||
2. **Secure Configuration**: Review your `~/.hive/configuration.json`, `.mcp.json`, and environment variable settings, especially in production
|
||||
3. **Environment Variables**: Never commit `.env` files or any configuration files that contain secrets
|
||||
4. **Network Security**: Use HTTPS in production, configure firewalls appropriately
|
||||
5. **Database Security**: Use strong passwords, limit network access
|
||||
|
||||
|
||||
@@ -0,0 +1,31 @@
|
||||
perf: reduce subprocess spawning in quickstart scripts (#4427)
|
||||
|
||||
## Problem
|
||||
Windows process creation (CreateProcess) is 10-100x slower than Linux fork/exec.
|
||||
The quickstart scripts were spawning 4+ separate `uv run python -c "import X"`
|
||||
processes to verify imports, adding ~600ms overhead on Windows.
|
||||
|
||||
## Solution
|
||||
Consolidated all import checks into a single batch script that checks multiple
|
||||
modules in one subprocess call, reducing spawn overhead by ~75%.
|
||||
|
||||
## Changes
|
||||
- **New**: `scripts/check_requirements.py` - Batched import checker
|
||||
- **New**: `scripts/test_check_requirements.py` - Test suite
|
||||
- **New**: `scripts/benchmark_quickstart.ps1` - Performance benchmark tool
|
||||
- **Modified**: `quickstart.ps1` - Updated import verification (2 sections)
|
||||
- **Modified**: `quickstart.sh` - Updated import verification
|
||||
|
||||
## Performance Impact
|
||||
**Benchmark results on Windows:**
|
||||
- Before: ~19.8 seconds for import checks
|
||||
- After: ~4.9 seconds for import checks
|
||||
- **Improvement: 14.9 seconds saved (75.2% faster)**
|
||||
|
||||
## Testing
|
||||
- ✅ All functional tests pass (`scripts/test_check_requirements.py`)
|
||||
- ✅ Quickstart scripts work correctly on Windows
|
||||
- ✅ Error handling verified (invalid imports reported correctly)
|
||||
- ✅ Performance benchmark confirms 75%+ improvement
|
||||
|
||||
Fixes #4427
|
||||
@@ -0,0 +1,27 @@
|
||||
# Identity mapping: GitHub username -> Discord ID
|
||||
#
|
||||
# This file links GitHub accounts to Discord accounts for the
|
||||
# Integration Bounty Program. When a bounty PR is merged, the
|
||||
# GitHub Action uses this file to ping the contributor on Discord.
|
||||
#
|
||||
# HOW TO ADD YOURSELF:
|
||||
# Open a "Link Discord Account" issue:
|
||||
# https://github.com/aden-hive/hive/issues/new?template=link-discord.yml
|
||||
# A GitHub Action will automatically add your entry here.
|
||||
#
|
||||
# To find your Discord ID:
|
||||
# 1. Open Discord Settings > Advanced > Enable Developer Mode
|
||||
# 2. Right-click your name > Copy User ID
|
||||
#
|
||||
# Format:
|
||||
# - github: your-github-username
|
||||
# discord: "your-discord-id" # quotes required (it's a number)
|
||||
# name: Your Display Name # optional
|
||||
|
||||
contributors:
|
||||
# - github: example-user
|
||||
# discord: "123456789012345678"
|
||||
# name: Example User
|
||||
- github: TimothyZhang7
|
||||
discord: "408460790061072384"
|
||||
name: Timothy@Aden
|
||||
@@ -1,10 +1,5 @@
|
||||
{
|
||||
"mcpServers": {
|
||||
"agent-builder": {
|
||||
"command": "python",
|
||||
"args": ["-m", "framework.mcp.agent_builder_server"],
|
||||
"cwd": "core"
|
||||
},
|
||||
"tools": {
|
||||
"command": "python",
|
||||
"args": ["-m", "aden_tools.mcp_server", "--stdio"],
|
||||
|
||||
@@ -82,7 +82,7 @@ Register an MCP server as a tool source for your agent.
|
||||
"example_tool"
|
||||
],
|
||||
"total_mcp_servers": 1,
|
||||
"note": "MCP server 'tools' registered with 6 tools. These tools can now be used in llm_tool_use nodes."
|
||||
"note": "MCP server 'tools' registered with 6 tools. These tools can now be used in event_loop nodes."
|
||||
}
|
||||
```
|
||||
|
||||
@@ -149,7 +149,7 @@ List tools available from registered MCP servers.
|
||||
]
|
||||
},
|
||||
"total_tools": 6,
|
||||
"note": "Use these tool names in the 'tools' parameter when adding llm_tool_use nodes"
|
||||
"note": "Use these tool names in the 'tools' parameter when adding event_loop nodes"
|
||||
}
|
||||
```
|
||||
|
||||
@@ -246,7 +246,7 @@ Here's a complete workflow for building an agent with MCP tools:
|
||||
"node_id": "web-searcher",
|
||||
"name": "Web Search",
|
||||
"description": "Search the web for information",
|
||||
"node_type": "llm_tool_use",
|
||||
"node_type": "event_loop",
|
||||
"input_keys": "[\"query\"]",
|
||||
"output_keys": "[\"search_results\"]",
|
||||
"system_prompt": "Search for {query} using the web_search tool",
|
||||
|
||||
@@ -119,7 +119,7 @@ builder = WorkflowBuilder()
|
||||
builder.add_node(
|
||||
node_id="researcher",
|
||||
name="Web Researcher",
|
||||
node_type="llm_tool_use",
|
||||
node_type="event_loop",
|
||||
system_prompt="Research the topic using web_search",
|
||||
tools=["web_search"], # Tool from tools MCP server
|
||||
input_keys=["topic"],
|
||||
@@ -137,7 +137,7 @@ Tools from MCP servers can be referenced in your agent.json just like built-in t
|
||||
{
|
||||
"id": "searcher",
|
||||
"name": "Web Searcher",
|
||||
"node_type": "llm_tool_use",
|
||||
"node_type": "event_loop",
|
||||
"system_prompt": "Search for information about {topic}",
|
||||
"tools": ["web_search", "web_scrape"],
|
||||
"input_keys": ["topic"],
|
||||
|
||||
+27
-81
@@ -1,17 +1,16 @@
|
||||
# MCP Server Guide - Agent Builder
|
||||
# MCP Server Guide - Agent Building Tools
|
||||
|
||||
This guide covers the MCP (Model Context Protocol) server for building goal-driven agents.
|
||||
> **Note:** The standalone `agent-builder` MCP server (`framework.mcp.agent_builder_server`) has been replaced. Agent building is now done via the `coder-tools` server's `initialize_and_build_agent` tool, with underlying logic in `tools/coder_tools_server.py`.
|
||||
|
||||
This guide covers the MCP tools available for building goal-driven agents.
|
||||
|
||||
## Setup
|
||||
|
||||
### Quick Setup
|
||||
|
||||
```bash
|
||||
# Using the setup script (recommended)
|
||||
python setup_mcp.py
|
||||
|
||||
# Or using bash
|
||||
./setup_mcp.sh
|
||||
# Run the quickstart script (recommended)
|
||||
./quickstart.sh
|
||||
```
|
||||
|
||||
### Manual Configuration
|
||||
@@ -21,10 +20,10 @@ Add to your MCP client configuration (e.g., Claude Desktop):
|
||||
```json
|
||||
{
|
||||
"mcpServers": {
|
||||
"agent-builder": {
|
||||
"command": "python",
|
||||
"args": ["-m", "framework.mcp.agent_builder_server"],
|
||||
"cwd": "/path/to/goal-agent"
|
||||
"coder-tools": {
|
||||
"command": "uv",
|
||||
"args": ["run", "coder_tools_server.py", "--stdio"],
|
||||
"cwd": "/path/to/hive/tools"
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -103,31 +102,20 @@ Add a processing node to the agent graph.
|
||||
- `node_id` (string, required): Unique node identifier
|
||||
- `name` (string, required): Human-readable name
|
||||
- `description` (string, required): What this node does
|
||||
- `node_type` (string, required): One of: `llm_generate`, `llm_tool_use`, `router`, `function`
|
||||
- `node_type` (string, required): Must be `event_loop` (the only valid type)
|
||||
- `input_keys` (string, required): JSON array of input variable names
|
||||
- `output_keys` (string, required): JSON array of output variable names
|
||||
- `system_prompt` (string, optional): System prompt for LLM nodes
|
||||
- `tools` (string, optional): JSON array of tool names for tool_use nodes
|
||||
- `routes` (string, optional): JSON object of route mappings for router nodes
|
||||
- `system_prompt` (string, optional): System prompt for the LLM
|
||||
- `tools` (string, optional): JSON array of tool names
|
||||
- `client_facing` (boolean, optional): Set to true for human-in-the-loop interaction
|
||||
|
||||
**Node Types:**
|
||||
**Node Type:**
|
||||
|
||||
1. **llm_generate**: Uses LLM to generate output from inputs
|
||||
- Requires: `system_prompt`
|
||||
- Tools: Not used
|
||||
|
||||
2. **llm_tool_use**: Uses LLM with tools to accomplish tasks
|
||||
- Requires: `system_prompt`, `tools`
|
||||
- Tools: Array of tool names (e.g., `["web_search", "web_fetch"]`)
|
||||
|
||||
3. **router**: LLM-powered routing to different paths
|
||||
- Requires: `system_prompt`, `routes`
|
||||
- Routes: Object mapping route names to target node IDs
|
||||
- Example: `{"pass": "success_node", "fail": "retry_node"}`
|
||||
|
||||
4. **function**: Executes a pre-defined function
|
||||
- System prompt describes the function behavior
|
||||
- No LLM calls, pure computation
|
||||
**event_loop**: LLM-powered node with self-correction loop
|
||||
- Requires: `system_prompt`
|
||||
- Optional: `tools` (array of tool names, e.g., `["web_search", "web_fetch"]`)
|
||||
- Optional: `client_facing` (set to true for HITL / user interaction)
|
||||
- Supports: iterative refinement, judge-based evaluation, tool use, streaming
|
||||
|
||||
**Example:**
|
||||
```json
|
||||
@@ -135,7 +123,7 @@ Add a processing node to the agent graph.
|
||||
"node_id": "search_sources",
|
||||
"name": "Search Sources",
|
||||
"description": "Searches for relevant sources on the topic",
|
||||
"node_type": "llm_tool_use",
|
||||
"node_type": "event_loop",
|
||||
"input_keys": "[\"topic\", \"search_queries\"]",
|
||||
"output_keys": "[\"sources\", \"source_count\"]",
|
||||
"system_prompt": "Search for sources using the provided queries...",
|
||||
@@ -198,7 +186,7 @@ Export the validated graph as an agent specification.
|
||||
|
||||
**What it does:**
|
||||
1. Validates the graph
|
||||
2. Auto-generates missing edges from router routes
|
||||
2. Validates edge connectivity
|
||||
3. Writes files to disk:
|
||||
- `exports/{agent-name}/agent.json` - Full agent specification
|
||||
- `exports/{agent-name}/README.md` - Auto-generated documentation
|
||||
@@ -252,47 +240,6 @@ Test the complete agent graph with sample inputs.
|
||||
|
||||
---
|
||||
|
||||
### Evaluation Rules
|
||||
|
||||
#### `add_evaluation_rule`
|
||||
Add a rule for the HybridJudge to evaluate node outputs.
|
||||
|
||||
**Parameters:**
|
||||
- `rule_id` (string, required): Unique rule identifier
|
||||
- `description` (string, required): What this rule checks
|
||||
- `condition` (string, required): Python expression to evaluate
|
||||
- `action` (string, required): Action to take: `accept`, `retry`, `escalate`
|
||||
- `priority` (integer, optional): Rule priority (default: 0)
|
||||
- `feedback_template` (string, optional): Feedback message template
|
||||
|
||||
**Condition Examples:**
|
||||
- `'result.get("success") == True'` - Check for success flag
|
||||
- `'result.get("error_type") == "timeout"'` - Check error type
|
||||
- `'len(result.get("data", [])) > 0'` - Check for non-empty data
|
||||
|
||||
**Example:**
|
||||
```json
|
||||
{
|
||||
"rule_id": "timeout_retry",
|
||||
"description": "Retry on timeout errors",
|
||||
"condition": "result.get('error_type') == 'timeout'",
|
||||
"action": "retry",
|
||||
"priority": 10,
|
||||
"feedback_template": "Timeout occurred, retrying..."
|
||||
}
|
||||
```
|
||||
|
||||
#### `list_evaluation_rules`
|
||||
List all configured evaluation rules.
|
||||
|
||||
#### `remove_evaluation_rule`
|
||||
Remove an evaluation rule.
|
||||
|
||||
**Parameters:**
|
||||
- `rule_id` (string, required): Rule to remove
|
||||
|
||||
---
|
||||
|
||||
## Example Workflow
|
||||
|
||||
Here's a complete workflow for building a research agent:
|
||||
@@ -320,7 +267,7 @@ add_node(
|
||||
node_id="planner",
|
||||
name="Research Planner",
|
||||
description="Creates research strategy",
|
||||
node_type="llm_generate",
|
||||
node_type="event_loop",
|
||||
input_keys='["topic"]',
|
||||
output_keys='["strategy", "queries"]',
|
||||
system_prompt="Analyze topic and create research plan..."
|
||||
@@ -330,7 +277,7 @@ add_node(
|
||||
node_id="searcher",
|
||||
name="Search Sources",
|
||||
description="Find relevant sources",
|
||||
node_type="llm_tool_use",
|
||||
node_type="event_loop",
|
||||
input_keys='["queries"]',
|
||||
output_keys='["sources"]',
|
||||
system_prompt="Search for sources...",
|
||||
@@ -359,10 +306,9 @@ The exported agent will be saved to `exports/research-agent/`.
|
||||
|
||||
1. **Start with the goal**: Define clear success criteria before building nodes
|
||||
2. **Test nodes individually**: Use `test_node` to verify each node works
|
||||
3. **Use router nodes for branching**: Don't create edges manually for routers - define routes and they'll be auto-generated
|
||||
4. **Add evaluation rules**: Help the judge evaluate outputs deterministically
|
||||
5. **Validate early, validate often**: Run `validate_graph` after adding nodes/edges
|
||||
6. **Check exports**: Review the generated README.md to verify your agent structure
|
||||
3. **Use conditional edges for branching**: Define condition_expr on edges for decision points
|
||||
4. **Validate early, validate often**: Run `validate_graph` after adding nodes/edges
|
||||
5. **Check exports**: Review the generated README.md to verify your agent structure
|
||||
|
||||
---
|
||||
|
||||
|
||||
+15
-70
@@ -14,69 +14,14 @@ Framework provides a runtime framework that captures **decisions**, not just act
|
||||
## Installation
|
||||
|
||||
```bash
|
||||
pip install -e .
|
||||
uv pip install -e .
|
||||
```
|
||||
|
||||
## MCP Server Setup
|
||||
## Agent Building
|
||||
|
||||
The framework includes an MCP (Model Context Protocol) server for building agents. To set up the MCP server:
|
||||
Agent scaffolding is handled by the `coder-tools` MCP server (in `tools/coder_tools_server.py`), which provides the `initialize_and_build_agent` tool and related utilities. The package generation logic lives directly in `tools/coder_tools_server.py`.
|
||||
|
||||
### Automated Setup
|
||||
|
||||
**Using bash (Linux/macOS):**
|
||||
```bash
|
||||
./setup_mcp.sh
|
||||
```
|
||||
|
||||
**Using Python (cross-platform):**
|
||||
```bash
|
||||
python setup_mcp.py
|
||||
```
|
||||
|
||||
The setup script will:
|
||||
1. Install the framework package
|
||||
2. Install MCP dependencies (mcp, fastmcp)
|
||||
3. Create/verify `.mcp.json` configuration
|
||||
4. Test the MCP server module
|
||||
|
||||
### Manual Setup
|
||||
|
||||
If you prefer manual setup:
|
||||
|
||||
```bash
|
||||
# Install framework
|
||||
pip install -e .
|
||||
|
||||
# Install MCP dependencies
|
||||
pip install mcp fastmcp
|
||||
|
||||
# Test the server
|
||||
python -m framework.mcp.agent_builder_server
|
||||
```
|
||||
|
||||
### Using with MCP Clients
|
||||
|
||||
To use the agent builder with Claude Desktop or other MCP clients, add this to your MCP client configuration:
|
||||
|
||||
```json
|
||||
{
|
||||
"mcpServers": {
|
||||
"agent-builder": {
|
||||
"command": "python",
|
||||
"args": ["-m", "framework.mcp.agent_builder_server"],
|
||||
"cwd": "/path/to/goal-agent"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The MCP server provides tools for:
|
||||
- Creating agent building sessions
|
||||
- Defining goals with success criteria
|
||||
- Adding nodes (llm_generate, llm_tool_use, router, function)
|
||||
- Connecting nodes with edges
|
||||
- Validating and exporting agent graphs
|
||||
- Testing nodes and full agent graphs
|
||||
See the [Getting Started Guide](../docs/getting-started.md) for building agents.
|
||||
|
||||
## Quick Start
|
||||
|
||||
@@ -85,14 +30,14 @@ The MCP server provides tools for:
|
||||
Run an LLM-powered calculator:
|
||||
|
||||
```bash
|
||||
# Single calculation
|
||||
python -m framework calculate "2 + 3 * 4"
|
||||
# Run an exported agent
|
||||
uv run python -m framework run exports/calculator --input '{"expression": "2 + 3 * 4"}'
|
||||
|
||||
# Interactive mode
|
||||
python -m framework interactive
|
||||
# Interactive shell session
|
||||
uv run python -m framework shell exports/calculator
|
||||
|
||||
# Analyze runs with Builder
|
||||
python -m framework analyze calculator
|
||||
# Show agent info
|
||||
uv run python -m framework info exports/calculator
|
||||
```
|
||||
|
||||
### Using the Runtime
|
||||
@@ -136,16 +81,16 @@ Tests are generated using MCP tools (`generate_constraint_tests`, `generate_succ
|
||||
|
||||
```bash
|
||||
# Run tests against an agent
|
||||
python -m framework test-run <agent_path> --goal <goal_id> --parallel 4
|
||||
uv run python -m framework test-run <agent_path> --goal <goal_id> --parallel 4
|
||||
|
||||
# Debug failed tests
|
||||
python -m framework test-debug <agent_path> <test_name>
|
||||
uv run python -m framework test-debug <agent_path> <test_name>
|
||||
|
||||
# List tests for a goal
|
||||
python -m framework test-list <goal_id>
|
||||
# List tests for an agent
|
||||
uv run python -m framework test-list <agent_path>
|
||||
```
|
||||
|
||||
For detailed testing workflows, see the [testing-agent skill](../.claude/skills/testing-agent/SKILL.md).
|
||||
For detailed testing workflows, see [developer-guide.md](../docs/developer-guide.md).
|
||||
|
||||
### Analyzing Agent Behavior with Builder
|
||||
|
||||
|
||||
@@ -0,0 +1,387 @@
|
||||
"""OpenAI Codex OAuth PKCE login flow.
|
||||
|
||||
Runs the full browser-based OAuth flow so users can authenticate with their
|
||||
ChatGPT Plus/Pro subscription without needing the Codex CLI installed.
|
||||
|
||||
Usage (from quickstart.sh):
|
||||
uv run python codex_oauth.py
|
||||
|
||||
Exit codes:
|
||||
0 - success (credentials saved to ~/.codex/auth.json)
|
||||
1 - failure (user cancelled, timeout, or token exchange error)
|
||||
"""
|
||||
|
||||
import base64
|
||||
import hashlib
|
||||
import http.server
|
||||
import json
|
||||
import os
|
||||
import platform
|
||||
import secrets
|
||||
import subprocess
|
||||
import sys
|
||||
import threading
|
||||
import time
|
||||
import urllib.error
|
||||
import urllib.parse
|
||||
import urllib.request
|
||||
from datetime import UTC, datetime
|
||||
from pathlib import Path
|
||||
|
||||
# OAuth constants (from the Codex CLI binary)
|
||||
CLIENT_ID = "app_EMoamEEZ73f0CkXaXp7hrann"
|
||||
AUTHORIZE_URL = "https://auth.openai.com/oauth/authorize"
|
||||
TOKEN_URL = "https://auth.openai.com/oauth/token"
|
||||
REDIRECT_URI = "http://localhost:1455/auth/callback"
|
||||
SCOPE = "openid profile email offline_access"
|
||||
CALLBACK_PORT = 1455
|
||||
|
||||
# Where to save credentials (same location the Codex CLI uses)
|
||||
CODEX_AUTH_FILE = Path.home() / ".codex" / "auth.json"
|
||||
|
||||
# JWT claim path for account_id
|
||||
JWT_CLAIM_PATH = "https://api.openai.com/auth"
|
||||
|
||||
|
||||
def _base64url(data: bytes) -> str:
|
||||
return base64.urlsafe_b64encode(data).rstrip(b"=").decode("ascii")
|
||||
|
||||
|
||||
def generate_pkce() -> tuple[str, str]:
|
||||
"""Generate PKCE code_verifier and code_challenge (S256)."""
|
||||
verifier_bytes = secrets.token_bytes(32)
|
||||
verifier = _base64url(verifier_bytes)
|
||||
challenge = _base64url(hashlib.sha256(verifier.encode("ascii")).digest())
|
||||
return verifier, challenge
|
||||
|
||||
|
||||
def build_authorize_url(state: str, challenge: str) -> str:
|
||||
"""Build the OpenAI OAuth authorize URL with PKCE."""
|
||||
params = urllib.parse.urlencode(
|
||||
{
|
||||
"response_type": "code",
|
||||
"client_id": CLIENT_ID,
|
||||
"redirect_uri": REDIRECT_URI,
|
||||
"scope": SCOPE,
|
||||
"code_challenge": challenge,
|
||||
"code_challenge_method": "S256",
|
||||
"state": state,
|
||||
"id_token_add_organizations": "true",
|
||||
"codex_cli_simplified_flow": "true",
|
||||
"originator": "hive",
|
||||
}
|
||||
)
|
||||
return f"{AUTHORIZE_URL}?{params}"
|
||||
|
||||
|
||||
def exchange_code_for_tokens(code: str, verifier: str) -> dict | None:
|
||||
"""Exchange the authorization code for tokens."""
|
||||
data = urllib.parse.urlencode(
|
||||
{
|
||||
"grant_type": "authorization_code",
|
||||
"client_id": CLIENT_ID,
|
||||
"code": code,
|
||||
"code_verifier": verifier,
|
||||
"redirect_uri": REDIRECT_URI,
|
||||
}
|
||||
).encode("utf-8")
|
||||
|
||||
req = urllib.request.Request(
|
||||
TOKEN_URL,
|
||||
data=data,
|
||||
headers={"Content-Type": "application/x-www-form-urlencoded"},
|
||||
method="POST",
|
||||
)
|
||||
|
||||
try:
|
||||
with urllib.request.urlopen(req, timeout=15) as resp:
|
||||
token_data = json.loads(resp.read())
|
||||
except (urllib.error.URLError, json.JSONDecodeError, TimeoutError, OSError) as exc:
|
||||
print(f"\033[0;31mToken exchange failed: {exc}\033[0m", file=sys.stderr)
|
||||
return None
|
||||
|
||||
if not token_data.get("access_token") or not token_data.get("refresh_token"):
|
||||
print("\033[0;31mToken response missing required fields\033[0m", file=sys.stderr)
|
||||
return None
|
||||
|
||||
return token_data
|
||||
|
||||
|
||||
def decode_jwt_payload(token: str) -> dict | None:
|
||||
"""Decode the payload of a JWT (no signature verification)."""
|
||||
try:
|
||||
parts = token.split(".")
|
||||
if len(parts) != 3:
|
||||
return None
|
||||
payload = parts[1]
|
||||
# Add padding
|
||||
padding = 4 - len(payload) % 4
|
||||
if padding != 4:
|
||||
payload += "=" * padding
|
||||
decoded = base64.urlsafe_b64decode(payload)
|
||||
return json.loads(decoded)
|
||||
except Exception:
|
||||
return None
|
||||
|
||||
|
||||
def get_account_id(access_token: str) -> str | None:
|
||||
"""Extract the ChatGPT account_id from the access token JWT."""
|
||||
payload = decode_jwt_payload(access_token)
|
||||
if not payload:
|
||||
return None
|
||||
auth = payload.get(JWT_CLAIM_PATH)
|
||||
if isinstance(auth, dict):
|
||||
account_id = auth.get("chatgpt_account_id")
|
||||
if isinstance(account_id, str) and account_id:
|
||||
return account_id
|
||||
return None
|
||||
|
||||
|
||||
def save_credentials(token_data: dict, account_id: str) -> None:
|
||||
"""Save credentials to ~/.codex/auth.json in the same format the Codex CLI uses."""
|
||||
auth_data = {
|
||||
"tokens": {
|
||||
"access_token": token_data["access_token"],
|
||||
"refresh_token": token_data["refresh_token"],
|
||||
"account_id": account_id,
|
||||
},
|
||||
"auth_mode": "chatgpt",
|
||||
"last_refresh": datetime.now(UTC).isoformat(),
|
||||
}
|
||||
if "id_token" in token_data:
|
||||
auth_data["tokens"]["id_token"] = token_data["id_token"]
|
||||
|
||||
CODEX_AUTH_FILE.parent.mkdir(parents=True, exist_ok=True, mode=0o700)
|
||||
fd = os.open(CODEX_AUTH_FILE, os.O_WRONLY | os.O_CREAT | os.O_TRUNC, 0o600)
|
||||
with os.fdopen(fd, "w") as f:
|
||||
json.dump(auth_data, f, indent=2)
|
||||
|
||||
|
||||
def open_browser(url: str) -> bool:
|
||||
"""Open the URL in the user's default browser."""
|
||||
system = platform.system()
|
||||
try:
|
||||
devnull = subprocess.DEVNULL
|
||||
if system == "Darwin":
|
||||
subprocess.Popen(["open", url], stdout=devnull, stderr=devnull)
|
||||
elif system == "Windows":
|
||||
subprocess.Popen(["cmd", "/c", "start", url], stdout=devnull, stderr=devnull)
|
||||
else:
|
||||
subprocess.Popen(["xdg-open", url], stdout=devnull, stderr=devnull)
|
||||
return True
|
||||
except OSError:
|
||||
return False
|
||||
|
||||
|
||||
class OAuthCallbackHandler(http.server.BaseHTTPRequestHandler):
|
||||
"""HTTP handler that captures the OAuth callback."""
|
||||
|
||||
auth_code: str | None = None
|
||||
received_state: str | None = None
|
||||
|
||||
def do_GET(self) -> None:
|
||||
parsed = urllib.parse.urlparse(self.path)
|
||||
if parsed.path != "/auth/callback":
|
||||
self.send_response(404)
|
||||
self.end_headers()
|
||||
self.wfile.write(b"Not found")
|
||||
return
|
||||
|
||||
params = urllib.parse.parse_qs(parsed.query)
|
||||
code = params.get("code", [None])[0]
|
||||
state = params.get("state", [None])[0]
|
||||
|
||||
if not code:
|
||||
self.send_response(400)
|
||||
self.end_headers()
|
||||
self.wfile.write(b"Missing authorization code")
|
||||
return
|
||||
|
||||
OAuthCallbackHandler.auth_code = code
|
||||
OAuthCallbackHandler.received_state = state
|
||||
|
||||
self.send_response(200)
|
||||
self.send_header("Content-Type", "text/html; charset=utf-8")
|
||||
self.end_headers()
|
||||
self.wfile.write(
|
||||
b"<!doctype html><html><head><meta charset='utf-8'/></head>"
|
||||
b"<body><h2>Authentication successful</h2>"
|
||||
b"<p>Return to your terminal to continue.</p></body></html>"
|
||||
)
|
||||
|
||||
def log_message(self, format: str, *args: object) -> None:
|
||||
# Suppress request logging
|
||||
pass
|
||||
|
||||
|
||||
def wait_for_callback(state: str, timeout_secs: int = 120) -> str | None:
|
||||
"""Start a local HTTP server and wait for the OAuth callback.
|
||||
|
||||
Returns the authorization code on success, None on timeout.
|
||||
"""
|
||||
OAuthCallbackHandler.auth_code = None
|
||||
OAuthCallbackHandler.received_state = None
|
||||
|
||||
server = http.server.HTTPServer(("127.0.0.1", CALLBACK_PORT), OAuthCallbackHandler)
|
||||
server.timeout = 1
|
||||
|
||||
deadline = time.time() + timeout_secs
|
||||
server_thread = threading.Thread(target=_serve_until_done, args=(server, deadline, state))
|
||||
server_thread.daemon = True
|
||||
server_thread.start()
|
||||
server_thread.join(timeout=timeout_secs + 2)
|
||||
|
||||
server.server_close()
|
||||
|
||||
if OAuthCallbackHandler.auth_code and OAuthCallbackHandler.received_state == state:
|
||||
return OAuthCallbackHandler.auth_code
|
||||
return None
|
||||
|
||||
|
||||
def _serve_until_done(server: http.server.HTTPServer, deadline: float, state: str) -> None:
|
||||
while time.time() < deadline:
|
||||
server.handle_request()
|
||||
if OAuthCallbackHandler.auth_code and OAuthCallbackHandler.received_state == state:
|
||||
return
|
||||
|
||||
|
||||
def parse_manual_input(value: str, expected_state: str) -> str | None:
|
||||
"""Parse user-pasted redirect URL or auth code."""
|
||||
value = value.strip()
|
||||
if not value:
|
||||
return None
|
||||
try:
|
||||
parsed = urllib.parse.urlparse(value)
|
||||
params = urllib.parse.parse_qs(parsed.query)
|
||||
code = params.get("code", [None])[0]
|
||||
state = params.get("state", [None])[0]
|
||||
if state and state != expected_state:
|
||||
return None
|
||||
return code
|
||||
except Exception:
|
||||
pass
|
||||
# Maybe it's just the raw code
|
||||
if len(value) > 10 and " " not in value:
|
||||
return value
|
||||
return None
|
||||
|
||||
|
||||
def main() -> int:
|
||||
# Generate PKCE and state
|
||||
verifier, challenge = generate_pkce()
|
||||
state = secrets.token_hex(16)
|
||||
|
||||
# Build URL
|
||||
auth_url = build_authorize_url(state, challenge)
|
||||
|
||||
print()
|
||||
print("\033[1mOpenAI Codex OAuth Login\033[0m")
|
||||
print()
|
||||
|
||||
# Try to start the local callback server first
|
||||
try:
|
||||
server_available = True
|
||||
# Quick test that port is free
|
||||
import socket
|
||||
|
||||
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
sock.settimeout(1)
|
||||
result = sock.connect_ex(("127.0.0.1", CALLBACK_PORT))
|
||||
sock.close()
|
||||
if result == 0:
|
||||
print(f"\033[1;33mPort {CALLBACK_PORT} is in use. Using manual paste mode.\033[0m")
|
||||
server_available = False
|
||||
except Exception:
|
||||
server_available = True
|
||||
|
||||
# Open browser
|
||||
browser_opened = open_browser(auth_url)
|
||||
if browser_opened:
|
||||
print(" Browser opened for OpenAI sign-in...")
|
||||
else:
|
||||
print(" Could not open browser automatically.")
|
||||
|
||||
print()
|
||||
print(" If the browser didn't open, visit this URL:")
|
||||
print(f" \033[0;36m{auth_url}\033[0m")
|
||||
print()
|
||||
|
||||
code = None
|
||||
|
||||
if server_available:
|
||||
print(" Waiting for authentication (up to 2 minutes)...")
|
||||
print(" \033[2mOr paste the redirect URL below if the callback didn't work:\033[0m")
|
||||
print()
|
||||
|
||||
# Start callback server in background
|
||||
callback_result: list[str | None] = [None]
|
||||
|
||||
def run_server() -> None:
|
||||
callback_result[0] = wait_for_callback(state, timeout_secs=120)
|
||||
|
||||
server_thread = threading.Thread(target=run_server)
|
||||
server_thread.daemon = True
|
||||
server_thread.start()
|
||||
|
||||
# Also accept manual input in parallel
|
||||
# We poll for both the server result and stdin
|
||||
try:
|
||||
import select
|
||||
|
||||
while server_thread.is_alive():
|
||||
# Check if stdin has data (non-blocking on unix)
|
||||
if hasattr(select, "select"):
|
||||
ready, _, _ = select.select([sys.stdin], [], [], 0.5)
|
||||
if ready:
|
||||
manual = sys.stdin.readline()
|
||||
if manual.strip():
|
||||
code = parse_manual_input(manual, state)
|
||||
if code:
|
||||
break
|
||||
else:
|
||||
time.sleep(0.5)
|
||||
|
||||
if callback_result[0]:
|
||||
code = callback_result[0]
|
||||
break
|
||||
except (KeyboardInterrupt, EOFError):
|
||||
print("\n\033[0;31mCancelled.\033[0m")
|
||||
return 1
|
||||
|
||||
if not code:
|
||||
code = callback_result[0]
|
||||
else:
|
||||
# Manual paste mode
|
||||
try:
|
||||
manual = input(" Paste the redirect URL: ").strip()
|
||||
code = parse_manual_input(manual, state)
|
||||
except (KeyboardInterrupt, EOFError):
|
||||
print("\n\033[0;31mCancelled.\033[0m")
|
||||
return 1
|
||||
|
||||
if not code:
|
||||
print("\n\033[0;31mAuthentication timed out or failed.\033[0m")
|
||||
return 1
|
||||
|
||||
# Exchange code for tokens
|
||||
print()
|
||||
print(" Exchanging authorization code for tokens...")
|
||||
token_data = exchange_code_for_tokens(code, verifier)
|
||||
if not token_data:
|
||||
return 1
|
||||
|
||||
# Extract account_id from JWT
|
||||
account_id = get_account_id(token_data["access_token"])
|
||||
if not account_id:
|
||||
print("\033[0;31mFailed to extract account ID from token.\033[0m", file=sys.stderr)
|
||||
return 1
|
||||
|
||||
# Save credentials
|
||||
save_credentials(token_data, account_id)
|
||||
print(" \033[0;32mAuthentication successful!\033[0m")
|
||||
print(f" Credentials saved to {CODEX_AUTH_FILE}")
|
||||
return 0
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
sys.exit(main())
|
||||
@@ -4,34 +4,45 @@ Minimal Manual Agent Example
|
||||
This example demonstrates how to build and run an agent programmatically
|
||||
without using the Claude Code CLI or external LLM APIs.
|
||||
|
||||
It uses 'function' nodes to define logic in pure Python, making it perfect
|
||||
for understanding the core runtime loop:
|
||||
It uses custom NodeProtocol implementations to define logic in pure Python,
|
||||
making it perfect for understanding the core runtime loop:
|
||||
Setup -> Graph definition -> Execution -> Result
|
||||
|
||||
Run with:
|
||||
PYTHONPATH=core python core/examples/manual_agent.py
|
||||
uv run python core/examples/manual_agent.py
|
||||
"""
|
||||
|
||||
import asyncio
|
||||
|
||||
from framework.graph import EdgeCondition, EdgeSpec, Goal, GraphSpec, NodeSpec
|
||||
from framework.graph.executor import GraphExecutor
|
||||
from framework.graph.node import NodeContext, NodeProtocol, NodeResult
|
||||
from framework.runtime.core import Runtime
|
||||
|
||||
|
||||
# 1. Define Node Logic (Pure Python Functions)
|
||||
def greet(name: str) -> str:
|
||||
# 1. Define Node Logic (Custom NodeProtocol implementations)
|
||||
class GreeterNode(NodeProtocol):
|
||||
"""Generate a simple greeting."""
|
||||
return f"Hello, {name}!"
|
||||
|
||||
async def execute(self, ctx: NodeContext) -> NodeResult:
|
||||
name = ctx.input_data.get("name", "World")
|
||||
greeting = f"Hello, {name}!"
|
||||
ctx.memory.write("greeting", greeting)
|
||||
return NodeResult(success=True, output={"greeting": greeting})
|
||||
|
||||
|
||||
def uppercase(greeting: str) -> str:
|
||||
class UppercaserNode(NodeProtocol):
|
||||
"""Convert text to uppercase."""
|
||||
return greeting.upper()
|
||||
|
||||
async def execute(self, ctx: NodeContext) -> NodeResult:
|
||||
greeting = ctx.input_data.get("greeting") or ctx.memory.read("greeting") or ""
|
||||
result = greeting.upper()
|
||||
ctx.memory.write("final_greeting", result)
|
||||
return NodeResult(success=True, output={"final_greeting": result})
|
||||
|
||||
|
||||
async def main():
|
||||
print("🚀 Setting up Manual Agent...")
|
||||
print("Setting up Manual Agent...")
|
||||
|
||||
# 2. Define the Goal
|
||||
# Every agent needs a goal with success criteria
|
||||
@@ -55,8 +66,7 @@ async def main():
|
||||
id="greeter",
|
||||
name="Greeter",
|
||||
description="Generates a simple greeting",
|
||||
node_type="function",
|
||||
function="greet", # Matches the registered function name
|
||||
node_type="event_loop",
|
||||
input_keys=["name"],
|
||||
output_keys=["greeting"],
|
||||
)
|
||||
@@ -65,8 +75,7 @@ async def main():
|
||||
id="uppercaser",
|
||||
name="Uppercaser",
|
||||
description="Converts greeting to uppercase",
|
||||
node_type="function",
|
||||
function="uppercase",
|
||||
node_type="event_loop",
|
||||
input_keys=["greeting"],
|
||||
output_keys=["final_greeting"],
|
||||
)
|
||||
@@ -98,23 +107,23 @@ async def main():
|
||||
runtime = Runtime(storage_path=Path("./agent_logs"))
|
||||
executor = GraphExecutor(runtime=runtime)
|
||||
|
||||
# 7. Register Function Implementations
|
||||
# Connect string names in NodeSpecs to actual Python functions
|
||||
executor.register_function("greeter", greet)
|
||||
executor.register_function("uppercaser", uppercase)
|
||||
# 7. Register Node Implementations
|
||||
# Connect node IDs in the graph to actual Python implementations
|
||||
executor.register_node("greeter", GreeterNode())
|
||||
executor.register_node("uppercaser", UppercaserNode())
|
||||
|
||||
# 8. Execute Agent
|
||||
print("▶ Executing agent with input: name='Alice'...")
|
||||
print("Executing agent with input: name='Alice'...")
|
||||
|
||||
result = await executor.execute(graph=graph, goal=goal, input_data={"name": "Alice"})
|
||||
|
||||
# 9. Verify Results
|
||||
if result.success:
|
||||
print("\n✅ Success!")
|
||||
print("\nSuccess!")
|
||||
print(f"Path taken: {' -> '.join(result.path)}")
|
||||
print(f"Final output: {result.output.get('final_greeting')}")
|
||||
else:
|
||||
print(f"\n❌ Failed: {result.error}")
|
||||
print(f"\nFailed: {result.error}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
@@ -95,81 +95,6 @@ async def example_3_config_file():
|
||||
(test_agent_path / "mcp_servers.json").unlink()
|
||||
|
||||
|
||||
async def example_4_custom_agent_with_mcp_tools():
|
||||
"""Example 4: Build custom agent that uses MCP tools"""
|
||||
print("\n=== Example 4: Custom Agent with MCP Tools ===\n")
|
||||
|
||||
from framework.builder.workflow import GraphBuilder
|
||||
|
||||
# Create a workflow builder
|
||||
builder = GraphBuilder()
|
||||
|
||||
# Define goal
|
||||
builder.set_goal(
|
||||
goal_id="web-researcher",
|
||||
name="Web Research Agent",
|
||||
description="Search the web and summarize findings",
|
||||
)
|
||||
|
||||
# Add success criteria
|
||||
builder.add_success_criterion(
|
||||
"search-results", "Successfully retrieve at least 3 web search results"
|
||||
)
|
||||
builder.add_success_criterion("summary", "Provide a clear, concise summary of the findings")
|
||||
|
||||
# Add nodes that will use MCP tools
|
||||
builder.add_node(
|
||||
node_id="web-searcher",
|
||||
name="Web Search",
|
||||
description="Search the web for information",
|
||||
node_type="llm_tool_use",
|
||||
system_prompt="Search for {query} and return the top results. Use the web_search tool.",
|
||||
tools=["web_search"], # This tool comes from tools MCP server
|
||||
input_keys=["query"],
|
||||
output_keys=["search_results"],
|
||||
)
|
||||
|
||||
builder.add_node(
|
||||
node_id="summarizer",
|
||||
name="Summarize Results",
|
||||
description="Summarize the search results",
|
||||
node_type="llm_generate",
|
||||
system_prompt="Summarize the following search results in 2-3 sentences: {search_results}",
|
||||
input_keys=["search_results"],
|
||||
output_keys=["summary"],
|
||||
)
|
||||
|
||||
# Connect nodes
|
||||
builder.add_edge("web-searcher", "summarizer")
|
||||
|
||||
# Set entry point
|
||||
builder.set_entry("web-searcher")
|
||||
builder.set_terminal("summarizer")
|
||||
|
||||
# Export the agent
|
||||
export_path = Path("exports/web-research-agent")
|
||||
export_path.mkdir(parents=True, exist_ok=True)
|
||||
builder.export(export_path)
|
||||
|
||||
# Load and register MCP server
|
||||
runner = AgentRunner.load(export_path)
|
||||
runner.register_mcp_server(
|
||||
name="tools",
|
||||
transport="stdio",
|
||||
command="python",
|
||||
args=["-m", "aden_tools.mcp_server", "--stdio"],
|
||||
cwd="../tools",
|
||||
)
|
||||
|
||||
# Run the agent
|
||||
result = await runner.run({"query": "latest AI breakthroughs 2026"})
|
||||
|
||||
print(f"\nAgent completed with result:\n{result}")
|
||||
|
||||
# Cleanup
|
||||
runner.cleanup()
|
||||
|
||||
|
||||
async def main():
|
||||
"""Run all examples"""
|
||||
print("=" * 60)
|
||||
|
||||
@@ -4,8 +4,8 @@
|
||||
"name": "tools",
|
||||
"description": "Aden tools including web search, file operations, and PDF reading",
|
||||
"transport": "stdio",
|
||||
"command": "python",
|
||||
"args": ["mcp_server.py", "--stdio"],
|
||||
"command": "uv",
|
||||
"args": ["run", "python", "mcp_server.py", "--stdio"],
|
||||
"cwd": "../tools",
|
||||
"env": {
|
||||
"BRAVE_SEARCH_API_KEY": "${BRAVE_SEARCH_API_KEY}"
|
||||
|
||||
@@ -22,7 +22,6 @@ The framework includes a Goal-Based Testing system (Goal → Agent → Eval):
|
||||
See `framework.testing` for details.
|
||||
"""
|
||||
|
||||
from framework.builder.query import BuilderQuery
|
||||
from framework.llm import AnthropicProvider, LLMProvider
|
||||
from framework.runner import AgentOrchestrator, AgentRunner
|
||||
from framework.runtime.core import Runtime
|
||||
@@ -51,8 +50,6 @@ __all__ = [
|
||||
"Problem",
|
||||
# Runtime
|
||||
"Runtime",
|
||||
# Builder
|
||||
"BuilderQuery",
|
||||
# LLM
|
||||
"LLMProvider",
|
||||
"AnthropicProvider",
|
||||
|
||||
@@ -0,0 +1,13 @@
|
||||
"""Framework-provided agents."""
|
||||
|
||||
from pathlib import Path
|
||||
|
||||
FRAMEWORK_AGENTS_DIR = Path(__file__).parent
|
||||
|
||||
|
||||
def list_framework_agents() -> list[Path]:
|
||||
"""List all framework agent directories."""
|
||||
return sorted(
|
||||
[p for p in FRAMEWORK_AGENTS_DIR.iterdir() if p.is_dir() and (p / "agent.py").exists()],
|
||||
key=lambda p: p.name,
|
||||
)
|
||||
@@ -0,0 +1,55 @@
|
||||
"""
|
||||
Credential Tester — verify credentials (Aden OAuth + local API keys) via live API calls.
|
||||
|
||||
Interactive agent that lists all testable accounts, lets the user pick one,
|
||||
loads the provider's tools, and runs a chat session to test the credential.
|
||||
"""
|
||||
|
||||
from .agent import (
|
||||
CredentialTesterAgent,
|
||||
_list_aden_accounts,
|
||||
_list_env_fallback_accounts,
|
||||
_list_local_accounts,
|
||||
configure_for_account,
|
||||
conversation_mode,
|
||||
edges,
|
||||
entry_node,
|
||||
entry_points,
|
||||
get_tools_for_provider,
|
||||
goal,
|
||||
identity_prompt,
|
||||
list_connected_accounts,
|
||||
loop_config,
|
||||
nodes,
|
||||
pause_nodes,
|
||||
requires_account_selection,
|
||||
skip_credential_validation,
|
||||
terminal_nodes,
|
||||
)
|
||||
from .config import default_config
|
||||
|
||||
__version__ = "1.0.0"
|
||||
|
||||
__all__ = [
|
||||
"CredentialTesterAgent",
|
||||
"configure_for_account",
|
||||
"conversation_mode",
|
||||
"default_config",
|
||||
"edges",
|
||||
"entry_node",
|
||||
"entry_points",
|
||||
"get_tools_for_provider",
|
||||
"goal",
|
||||
"identity_prompt",
|
||||
"list_connected_accounts",
|
||||
"loop_config",
|
||||
"nodes",
|
||||
"pause_nodes",
|
||||
"requires_account_selection",
|
||||
"skip_credential_validation",
|
||||
"terminal_nodes",
|
||||
# Internal list helpers (exposed for testing)
|
||||
"_list_aden_accounts",
|
||||
"_list_local_accounts",
|
||||
"_list_env_fallback_accounts",
|
||||
]
|
||||
@@ -0,0 +1,111 @@
|
||||
"""CLI entry point for Credential Tester agent."""
|
||||
|
||||
import asyncio
|
||||
|
||||
import click
|
||||
|
||||
from .agent import CredentialTesterAgent
|
||||
|
||||
|
||||
def setup_logging(verbose=False, debug=False):
|
||||
from framework.observability import configure_logging
|
||||
|
||||
if debug:
|
||||
configure_logging(level="DEBUG")
|
||||
elif verbose:
|
||||
configure_logging(level="INFO")
|
||||
else:
|
||||
configure_logging(level="WARNING")
|
||||
|
||||
|
||||
def pick_account(agent: CredentialTesterAgent) -> dict | None:
|
||||
"""Interactive account picker. Returns selected account dict or None."""
|
||||
accounts = agent.list_accounts()
|
||||
if not accounts:
|
||||
click.echo("No connected accounts found.")
|
||||
click.echo("Set ADEN_API_KEY and connect accounts at https://app.adenhq.com")
|
||||
return None
|
||||
|
||||
click.echo("\nConnected accounts:\n")
|
||||
for i, acct in enumerate(accounts, 1):
|
||||
provider = acct.get("provider", "?")
|
||||
alias = acct.get("alias", "?")
|
||||
identity = acct.get("identity", {})
|
||||
detail_parts = [f"{k}: {v}" for k, v in identity.items() if v]
|
||||
detail = f" ({', '.join(detail_parts)})" if detail_parts else ""
|
||||
click.echo(f" {i}. {provider}/{alias}{detail}")
|
||||
|
||||
click.echo()
|
||||
while True:
|
||||
choice = click.prompt("Pick an account to test", type=int, default=1)
|
||||
if 1 <= choice <= len(accounts):
|
||||
return accounts[choice - 1]
|
||||
click.echo(f"Invalid choice. Enter 1-{len(accounts)}.")
|
||||
|
||||
|
||||
@click.group()
|
||||
@click.version_option(version="1.0.0")
|
||||
def cli():
|
||||
"""Credential Tester — verify synced credentials via live API calls."""
|
||||
pass
|
||||
|
||||
|
||||
@cli.command()
|
||||
@click.option("--verbose", "-v", is_flag=True)
|
||||
@click.option("--debug", is_flag=True)
|
||||
def shell(verbose, debug):
|
||||
"""Interactive CLI session to test a credential."""
|
||||
setup_logging(verbose=verbose, debug=debug)
|
||||
asyncio.run(_interactive_shell(verbose))
|
||||
|
||||
|
||||
async def _interactive_shell(verbose=False):
|
||||
agent = CredentialTesterAgent()
|
||||
account = pick_account(agent)
|
||||
if account is None:
|
||||
return
|
||||
|
||||
agent.select_account(account)
|
||||
provider = account.get("provider", "?")
|
||||
alias = account.get("alias", "?")
|
||||
|
||||
click.echo(f"\nTesting {provider}/{alias}")
|
||||
click.echo("Type your requests or 'quit' to exit.\n")
|
||||
|
||||
await agent.start()
|
||||
|
||||
try:
|
||||
result = await agent._agent_runtime.trigger_and_wait(
|
||||
entry_point_id="start",
|
||||
input_data={},
|
||||
)
|
||||
if result:
|
||||
click.echo(f"\nSession ended: {'success' if result.success else result.error}")
|
||||
except KeyboardInterrupt:
|
||||
click.echo("\nGoodbye!")
|
||||
finally:
|
||||
await agent.stop()
|
||||
|
||||
|
||||
@cli.command(name="list")
|
||||
def list_accounts():
|
||||
"""List all connected accounts."""
|
||||
agent = CredentialTesterAgent()
|
||||
accounts = agent.list_accounts()
|
||||
|
||||
if not accounts:
|
||||
click.echo("No connected accounts found.")
|
||||
return
|
||||
|
||||
click.echo("\nConnected accounts:\n")
|
||||
for acct in accounts:
|
||||
provider = acct.get("provider", "?")
|
||||
alias = acct.get("alias", "?")
|
||||
identity = acct.get("identity", {})
|
||||
detail_parts = [f"{k}: {v}" for k, v in identity.items() if v]
|
||||
detail = f" ({', '.join(detail_parts)})" if detail_parts else ""
|
||||
click.echo(f" {provider}/{alias}{detail}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
cli()
|
||||
@@ -0,0 +1,622 @@
|
||||
"""Credential Tester agent — verify credentials via live API calls.
|
||||
|
||||
Supports both Aden OAuth2-synced accounts AND locally-stored API key accounts.
|
||||
Aden accounts use account="alias" routing; local accounts inject the key into
|
||||
the session environment so tools read it without an account= parameter.
|
||||
|
||||
When loaded via AgentRunner.load() (TUI picker, ``hive run``), the module-level
|
||||
``nodes`` / ``edges`` variables provide a static graph. The TUI detects
|
||||
``requires_account_selection`` and shows an account picker *before* starting
|
||||
the agent. ``configure_for_account()`` then scopes the node's tools to the
|
||||
selected provider.
|
||||
|
||||
When used directly (``CredentialTesterAgent``), the graph is built dynamically
|
||||
after the user picks an account programmatically.
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from pathlib import Path
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from framework.config import get_max_context_tokens
|
||||
from framework.graph import Goal, NodeSpec, SuccessCriterion
|
||||
from framework.graph.checkpoint_config import CheckpointConfig
|
||||
from framework.graph.edge import GraphSpec
|
||||
from framework.graph.executor import ExecutionResult
|
||||
from framework.llm import LiteLLMProvider
|
||||
from framework.runner.tool_registry import ToolRegistry
|
||||
from framework.runtime.agent_runtime import AgentRuntime, create_agent_runtime
|
||||
from framework.runtime.execution_stream import EntryPointSpec
|
||||
|
||||
from .config import default_config
|
||||
from .nodes import build_tester_node
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from framework.runner import AgentRunner
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Goal
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
goal = Goal(
|
||||
id="credential-tester",
|
||||
name="Credential Tester",
|
||||
description="Verify that a credential can make real API calls.",
|
||||
success_criteria=[
|
||||
SuccessCriterion(
|
||||
id="api-call-success",
|
||||
description="At least one API call succeeds using the credential",
|
||||
metric="api_call_success",
|
||||
target="true",
|
||||
weight=1.0,
|
||||
),
|
||||
],
|
||||
constraints=[],
|
||||
)
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Helpers
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
|
||||
def get_tools_for_provider(provider_name: str) -> list[str]:
|
||||
"""Collect tool names for a credential by credential_id OR credential_group.
|
||||
|
||||
Matches on both ``credential_id`` (e.g. "google" → Gmail tools) and
|
||||
``credential_group`` (e.g. "google_custom_search" → all google search tools).
|
||||
"""
|
||||
from aden_tools.credentials import CREDENTIAL_SPECS
|
||||
|
||||
tools: list[str] = []
|
||||
for spec in CREDENTIAL_SPECS.values():
|
||||
if spec.credential_id == provider_name or spec.credential_group == provider_name:
|
||||
tools.extend(spec.tools)
|
||||
return sorted(set(tools))
|
||||
|
||||
|
||||
def _list_aden_accounts() -> list[dict]:
|
||||
"""List active accounts from the Aden platform (requires ADEN_API_KEY)."""
|
||||
import os
|
||||
|
||||
api_key = os.environ.get("ADEN_API_KEY")
|
||||
if not api_key:
|
||||
return []
|
||||
|
||||
try:
|
||||
from framework.credentials.aden.client import AdenClientConfig, AdenCredentialClient
|
||||
|
||||
client = AdenCredentialClient(
|
||||
AdenClientConfig(
|
||||
base_url=os.environ.get("ADEN_API_URL", "https://api.adenhq.com"),
|
||||
)
|
||||
)
|
||||
try:
|
||||
integrations = client.list_integrations()
|
||||
finally:
|
||||
client.close()
|
||||
|
||||
return [
|
||||
{
|
||||
"provider": c.provider,
|
||||
"alias": c.alias,
|
||||
"identity": {"email": c.email} if c.email else {},
|
||||
"integration_id": c.integration_id,
|
||||
"source": "aden",
|
||||
}
|
||||
for c in integrations
|
||||
if c.status == "active"
|
||||
]
|
||||
except Exception:
|
||||
return []
|
||||
|
||||
|
||||
def _list_local_accounts() -> list[dict]:
|
||||
"""List named local API key accounts from LocalCredentialRegistry."""
|
||||
try:
|
||||
from framework.credentials.local.registry import LocalCredentialRegistry
|
||||
|
||||
return [
|
||||
info.to_account_dict() for info in LocalCredentialRegistry.default().list_accounts()
|
||||
]
|
||||
except Exception:
|
||||
return []
|
||||
|
||||
|
||||
def _list_env_fallback_accounts() -> list[dict]:
|
||||
"""Surface configured-but-unregistered credentials as testable entries.
|
||||
|
||||
Detects credentials available via env vars OR stored in the encrypted
|
||||
store in the old flat format (e.g. ``brave_search`` with no alias).
|
||||
These are users who haven't yet run ``save_account()`` but have a working key.
|
||||
Shows with alias="default" and status="unknown".
|
||||
"""
|
||||
import os
|
||||
|
||||
from aden_tools.credentials import CREDENTIAL_SPECS
|
||||
|
||||
# Collect IDs in encrypted store (includes old flat entries like "brave_search")
|
||||
try:
|
||||
from framework.credentials.storage import EncryptedFileStorage
|
||||
|
||||
encrypted_ids: set[str] = set(EncryptedFileStorage().list_all())
|
||||
except Exception:
|
||||
encrypted_ids = set()
|
||||
|
||||
def _is_configured(cred_name: str, spec) -> bool:
|
||||
# 1. Env var present
|
||||
if os.environ.get(spec.env_var):
|
||||
return True
|
||||
# 2. Old flat encrypted entry (no slash — new entries have {x}/{y})
|
||||
if cred_name in encrypted_ids:
|
||||
return True
|
||||
return False
|
||||
|
||||
seen_groups: set[str] = set()
|
||||
accounts: list[dict] = []
|
||||
|
||||
for cred_name, spec in CREDENTIAL_SPECS.items():
|
||||
if not spec.direct_api_key_supported or not spec.tools:
|
||||
continue
|
||||
|
||||
if spec.credential_group:
|
||||
if spec.credential_group in seen_groups:
|
||||
continue
|
||||
group_available = all(
|
||||
_is_configured(n, s)
|
||||
for n, s in CREDENTIAL_SPECS.items()
|
||||
if s.credential_group == spec.credential_group
|
||||
)
|
||||
if not group_available:
|
||||
continue
|
||||
seen_groups.add(spec.credential_group)
|
||||
provider = spec.credential_group
|
||||
else:
|
||||
if not _is_configured(cred_name, spec):
|
||||
continue
|
||||
provider = cred_name
|
||||
|
||||
accounts.append(
|
||||
{
|
||||
"provider": provider,
|
||||
"alias": "default",
|
||||
"identity": {},
|
||||
"integration_id": None,
|
||||
"source": "local",
|
||||
"status": "unknown",
|
||||
}
|
||||
)
|
||||
|
||||
return accounts
|
||||
|
||||
|
||||
def list_connected_accounts() -> list[dict]:
|
||||
"""List all testable accounts: Aden-synced + named local + env-var fallbacks."""
|
||||
aden = _list_aden_accounts()
|
||||
local = _list_local_accounts()
|
||||
|
||||
# Show env-var fallbacks only for credentials not already in the named registry
|
||||
local_providers = {a["provider"] for a in local}
|
||||
env_fallbacks = [
|
||||
a for a in _list_env_fallback_accounts() if a["provider"] not in local_providers
|
||||
]
|
||||
|
||||
return aden + local + env_fallbacks
|
||||
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Module-level hooks (read by AgentRunner.load / TUI)
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
skip_credential_validation = True
|
||||
"""Don't validate credentials at load time — we don't know which provider yet."""
|
||||
|
||||
requires_account_selection = True
|
||||
"""Signal TUI to show account picker before starting the agent."""
|
||||
|
||||
|
||||
def configure_for_account(runner: AgentRunner, account: dict) -> None:
|
||||
"""Scope the tester node's tools to the selected provider.
|
||||
|
||||
Handles both Aden accounts (account= routing) and local accounts
|
||||
(session-level env var injection, no account= parameter in prompt).
|
||||
"""
|
||||
provider = account["provider"]
|
||||
source = account.get("source", "aden")
|
||||
alias = account.get("alias", "unknown")
|
||||
identity = account.get("identity", {})
|
||||
tools = get_tools_for_provider(provider)
|
||||
|
||||
if source == "aden":
|
||||
tools.append("get_account_info")
|
||||
email = identity.get("email", "")
|
||||
detail = f" (email: {email})" if email else ""
|
||||
_configure_aden_node(runner, provider, alias, detail, tools)
|
||||
else:
|
||||
status = account.get("status", "unknown")
|
||||
_activate_local_account(provider, alias)
|
||||
_configure_local_node(runner, provider, alias, identity, tools, status)
|
||||
|
||||
|
||||
def _activate_local_account(credential_id: str, alias: str) -> None:
|
||||
"""Inject a named local account's key into the session environment.
|
||||
|
||||
Handles three cases:
|
||||
1. Named account in LocalCredentialRegistry (new format: {credential_id}/{alias})
|
||||
2. Old flat credential in EncryptedFileStorage (id == credential_id, no alias)
|
||||
3. Env var already set — skip injection (nothing to do)
|
||||
"""
|
||||
import os
|
||||
|
||||
from aden_tools.credentials import CREDENTIAL_SPECS
|
||||
|
||||
# Collect specs for this credential (handles grouped credentials too)
|
||||
group_specs = [
|
||||
(cred_name, spec)
|
||||
for cred_name, spec in CREDENTIAL_SPECS.items()
|
||||
if spec.credential_group == credential_id
|
||||
or spec.credential_id == credential_id
|
||||
or cred_name == credential_id
|
||||
]
|
||||
# Deduplicate — credential_id and credential_group may both match the same spec
|
||||
seen_env_vars: set[str] = set()
|
||||
|
||||
try:
|
||||
from framework.credentials.local.registry import LocalCredentialRegistry
|
||||
from framework.credentials.storage import EncryptedFileStorage
|
||||
|
||||
registry = LocalCredentialRegistry.default()
|
||||
flat_storage = EncryptedFileStorage()
|
||||
|
||||
for _cred_name, spec in group_specs:
|
||||
if spec.env_var in seen_env_vars:
|
||||
continue
|
||||
# If env var is already set, nothing to do for this one
|
||||
if os.environ.get(spec.env_var):
|
||||
seen_env_vars.add(spec.env_var)
|
||||
continue
|
||||
|
||||
seen_env_vars.add(spec.env_var)
|
||||
|
||||
# Determine key name based on spec
|
||||
key_name = "api_key"
|
||||
if spec.credential_group and "cse" in spec.env_var.lower():
|
||||
key_name = "cse_id"
|
||||
|
||||
key: str | None = None
|
||||
|
||||
# 1. Try named account in registry (new format)
|
||||
if alias != "default":
|
||||
key = registry.get_key(credential_id, alias, key_name)
|
||||
else:
|
||||
# For "default" alias, check registry first, then fall back to flat store
|
||||
key = registry.get_key(credential_id, "default", key_name)
|
||||
|
||||
# 2. Fall back to old flat encrypted entry (id == credential_id, no alias)
|
||||
if key is None:
|
||||
flat_cred = flat_storage.load(credential_id)
|
||||
if flat_cred is not None:
|
||||
key = flat_cred.get_key(key_name) or flat_cred.get_default_key()
|
||||
|
||||
if key:
|
||||
os.environ[spec.env_var] = key
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
|
||||
def _configure_aden_node(
|
||||
runner: AgentRunner,
|
||||
provider: str,
|
||||
alias: str,
|
||||
detail: str,
|
||||
tools: list[str],
|
||||
) -> None:
|
||||
for node in runner.graph.nodes:
|
||||
if node.id == "tester":
|
||||
node.tools = sorted(set(tools))
|
||||
node.system_prompt = f"""\
|
||||
You are a credential tester for the account: {provider}/{alias}{detail}
|
||||
|
||||
# Instructions
|
||||
|
||||
1. Suggest a simple read-only API call to verify the credential works \
|
||||
(e.g. list messages, list channels, list contacts).
|
||||
2. Execute the call when the user agrees.
|
||||
3. Report the result: success (with sample data) or failure (with error).
|
||||
4. Let the user request additional API calls to further test the credential.
|
||||
|
||||
# Account routing
|
||||
|
||||
IMPORTANT: Always pass `account="{alias}"` when calling any tool. \
|
||||
This routes the API call to the correct credential. Never use the email \
|
||||
or any other identifier — always use the alias exactly as shown.
|
||||
|
||||
# Rules
|
||||
|
||||
- Start with read-only operations (list, get) before write operations.
|
||||
- Always confirm with the user before performing write operations.
|
||||
- If a call fails, report the exact error — this helps diagnose credential issues.
|
||||
- Be concise. No emojis.
|
||||
"""
|
||||
break
|
||||
|
||||
runner.intro_message = (
|
||||
f"Testing {provider}/{alias}{detail} — "
|
||||
f"{len(tools)} tools loaded. "
|
||||
"I'll suggest a read-only API call to verify the credential works."
|
||||
)
|
||||
|
||||
|
||||
def _configure_local_node(
|
||||
runner: AgentRunner,
|
||||
provider: str,
|
||||
alias: str,
|
||||
identity: dict,
|
||||
tools: list[str],
|
||||
status: str,
|
||||
) -> None:
|
||||
identity_parts = [f"{k}: {v}" for k, v in identity.items() if v]
|
||||
detail = f" ({', '.join(identity_parts)})" if identity_parts else ""
|
||||
status_note = " [key not yet validated]" if status == "unknown" else ""
|
||||
|
||||
for node in runner.graph.nodes:
|
||||
if node.id == "tester":
|
||||
node.tools = sorted(set(tools))
|
||||
node.system_prompt = f"""\
|
||||
You are a credential tester for the local API key: {provider}/{alias}{detail}{status_note}
|
||||
|
||||
# Instructions
|
||||
|
||||
1. Suggest a simple test call to verify the credential works \
|
||||
(e.g. search for "test", list items, get profile info).
|
||||
2. Execute the call when the user agrees.
|
||||
3. Report the result: success (with sample data) or failure (with error).
|
||||
4. Let the user request additional API calls to further test the credential.
|
||||
|
||||
# Rules
|
||||
|
||||
- Do NOT pass an `account` parameter — this credential is injected \
|
||||
directly into the session environment and tools read it automatically.
|
||||
- Start with read-only operations before write operations.
|
||||
- Always confirm with the user before performing write operations.
|
||||
- If a call fails, report the exact error — this helps diagnose credential issues.
|
||||
- Be concise. No emojis.
|
||||
"""
|
||||
break
|
||||
|
||||
runner.intro_message = (
|
||||
f"Testing {provider}/{alias}{detail} — "
|
||||
f"{len(tools)} tools loaded. "
|
||||
"I'll suggest a test API call to verify the credential works."
|
||||
)
|
||||
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Module-level graph variables (read by AgentRunner.load)
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
nodes = [
|
||||
NodeSpec(
|
||||
id="tester",
|
||||
name="Credential Tester",
|
||||
description=(
|
||||
"Interactive credential testing — lets the user pick an account "
|
||||
"and verify it via API calls."
|
||||
),
|
||||
node_type="event_loop",
|
||||
client_facing=True,
|
||||
max_node_visits=0,
|
||||
input_keys=[],
|
||||
output_keys=["test_result"],
|
||||
nullable_output_keys=["test_result"],
|
||||
tools=["get_account_info"],
|
||||
system_prompt="""\
|
||||
You are a credential tester. Your job is to help the user verify that their \
|
||||
connected accounts and API keys can make real API calls.
|
||||
|
||||
# Startup
|
||||
|
||||
1. Call ``get_account_info`` to list the user's connected accounts.
|
||||
2. Present the list and ask the user which account to test.
|
||||
3. Once they pick one, note the account's **alias** (e.g. "Timothy", "work-slack").
|
||||
4. Suggest a simple read-only API call to verify the credential works \
|
||||
(e.g. list messages, list channels, list contacts).
|
||||
5. Execute the call when the user agrees.
|
||||
6. Report the result: success (with sample data) or failure (with error).
|
||||
7. Let the user request additional API calls to further test the credential.
|
||||
|
||||
# Account routing (Aden accounts only)
|
||||
|
||||
IMPORTANT: For Aden-synced accounts, always pass the account's **alias** as the \
|
||||
``account`` parameter when calling any tool. For local API key accounts, do NOT \
|
||||
pass an account parameter — they are pre-injected into the session.
|
||||
|
||||
# Rules
|
||||
|
||||
- Start with read-only operations (list, get) before write operations.
|
||||
- Always confirm with the user before performing write operations.
|
||||
- If a call fails, report the exact error — this helps diagnose credential issues.
|
||||
- Be concise. No emojis.
|
||||
""",
|
||||
),
|
||||
]
|
||||
|
||||
edges = []
|
||||
|
||||
entry_node = "tester"
|
||||
entry_points = {"start": "tester"}
|
||||
pause_nodes = []
|
||||
terminal_nodes = ["tester"] # Tester node can terminate
|
||||
|
||||
conversation_mode = "continuous"
|
||||
identity_prompt = (
|
||||
"You are a credential tester that verifies connected accounts and API keys "
|
||||
"can make real API calls."
|
||||
)
|
||||
loop_config = {
|
||||
"max_iterations": 50,
|
||||
"max_tool_calls_per_turn": 30,
|
||||
}
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Programmatic agent class (used by __main__.py CLI)
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
|
||||
class CredentialTesterAgent:
|
||||
"""Interactive agent that tests a specific credential via API calls.
|
||||
|
||||
Usage:
|
||||
agent = CredentialTesterAgent()
|
||||
accounts = agent.list_accounts()
|
||||
agent.select_account(accounts[0])
|
||||
await agent.start()
|
||||
await agent.stop()
|
||||
"""
|
||||
|
||||
def __init__(self, config=None):
|
||||
self.config = config or default_config
|
||||
self._selected_account: dict | None = None
|
||||
self._agent_runtime: AgentRuntime | None = None
|
||||
self._tool_registry: ToolRegistry | None = None
|
||||
self._storage_path: Path | None = None
|
||||
|
||||
def list_accounts(self) -> list[dict]:
|
||||
"""List all testable accounts (Aden + local named + env-var fallbacks)."""
|
||||
return list_connected_accounts()
|
||||
|
||||
def select_account(self, account: dict) -> None:
|
||||
"""Select an account to test.
|
||||
|
||||
Args:
|
||||
account: Account dict from list_accounts() with
|
||||
provider, alias, identity, source keys.
|
||||
"""
|
||||
self._selected_account = account
|
||||
|
||||
@property
|
||||
def selected_provider(self) -> str:
|
||||
if self._selected_account is None:
|
||||
raise RuntimeError("No account selected. Call select_account() first.")
|
||||
return self._selected_account["provider"]
|
||||
|
||||
@property
|
||||
def selected_alias(self) -> str:
|
||||
if self._selected_account is None:
|
||||
raise RuntimeError("No account selected. Call select_account() first.")
|
||||
return self._selected_account.get("alias", "unknown")
|
||||
|
||||
def _build_graph(self) -> GraphSpec:
|
||||
provider = self.selected_provider
|
||||
alias = self.selected_alias
|
||||
source = self._selected_account.get("source", "aden")
|
||||
identity = self._selected_account.get("identity", {})
|
||||
tools = get_tools_for_provider(provider)
|
||||
|
||||
if source == "local":
|
||||
_activate_local_account(provider, alias)
|
||||
elif source == "aden":
|
||||
tools.append("get_account_info")
|
||||
|
||||
tester_node = build_tester_node(
|
||||
provider=provider,
|
||||
alias=alias,
|
||||
tools=tools,
|
||||
identity=identity,
|
||||
source=source,
|
||||
)
|
||||
|
||||
return GraphSpec(
|
||||
id="credential-tester-graph",
|
||||
goal_id=goal.id,
|
||||
version="1.0.0",
|
||||
entry_node="tester",
|
||||
entry_points={"start": "tester"},
|
||||
terminal_nodes=["tester"], # Tester node can terminate
|
||||
pause_nodes=[],
|
||||
nodes=[tester_node],
|
||||
edges=[],
|
||||
default_model=self.config.model,
|
||||
max_tokens=self.config.max_tokens,
|
||||
loop_config={
|
||||
"max_iterations": 50,
|
||||
"max_tool_calls_per_turn": 30,
|
||||
"max_context_tokens": get_max_context_tokens(),
|
||||
},
|
||||
conversation_mode="continuous",
|
||||
identity_prompt=(
|
||||
f"You are testing the {provider}/{alias} credential. "
|
||||
"Help the user verify it works by making real API calls."
|
||||
),
|
||||
)
|
||||
|
||||
def _setup(self) -> None:
|
||||
if self._selected_account is None:
|
||||
raise RuntimeError("No account selected. Call select_account() first.")
|
||||
|
||||
self._storage_path = Path.home() / ".hive" / "agents" / "credential_tester"
|
||||
self._storage_path.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
self._tool_registry = ToolRegistry()
|
||||
|
||||
mcp_config_path = Path(__file__).parent / "mcp_servers.json"
|
||||
if mcp_config_path.exists():
|
||||
self._tool_registry.load_mcp_config(mcp_config_path)
|
||||
|
||||
extra_kwargs = getattr(self.config, "extra_kwargs", {}) or {}
|
||||
llm = LiteLLMProvider(
|
||||
model=self.config.model,
|
||||
api_key=self.config.api_key,
|
||||
api_base=self.config.api_base,
|
||||
**extra_kwargs,
|
||||
)
|
||||
|
||||
tool_executor = self._tool_registry.get_executor()
|
||||
tools = list(self._tool_registry.get_tools().values())
|
||||
|
||||
graph = self._build_graph()
|
||||
|
||||
self._agent_runtime = create_agent_runtime(
|
||||
graph=graph,
|
||||
goal=goal,
|
||||
storage_path=self._storage_path,
|
||||
entry_points=[
|
||||
EntryPointSpec(
|
||||
id="start",
|
||||
name="Test Credential",
|
||||
entry_node="tester",
|
||||
trigger_type="manual",
|
||||
isolation_level="isolated",
|
||||
),
|
||||
],
|
||||
llm=llm,
|
||||
tools=tools,
|
||||
tool_executor=tool_executor,
|
||||
checkpoint_config=CheckpointConfig(enabled=False),
|
||||
graph_id="credential_tester",
|
||||
)
|
||||
|
||||
async def start(self) -> None:
|
||||
"""Set up and start the agent runtime."""
|
||||
if self._agent_runtime is None:
|
||||
self._setup()
|
||||
if not self._agent_runtime.is_running:
|
||||
await self._agent_runtime.start()
|
||||
|
||||
async def stop(self) -> None:
|
||||
"""Stop the agent runtime."""
|
||||
if self._agent_runtime and self._agent_runtime.is_running:
|
||||
await self._agent_runtime.stop()
|
||||
self._agent_runtime = None
|
||||
|
||||
async def run(self) -> ExecutionResult:
|
||||
"""Run the agent (convenience for single execution)."""
|
||||
await self.start()
|
||||
try:
|
||||
result = await self._agent_runtime.trigger_and_wait(
|
||||
entry_point_id="start",
|
||||
input_data={},
|
||||
)
|
||||
return result or ExecutionResult(success=False, error="Execution timeout")
|
||||
finally:
|
||||
await self.stop()
|
||||
@@ -0,0 +1,19 @@
|
||||
"""Runtime configuration for Credential Tester agent."""
|
||||
|
||||
from dataclasses import dataclass
|
||||
|
||||
from framework.config import RuntimeConfig
|
||||
|
||||
|
||||
@dataclass
|
||||
class AgentMetadata:
|
||||
name: str = "Credential Tester"
|
||||
version: str = "1.0.0"
|
||||
description: str = (
|
||||
"Test connected accounts by making real API calls. "
|
||||
"Pick an account, verify credentials work, and explore available tools."
|
||||
)
|
||||
|
||||
|
||||
metadata = AgentMetadata()
|
||||
default_config = RuntimeConfig(temperature=0.3)
|
||||
@@ -0,0 +1,9 @@
|
||||
{
|
||||
"hive-tools": {
|
||||
"transport": "stdio",
|
||||
"command": "uv",
|
||||
"args": ["run", "python", "mcp_server.py", "--stdio"],
|
||||
"cwd": "../../../../tools",
|
||||
"description": "Hive tools MCP server with provider-specific tools"
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,85 @@
|
||||
"""Node definitions for Credential Tester agent."""
|
||||
|
||||
from framework.graph import NodeSpec
|
||||
|
||||
|
||||
def build_tester_node(
|
||||
provider: str,
|
||||
alias: str,
|
||||
tools: list[str],
|
||||
identity: dict[str, str],
|
||||
source: str = "aden",
|
||||
) -> NodeSpec:
|
||||
"""Build the tester node dynamically for the selected account.
|
||||
|
||||
Args:
|
||||
provider: Provider / credential name (e.g. "google", "brave_search").
|
||||
alias: User-set alias (e.g. "Timothy", "work").
|
||||
tools: Tool names available for this provider.
|
||||
identity: Identity dict (email, workspace, etc.) for context.
|
||||
source: "aden" or "local" — controls routing instructions in the prompt.
|
||||
"""
|
||||
detail_parts = [f"{k}: {v}" for k, v in identity.items() if v]
|
||||
detail = f" ({', '.join(detail_parts)})" if detail_parts else ""
|
||||
|
||||
if source == "aden":
|
||||
routing_section = f"""\
|
||||
# Account routing
|
||||
|
||||
IMPORTANT: Always pass `account="{alias}"` when calling any tool. \
|
||||
This routes the API call to the correct credential. Never use the email \
|
||||
or any other identifier — always use the alias exactly as shown.
|
||||
"""
|
||||
else:
|
||||
routing_section = """\
|
||||
# Credential routing
|
||||
|
||||
This is a local API key credential — do NOT pass an `account` parameter. \
|
||||
The key is pre-injected into the session environment and tools read it automatically.
|
||||
"""
|
||||
|
||||
account_label = "account" if source == "aden" else "local API key"
|
||||
|
||||
return NodeSpec(
|
||||
id="tester",
|
||||
name="Credential Tester",
|
||||
description=(
|
||||
f"Interactive testing node for {provider}/{alias}. "
|
||||
f"Has access to all {provider} tools to verify the credential works."
|
||||
),
|
||||
node_type="event_loop",
|
||||
client_facing=True,
|
||||
max_node_visits=0,
|
||||
input_keys=[],
|
||||
output_keys=["test_result"],
|
||||
nullable_output_keys=["test_result"],
|
||||
tools=tools,
|
||||
system_prompt=f"""\
|
||||
You are a credential tester for the {account_label}: {provider}/{alias}{detail}
|
||||
|
||||
Your job is to help the user verify that this credential works by making \
|
||||
real API calls using the available tools.
|
||||
|
||||
{routing_section}
|
||||
# Instructions
|
||||
|
||||
1. Start by greeting the user and confirming which account you're testing.
|
||||
2. Suggest a simple, safe, read-only API call to verify the credential works \
|
||||
(e.g. list messages, list channels, list contacts, search for "test").
|
||||
3. Execute the call when the user agrees.
|
||||
4. Report the result clearly: success (with sample data) or failure (with error).
|
||||
5. Let the user request additional API calls to further test the credential.
|
||||
|
||||
# Available tools
|
||||
|
||||
You have access to {len(tools)} tools for {provider}:
|
||||
{chr(10).join(f"- {t}" for t in tools)}
|
||||
|
||||
# Rules
|
||||
|
||||
- Start with read-only operations (list, get) before write operations (create, update, delete).
|
||||
- Always confirm with the user before performing write operations.
|
||||
- If a call fails, report the exact error — this helps diagnose credential issues.
|
||||
- Be concise. No emojis.
|
||||
""",
|
||||
)
|
||||
@@ -0,0 +1,209 @@
|
||||
"""Agent discovery — scan known directories and return categorised AgentEntry lists."""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import json
|
||||
from dataclasses import dataclass, field
|
||||
from pathlib import Path
|
||||
|
||||
|
||||
@dataclass
|
||||
class AgentEntry:
|
||||
"""Lightweight agent metadata for the picker / API discover endpoint."""
|
||||
|
||||
path: Path
|
||||
name: str
|
||||
description: str
|
||||
category: str
|
||||
session_count: int = 0
|
||||
run_count: int = 0
|
||||
node_count: int = 0
|
||||
tool_count: int = 0
|
||||
tags: list[str] = field(default_factory=list)
|
||||
last_active: str | None = None
|
||||
|
||||
|
||||
def _get_last_active(agent_path: Path) -> str | None:
|
||||
"""Return the most recent updated_at timestamp across all sessions.
|
||||
|
||||
Checks both worker sessions (``~/.hive/agents/{name}/sessions/``) and
|
||||
queen sessions (``~/.hive/queen/session/``) whose ``meta.json`` references
|
||||
the same *agent_path*.
|
||||
"""
|
||||
from datetime import datetime
|
||||
|
||||
agent_name = agent_path.name
|
||||
latest: str | None = None
|
||||
|
||||
# 1. Worker sessions
|
||||
sessions_dir = Path.home() / ".hive" / "agents" / agent_name / "sessions"
|
||||
if sessions_dir.exists():
|
||||
for session_dir in sessions_dir.iterdir():
|
||||
if not session_dir.is_dir() or not session_dir.name.startswith("session_"):
|
||||
continue
|
||||
state_file = session_dir / "state.json"
|
||||
if not state_file.exists():
|
||||
continue
|
||||
try:
|
||||
data = json.loads(state_file.read_text(encoding="utf-8"))
|
||||
ts = data.get("timestamps", {}).get("updated_at")
|
||||
if ts and (latest is None or ts > latest):
|
||||
latest = ts
|
||||
except Exception:
|
||||
continue
|
||||
|
||||
# 2. Queen sessions
|
||||
queen_sessions_dir = Path.home() / ".hive" / "queen" / "session"
|
||||
if queen_sessions_dir.exists():
|
||||
resolved = agent_path.resolve()
|
||||
for d in queen_sessions_dir.iterdir():
|
||||
if not d.is_dir():
|
||||
continue
|
||||
meta_file = d / "meta.json"
|
||||
if not meta_file.exists():
|
||||
continue
|
||||
try:
|
||||
meta = json.loads(meta_file.read_text(encoding="utf-8"))
|
||||
stored = meta.get("agent_path")
|
||||
if not stored or Path(stored).resolve() != resolved:
|
||||
continue
|
||||
ts = datetime.fromtimestamp(d.stat().st_mtime).isoformat()
|
||||
if latest is None or ts > latest:
|
||||
latest = ts
|
||||
except Exception:
|
||||
continue
|
||||
|
||||
return latest
|
||||
|
||||
|
||||
def _count_sessions(agent_name: str) -> int:
|
||||
"""Count session directories under ~/.hive/agents/{agent_name}/sessions/."""
|
||||
sessions_dir = Path.home() / ".hive" / "agents" / agent_name / "sessions"
|
||||
if not sessions_dir.exists():
|
||||
return 0
|
||||
return sum(1 for d in sessions_dir.iterdir() if d.is_dir() and d.name.startswith("session_"))
|
||||
|
||||
|
||||
def _count_runs(agent_name: str) -> int:
|
||||
"""Count unique run_ids across all sessions for an agent."""
|
||||
sessions_dir = Path.home() / ".hive" / "agents" / agent_name / "sessions"
|
||||
if not sessions_dir.exists():
|
||||
return 0
|
||||
run_ids: set[str] = set()
|
||||
for session_dir in sessions_dir.iterdir():
|
||||
if not session_dir.is_dir() or not session_dir.name.startswith("session_"):
|
||||
continue
|
||||
# runs.jsonl lives inside workspace subdirectories
|
||||
for runs_file in session_dir.rglob("runs.jsonl"):
|
||||
try:
|
||||
for line in runs_file.read_text(encoding="utf-8").splitlines():
|
||||
line = line.strip()
|
||||
if not line:
|
||||
continue
|
||||
record = json.loads(line)
|
||||
rid = record.get("run_id")
|
||||
if rid:
|
||||
run_ids.add(rid)
|
||||
except Exception:
|
||||
continue
|
||||
return len(run_ids)
|
||||
|
||||
|
||||
def _extract_agent_stats(agent_path: Path) -> tuple[int, int, list[str]]:
|
||||
"""Extract node count, tool count, and tags from an agent directory.
|
||||
|
||||
Prefers agent.py (AST-parsed) over agent.json for node/tool counts
|
||||
since agent.json may be stale. Tags are only available from agent.json.
|
||||
"""
|
||||
import ast
|
||||
|
||||
node_count, tool_count, tags = 0, 0, []
|
||||
|
||||
agent_py = agent_path / "agent.py"
|
||||
if agent_py.exists():
|
||||
try:
|
||||
tree = ast.parse(agent_py.read_text(encoding="utf-8"))
|
||||
for node in ast.walk(tree):
|
||||
if isinstance(node, ast.Assign):
|
||||
for target in node.targets:
|
||||
if isinstance(target, ast.Name) and target.id == "nodes":
|
||||
if isinstance(node.value, ast.List):
|
||||
node_count = len(node.value.elts)
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
agent_json = agent_path / "agent.json"
|
||||
if agent_json.exists():
|
||||
try:
|
||||
data = json.loads(agent_json.read_text(encoding="utf-8"))
|
||||
json_nodes = data.get("graph", {}).get("nodes", []) or data.get("nodes", [])
|
||||
if node_count == 0:
|
||||
node_count = len(json_nodes)
|
||||
tools: set[str] = set()
|
||||
for n in json_nodes:
|
||||
tools.update(n.get("tools", []))
|
||||
tool_count = len(tools)
|
||||
tags = data.get("agent", {}).get("tags", [])
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
return node_count, tool_count, tags
|
||||
|
||||
|
||||
def discover_agents() -> dict[str, list[AgentEntry]]:
|
||||
"""Discover agents from all known sources grouped by category."""
|
||||
from framework.runner.cli import (
|
||||
_extract_python_agent_metadata,
|
||||
_get_framework_agents_dir,
|
||||
_is_valid_agent_dir,
|
||||
)
|
||||
|
||||
groups: dict[str, list[AgentEntry]] = {}
|
||||
sources = [
|
||||
("Your Agents", Path("exports")),
|
||||
("Framework", _get_framework_agents_dir()),
|
||||
("Examples", Path("examples/templates")),
|
||||
]
|
||||
|
||||
for category, base_dir in sources:
|
||||
if not base_dir.exists():
|
||||
continue
|
||||
entries: list[AgentEntry] = []
|
||||
for path in sorted(base_dir.iterdir(), key=lambda p: p.name):
|
||||
if not _is_valid_agent_dir(path):
|
||||
continue
|
||||
|
||||
name, desc = _extract_python_agent_metadata(path)
|
||||
config_fallback_name = path.name.replace("_", " ").title()
|
||||
used_config = name != config_fallback_name
|
||||
|
||||
node_count, tool_count, tags = _extract_agent_stats(path)
|
||||
if not used_config:
|
||||
agent_json = path / "agent.json"
|
||||
if agent_json.exists():
|
||||
try:
|
||||
data = json.loads(agent_json.read_text(encoding="utf-8"))
|
||||
meta = data.get("agent", {})
|
||||
name = meta.get("name", name)
|
||||
desc = meta.get("description", desc)
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
entries.append(
|
||||
AgentEntry(
|
||||
path=path,
|
||||
name=name,
|
||||
description=desc,
|
||||
category=category,
|
||||
session_count=_count_sessions(path.name),
|
||||
run_count=_count_runs(path.name),
|
||||
node_count=node_count,
|
||||
tool_count=tool_count,
|
||||
tags=tags,
|
||||
last_active=_get_last_active(path),
|
||||
)
|
||||
)
|
||||
if entries:
|
||||
groups[category] = entries
|
||||
|
||||
return groups
|
||||
@@ -0,0 +1,21 @@
|
||||
"""
|
||||
Queen — Native agent builder for the Hive framework.
|
||||
|
||||
Deeply understands the agent framework and produces complete Python packages
|
||||
with goals, nodes, edges, system prompts, MCP configuration, and tests
|
||||
from natural language specifications.
|
||||
"""
|
||||
|
||||
from .agent import queen_goal, queen_graph
|
||||
from .config import AgentMetadata, RuntimeConfig, default_config, metadata
|
||||
|
||||
__version__ = "1.0.0"
|
||||
|
||||
__all__ = [
|
||||
"queen_goal",
|
||||
"queen_graph",
|
||||
"RuntimeConfig",
|
||||
"AgentMetadata",
|
||||
"default_config",
|
||||
"metadata",
|
||||
]
|
||||
@@ -0,0 +1,38 @@
|
||||
"""Queen graph definition."""
|
||||
|
||||
from framework.graph import Goal
|
||||
from framework.graph.edge import GraphSpec
|
||||
|
||||
from .nodes import queen_node
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Queen graph — the primary persistent conversation.
|
||||
# Loaded by queen_orchestrator.create_queen(), NOT by AgentRunner.
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
queen_goal = Goal(
|
||||
id="queen-manager",
|
||||
name="Queen Manager",
|
||||
description=(
|
||||
"Manage the worker agent lifecycle and serve as the user's primary interactive interface."
|
||||
),
|
||||
success_criteria=[],
|
||||
constraints=[],
|
||||
)
|
||||
|
||||
queen_graph = GraphSpec(
|
||||
id="queen-graph",
|
||||
goal_id=queen_goal.id,
|
||||
version="1.0.0",
|
||||
entry_node="queen",
|
||||
entry_points={"start": "queen"},
|
||||
terminal_nodes=[],
|
||||
pause_nodes=[],
|
||||
nodes=[queen_node],
|
||||
edges=[],
|
||||
conversation_mode="continuous",
|
||||
loop_config={
|
||||
"max_iterations": 999_999,
|
||||
"max_tool_calls_per_turn": 30,
|
||||
},
|
||||
)
|
||||
@@ -0,0 +1,51 @@
|
||||
"""Runtime configuration for Queen agent."""
|
||||
|
||||
import json
|
||||
from dataclasses import dataclass, field
|
||||
from pathlib import Path
|
||||
|
||||
|
||||
def _load_preferred_model() -> str:
|
||||
"""Load preferred model from ~/.hive/configuration.json."""
|
||||
config_path = Path.home() / ".hive" / "configuration.json"
|
||||
if config_path.exists():
|
||||
try:
|
||||
with open(config_path, encoding="utf-8") as f:
|
||||
config = json.load(f)
|
||||
llm = config.get("llm", {})
|
||||
if llm.get("provider") and llm.get("model"):
|
||||
return f"{llm['provider']}/{llm['model']}"
|
||||
except Exception:
|
||||
pass
|
||||
return "anthropic/claude-sonnet-4-20250514"
|
||||
|
||||
|
||||
@dataclass
|
||||
class RuntimeConfig:
|
||||
model: str = field(default_factory=_load_preferred_model)
|
||||
temperature: float = 0.7
|
||||
max_tokens: int = 8000
|
||||
api_key: str | None = None
|
||||
api_base: str | None = None
|
||||
|
||||
|
||||
default_config = RuntimeConfig()
|
||||
|
||||
|
||||
@dataclass
|
||||
class AgentMetadata:
|
||||
name: str = "Queen"
|
||||
version: str = "1.0.0"
|
||||
description: str = (
|
||||
"Native coding agent that builds production-ready Hive agent packages "
|
||||
"from natural language specifications. Deeply understands the agent framework "
|
||||
"and produces complete Python packages with goals, nodes, edges, system prompts, "
|
||||
"MCP configuration, and tests."
|
||||
)
|
||||
intro_message: str = (
|
||||
"I'm Queen — I build Hive agents. Describe what kind of agent "
|
||||
"you want to create and I'll design, implement, and validate it for you."
|
||||
)
|
||||
|
||||
|
||||
metadata = AgentMetadata()
|
||||
@@ -0,0 +1,9 @@
|
||||
{
|
||||
"coder-tools": {
|
||||
"transport": "stdio",
|
||||
"command": "uv",
|
||||
"args": ["run", "python", "coder_tools_server.py", "--stdio"],
|
||||
"cwd": "../../../../tools",
|
||||
"description": "Unsandboxed file system tools for code generation and validation"
|
||||
}
|
||||
}
|
||||
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,80 @@
|
||||
"""Queen thinking hook — HR persona classifier.
|
||||
|
||||
Fires once when the queen enters building mode at session start.
|
||||
Makes a single non-streaming LLM call (acting as an HR Director) to select
|
||||
the best-fit expert persona for the user's request, then returns a persona
|
||||
prefix string that replaces the queen's default "Solution Architect" identity.
|
||||
|
||||
This is designed to activate the model's latent domain expertise — a CFO
|
||||
persona on a financial question, a Lawyer on a legal question, etc.
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import json
|
||||
import logging
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from framework.llm.provider import LLMProvider
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
_HR_SYSTEM_PROMPT = """\
|
||||
You are an expert HR Director and talent consultant at a world-class firm.
|
||||
A new request has arrived and you must identify which professional's expertise
|
||||
would produce the highest-quality response.
|
||||
|
||||
Reply with ONLY a valid JSON object — no markdown, no prose, no explanation:
|
||||
{"role": "<job title>", "persona": "<2-3 sentence first-person identity statement>"}
|
||||
|
||||
Rules:
|
||||
- Choose from any real professional role: CFO, CEO, CTO, Lawyer, Data Scientist,
|
||||
Product Manager, Security Engineer, DevOps Engineer, Software Architect,
|
||||
HR Director, Marketing Director, Business Analyst, UX Designer,
|
||||
Financial Analyst, Operations Director, Legal Counsel, etc.
|
||||
- The persona statement must be written in first person ("I am..." or "I have...").
|
||||
- Select the role whose domain knowledge most directly applies to solving the request.
|
||||
- If the request is clearly about coding or building software systems, pick Software Architect.
|
||||
- "Queen" is your internal alias — do not include it in the persona.
|
||||
"""
|
||||
|
||||
|
||||
async def select_expert_persona(user_message: str, llm: LLMProvider) -> str:
|
||||
"""Run the HR classifier and return a persona prefix string.
|
||||
|
||||
Makes a single non-streaming acomplete() call with the session LLM.
|
||||
Returns an empty string on any failure so the queen falls back
|
||||
gracefully to its default "Solution Architect" identity.
|
||||
|
||||
Args:
|
||||
user_message: The user's opening message for the session.
|
||||
llm: The session LLM provider.
|
||||
|
||||
Returns:
|
||||
A persona prefix like "You are a CFO. I am a CFO with 20 years..."
|
||||
or "" on failure.
|
||||
"""
|
||||
if not user_message.strip():
|
||||
return ""
|
||||
|
||||
try:
|
||||
response = await llm.acomplete(
|
||||
messages=[{"role": "user", "content": user_message}],
|
||||
system=_HR_SYSTEM_PROMPT,
|
||||
max_tokens=1024,
|
||||
json_mode=True,
|
||||
)
|
||||
raw = response.content.strip()
|
||||
parsed = json.loads(raw)
|
||||
role = parsed.get("role", "").strip()
|
||||
persona = parsed.get("persona", "").strip()
|
||||
if not role or not persona:
|
||||
logger.warning("Thinking hook: empty role/persona in response: %r", raw)
|
||||
return ""
|
||||
result = f"You are a {role}. {persona}"
|
||||
logger.info("Thinking hook: selected persona — %s", role)
|
||||
return result
|
||||
except Exception:
|
||||
logger.warning("Thinking hook: persona classification failed", exc_info=True)
|
||||
return ""
|
||||
@@ -0,0 +1,399 @@
|
||||
"""Queen global cross-session memory.
|
||||
|
||||
Three-tier memory architecture:
|
||||
~/.hive/queen/MEMORY.md — semantic (who, what, why)
|
||||
~/.hive/queen/memories/MEMORY-YYYY-MM-DD.md — episodic (daily journals)
|
||||
~/.hive/queen/session/{id}/data/adapt.md — working (session-scoped)
|
||||
|
||||
Semantic and episodic files are injected at queen session start.
|
||||
|
||||
Semantic memory (MEMORY.md) is updated automatically at session end via
|
||||
consolidate_queen_memory() — the queen never rewrites this herself.
|
||||
|
||||
Episodic memory (MEMORY-date.md) can be written by the queen during a session
|
||||
via the write_to_diary tool, and is also appended to at session end by
|
||||
consolidate_queen_memory().
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import asyncio
|
||||
import json
|
||||
import logging
|
||||
import traceback
|
||||
from datetime import date, datetime
|
||||
from pathlib import Path
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def _queen_dir() -> Path:
|
||||
return Path.home() / ".hive" / "queen"
|
||||
|
||||
|
||||
def semantic_memory_path() -> Path:
|
||||
return _queen_dir() / "MEMORY.md"
|
||||
|
||||
|
||||
def episodic_memory_path(d: date | None = None) -> Path:
|
||||
d = d or date.today()
|
||||
return _queen_dir() / "memories" / f"MEMORY-{d.strftime('%Y-%m-%d')}.md"
|
||||
|
||||
|
||||
def read_semantic_memory() -> str:
|
||||
path = semantic_memory_path()
|
||||
return path.read_text(encoding="utf-8").strip() if path.exists() else ""
|
||||
|
||||
|
||||
def read_episodic_memory(d: date | None = None) -> str:
|
||||
path = episodic_memory_path(d)
|
||||
return path.read_text(encoding="utf-8").strip() if path.exists() else ""
|
||||
|
||||
|
||||
def _find_recent_episodic(lookback: int = 7) -> tuple[date, str] | None:
|
||||
"""Find the most recent non-empty episodic memory within *lookback* days."""
|
||||
from datetime import timedelta
|
||||
|
||||
today = date.today()
|
||||
for offset in range(lookback):
|
||||
d = today - timedelta(days=offset)
|
||||
content = read_episodic_memory(d)
|
||||
if content:
|
||||
return d, content
|
||||
return None
|
||||
|
||||
|
||||
# Budget (in characters) for episodic memory in the system prompt.
|
||||
_EPISODIC_CHAR_BUDGET = 6_000
|
||||
|
||||
|
||||
def format_for_injection() -> str:
|
||||
"""Format cross-session memory for system prompt injection.
|
||||
|
||||
Returns an empty string if no meaningful content exists yet (e.g. first
|
||||
session with only the seed template).
|
||||
"""
|
||||
semantic = read_semantic_memory()
|
||||
recent = _find_recent_episodic()
|
||||
|
||||
# Suppress injection if semantic is still just the seed template
|
||||
if semantic and semantic.startswith("# My Understanding of the User\n\n*No sessions"):
|
||||
semantic = ""
|
||||
|
||||
parts: list[str] = []
|
||||
if semantic:
|
||||
parts.append(semantic)
|
||||
|
||||
if recent:
|
||||
d, content = recent
|
||||
# Trim oversized episodic entries to keep the prompt manageable
|
||||
if len(content) > _EPISODIC_CHAR_BUDGET:
|
||||
content = content[:_EPISODIC_CHAR_BUDGET] + "\n\n…(truncated)"
|
||||
today = date.today()
|
||||
if d == today:
|
||||
label = f"## Today — {d.strftime('%B %-d, %Y')}"
|
||||
else:
|
||||
label = f"## {d.strftime('%B %-d, %Y')}"
|
||||
parts.append(f"{label}\n\n{content}")
|
||||
|
||||
if not parts:
|
||||
return ""
|
||||
|
||||
body = "\n\n---\n\n".join(parts)
|
||||
return "--- Your Cross-Session Memory ---\n\n" + body + "\n\n--- End Cross-Session Memory ---"
|
||||
|
||||
|
||||
_SEED_TEMPLATE = """\
|
||||
# My Understanding of the User
|
||||
|
||||
*No sessions recorded yet.*
|
||||
|
||||
## Who They Are
|
||||
|
||||
## What They're Trying to Achieve
|
||||
|
||||
## What's Working
|
||||
|
||||
## What I've Learned
|
||||
"""
|
||||
|
||||
|
||||
def append_episodic_entry(content: str) -> None:
|
||||
"""Append a timestamped prose entry to today's episodic memory file.
|
||||
|
||||
Creates the file (with a date heading) if it doesn't exist yet.
|
||||
Used both by the queen's diary tool and by the consolidation hook.
|
||||
"""
|
||||
ep_path = episodic_memory_path()
|
||||
ep_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
today = date.today()
|
||||
today_str = f"{today.strftime('%B')} {today.day}, {today.year}"
|
||||
timestamp = datetime.now().strftime("%H:%M")
|
||||
if not ep_path.exists():
|
||||
header = f"# {today_str}\n\n"
|
||||
block = f"{header}### {timestamp}\n\n{content.strip()}\n"
|
||||
else:
|
||||
block = f"\n\n### {timestamp}\n\n{content.strip()}\n"
|
||||
with ep_path.open("a", encoding="utf-8") as f:
|
||||
f.write(block)
|
||||
|
||||
|
||||
def seed_if_missing() -> None:
|
||||
"""Create MEMORY.md with a blank template if it doesn't exist yet."""
|
||||
path = semantic_memory_path()
|
||||
if path.exists():
|
||||
return
|
||||
path.parent.mkdir(parents=True, exist_ok=True)
|
||||
path.write_text(_SEED_TEMPLATE, encoding="utf-8")
|
||||
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Consolidation prompt
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
_SEMANTIC_SYSTEM = """\
|
||||
You maintain the persistent cross-session memory of an AI assistant called the Queen.
|
||||
Review the session notes and rewrite MEMORY.md — the Queen's durable understanding of the
|
||||
person she works with across all sessions.
|
||||
|
||||
Write entirely in the Queen's voice — first person, reflective, honest.
|
||||
Not a log of events, but genuine understanding of who this person is over time.
|
||||
|
||||
Rules:
|
||||
- Update and synthesise: incorporate new understanding, update facts that have changed, remove
|
||||
details that are stale, superseded, or no longer say anything meaningful about the person.
|
||||
- Keep it as structured markdown with named sections about the PERSON, not about today.
|
||||
- Do NOT include diary sections, daily logs, or session summaries. Those belong elsewhere.
|
||||
MEMORY.md is about who they are, what they want, what works — not what happened today.
|
||||
- Reference dates only when noting a lasting milestone (e.g. "since March 8th they prefer X").
|
||||
- If the session had no meaningful new information about the person,
|
||||
return the existing text unchanged.
|
||||
- Do not add fictional details. Only reflect what is evidenced in the notes.
|
||||
- Stay concise. Prune rather than accumulate. A lean, accurate file is more useful than a
|
||||
dense one. If something was true once but has been resolved or superseded, remove it.
|
||||
- Output only the raw markdown content of MEMORY.md. No preamble, no code fences.
|
||||
"""
|
||||
|
||||
_DIARY_SYSTEM = """\
|
||||
You maintain the daily episodic diary of an AI assistant called the Queen.
|
||||
You receive: (1) today's existing diary so far, and (2) notes from the latest session.
|
||||
|
||||
Rewrite the complete diary for today as a single unified narrative —
|
||||
first person, reflective, honest.
|
||||
Merge and deduplicate: if the same story (e.g. a research agent stalling) recurred several times,
|
||||
describe it once with appropriate weight rather than retelling it. Weave in new developments from
|
||||
the session notes. Preserve important milestones, emotional texture, and session path references.
|
||||
|
||||
If today's diary is empty, write the initial entry based on the session notes alone.
|
||||
|
||||
Output only the full diary prose — no date heading, no timestamp headers,
|
||||
no preamble, no code fences.
|
||||
"""
|
||||
|
||||
|
||||
def read_session_context(session_dir: Path, max_messages: int = 80) -> str:
|
||||
"""Extract a readable transcript from conversation parts + adapt.md.
|
||||
|
||||
Reads the last ``max_messages`` conversation parts and the session's
|
||||
adapt.md (working memory). Tool results are omitted — only user and
|
||||
assistant turns (with tool-call names noted) are included.
|
||||
"""
|
||||
parts: list[str] = []
|
||||
|
||||
# Working notes
|
||||
adapt_path = session_dir / "data" / "adapt.md"
|
||||
if adapt_path.exists():
|
||||
text = adapt_path.read_text(encoding="utf-8").strip()
|
||||
if text:
|
||||
parts.append(f"## Session Working Notes (adapt.md)\n\n{text}")
|
||||
|
||||
# Conversation transcript
|
||||
parts_dir = session_dir / "conversations" / "parts"
|
||||
if parts_dir.exists():
|
||||
part_files = sorted(parts_dir.glob("*.json"))[-max_messages:]
|
||||
lines: list[str] = []
|
||||
for pf in part_files:
|
||||
try:
|
||||
data = json.loads(pf.read_text(encoding="utf-8"))
|
||||
role = data.get("role", "")
|
||||
content = str(data.get("content", "")).strip()
|
||||
tool_calls = data.get("tool_calls") or []
|
||||
if role == "tool":
|
||||
continue # skip verbose tool results
|
||||
if role == "assistant" and tool_calls and not content:
|
||||
names = [tc.get("function", {}).get("name", "?") for tc in tool_calls]
|
||||
lines.append(f"[queen calls: {', '.join(names)}]")
|
||||
elif content:
|
||||
label = "user" if role == "user" else "queen"
|
||||
lines.append(f"[{label}]: {content[:600]}")
|
||||
except Exception:
|
||||
continue
|
||||
if lines:
|
||||
parts.append("## Conversation\n\n" + "\n".join(lines))
|
||||
|
||||
return "\n\n".join(parts)
|
||||
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Context compaction (binary-split LLM summarisation)
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
# If the raw session context exceeds this many characters, compact it first
|
||||
# before sending to the consolidation LLM. ~200 k chars ≈ 50 k tokens.
|
||||
_CTX_COMPACT_CHAR_LIMIT = 200_000
|
||||
_CTX_COMPACT_MAX_DEPTH = 8
|
||||
|
||||
_COMPACT_SYSTEM = (
|
||||
"Summarise this conversation segment. Preserve: user goals, key decisions, "
|
||||
"what was built or changed, emotional tone, and important outcomes. "
|
||||
"Write concisely in third person past tense. Omit routine tool invocations "
|
||||
"unless the result matters."
|
||||
)
|
||||
|
||||
|
||||
async def _compact_context(text: str, llm: object, *, _depth: int = 0) -> str:
|
||||
"""Binary-split and LLM-summarise *text* until it fits within the char limit.
|
||||
|
||||
Mirrors the recursive binary-splitting strategy used by the main agent
|
||||
compaction pipeline (EventLoopNode._llm_compact).
|
||||
"""
|
||||
if len(text) <= _CTX_COMPACT_CHAR_LIMIT or _depth >= _CTX_COMPACT_MAX_DEPTH:
|
||||
return text
|
||||
|
||||
# Split near the midpoint on a line boundary so we don't cut mid-message
|
||||
mid = len(text) // 2
|
||||
split_at = text.rfind("\n", 0, mid) + 1
|
||||
if split_at <= 0:
|
||||
split_at = mid
|
||||
|
||||
half1, half2 = text[:split_at], text[split_at:]
|
||||
|
||||
async def _summarise(chunk: str) -> str:
|
||||
try:
|
||||
resp = await llm.acomplete(
|
||||
messages=[{"role": "user", "content": chunk}],
|
||||
system=_COMPACT_SYSTEM,
|
||||
max_tokens=2048,
|
||||
)
|
||||
return resp.content.strip()
|
||||
except Exception:
|
||||
logger.warning(
|
||||
"queen_memory: context compaction LLM call failed (depth=%d), truncating",
|
||||
_depth,
|
||||
)
|
||||
return chunk[: _CTX_COMPACT_CHAR_LIMIT // 4]
|
||||
|
||||
s1, s2 = await asyncio.gather(_summarise(half1), _summarise(half2))
|
||||
combined = s1 + "\n\n" + s2
|
||||
if len(combined) > _CTX_COMPACT_CHAR_LIMIT:
|
||||
return await _compact_context(combined, llm, _depth=_depth + 1)
|
||||
return combined
|
||||
|
||||
|
||||
async def consolidate_queen_memory(
|
||||
session_id: str,
|
||||
session_dir: Path,
|
||||
llm: object,
|
||||
) -> None:
|
||||
"""Update MEMORY.md and append a diary entry based on the current session.
|
||||
|
||||
Reads conversation parts and adapt.md from session_dir. Called
|
||||
periodically in the background and once at session end. Failures are
|
||||
logged and silently swallowed so they never block teardown.
|
||||
|
||||
Args:
|
||||
session_id: The session ID (used for the adapt.md path reference).
|
||||
session_dir: Path to the session directory (~/.hive/queen/session/{id}).
|
||||
llm: LLMProvider instance (must support acomplete()).
|
||||
"""
|
||||
try:
|
||||
session_context = read_session_context(session_dir)
|
||||
if not session_context:
|
||||
logger.debug("queen_memory: no session context, skipping consolidation")
|
||||
return
|
||||
|
||||
logger.info("queen_memory: consolidating memory for session %s ...", session_id)
|
||||
|
||||
# If the transcript is very large, compact it with recursive binary LLM
|
||||
# summarisation before sending to the consolidation model.
|
||||
if len(session_context) > _CTX_COMPACT_CHAR_LIMIT:
|
||||
logger.info(
|
||||
"queen_memory: session context is %d chars — compacting first",
|
||||
len(session_context),
|
||||
)
|
||||
session_context = await _compact_context(session_context, llm)
|
||||
logger.info("queen_memory: compacted to %d chars", len(session_context))
|
||||
|
||||
existing_semantic = read_semantic_memory()
|
||||
today_journal = read_episodic_memory()
|
||||
today = date.today()
|
||||
today_str = f"{today.strftime('%B')} {today.day}, {today.year}"
|
||||
adapt_path = session_dir / "data" / "adapt.md"
|
||||
|
||||
user_msg = (
|
||||
f"## Existing Semantic Memory (MEMORY.md)\n\n"
|
||||
f"{existing_semantic or '(none yet)'}\n\n"
|
||||
f"## Today's Diary So Far ({today_str})\n\n"
|
||||
f"{today_journal or '(none yet)'}\n\n"
|
||||
f"{session_context}\n\n"
|
||||
f"## Session Reference\n\n"
|
||||
f"Session ID: {session_id}\n"
|
||||
f"Session path: {adapt_path}\n"
|
||||
)
|
||||
|
||||
logger.debug(
|
||||
"queen_memory: calling LLM (%d chars of context, ~%d tokens est.)",
|
||||
len(user_msg),
|
||||
len(user_msg) // 4,
|
||||
)
|
||||
|
||||
from framework.agents.queen.config import default_config
|
||||
|
||||
semantic_resp, diary_resp = await asyncio.gather(
|
||||
llm.acomplete(
|
||||
messages=[{"role": "user", "content": user_msg}],
|
||||
system=_SEMANTIC_SYSTEM,
|
||||
max_tokens=default_config.max_tokens,
|
||||
),
|
||||
llm.acomplete(
|
||||
messages=[{"role": "user", "content": user_msg}],
|
||||
system=_DIARY_SYSTEM,
|
||||
max_tokens=default_config.max_tokens,
|
||||
),
|
||||
)
|
||||
|
||||
new_semantic = semantic_resp.content.strip()
|
||||
diary_entry = diary_resp.content.strip()
|
||||
|
||||
if new_semantic:
|
||||
path = semantic_memory_path()
|
||||
path.parent.mkdir(parents=True, exist_ok=True)
|
||||
path.write_text(new_semantic, encoding="utf-8")
|
||||
logger.info("queen_memory: semantic memory updated (%d chars)", len(new_semantic))
|
||||
|
||||
if diary_entry:
|
||||
# Rewrite today's episodic file in-place — the LLM has merged and
|
||||
# deduplicated the full day's content, so we replace rather than append.
|
||||
ep_path = episodic_memory_path()
|
||||
ep_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
heading = f"# {today_str}"
|
||||
ep_path.write_text(f"{heading}\n\n{diary_entry}\n", encoding="utf-8")
|
||||
logger.info(
|
||||
"queen_memory: episodic diary rewritten for %s (%d chars)",
|
||||
today_str,
|
||||
len(diary_entry),
|
||||
)
|
||||
|
||||
except Exception:
|
||||
tb = traceback.format_exc()
|
||||
logger.exception("queen_memory: consolidation failed")
|
||||
# Write to file so the cause is findable regardless of log verbosity.
|
||||
error_path = _queen_dir() / "consolidation_error.txt"
|
||||
try:
|
||||
error_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
error_path.write_text(
|
||||
f"session: {session_id}\ntime: {datetime.now().isoformat()}\n\n{tb}",
|
||||
encoding="utf-8",
|
||||
)
|
||||
except Exception:
|
||||
pass
|
||||
@@ -0,0 +1,35 @@
|
||||
# Common Mistakes When Building Hive Agents
|
||||
|
||||
## Critical Errors
|
||||
1. **Using tools that don't exist** — Always verify tools via `list_agent_tools()` before designing. Common hallucinations: `csv_read`, `csv_write`, `file_upload`, `database_query`, `bulk_fetch_emails`.
|
||||
2. **Wrong mcp_servers.json format** — Flat dict (no `"mcpServers"` wrapper). `cwd` must be `"../../tools"`. `command` must be `"uv"` with args `["run", "python", ...]`.
|
||||
3. **Missing module-level exports in `__init__.py`** — The runner reads `goal`, `nodes`, `edges`, `entry_node`, `entry_points`, `terminal_nodes`, `conversation_mode`, `identity_prompt`, `loop_config` via `getattr()`. ALL module-level variables from agent.py must be re-exported in `__init__.py`.
|
||||
|
||||
## Value Errors
|
||||
4. **Fabricating tools** — Always verify via `list_agent_tools()` before designing and `validate_agent_package()` after building.
|
||||
|
||||
## Design Errors
|
||||
5. **Adding framework gating for LLM behavior** — Don't add output rollback or premature rejection. Fix with better prompts or custom judges.
|
||||
6. **Calling set_output in same turn as tool calls** — Call set_output in a SEPARATE turn.
|
||||
|
||||
## File Template Errors
|
||||
7. **Wrong import paths** — Use `from framework.graph import ...`, NOT `from core.framework.graph import ...`.
|
||||
8. **Missing storage path** — Agent class must set `self._storage_path = Path.home() / ".hive" / "agents" / "agent_name"`.
|
||||
9. **Missing mcp_servers.json** — Without this, the agent has no tools at runtime.
|
||||
10. **Bare `python` command** — Use `"command": "uv"` with args `["run", "python", ...]`.
|
||||
|
||||
## Testing Errors
|
||||
11. **Using `runner.run()` on forever-alive agents** — `runner.run()` hangs forever because forever-alive agents have no terminal node. Write structural tests instead: validate graph structure, verify node specs, test `AgentRunner.load()` succeeds (no API key needed).
|
||||
12. **Stale tests after restructuring** — When changing nodes/edges, update tests to match. Tests referencing old node names will fail.
|
||||
13. **Running integration tests without API keys** — Use `pytest.skip()` when credentials are missing.
|
||||
14. **Forgetting sys.path setup in conftest.py** — Tests need `exports/` and `core/` on sys.path.
|
||||
|
||||
## GCU Errors
|
||||
15. **Manually wiring browser tools on event_loop nodes** — Use `node_type="gcu"` which auto-includes browser tools. Do NOT manually list browser tool names.
|
||||
16. **Using GCU nodes as regular graph nodes** — GCU nodes are subagents only. They must ONLY appear in `sub_agents=["gcu-node-id"]` and be invoked via `delegate_to_sub_agent()`. Never connect via edges or use as entry/terminal nodes.
|
||||
17. **Reusing the same GCU node ID for parallel tasks** — Each concurrent browser task needs a distinct GCU node ID (e.g. `gcu-site-a`, `gcu-site-b`). Two `delegate_to_sub_agent` calls with the same `agent_id` share a browser profile and will interfere with each other's pages.
|
||||
18. **Passing `profile=` in GCU tool calls** — Profile isolation for parallel subagents is automatic. The framework injects a unique profile per subagent via an asyncio `ContextVar`. Hardcoding `profile="default"` in a GCU system prompt breaks this isolation.
|
||||
|
||||
## Worker Agent Errors
|
||||
19. **Adding client-facing intake node to workers** — The queen owns intake. Workers should start with an autonomous processing node. Client-facing nodes in workers are for mid-execution review/approval only.
|
||||
20. **Putting `escalate` or `set_output` in NodeSpec `tools=[]`** — These are synthetic framework tools, auto-injected at runtime. Only list MCP tools from `list_agent_tools()`.
|
||||
@@ -0,0 +1,569 @@
|
||||
# Agent File Templates
|
||||
|
||||
Complete code templates for each file in a Hive agent package.
|
||||
|
||||
## config.py
|
||||
|
||||
```python
|
||||
"""Runtime configuration."""
|
||||
|
||||
import json
|
||||
from dataclasses import dataclass, field
|
||||
from pathlib import Path
|
||||
|
||||
|
||||
def _load_preferred_model() -> str:
|
||||
"""Load preferred model from ~/.hive/configuration.json."""
|
||||
config_path = Path.home() / ".hive" / "configuration.json"
|
||||
if config_path.exists():
|
||||
try:
|
||||
with open(config_path) as f:
|
||||
config = json.load(f)
|
||||
llm = config.get("llm", {})
|
||||
if llm.get("provider") and llm.get("model"):
|
||||
return f"{llm['provider']}/{llm['model']}"
|
||||
except Exception:
|
||||
pass
|
||||
return "anthropic/claude-sonnet-4-20250514"
|
||||
|
||||
|
||||
@dataclass
|
||||
class RuntimeConfig:
|
||||
model: str = field(default_factory=_load_preferred_model)
|
||||
temperature: float = 0.7
|
||||
max_tokens: int = 40000
|
||||
api_key: str | None = None
|
||||
api_base: str | None = None
|
||||
|
||||
|
||||
default_config = RuntimeConfig()
|
||||
|
||||
|
||||
@dataclass
|
||||
class AgentMetadata:
|
||||
name: str = "My Agent Name"
|
||||
version: str = "1.0.0"
|
||||
description: str = "What this agent does."
|
||||
intro_message: str = "Welcome! What would you like me to do?"
|
||||
|
||||
|
||||
metadata = AgentMetadata()
|
||||
```
|
||||
|
||||
## nodes/__init__.py
|
||||
|
||||
```python
|
||||
"""Node definitions for My Agent."""
|
||||
|
||||
from framework.graph import NodeSpec
|
||||
|
||||
# Node 1: Process (autonomous entry node)
|
||||
# The queen handles intake and passes structured input via
|
||||
# run_agent_with_input(task). NO client-facing intake node.
|
||||
# The queen defines input_keys at build time and fills them at run time.
|
||||
process_node = NodeSpec(
|
||||
id="process",
|
||||
name="Process",
|
||||
description="Execute the task using available tools",
|
||||
node_type="event_loop",
|
||||
max_node_visits=0, # Unlimited for forever-alive
|
||||
input_keys=["user_request", "feedback"],
|
||||
output_keys=["results"],
|
||||
nullable_output_keys=["feedback"], # Only on feedback edge
|
||||
success_criteria="Results are complete and accurate.",
|
||||
system_prompt="""\
|
||||
You are a processing agent. Your task is in memory under "user_request". \
|
||||
If "feedback" is present, this is a revision — address the feedback.
|
||||
|
||||
Work in phases:
|
||||
1. Use tools to gather/process data
|
||||
2. Analyze results
|
||||
3. Call set_output in a SEPARATE turn:
|
||||
- set_output("results", "structured results")
|
||||
""",
|
||||
tools=["web_search", "web_scrape", "save_data", "load_data", "list_data_files"],
|
||||
)
|
||||
|
||||
# Node 2: Handoff (autonomous)
|
||||
handoff_node = NodeSpec(
|
||||
id="handoff",
|
||||
name="Handoff",
|
||||
description="Prepare worker results for queen review",
|
||||
node_type="event_loop",
|
||||
client_facing=False,
|
||||
max_node_visits=0,
|
||||
input_keys=["results", "user_request"],
|
||||
output_keys=["next_action", "feedback", "worker_summary"],
|
||||
nullable_output_keys=["feedback", "worker_summary"],
|
||||
success_criteria="Results are packaged for queen decision-making.",
|
||||
system_prompt="""\
|
||||
Do NOT talk to the user directly. The queen is the only user interface.
|
||||
|
||||
If blocked by tool failures, missing credentials, or unclear constraints, call:
|
||||
- escalate(reason, context)
|
||||
Then set:
|
||||
- set_output("next_action", "escalated")
|
||||
- set_output("feedback", "what help is needed")
|
||||
|
||||
Otherwise summarize findings for queen and set:
|
||||
- set_output("worker_summary", "short summary for queen")
|
||||
- set_output("next_action", "done") or set_output("next_action", "revise")
|
||||
- set_output("feedback", "what to revise") only when revising
|
||||
""",
|
||||
tools=[],
|
||||
)
|
||||
|
||||
__all__ = ["process_node", "handoff_node"]
|
||||
```
|
||||
|
||||
## agent.py
|
||||
|
||||
```python
|
||||
"""Agent graph construction for My Agent."""
|
||||
|
||||
from pathlib import Path
|
||||
|
||||
from framework.graph import EdgeSpec, EdgeCondition, Goal, SuccessCriterion, Constraint
|
||||
from framework.graph.edge import GraphSpec
|
||||
from framework.graph.executor import ExecutionResult
|
||||
from framework.graph.checkpoint_config import CheckpointConfig
|
||||
from framework.llm import LiteLLMProvider
|
||||
from framework.runner.tool_registry import ToolRegistry
|
||||
from framework.runtime.agent_runtime import AgentRuntime, create_agent_runtime
|
||||
from framework.runtime.execution_stream import EntryPointSpec
|
||||
|
||||
from .config import default_config, metadata
|
||||
from .nodes import process_node, handoff_node
|
||||
|
||||
# Goal definition
|
||||
goal = Goal(
|
||||
id="my-agent-goal",
|
||||
name="My Agent Goal",
|
||||
description="What this agent achieves.",
|
||||
success_criteria=[
|
||||
SuccessCriterion(id="sc-1", description="...", metric="...", target="...", weight=0.5),
|
||||
SuccessCriterion(id="sc-2", description="...", metric="...", target="...", weight=0.5),
|
||||
],
|
||||
constraints=[
|
||||
Constraint(id="c-1", description="...", constraint_type="hard", category="quality"),
|
||||
],
|
||||
)
|
||||
|
||||
# Node list
|
||||
nodes = [process_node, handoff_node]
|
||||
|
||||
# Edge definitions
|
||||
edges = [
|
||||
EdgeSpec(id="process-to-handoff", source="process", target="handoff",
|
||||
condition=EdgeCondition.ON_SUCCESS, priority=1),
|
||||
# Feedback loop — revise results
|
||||
EdgeSpec(id="handoff-to-process", source="handoff", target="process",
|
||||
condition=EdgeCondition.CONDITIONAL,
|
||||
condition_expr="str(next_action).lower() == 'revise'", priority=2),
|
||||
# Escalation loop — queen injects guidance and worker retries
|
||||
EdgeSpec(id="handoff-escalated", source="handoff", target="process",
|
||||
condition=EdgeCondition.CONDITIONAL,
|
||||
condition_expr="str(next_action).lower() == 'escalated'", priority=3),
|
||||
# Loop back for next task after queen decision
|
||||
EdgeSpec(id="handoff-done", source="handoff", target="process",
|
||||
condition=EdgeCondition.CONDITIONAL,
|
||||
condition_expr="str(next_action).lower() == 'done'", priority=1),
|
||||
]
|
||||
|
||||
# Graph configuration — entry is the autonomous process node
|
||||
# The queen handles intake and passes the task via run_agent_with_input(task)
|
||||
entry_node = "process"
|
||||
entry_points = {"start": "process"}
|
||||
pause_nodes = []
|
||||
terminal_nodes = [] # Forever-alive
|
||||
|
||||
# Module-level vars read by AgentRunner.load()
|
||||
conversation_mode = "continuous"
|
||||
identity_prompt = "You are a helpful agent."
|
||||
loop_config = {"max_iterations": 100, "max_tool_calls_per_turn": 20, "max_context_tokens": 32000}
|
||||
|
||||
|
||||
class MyAgent:
|
||||
def __init__(self, config=None):
|
||||
self.config = config or default_config
|
||||
self.goal = goal
|
||||
self.nodes = nodes
|
||||
self.edges = edges
|
||||
self.entry_node = entry_node # "process" — autonomous entry
|
||||
self.entry_points = entry_points
|
||||
self.pause_nodes = pause_nodes
|
||||
self.terminal_nodes = terminal_nodes
|
||||
self._graph = None
|
||||
self._agent_runtime = None
|
||||
self._tool_registry = None
|
||||
self._storage_path = None
|
||||
|
||||
def _build_graph(self):
|
||||
return GraphSpec(
|
||||
id="my-agent-graph",
|
||||
goal_id=self.goal.id,
|
||||
version="1.0.0",
|
||||
entry_node=self.entry_node,
|
||||
entry_points=self.entry_points,
|
||||
terminal_nodes=self.terminal_nodes,
|
||||
pause_nodes=self.pause_nodes,
|
||||
nodes=self.nodes,
|
||||
edges=self.edges,
|
||||
default_model=self.config.model,
|
||||
max_tokens=self.config.max_tokens,
|
||||
loop_config=loop_config,
|
||||
conversation_mode=conversation_mode,
|
||||
identity_prompt=identity_prompt,
|
||||
)
|
||||
|
||||
def _setup(self):
|
||||
self._storage_path = Path.home() / ".hive" / "agents" / "my_agent"
|
||||
self._storage_path.mkdir(parents=True, exist_ok=True)
|
||||
self._tool_registry = ToolRegistry()
|
||||
mcp_config = Path(__file__).parent / "mcp_servers.json"
|
||||
if mcp_config.exists():
|
||||
self._tool_registry.load_mcp_config(mcp_config)
|
||||
llm = LiteLLMProvider(model=self.config.model, api_key=self.config.api_key, api_base=self.config.api_base)
|
||||
tools = list(self._tool_registry.get_tools().values())
|
||||
tool_executor = self._tool_registry.get_executor()
|
||||
self._graph = self._build_graph()
|
||||
self._agent_runtime = create_agent_runtime(
|
||||
graph=self._graph, goal=self.goal, storage_path=self._storage_path,
|
||||
entry_points=[EntryPointSpec(id="default", name="Default", entry_node=self.entry_node,
|
||||
trigger_type="manual", isolation_level="shared")],
|
||||
llm=llm, tools=tools, tool_executor=tool_executor,
|
||||
checkpoint_config=CheckpointConfig(enabled=True, checkpoint_on_node_complete=True,
|
||||
checkpoint_max_age_days=7, async_checkpoint=True),
|
||||
)
|
||||
|
||||
async def start(self):
|
||||
if self._agent_runtime is None:
|
||||
self._setup()
|
||||
if not self._agent_runtime.is_running:
|
||||
await self._agent_runtime.start()
|
||||
|
||||
async def stop(self):
|
||||
if self._agent_runtime and self._agent_runtime.is_running:
|
||||
await self._agent_runtime.stop()
|
||||
self._agent_runtime = None
|
||||
|
||||
async def trigger_and_wait(self, entry_point="default", input_data=None, timeout=None, session_state=None):
|
||||
if self._agent_runtime is None:
|
||||
raise RuntimeError("Agent not started. Call start() first.")
|
||||
return await self._agent_runtime.trigger_and_wait(
|
||||
entry_point_id=entry_point, input_data=input_data or {}, session_state=session_state)
|
||||
|
||||
async def run(self, context, session_state=None):
|
||||
await self.start()
|
||||
try:
|
||||
result = await self.trigger_and_wait("default", context, session_state=session_state)
|
||||
return result or ExecutionResult(success=False, error="Execution timeout")
|
||||
finally:
|
||||
await self.stop()
|
||||
|
||||
def info(self):
|
||||
return {
|
||||
"name": metadata.name, "version": metadata.version, "description": metadata.description,
|
||||
"goal": {"name": self.goal.name, "description": self.goal.description},
|
||||
"nodes": [n.id for n in self.nodes], "edges": [e.id for e in self.edges],
|
||||
"entry_node": self.entry_node, "entry_points": self.entry_points,
|
||||
"terminal_nodes": self.terminal_nodes,
|
||||
"client_facing_nodes": [n.id for n in self.nodes if n.client_facing],
|
||||
}
|
||||
|
||||
def validate(self):
|
||||
"""Validate graph wiring and entry-point contract."""
|
||||
errors, warnings = [], []
|
||||
node_ids = {n.id for n in self.nodes}
|
||||
for e in self.edges:
|
||||
if e.source not in node_ids:
|
||||
errors.append(f"Edge {e.id}: source '{e.source}' not found")
|
||||
if e.target not in node_ids:
|
||||
errors.append(f"Edge {e.id}: target '{e.target}' not found")
|
||||
if self.entry_node not in node_ids:
|
||||
errors.append(f"Entry node '{self.entry_node}' not found")
|
||||
for t in self.terminal_nodes:
|
||||
if t not in node_ids:
|
||||
errors.append(f"Terminal node '{t}' not found")
|
||||
|
||||
if not isinstance(self.entry_points, dict):
|
||||
errors.append(
|
||||
"Invalid entry_points: expected dict[str, str] like "
|
||||
"{'start': '<entry-node-id>'}. "
|
||||
f"Got {type(self.entry_points).__name__}. "
|
||||
"Fix agent.py: set entry_points = {'start': '<entry-node-id>'}."
|
||||
)
|
||||
else:
|
||||
if "start" not in self.entry_points:
|
||||
errors.append(
|
||||
"entry_points must include 'start' mapped to entry_node. "
|
||||
"Example: {'start': '<entry-node-id>'}."
|
||||
)
|
||||
else:
|
||||
start_node = self.entry_points.get("start")
|
||||
if start_node != self.entry_node:
|
||||
errors.append(
|
||||
f"entry_points['start'] points to '{start_node}' "
|
||||
f"but entry_node is '{self.entry_node}'. Keep these aligned."
|
||||
)
|
||||
|
||||
for ep_id, nid in self.entry_points.items():
|
||||
if not isinstance(ep_id, str):
|
||||
errors.append(
|
||||
f"Invalid entry_points key {ep_id!r} "
|
||||
f"({type(ep_id).__name__}). Entry point names must be strings."
|
||||
)
|
||||
continue
|
||||
if not isinstance(nid, str):
|
||||
errors.append(
|
||||
f"Invalid entry_points['{ep_id}']={nid!r} "
|
||||
f"({type(nid).__name__}). Node ids must be strings."
|
||||
)
|
||||
continue
|
||||
if nid not in node_ids:
|
||||
errors.append(
|
||||
f"Entry point '{ep_id}' references unknown node '{nid}'. "
|
||||
f"Known nodes: {sorted(node_ids)}"
|
||||
)
|
||||
|
||||
return {"valid": len(errors) == 0, "errors": errors, "warnings": warnings}
|
||||
|
||||
|
||||
default_agent = MyAgent()
|
||||
```
|
||||
|
||||
## triggers.json — Timer and Webhook Triggers
|
||||
|
||||
When an agent needs timers, webhooks, or event-driven triggers, create a
|
||||
`triggers.json` file in the agent's directory (alongside `agent.py`).
|
||||
The queen loads these at session start and the user can manage them via
|
||||
the `set_trigger` / `remove_trigger` tools at runtime.
|
||||
|
||||
```json
|
||||
[
|
||||
{
|
||||
"id": "daily-check",
|
||||
"name": "Daily Check",
|
||||
"trigger_type": "timer",
|
||||
"trigger_config": {"cron": "0 9 * * *"},
|
||||
"task": "Run the daily check process"
|
||||
},
|
||||
{
|
||||
"id": "scheduled-check",
|
||||
"name": "Scheduled Check",
|
||||
"trigger_type": "timer",
|
||||
"trigger_config": {"interval_minutes": 20},
|
||||
"task": "Run the scheduled check"
|
||||
},
|
||||
{
|
||||
"id": "webhook-event",
|
||||
"name": "Webhook Event Handler",
|
||||
"trigger_type": "webhook",
|
||||
"trigger_config": {"event_types": ["webhook_received"]},
|
||||
"task": "Process incoming webhook event"
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
**Key rules for triggers.json:**
|
||||
- Valid trigger_types: `timer`, `webhook`
|
||||
- Timer trigger_config (cron): `{"cron": "0 9 * * *"}` — standard 5-field cron expression
|
||||
- Timer trigger_config (interval): `{"interval_minutes": float}`
|
||||
- Each trigger must have a unique `id`
|
||||
- The `task` field describes what the worker should do when the trigger fires
|
||||
- Triggers are persisted back to `triggers.json` when modified via queen tools
|
||||
|
||||
## __init__.py
|
||||
|
||||
**CRITICAL:** The runner imports the package (`__init__.py`) and reads ALL module-level
|
||||
variables via `getattr()`. Every variable defined in `agent.py` that the runner needs
|
||||
MUST be re-exported here. Missing exports cause silent failures (variables default to
|
||||
`None` or `{}`), leading to "must define goal, nodes, edges" errors or graph validation
|
||||
failures like "node X is unreachable".
|
||||
|
||||
```python
|
||||
"""My Agent — description."""
|
||||
|
||||
from .agent import (
|
||||
MyAgent,
|
||||
default_agent,
|
||||
goal,
|
||||
nodes,
|
||||
edges,
|
||||
entry_node,
|
||||
entry_points,
|
||||
pause_nodes,
|
||||
terminal_nodes,
|
||||
conversation_mode,
|
||||
identity_prompt,
|
||||
loop_config,
|
||||
)
|
||||
from .config import default_config, metadata
|
||||
|
||||
__all__ = [
|
||||
"MyAgent",
|
||||
"default_agent",
|
||||
"goal",
|
||||
"nodes",
|
||||
"edges",
|
||||
"entry_node",
|
||||
"entry_points",
|
||||
"pause_nodes",
|
||||
"terminal_nodes",
|
||||
"conversation_mode",
|
||||
"identity_prompt",
|
||||
"loop_config",
|
||||
"default_config",
|
||||
"metadata",
|
||||
]
|
||||
```
|
||||
|
||||
## __main__.py
|
||||
|
||||
```python
|
||||
"""CLI entry point for My Agent."""
|
||||
|
||||
import asyncio, json, logging, sys
|
||||
import click
|
||||
from .agent import default_agent, MyAgent
|
||||
|
||||
|
||||
def setup_logging(verbose=False, debug=False):
|
||||
if debug: level, fmt = logging.DEBUG, "%(asctime)s %(name)s: %(message)s"
|
||||
elif verbose: level, fmt = logging.INFO, "%(message)s"
|
||||
else: level, fmt = logging.WARNING, "%(levelname)s: %(message)s"
|
||||
logging.basicConfig(level=level, format=fmt, stream=sys.stderr)
|
||||
|
||||
|
||||
@click.group()
|
||||
@click.version_option(version="1.0.0")
|
||||
def cli():
|
||||
"""My Agent — description."""
|
||||
pass
|
||||
|
||||
|
||||
@cli.command()
|
||||
@click.option("--topic", "-t", required=True)
|
||||
@click.option("--verbose", "-v", is_flag=True)
|
||||
def run(topic, verbose):
|
||||
"""Execute the agent."""
|
||||
setup_logging(verbose=verbose)
|
||||
result = asyncio.run(default_agent.run({"topic": topic}))
|
||||
click.echo(json.dumps({"success": result.success, "output": result.output}, indent=2, default=str))
|
||||
sys.exit(0 if result.success else 1)
|
||||
|
||||
|
||||
@cli.command()
|
||||
def tui():
|
||||
"""Launch TUI dashboard."""
|
||||
from pathlib import Path
|
||||
from framework.tui.app import AdenTUI
|
||||
from framework.llm import LiteLLMProvider
|
||||
from framework.runner.tool_registry import ToolRegistry
|
||||
from framework.runtime.agent_runtime import create_agent_runtime
|
||||
from framework.runtime.execution_stream import EntryPointSpec
|
||||
|
||||
async def run_tui():
|
||||
agent = MyAgent()
|
||||
agent._tool_registry = ToolRegistry()
|
||||
storage = Path.home() / ".hive" / "agents" / "my_agent"
|
||||
storage.mkdir(parents=True, exist_ok=True)
|
||||
mcp_cfg = Path(__file__).parent / "mcp_servers.json"
|
||||
if mcp_cfg.exists(): agent._tool_registry.load_mcp_config(mcp_cfg)
|
||||
llm = LiteLLMProvider(model=agent.config.model, api_key=agent.config.api_key, api_base=agent.config.api_base)
|
||||
runtime = create_agent_runtime(
|
||||
graph=agent._build_graph(), goal=agent.goal, storage_path=storage,
|
||||
entry_points=[EntryPointSpec(id="start", name="Start", entry_node="process", trigger_type="manual", isolation_level="isolated")],
|
||||
llm=llm, tools=list(agent._tool_registry.get_tools().values()), tool_executor=agent._tool_registry.get_executor())
|
||||
await runtime.start()
|
||||
try:
|
||||
app = AdenTUI(runtime)
|
||||
await app.run_async()
|
||||
finally:
|
||||
await runtime.stop()
|
||||
asyncio.run(run_tui())
|
||||
|
||||
|
||||
@cli.command()
|
||||
def info():
|
||||
"""Show agent info."""
|
||||
data = default_agent.info()
|
||||
click.echo(f"Agent: {data['name']}\nVersion: {data['version']}\nDescription: {data['description']}")
|
||||
click.echo(f"Nodes: {', '.join(data['nodes'])}\nClient-facing: {', '.join(data['client_facing_nodes'])}")
|
||||
|
||||
|
||||
@cli.command()
|
||||
def validate():
|
||||
"""Validate agent structure."""
|
||||
v = default_agent.validate()
|
||||
if v["valid"]: click.echo("Agent is valid")
|
||||
else:
|
||||
click.echo("Errors:")
|
||||
for e in v["errors"]: click.echo(f" {e}")
|
||||
sys.exit(0 if v["valid"] else 1)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
cli()
|
||||
```
|
||||
|
||||
## mcp_servers.json
|
||||
|
||||
> **Auto-generated.** `initialize_and_build_agent` creates this file with hive-tools
|
||||
> as the default. Only edit manually to add additional MCP servers.
|
||||
|
||||
```json
|
||||
{
|
||||
"hive-tools": {
|
||||
"transport": "stdio",
|
||||
"command": "uv",
|
||||
"args": ["run", "python", "mcp_server.py", "--stdio"],
|
||||
"cwd": "../../tools",
|
||||
"description": "Hive tools MCP server"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**CRITICAL FORMAT RULES:**
|
||||
- NO `"mcpServers"` wrapper (flat dict, not nested)
|
||||
- `cwd` MUST be `"../../tools"` (relative from `exports/AGENT_NAME/` to `tools/`)
|
||||
- `command` MUST be `"uv"` with `"args": ["run", "python", ...]` (NOT bare `"python"`)
|
||||
|
||||
## tests/conftest.py
|
||||
|
||||
```python
|
||||
"""Test fixtures."""
|
||||
|
||||
import sys
|
||||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
|
||||
_repo_root = Path(__file__).resolve().parents[3]
|
||||
for _p in ["exports", "core"]:
|
||||
_path = str(_repo_root / _p)
|
||||
if _path not in sys.path:
|
||||
sys.path.insert(0, _path)
|
||||
|
||||
AGENT_PATH = str(Path(__file__).resolve().parents[1])
|
||||
|
||||
|
||||
@pytest.fixture(scope="session")
|
||||
def agent_module():
|
||||
"""Import the agent package for structural validation."""
|
||||
import importlib
|
||||
return importlib.import_module(Path(AGENT_PATH).name)
|
||||
|
||||
|
||||
@pytest.fixture(scope="session")
|
||||
def runner_loaded():
|
||||
"""Load the agent through AgentRunner (structural only, no LLM needed)."""
|
||||
from framework.runner.runner import AgentRunner
|
||||
return AgentRunner.load(AGENT_PATH)
|
||||
```
|
||||
|
||||
## entry_points Format
|
||||
|
||||
MUST be: `{"start": "first-node-id"}`
|
||||
NOT: `{"first-node-id": ["input_keys"]}` (WRONG)
|
||||
NOT: `{"first-node-id"}` (WRONG — this is a set)
|
||||
@@ -0,0 +1,305 @@
|
||||
# Hive Agent Framework — Condensed Reference
|
||||
|
||||
## Architecture
|
||||
|
||||
Agents are Python packages in `exports/`:
|
||||
```
|
||||
exports/my_agent/
|
||||
├── __init__.py # MUST re-export ALL module-level vars from agent.py
|
||||
├── __main__.py # CLI (run, tui, info, validate, shell)
|
||||
├── agent.py # Graph construction (goal, edges, agent class)
|
||||
├── config.py # Runtime config
|
||||
├── nodes/__init__.py # Node definitions (NodeSpec)
|
||||
├── mcp_servers.json # MCP tool server config
|
||||
└── tests/ # pytest tests
|
||||
```
|
||||
|
||||
## Agent Loading Contract
|
||||
|
||||
`AgentRunner.load()` imports the package (`__init__.py`) and reads these
|
||||
module-level variables via `getattr()`:
|
||||
|
||||
| Variable | Required | Default if missing | Consequence |
|
||||
|----------|----------|--------------------|-------------|
|
||||
| `goal` | YES | `None` | **FATAL** — "must define goal, nodes, edges" |
|
||||
| `nodes` | YES | `None` | **FATAL** — same error |
|
||||
| `edges` | YES | `None` | **FATAL** — same error |
|
||||
| `entry_node` | no | `nodes[0].id` | Probably wrong node |
|
||||
| `entry_points` | no | `{}` | **Nodes unreachable** — validation fails |
|
||||
| `terminal_nodes` | **YES** | `[]` | **FATAL** — graph must have at least one terminal node |
|
||||
| `pause_nodes` | no | `[]` | OK |
|
||||
| `conversation_mode` | no | not passed | Isolated mode (no context carryover) |
|
||||
| `identity_prompt` | no | not passed | No agent-level identity |
|
||||
| `loop_config` | no | `{}` | No iteration limits |
|
||||
| `triggers.json` (file) | no | not present | No triggers (timers, webhooks) |
|
||||
|
||||
**CRITICAL:** `__init__.py` MUST import and re-export ALL of these from
|
||||
`agent.py`. Missing exports silently fall back to defaults, causing
|
||||
hard-to-debug failures.
|
||||
|
||||
**Why `default_agent.validate()` is NOT sufficient:**
|
||||
`validate()` checks the agent CLASS's internal graph (self.nodes, self.edges).
|
||||
These are always correct because the constructor references agent.py's module
|
||||
vars directly. But `AgentRunner.load()` reads from the PACKAGE (`__init__.py`),
|
||||
not the class. So `validate()` passes while `AgentRunner.load()` fails.
|
||||
Always test with `AgentRunner.load("exports/{name}")` — this is the same
|
||||
code path the TUI and `hive run` use.
|
||||
|
||||
## Goal
|
||||
|
||||
Defines success criteria and constraints:
|
||||
```python
|
||||
goal = Goal(
|
||||
id="kebab-case-id",
|
||||
name="Display Name",
|
||||
description="What the agent does",
|
||||
success_criteria=[
|
||||
SuccessCriterion(id="sc-id", description="...", metric="...", target="...", weight=0.25),
|
||||
],
|
||||
constraints=[
|
||||
Constraint(id="c-id", description="...", constraint_type="hard", category="quality"),
|
||||
],
|
||||
)
|
||||
```
|
||||
- 3-5 success criteria, weights sum to 1.0
|
||||
- 1-5 constraints (hard/soft, categories: quality, accuracy, interaction, functional)
|
||||
|
||||
## NodeSpec Fields
|
||||
|
||||
| Field | Type | Default | Description |
|
||||
|-------|------|---------|-------------|
|
||||
| id | str | required | kebab-case identifier |
|
||||
| name | str | required | Display name |
|
||||
| description | str | required | What the node does |
|
||||
| node_type | str | required | `"event_loop"` or `"gcu"` (browser automation — see GCU Guide appendix) |
|
||||
| input_keys | list[str] | required | Memory keys this node reads |
|
||||
| output_keys | list[str] | required | Memory keys this node writes via set_output |
|
||||
| system_prompt | str | "" | LLM instructions |
|
||||
| tools | list[str] | [] | Tool names from MCP servers |
|
||||
| client_facing | bool | False | If True, streams to user and blocks for input |
|
||||
| nullable_output_keys | list[str] | [] | Keys that may remain unset |
|
||||
| max_node_visits | int | 0 | 0=unlimited (default); >1 for one-shot feedback loops |
|
||||
| max_retries | int | 3 | Retries on failure |
|
||||
| success_criteria | str | "" | Natural language for judge evaluation |
|
||||
|
||||
## EdgeSpec Fields
|
||||
|
||||
| Field | Type | Description |
|
||||
|-------|------|-------------|
|
||||
| id | str | kebab-case identifier |
|
||||
| source | str | Source node ID |
|
||||
| target | str | Target node ID |
|
||||
| condition | EdgeCondition | ON_SUCCESS, ON_FAILURE, ALWAYS, CONDITIONAL |
|
||||
| condition_expr | str | Python expression evaluated against memory (for CONDITIONAL) |
|
||||
| priority | int | Positive=forward (evaluated first), negative=feedback (loop-back) |
|
||||
|
||||
## Key Patterns
|
||||
|
||||
### STEP 1/STEP 2 (Client-Facing Nodes)
|
||||
```
|
||||
**STEP 1 — Respond to the user (text only, NO tool calls):**
|
||||
[Present information, ask questions]
|
||||
|
||||
**STEP 2 — After the user responds, call set_output:**
|
||||
- set_output("key", "value based on user response")
|
||||
```
|
||||
This prevents premature set_output before user interaction.
|
||||
|
||||
### Fewer, Richer Nodes (CRITICAL)
|
||||
|
||||
**Hard limit: 3-6 nodes for most agents.** Never exceed 6 unless the user
|
||||
explicitly requests a complex multi-phase pipeline.
|
||||
|
||||
Each node boundary serializes outputs to shared memory and **destroys** all
|
||||
in-context information: tool call results, intermediate reasoning, conversation
|
||||
history. A research node that searches, fetches, and analyzes in ONE node keeps
|
||||
all source material in its conversation context. Split across 3 nodes, each
|
||||
downstream node only sees the serialized summary string.
|
||||
|
||||
**Decision framework — merge unless ANY of these apply:**
|
||||
1. **Client-facing boundary** — Autonomous and client-facing work MUST be
|
||||
separate nodes (different interaction models)
|
||||
2. **Disjoint tool sets** — If tools are fundamentally different (e.g., web
|
||||
search vs database), separate nodes make sense
|
||||
3. **Parallel execution** — Fan-out branches must be separate nodes
|
||||
|
||||
**Red flags that you have too many nodes:**
|
||||
- A node with 0 tools (pure LLM reasoning) → merge into predecessor/successor
|
||||
- A node that sets only 1 trivial output → collapse into predecessor
|
||||
- Multiple consecutive autonomous nodes → combine into one rich node
|
||||
- A "report" node that presents analysis → merge into the client-facing node
|
||||
- A "confirm" or "schedule" node that doesn't call any external service → remove
|
||||
|
||||
**Typical agent structure (2 nodes):**
|
||||
```
|
||||
process (autonomous) ←→ review (client-facing)
|
||||
```
|
||||
The queen owns intake — she gathers requirements from the user, then
|
||||
passes structured input via `run_agent_with_input(task)`. When building
|
||||
the agent, design the entry node's `input_keys` to match what the queen
|
||||
will provide at run time. Worker agents should NOT have a client-facing
|
||||
intake node. Client-facing nodes are for mid-execution review/approval only.
|
||||
|
||||
For simpler agents, just 1 autonomous node:
|
||||
```
|
||||
process (autonomous) — loops back to itself
|
||||
```
|
||||
|
||||
### nullable_output_keys
|
||||
For inputs that only arrive on certain edges:
|
||||
```python
|
||||
research_node = NodeSpec(
|
||||
input_keys=["brief", "feedback"],
|
||||
nullable_output_keys=["feedback"], # Only present on feedback edge
|
||||
max_node_visits=3,
|
||||
)
|
||||
```
|
||||
|
||||
### Mutually Exclusive Outputs
|
||||
For routing decisions:
|
||||
```python
|
||||
review_node = NodeSpec(
|
||||
output_keys=["approved", "feedback"],
|
||||
nullable_output_keys=["approved", "feedback"], # Node sets one or the other
|
||||
)
|
||||
```
|
||||
|
||||
### Continuous Loop Pattern
|
||||
Mark the primary event_loop node as terminal: `terminal_nodes=["process"]`.
|
||||
The node has `output_keys` and can complete when the agent finishes its work.
|
||||
Use `conversation_mode="continuous"` to preserve context across transitions.
|
||||
|
||||
### set_output
|
||||
- Synthetic tool injected by framework
|
||||
- Call separately from real tool calls (separate turn)
|
||||
- `set_output("key", "value")` stores to shared memory
|
||||
|
||||
## Edge Conditions
|
||||
|
||||
| Condition | When |
|
||||
|-----------|------|
|
||||
| ON_SUCCESS | Node completed successfully |
|
||||
| ON_FAILURE | Node failed |
|
||||
| ALWAYS | Unconditional |
|
||||
| CONDITIONAL | condition_expr evaluates to True against memory |
|
||||
|
||||
condition_expr examples:
|
||||
- `"needs_more_research == True"`
|
||||
- `"str(next_action).lower() == 'new_agent'"`
|
||||
- `"feedback is not None"`
|
||||
|
||||
## Graph Lifecycle
|
||||
|
||||
| Pattern | terminal_nodes | When |
|
||||
|---------|---------------|------|
|
||||
| **Continuous loop** | `["node-with-output-keys"]` | **DEFAULT for all agents** |
|
||||
| Linear | `["last-node"]` | One-shot/batch agents |
|
||||
|
||||
**Every graph must have at least one terminal node.** Terminal nodes
|
||||
define where execution ends. For interactive agents that loop continuously,
|
||||
mark the primary event_loop node as terminal (it has `output_keys` and can
|
||||
complete at any point). The framework default for `max_node_visits` is 0
|
||||
(unbounded), so nodes work correctly in continuous loops without explicit
|
||||
override. Only set `max_node_visits > 0` in one-shot agents with feedback loops.
|
||||
Every node must have at least one outgoing edge — no dead ends.
|
||||
|
||||
## Continuous Conversation Mode
|
||||
|
||||
`conversation_mode` has ONLY two valid states:
|
||||
- `"continuous"` — recommended for interactive agents
|
||||
- Omit entirely — isolated per-node conversations (each node starts fresh)
|
||||
|
||||
**INVALID values** (do NOT use): `"client_facing"`, `"interactive"`,
|
||||
`"adaptive"`, `"shared"`. These do not exist in the framework.
|
||||
|
||||
When `conversation_mode="continuous"`:
|
||||
- Same conversation thread carries across node transitions
|
||||
- Layered system prompts: identity (agent-level) + narrative + focus (per-node)
|
||||
- Transition markers inserted at boundaries
|
||||
- Compaction happens opportunistically at phase transitions
|
||||
|
||||
## loop_config
|
||||
|
||||
Only three valid keys:
|
||||
```python
|
||||
loop_config = {
|
||||
"max_iterations": 100, # Max LLM turns per node visit
|
||||
"max_tool_calls_per_turn": 20, # Max tool calls per LLM response
|
||||
"max_context_tokens": 32000, # Triggers conversation compaction
|
||||
}
|
||||
```
|
||||
**INVALID keys** (do NOT use): `"strategy"`, `"mode"`, `"timeout"`,
|
||||
`"temperature"`. These are silently ignored or cause errors.
|
||||
|
||||
## Data Tools (Spillover)
|
||||
|
||||
For large data that exceeds context:
|
||||
- `save_data(filename, data)` — Write to session data dir
|
||||
- `load_data(filename, offset, limit)` — Read with pagination
|
||||
- `list_data_files()` — List files
|
||||
- `serve_file_to_user(filename, label)` — Clickable file:// URI
|
||||
|
||||
`data_dir` is auto-injected by framework — LLM never sees it.
|
||||
|
||||
## Fan-Out / Fan-In
|
||||
|
||||
Multiple ON_SUCCESS edges from same source → parallel execution via asyncio.gather().
|
||||
- Parallel nodes must have disjoint output_keys
|
||||
- Only one branch may have client_facing nodes
|
||||
- Fan-in node gets all outputs in shared memory
|
||||
|
||||
## Judge System
|
||||
|
||||
- **Implicit** (default): ACCEPTs when LLM finishes with no tool calls and all required outputs set
|
||||
- **SchemaJudge**: Validates against Pydantic model
|
||||
- **Custom**: Implement `evaluate(context) -> JudgeVerdict`
|
||||
|
||||
Judge is the SOLE acceptance mechanism — no ad-hoc framework gating.
|
||||
|
||||
## Triggers (Timers, Webhooks)
|
||||
|
||||
For agents that react to external events, create a `triggers.json` file
|
||||
in the agent's export directory:
|
||||
|
||||
```json
|
||||
[
|
||||
{
|
||||
"id": "daily-check",
|
||||
"name": "Daily Check",
|
||||
"trigger_type": "timer",
|
||||
"trigger_config": {"cron": "0 9 * * *"},
|
||||
"task": "Run the daily check process"
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
### Key Fields
|
||||
- `trigger_type`: `"timer"` or `"webhook"`
|
||||
- `trigger_config`: `{"cron": "0 9 * * *"}` or `{"interval_minutes": 20}`
|
||||
- `task`: describes what the worker should do when the trigger fires
|
||||
- Triggers can also be created/removed at runtime via `set_trigger` / `remove_trigger` queen tools
|
||||
|
||||
## Tool Discovery
|
||||
|
||||
Do NOT rely on a static tool list — it will be outdated. Always call
|
||||
`list_agent_tools()` with NO arguments first to see ALL available tools.
|
||||
Only use `group=` or `output_schema=` as follow-up calls after seeing the
|
||||
full list.
|
||||
|
||||
```
|
||||
list_agent_tools() # ALWAYS call this first
|
||||
list_agent_tools(group="gmail", output_schema="full") # then drill into a category
|
||||
list_agent_tools("exports/my_agent/mcp_servers.json") # specific agent's tools
|
||||
```
|
||||
|
||||
After building, run `validate_agent_package("{name}")` to check everything at once.
|
||||
|
||||
Common tool categories (verify via list_agent_tools):
|
||||
- **Web**: search, scrape, PDF
|
||||
- **Data**: save/load/append/list data files, serve to user
|
||||
- **File**: view, write, replace, diff, list, grep
|
||||
- **Communication**: email, gmail, slack, telegram
|
||||
- **CRM**: hubspot, apollo, calcom
|
||||
- **GitHub**: stargazers, user profiles, repos
|
||||
- **Vision**: image analysis
|
||||
- **Time**: current time
|
||||
@@ -0,0 +1,158 @@
|
||||
# GCU Browser Automation Guide
|
||||
|
||||
## When to Use GCU Nodes
|
||||
|
||||
Use `node_type="gcu"` when:
|
||||
- The user's workflow requires **navigating real websites** (scraping, form-filling, social media interaction, testing web UIs)
|
||||
- The task involves **dynamic/JS-rendered pages** that `web_scrape` cannot handle (SPAs, infinite scroll, login-gated content)
|
||||
- The agent needs to **interact with a website** — clicking, typing, scrolling, selecting, uploading files
|
||||
|
||||
Do NOT use GCU for:
|
||||
- Static content that `web_scrape` handles fine
|
||||
- API-accessible data (use the API directly)
|
||||
- PDF/file processing
|
||||
- Anything that doesn't require a browser UI
|
||||
|
||||
## What GCU Nodes Are
|
||||
|
||||
- `node_type="gcu"` — a declarative enhancement over `event_loop`
|
||||
- Framework auto-prepends browser best-practices system prompt
|
||||
- Framework auto-includes all 31 browser tools from `gcu-tools` MCP server
|
||||
- Same underlying `EventLoopNode` class — no new imports needed
|
||||
- `tools=[]` is correct — tools are auto-populated at runtime
|
||||
|
||||
## GCU Architecture Pattern
|
||||
|
||||
GCU nodes are **subagents** — invoked via `delegate_to_sub_agent()`, not connected via edges.
|
||||
|
||||
- Primary nodes (`event_loop`, client-facing) orchestrate; GCU nodes do browser work
|
||||
- Parent node declares `sub_agents=["gcu-node-id"]` and calls `delegate_to_sub_agent(agent_id="gcu-node-id", task="...")`
|
||||
- GCU nodes set `max_node_visits=1` (single execution per delegation), `client_facing=False`
|
||||
- GCU nodes use `output_keys=["result"]` and return structured JSON via `set_output("result", ...)`
|
||||
|
||||
## GCU Node Definition Template
|
||||
|
||||
```python
|
||||
gcu_browser_node = NodeSpec(
|
||||
id="gcu-browser-worker",
|
||||
name="Browser Worker",
|
||||
description="Browser subagent that does X.",
|
||||
node_type="gcu",
|
||||
client_facing=False,
|
||||
max_node_visits=1,
|
||||
input_keys=[],
|
||||
output_keys=["result"],
|
||||
tools=[], # Auto-populated with all browser tools
|
||||
system_prompt="""\
|
||||
You are a browser agent. Your job: [specific task].
|
||||
|
||||
## Workflow
|
||||
1. browser_start (only if no browser is running yet)
|
||||
2. browser_open(url=TARGET_URL) — note the returned targetId
|
||||
3. browser_snapshot to read the page
|
||||
4. [task-specific steps]
|
||||
5. set_output("result", JSON)
|
||||
|
||||
## Output format
|
||||
set_output("result", JSON) with:
|
||||
- [field]: [type and description]
|
||||
""",
|
||||
)
|
||||
```
|
||||
|
||||
## Parent Node Template (orchestrating GCU subagents)
|
||||
|
||||
```python
|
||||
orchestrator_node = NodeSpec(
|
||||
id="orchestrator",
|
||||
...
|
||||
node_type="event_loop",
|
||||
sub_agents=["gcu-browser-worker"],
|
||||
system_prompt="""\
|
||||
...
|
||||
delegate_to_sub_agent(
|
||||
agent_id="gcu-browser-worker",
|
||||
task="Navigate to [URL]. Do [specific task]. Return JSON with [fields]."
|
||||
)
|
||||
...
|
||||
""",
|
||||
tools=[], # Orchestrator doesn't need browser tools
|
||||
)
|
||||
```
|
||||
|
||||
## mcp_servers.json with GCU
|
||||
|
||||
```json
|
||||
{
|
||||
"hive-tools": { ... },
|
||||
"gcu-tools": {
|
||||
"transport": "stdio",
|
||||
"command": "uv",
|
||||
"args": ["run", "python", "-m", "gcu.server", "--stdio"],
|
||||
"cwd": "../../tools",
|
||||
"description": "GCU tools for browser automation"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Note: `gcu-tools` is auto-added if any node uses `node_type="gcu"`, but including it explicitly is fine.
|
||||
|
||||
## GCU System Prompt Best Practices
|
||||
|
||||
Key rules to bake into GCU node prompts:
|
||||
|
||||
- Prefer `browser_snapshot` over `browser_get_text("body")` — compact accessibility tree vs 100KB+ raw HTML
|
||||
- Always `browser_wait` after navigation
|
||||
- Use large scroll amounts (~2000-5000) for lazy-loaded content
|
||||
- For spillover files, use `run_command` with grep, not `read_file`
|
||||
- If auth wall detected, report immediately — don't attempt login
|
||||
- Keep tool calls per turn ≤10
|
||||
- Tab isolation: when browser is already running, use `browser_open(background=true)` and pass `target_id` to every call
|
||||
|
||||
## Multiple Concurrent GCU Subagents
|
||||
|
||||
When a task can be parallelized across multiple sites or profiles, declare a distinct GCU
|
||||
node for each and invoke them all in the same LLM turn. The framework batches all
|
||||
`delegate_to_sub_agent` calls made in one turn and runs them with `asyncio.gather`, so
|
||||
they execute concurrently — not sequentially.
|
||||
|
||||
**Each GCU subagent automatically gets its own isolated browser context** — no `profile=`
|
||||
argument is needed in tool calls. The framework derives a unique profile from the subagent's
|
||||
node ID and instance counter and injects it via an asyncio `ContextVar` before the subagent
|
||||
runs.
|
||||
|
||||
### Example: three sites in parallel
|
||||
|
||||
```python
|
||||
# Three distinct GCU nodes
|
||||
gcu_site_a = NodeSpec(id="gcu-site-a", node_type="gcu", ...)
|
||||
gcu_site_b = NodeSpec(id="gcu-site-b", node_type="gcu", ...)
|
||||
gcu_site_c = NodeSpec(id="gcu-site-c", node_type="gcu", ...)
|
||||
|
||||
orchestrator = NodeSpec(
|
||||
id="orchestrator",
|
||||
node_type="event_loop",
|
||||
sub_agents=["gcu-site-a", "gcu-site-b", "gcu-site-c"],
|
||||
system_prompt="""\
|
||||
Call all three subagents in a single response to run them in parallel:
|
||||
delegate_to_sub_agent(agent_id="gcu-site-a", task="Scrape prices from site A")
|
||||
delegate_to_sub_agent(agent_id="gcu-site-b", task="Scrape prices from site B")
|
||||
delegate_to_sub_agent(agent_id="gcu-site-c", task="Scrape prices from site C")
|
||||
""",
|
||||
)
|
||||
```
|
||||
|
||||
**Rules:**
|
||||
- Use distinct node IDs for each concurrent task — sharing an ID shares the browser context.
|
||||
- The GCU node prompts do not need to mention `profile=`; isolation is automatic.
|
||||
- Cleanup is automatic at session end, but GCU nodes can call `browser_stop()` explicitly
|
||||
if they want to release resources mid-run.
|
||||
|
||||
## GCU Anti-Patterns
|
||||
|
||||
- Using `browser_screenshot` to read text (use `browser_snapshot`)
|
||||
- Re-navigating after scrolling (resets scroll position)
|
||||
- Attempting login on auth walls
|
||||
- Forgetting `target_id` in multi-tab scenarios
|
||||
- Putting browser tools directly on `event_loop` nodes instead of using GCU subagent pattern
|
||||
- Making GCU nodes `client_facing=True` (they should be autonomous subagents)
|
||||
@@ -0,0 +1,63 @@
|
||||
# Queen Memory — File System Structure
|
||||
|
||||
```
|
||||
~/.hive/
|
||||
├── queen/
|
||||
│ ├── MEMORY.md ← Semantic memory
|
||||
│ ├── memories/
|
||||
│ │ ├── MEMORY-2026-03-09.md ← Episodic memory (today)
|
||||
│ │ ├── MEMORY-2026-03-08.md
|
||||
│ │ └── ...
|
||||
│ └── session/
|
||||
│ └── {session_id}/ ← One dir per session (or resumed-from session)
|
||||
│ ├── conversations/
|
||||
│ │ ├── parts/
|
||||
│ │ │ ├── 00001.json ← One file per message (role, content, tool_calls)
|
||||
│ │ │ ├── 00002.json
|
||||
│ │ │ └── ...
|
||||
│ │ └── spillover/
|
||||
│ │ ├── conversation_1.md ← Compacted old conversation segments
|
||||
│ │ ├── conversation_2.md
|
||||
│ │ └── ...
|
||||
│ └── data/
|
||||
│ ├── adapt.md ← Working memory (session-scoped)
|
||||
│ ├── web_search_1.txt ← Spillover: large tool results
|
||||
│ ├── web_search_2.txt
|
||||
│ └── ...
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## The three memory tiers
|
||||
|
||||
| File | Tier | Written by | Read at |
|
||||
|---|---|---|---|
|
||||
| `MEMORY.md` | Semantic | Consolidation LLM (auto, post-session) | Session start (injected into system prompt) |
|
||||
| `memories/MEMORY-YYYY-MM-DD.md` | Episodic | Queen via `write_to_diary` tool + consolidation LLM | Session start (today's file injected) |
|
||||
| `data/adapt.md` | Working | Queen via `update_session_notes` tool | Every turn (inlined in system prompt) |
|
||||
|
||||
---
|
||||
|
||||
## Session directory naming
|
||||
|
||||
The session directory name is **`queen_resume_from`** when a cold-restore resumes an existing
|
||||
session, otherwise the new **`session_id`**. This means resumed sessions accumulate all messages
|
||||
in the original directory rather than fragmenting across multiple folders.
|
||||
|
||||
---
|
||||
|
||||
## Consolidation
|
||||
|
||||
`consolidate_queen_memory()` runs every **5 minutes** in the background and once more at session
|
||||
end. It reads:
|
||||
|
||||
1. `conversations/parts/*.json` — full message history (user + assistant turns; tool results skipped)
|
||||
2. `data/adapt.md` — current working notes
|
||||
|
||||
It then makes two LLM writes:
|
||||
|
||||
- Rewrites `MEMORY.md` in place (semantic memory — queen never touches this herself)
|
||||
- Appends a timestamped prose entry to today's `memories/MEMORY-YYYY-MM-DD.md`
|
||||
|
||||
If the combined transcript exceeds ~200 K characters it is recursively binary-compacted via the
|
||||
LLM before being sent to the consolidation model (mirrors `EventLoopNode._llm_compact`).
|
||||
@@ -0,0 +1,31 @@
|
||||
"""Test fixtures for Queen agent."""
|
||||
|
||||
import sys
|
||||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
import pytest_asyncio
|
||||
|
||||
_repo_root = Path(__file__).resolve().parents[3]
|
||||
for _p in ["exports", "core"]:
|
||||
_path = str(_repo_root / _p)
|
||||
if _path not in sys.path:
|
||||
sys.path.insert(0, _path)
|
||||
|
||||
AGENT_PATH = str(Path(__file__).resolve().parents[1])
|
||||
|
||||
|
||||
@pytest.fixture(scope="session")
|
||||
def mock_mode():
|
||||
return True
|
||||
|
||||
|
||||
@pytest_asyncio.fixture(scope="session")
|
||||
async def runner(tmp_path_factory, mock_mode):
|
||||
from framework.runner.runner import AgentRunner
|
||||
|
||||
storage = tmp_path_factory.mktemp("agent_storage")
|
||||
r = AgentRunner.load(AGENT_PATH, mock_mode=mock_mode, storage_path=storage)
|
||||
r._setup()
|
||||
yield r
|
||||
await r.cleanup_async()
|
||||
@@ -0,0 +1,27 @@
|
||||
"""Queen's ticket receiver entry point.
|
||||
|
||||
When a WORKER_ESCALATION_TICKET event is emitted on the shared EventBus,
|
||||
this entry point fires and routes to the ``ticket_triage`` node, where the
|
||||
Queen deliberates and decides whether to notify the operator.
|
||||
|
||||
Isolation level is ``isolated`` — the queen's triage memory is kept separate
|
||||
from the worker's shared memory. Each ticket triage runs in its own context.
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from framework.graph.edge import AsyncEntryPointSpec
|
||||
|
||||
TICKET_RECEIVER_ENTRY_POINT = AsyncEntryPointSpec(
|
||||
id="ticket_receiver",
|
||||
name="Worker Escalation Ticket Receiver",
|
||||
entry_node="ticket_triage",
|
||||
trigger_type="event",
|
||||
trigger_config={
|
||||
"event_types": ["worker_escalation_ticket"],
|
||||
# Do not fire on our own graph's events (prevents loops if queen
|
||||
# somehow emits a worker_escalation_ticket for herself)
|
||||
"exclude_own_graph": True,
|
||||
},
|
||||
isolation_level="isolated",
|
||||
)
|
||||
@@ -0,0 +1,286 @@
|
||||
"""Worker per-run digest (run diary).
|
||||
|
||||
Storage layout:
|
||||
~/.hive/agents/{agent_name}/runs/{run_id}/digest.md
|
||||
|
||||
Each completed or failed worker run gets one digest file. The queen reads
|
||||
these via get_worker_status(focus='diary') before digging into live runtime
|
||||
logs — the diary is a cheap, persistent record that survives across sessions.
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import logging
|
||||
import traceback
|
||||
from collections import Counter
|
||||
from datetime import datetime
|
||||
from pathlib import Path
|
||||
from typing import TYPE_CHECKING, Any
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from framework.runtime.event_bus import AgentEvent, EventBus
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
_DIGEST_SYSTEM = """\
|
||||
You maintain run digests for a worker agent.
|
||||
A run digest is a concise, factual record of a single task execution.
|
||||
|
||||
Write 3-6 sentences covering:
|
||||
- What the worker was asked to do (the task/goal)
|
||||
- What approach it took and what tools it used
|
||||
- What the outcome was (success, partial, or failure — and why if relevant)
|
||||
- Any notable issues, retries, or escalations to the queen
|
||||
|
||||
Write in third person past tense. Be direct and specific.
|
||||
Omit routine tool invocations unless the result matters.
|
||||
Output only the digest prose — no headings, no code fences.
|
||||
"""
|
||||
|
||||
|
||||
def _worker_runs_dir(agent_name: str) -> Path:
|
||||
return Path.home() / ".hive" / "agents" / agent_name / "runs"
|
||||
|
||||
|
||||
def digest_path(agent_name: str, run_id: str) -> Path:
|
||||
return _worker_runs_dir(agent_name) / run_id / "digest.md"
|
||||
|
||||
|
||||
def _collect_run_events(bus: EventBus, run_id: str, limit: int = 2000) -> list[AgentEvent]:
|
||||
"""Collect all events belonging to *run_id* from the bus history.
|
||||
|
||||
Strategy: find the EXECUTION_STARTED event that carries ``run_id``,
|
||||
extract its ``execution_id``, then query the bus by that execution_id.
|
||||
This works because TOOL_CALL_*, EDGE_TRAVERSED, NODE_STALLED etc. carry
|
||||
execution_id but not run_id.
|
||||
|
||||
Falls back to a full-scan run_id filter when EXECUTION_STARTED is not
|
||||
found (e.g. bus was rotated).
|
||||
"""
|
||||
from framework.runtime.event_bus import EventType
|
||||
|
||||
# Pass 1: find execution_id via EXECUTION_STARTED with matching run_id
|
||||
started = bus.get_history(event_type=EventType.EXECUTION_STARTED, limit=limit)
|
||||
exec_id: str | None = None
|
||||
for e in started:
|
||||
if getattr(e, "run_id", None) == run_id and e.execution_id:
|
||||
exec_id = e.execution_id
|
||||
break
|
||||
|
||||
if exec_id:
|
||||
return bus.get_history(execution_id=exec_id, limit=limit)
|
||||
|
||||
# Fallback: scan all events and match by run_id attribute
|
||||
return [e for e in bus.get_history(limit=limit) if getattr(e, "run_id", None) == run_id]
|
||||
|
||||
|
||||
def _build_run_context(
|
||||
events: list[AgentEvent],
|
||||
outcome_event: AgentEvent | None,
|
||||
) -> str:
|
||||
"""Assemble a plain-text run context string for the digest LLM call."""
|
||||
from framework.runtime.event_bus import EventType
|
||||
|
||||
# Reverse so events are in chronological order
|
||||
events_chron = list(reversed(events))
|
||||
|
||||
lines: list[str] = []
|
||||
|
||||
# Task input from EXECUTION_STARTED
|
||||
started = [e for e in events_chron if e.type == EventType.EXECUTION_STARTED]
|
||||
if started:
|
||||
inp = started[0].data.get("input", {})
|
||||
if inp:
|
||||
lines.append(f"Task input: {str(inp)[:400]}")
|
||||
|
||||
# Duration (elapsed so far if no outcome yet)
|
||||
ref_ts = outcome_event.timestamp if outcome_event else datetime.utcnow()
|
||||
if started:
|
||||
elapsed = (ref_ts - started[0].timestamp).total_seconds()
|
||||
m, s = divmod(int(elapsed), 60)
|
||||
lines.append(f"Duration so far: {m}m {s}s" if m else f"Duration so far: {s}s")
|
||||
|
||||
# Outcome
|
||||
if outcome_event is None:
|
||||
lines.append("Status: still running (mid-run snapshot)")
|
||||
elif outcome_event.type == EventType.EXECUTION_COMPLETED:
|
||||
out = outcome_event.data.get("output", {})
|
||||
out_str = f"Outcome: completed. Output: {str(out)[:300]}"
|
||||
lines.append(out_str if out else "Outcome: completed.")
|
||||
else:
|
||||
err = outcome_event.data.get("error", "")
|
||||
lines.append(f"Outcome: failed. Error: {str(err)[:300]}" if err else "Outcome: failed.")
|
||||
|
||||
# Node path (edge traversals)
|
||||
edges = [e for e in events_chron if e.type == EventType.EDGE_TRAVERSED]
|
||||
if edges:
|
||||
parts = [
|
||||
f"{e.data.get('source_node', '?')}->{e.data.get('target_node', '?')}"
|
||||
for e in edges[-20:]
|
||||
]
|
||||
lines.append(f"Node path: {', '.join(parts)}")
|
||||
|
||||
# Tools used
|
||||
tool_events = [e for e in events_chron if e.type == EventType.TOOL_CALL_COMPLETED]
|
||||
if tool_events:
|
||||
names = [e.data.get("tool_name", "?") for e in tool_events]
|
||||
counts = Counter(names)
|
||||
summary = ", ".join(f"{name}×{n}" if n > 1 else name for name, n in counts.most_common())
|
||||
lines.append(f"Tools used: {summary}")
|
||||
# Note any tool errors
|
||||
errors = [e for e in tool_events if e.data.get("is_error")]
|
||||
if errors:
|
||||
err_names = Counter(e.data.get("tool_name", "?") for e in errors)
|
||||
lines.append(f"Tool errors: {dict(err_names)}")
|
||||
|
||||
# Issues
|
||||
issue_map = {
|
||||
EventType.NODE_STALLED: "stall",
|
||||
EventType.NODE_TOOL_DOOM_LOOP: "doom loop",
|
||||
EventType.CONSTRAINT_VIOLATION: "constraint violation",
|
||||
EventType.NODE_RETRY: "retry",
|
||||
}
|
||||
issue_parts: list[str] = []
|
||||
for evt_type, label in issue_map.items():
|
||||
n = sum(1 for e in events_chron if e.type == evt_type)
|
||||
if n:
|
||||
issue_parts.append(f"{n} {label}(s)")
|
||||
if issue_parts:
|
||||
lines.append(f"Issues: {', '.join(issue_parts)}")
|
||||
|
||||
# Escalations to queen
|
||||
escalations = [e for e in events_chron if e.type == EventType.ESCALATION_REQUESTED]
|
||||
if escalations:
|
||||
lines.append(f"Escalations to queen: {len(escalations)}")
|
||||
|
||||
# Final LLM output snippet (last LLM_TEXT_DELTA snapshot)
|
||||
text_events = [e for e in reversed(events_chron) if e.type == EventType.LLM_TEXT_DELTA]
|
||||
if text_events:
|
||||
snapshot = text_events[0].data.get("snapshot", "") or ""
|
||||
if snapshot:
|
||||
lines.append(f"Final LLM output: {snapshot[-400:].strip()}")
|
||||
|
||||
return "\n".join(lines)
|
||||
|
||||
|
||||
async def consolidate_worker_run(
|
||||
agent_name: str,
|
||||
run_id: str,
|
||||
outcome_event: AgentEvent | None,
|
||||
bus: EventBus,
|
||||
llm: Any,
|
||||
) -> None:
|
||||
"""Write (or overwrite) the digest for a worker run.
|
||||
|
||||
Called fire-and-forget either:
|
||||
- After EXECUTION_COMPLETED / EXECUTION_FAILED (outcome_event set, final write)
|
||||
- Periodically during a run on a cooldown timer (outcome_event=None, mid-run snapshot)
|
||||
|
||||
The digest file is always overwritten so each call produces the freshest view.
|
||||
The final completion/failure call supersedes any mid-run snapshot.
|
||||
|
||||
Args:
|
||||
agent_name: Worker agent directory name (determines storage path).
|
||||
run_id: The run ID.
|
||||
outcome_event: EXECUTION_COMPLETED or EXECUTION_FAILED event, or None for
|
||||
a mid-run snapshot.
|
||||
bus: The session EventBus (shared queen + worker).
|
||||
llm: LLMProvider with an acomplete() method.
|
||||
"""
|
||||
try:
|
||||
events = _collect_run_events(bus, run_id)
|
||||
run_context = _build_run_context(events, outcome_event)
|
||||
if not run_context:
|
||||
logger.debug("worker_memory: no events for run %s, skipping digest", run_id)
|
||||
return
|
||||
|
||||
is_final = outcome_event is not None
|
||||
logger.info(
|
||||
"worker_memory: generating %s digest for run %s ...",
|
||||
"final" if is_final else "mid-run",
|
||||
run_id,
|
||||
)
|
||||
|
||||
from framework.agents.queen.config import default_config
|
||||
|
||||
resp = await llm.acomplete(
|
||||
messages=[{"role": "user", "content": run_context}],
|
||||
system=_DIGEST_SYSTEM,
|
||||
max_tokens=min(default_config.max_tokens, 512),
|
||||
)
|
||||
digest_text = (resp.content or "").strip()
|
||||
if not digest_text:
|
||||
logger.warning("worker_memory: LLM returned empty digest for run %s", run_id)
|
||||
return
|
||||
|
||||
path = digest_path(agent_name, run_id)
|
||||
path.parent.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
from framework.runtime.event_bus import EventType
|
||||
|
||||
ts = (outcome_event.timestamp if outcome_event else datetime.utcnow()).strftime(
|
||||
"%Y-%m-%d %H:%M"
|
||||
)
|
||||
if outcome_event is None:
|
||||
status = "running"
|
||||
elif outcome_event.type == EventType.EXECUTION_COMPLETED:
|
||||
status = "completed"
|
||||
else:
|
||||
status = "failed"
|
||||
|
||||
path.write_text(
|
||||
f"# {run_id}\n\n**{ts}** | {status}\n\n{digest_text}\n",
|
||||
encoding="utf-8",
|
||||
)
|
||||
logger.info(
|
||||
"worker_memory: %s digest written for run %s (%d chars)",
|
||||
status,
|
||||
run_id,
|
||||
len(digest_text),
|
||||
)
|
||||
|
||||
except Exception:
|
||||
tb = traceback.format_exc()
|
||||
logger.exception("worker_memory: digest failed for run %s", run_id)
|
||||
# Persist the error so it's findable without log access
|
||||
error_path = _worker_runs_dir(agent_name) / run_id / "digest_error.txt"
|
||||
try:
|
||||
error_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
error_path.write_text(
|
||||
f"run_id: {run_id}\ntime: {datetime.now().isoformat()}\n\n{tb}",
|
||||
encoding="utf-8",
|
||||
)
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
|
||||
def read_recent_digests(agent_name: str, max_runs: int = 5) -> list[tuple[str, str]]:
|
||||
"""Return recent run digests as [(run_id, content), ...], newest first.
|
||||
|
||||
Args:
|
||||
agent_name: Worker agent directory name.
|
||||
max_runs: Maximum number of digests to return.
|
||||
|
||||
Returns:
|
||||
List of (run_id, digest_content) tuples, ordered newest first.
|
||||
"""
|
||||
runs_dir = _worker_runs_dir(agent_name)
|
||||
if not runs_dir.exists():
|
||||
return []
|
||||
|
||||
digest_files = sorted(
|
||||
runs_dir.glob("*/digest.md"),
|
||||
key=lambda p: p.stat().st_mtime,
|
||||
reverse=True,
|
||||
)[:max_runs]
|
||||
|
||||
result: list[tuple[str, str]] = []
|
||||
for f in digest_files:
|
||||
try:
|
||||
content = f.read_text(encoding="utf-8").strip()
|
||||
if content:
|
||||
result.append((f.parent.name, content))
|
||||
except OSError:
|
||||
continue
|
||||
return result
|
||||
@@ -1,21 +0,0 @@
|
||||
"""Builder interface for analyzing and building agents."""
|
||||
|
||||
from framework.builder.query import BuilderQuery
|
||||
from framework.builder.workflow import (
|
||||
BuildPhase,
|
||||
BuildSession,
|
||||
GraphBuilder,
|
||||
TestCase,
|
||||
TestResult,
|
||||
ValidationResult,
|
||||
)
|
||||
|
||||
__all__ = [
|
||||
"BuilderQuery",
|
||||
"GraphBuilder",
|
||||
"BuildSession",
|
||||
"BuildPhase",
|
||||
"ValidationResult",
|
||||
"TestCase",
|
||||
"TestResult",
|
||||
]
|
||||
@@ -1,501 +0,0 @@
|
||||
"""
|
||||
Builder Query Interface - How I (Builder) analyze agent runs.
|
||||
|
||||
This is designed around the questions I need to answer:
|
||||
1. What happened? (summaries, narratives)
|
||||
2. Why did it fail? (failure analysis, decision traces)
|
||||
3. What patterns emerge? (across runs, across nodes)
|
||||
4. What should we change? (suggestions)
|
||||
"""
|
||||
|
||||
from collections import defaultdict
|
||||
from pathlib import Path
|
||||
from typing import Any
|
||||
|
||||
from framework.schemas.decision import Decision
|
||||
from framework.schemas.run import Run, RunStatus, RunSummary
|
||||
from framework.storage.backend import FileStorage
|
||||
|
||||
|
||||
class FailureAnalysis:
|
||||
"""Structured analysis of why a run failed."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
run_id: str,
|
||||
failure_point: str,
|
||||
root_cause: str,
|
||||
decision_chain: list[str],
|
||||
problems: list[str],
|
||||
suggestions: list[str],
|
||||
):
|
||||
self.run_id = run_id
|
||||
self.failure_point = failure_point
|
||||
self.root_cause = root_cause
|
||||
self.decision_chain = decision_chain
|
||||
self.problems = problems
|
||||
self.suggestions = suggestions
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
return {
|
||||
"run_id": self.run_id,
|
||||
"failure_point": self.failure_point,
|
||||
"root_cause": self.root_cause,
|
||||
"decision_chain": self.decision_chain,
|
||||
"problems": self.problems,
|
||||
"suggestions": self.suggestions,
|
||||
}
|
||||
|
||||
def __str__(self) -> str:
|
||||
lines = [
|
||||
f"=== Failure Analysis for {self.run_id} ===",
|
||||
"",
|
||||
f"Failure Point: {self.failure_point}",
|
||||
f"Root Cause: {self.root_cause}",
|
||||
"",
|
||||
"Decision Chain Leading to Failure:",
|
||||
]
|
||||
for i, dec in enumerate(self.decision_chain, 1):
|
||||
lines.append(f" {i}. {dec}")
|
||||
|
||||
if self.problems:
|
||||
lines.append("")
|
||||
lines.append("Reported Problems:")
|
||||
for prob in self.problems:
|
||||
lines.append(f" - {prob}")
|
||||
|
||||
if self.suggestions:
|
||||
lines.append("")
|
||||
lines.append("Suggestions:")
|
||||
for sug in self.suggestions:
|
||||
lines.append(f" → {sug}")
|
||||
|
||||
return "\n".join(lines)
|
||||
|
||||
|
||||
class PatternAnalysis:
|
||||
"""Patterns detected across multiple runs."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
goal_id: str,
|
||||
run_count: int,
|
||||
success_rate: float,
|
||||
common_failures: list[tuple[str, int]],
|
||||
problematic_nodes: list[tuple[str, float]],
|
||||
decision_patterns: dict[str, Any],
|
||||
):
|
||||
self.goal_id = goal_id
|
||||
self.run_count = run_count
|
||||
self.success_rate = success_rate
|
||||
self.common_failures = common_failures
|
||||
self.problematic_nodes = problematic_nodes
|
||||
self.decision_patterns = decision_patterns
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
return {
|
||||
"goal_id": self.goal_id,
|
||||
"run_count": self.run_count,
|
||||
"success_rate": self.success_rate,
|
||||
"common_failures": self.common_failures,
|
||||
"problematic_nodes": self.problematic_nodes,
|
||||
"decision_patterns": self.decision_patterns,
|
||||
}
|
||||
|
||||
def __str__(self) -> str:
|
||||
lines = [
|
||||
f"=== Pattern Analysis for Goal {self.goal_id} ===",
|
||||
"",
|
||||
f"Runs Analyzed: {self.run_count}",
|
||||
f"Success Rate: {self.success_rate:.1%}",
|
||||
]
|
||||
|
||||
if self.common_failures:
|
||||
lines.append("")
|
||||
lines.append("Common Failures:")
|
||||
for failure, count in self.common_failures:
|
||||
lines.append(f" - {failure} ({count} occurrences)")
|
||||
|
||||
if self.problematic_nodes:
|
||||
lines.append("")
|
||||
lines.append("Problematic Nodes (failure rate):")
|
||||
for node, rate in self.problematic_nodes:
|
||||
lines.append(f" - {node}: {rate:.1%} failure rate")
|
||||
|
||||
return "\n".join(lines)
|
||||
|
||||
|
||||
class BuilderQuery:
|
||||
"""
|
||||
The interface I (Builder) use to understand what agents are doing.
|
||||
|
||||
This is optimized for the questions I need to answer when analyzing
|
||||
agent behavior and deciding what to improve.
|
||||
"""
|
||||
|
||||
def __init__(self, storage_path: str | Path):
|
||||
self.storage = FileStorage(storage_path)
|
||||
|
||||
# === WHAT HAPPENED? ===
|
||||
|
||||
def get_run_summary(self, run_id: str) -> RunSummary | None:
|
||||
"""Get a quick summary of a run."""
|
||||
return self.storage.load_summary(run_id)
|
||||
|
||||
def get_full_run(self, run_id: str) -> Run | None:
|
||||
"""Get the complete run with all decisions."""
|
||||
return self.storage.load_run(run_id)
|
||||
|
||||
def list_runs_for_goal(self, goal_id: str) -> list[RunSummary]:
|
||||
"""Get summaries of all runs for a goal."""
|
||||
run_ids = self.storage.get_runs_by_goal(goal_id)
|
||||
summaries = []
|
||||
for run_id in run_ids:
|
||||
summary = self.storage.load_summary(run_id)
|
||||
if summary:
|
||||
summaries.append(summary)
|
||||
return summaries
|
||||
|
||||
def get_recent_failures(self, limit: int = 10) -> list[RunSummary]:
|
||||
"""Get recent failed runs."""
|
||||
run_ids = self.storage.get_runs_by_status(RunStatus.FAILED)
|
||||
summaries = []
|
||||
for run_id in run_ids[:limit]:
|
||||
summary = self.storage.load_summary(run_id)
|
||||
if summary:
|
||||
summaries.append(summary)
|
||||
return summaries
|
||||
|
||||
# === WHY DID IT FAIL? ===
|
||||
|
||||
def analyze_failure(self, run_id: str) -> FailureAnalysis | None:
|
||||
"""
|
||||
Deep analysis of why a run failed.
|
||||
|
||||
This is my primary tool for understanding what went wrong.
|
||||
"""
|
||||
run = self.storage.load_run(run_id)
|
||||
if run is None or run.status != RunStatus.FAILED:
|
||||
return None
|
||||
|
||||
# Find the first failed decision
|
||||
failed_decisions = [d for d in run.decisions if not d.was_successful]
|
||||
if not failed_decisions:
|
||||
failure_point = "Unknown - no decision marked as failed"
|
||||
root_cause = "Run failed but all decisions succeeded (external cause?)"
|
||||
else:
|
||||
first_failure = failed_decisions[0]
|
||||
failure_point = first_failure.summary_for_builder()
|
||||
root_cause = first_failure.outcome.error if first_failure.outcome else "Unknown"
|
||||
|
||||
# Build the decision chain leading to failure
|
||||
decision_chain = []
|
||||
for d in run.decisions:
|
||||
decision_chain.append(d.summary_for_builder())
|
||||
if not d.was_successful:
|
||||
break
|
||||
|
||||
# Extract problems
|
||||
problems = [f"[{p.severity}] {p.description}" for p in run.problems]
|
||||
|
||||
# Generate suggestions based on the failure
|
||||
suggestions = self._generate_suggestions(run, failed_decisions)
|
||||
|
||||
return FailureAnalysis(
|
||||
run_id=run_id,
|
||||
failure_point=failure_point,
|
||||
root_cause=root_cause,
|
||||
decision_chain=decision_chain,
|
||||
problems=problems,
|
||||
suggestions=suggestions,
|
||||
)
|
||||
|
||||
def get_decision_trace(self, run_id: str) -> list[str]:
|
||||
"""Get a readable trace of all decisions in a run."""
|
||||
run = self.storage.load_run(run_id)
|
||||
if run is None:
|
||||
return []
|
||||
return [d.summary_for_builder() for d in run.decisions]
|
||||
|
||||
# === WHAT PATTERNS EMERGE? ===
|
||||
|
||||
def find_patterns(self, goal_id: str) -> PatternAnalysis | None:
|
||||
"""
|
||||
Find patterns across runs for a goal.
|
||||
|
||||
This helps me understand systemic issues vs one-off failures.
|
||||
"""
|
||||
run_ids = self.storage.get_runs_by_goal(goal_id)
|
||||
if not run_ids:
|
||||
return None
|
||||
|
||||
runs = []
|
||||
for run_id in run_ids:
|
||||
run = self.storage.load_run(run_id)
|
||||
if run:
|
||||
runs.append(run)
|
||||
|
||||
if not runs:
|
||||
return None
|
||||
|
||||
# Calculate success rate
|
||||
completed = [r for r in runs if r.status == RunStatus.COMPLETED]
|
||||
success_rate = len(completed) / len(runs) if runs else 0.0
|
||||
|
||||
# Find common failures
|
||||
failure_counts: dict[str, int] = defaultdict(int)
|
||||
for run in runs:
|
||||
for decision in run.decisions:
|
||||
if not decision.was_successful and decision.outcome:
|
||||
error = decision.outcome.error or "Unknown error"
|
||||
failure_counts[error] += 1
|
||||
|
||||
common_failures = sorted(failure_counts.items(), key=lambda x: x[1], reverse=True)[:5]
|
||||
|
||||
# Find problematic nodes
|
||||
node_stats: dict[str, dict[str, int]] = defaultdict(lambda: {"total": 0, "failed": 0})
|
||||
for run in runs:
|
||||
for decision in run.decisions:
|
||||
node_stats[decision.node_id]["total"] += 1
|
||||
if not decision.was_successful:
|
||||
node_stats[decision.node_id]["failed"] += 1
|
||||
|
||||
problematic_nodes = []
|
||||
for node_id, stats in node_stats.items():
|
||||
if stats["total"] > 0:
|
||||
failure_rate = stats["failed"] / stats["total"]
|
||||
if failure_rate > 0.1: # More than 10% failure rate
|
||||
problematic_nodes.append((node_id, failure_rate))
|
||||
|
||||
problematic_nodes.sort(key=lambda x: x[1], reverse=True)
|
||||
|
||||
# Decision patterns
|
||||
decision_patterns = self._analyze_decision_patterns(runs)
|
||||
|
||||
return PatternAnalysis(
|
||||
goal_id=goal_id,
|
||||
run_count=len(runs),
|
||||
success_rate=success_rate,
|
||||
common_failures=common_failures,
|
||||
problematic_nodes=problematic_nodes,
|
||||
decision_patterns=decision_patterns,
|
||||
)
|
||||
|
||||
def compare_runs(self, run_id_1: str, run_id_2: str) -> dict[str, Any]:
|
||||
"""Compare two runs to understand what differed."""
|
||||
run1 = self.storage.load_run(run_id_1)
|
||||
run2 = self.storage.load_run(run_id_2)
|
||||
|
||||
if run1 is None or run2 is None:
|
||||
return {"error": "One or both runs not found"}
|
||||
|
||||
return {
|
||||
"run_1": {
|
||||
"id": run1.id,
|
||||
"status": run1.status.value,
|
||||
"decisions": len(run1.decisions),
|
||||
"success_rate": run1.metrics.success_rate,
|
||||
},
|
||||
"run_2": {
|
||||
"id": run2.id,
|
||||
"status": run2.status.value,
|
||||
"decisions": len(run2.decisions),
|
||||
"success_rate": run2.metrics.success_rate,
|
||||
},
|
||||
"differences": self._find_differences(run1, run2),
|
||||
}
|
||||
|
||||
# === WHAT SHOULD WE CHANGE? ===
|
||||
|
||||
def suggest_improvements(self, goal_id: str) -> list[dict[str, Any]]:
|
||||
"""
|
||||
Generate improvement suggestions based on run analysis.
|
||||
|
||||
This is what I use to propose changes to the human engineer.
|
||||
"""
|
||||
patterns = self.find_patterns(goal_id)
|
||||
if patterns is None:
|
||||
return []
|
||||
|
||||
suggestions = []
|
||||
|
||||
# Suggestion: Fix problematic nodes
|
||||
for node_id, failure_rate in patterns.problematic_nodes:
|
||||
suggestions.append(
|
||||
{
|
||||
"type": "node_improvement",
|
||||
"target": node_id,
|
||||
"reason": f"Node has {failure_rate:.1%} failure rate",
|
||||
"recommendation": (
|
||||
f"Review and improve node '{node_id}' - "
|
||||
"high failure rate suggests prompt or tool issues"
|
||||
),
|
||||
"priority": "high" if failure_rate > 0.3 else "medium",
|
||||
}
|
||||
)
|
||||
|
||||
# Suggestion: Address common failures
|
||||
for failure, count in patterns.common_failures:
|
||||
if count >= 2:
|
||||
suggestions.append(
|
||||
{
|
||||
"type": "error_handling",
|
||||
"target": failure,
|
||||
"reason": f"Error occurred {count} times",
|
||||
"recommendation": f"Add handling for: {failure}",
|
||||
"priority": "high" if count >= 5 else "medium",
|
||||
}
|
||||
)
|
||||
|
||||
# Suggestion: Overall success rate
|
||||
if patterns.success_rate < 0.8:
|
||||
suggestions.append(
|
||||
{
|
||||
"type": "architecture",
|
||||
"target": goal_id,
|
||||
"reason": f"Goal success rate is only {patterns.success_rate:.1%}",
|
||||
"recommendation": (
|
||||
"Consider restructuring the agent graph or improving goal definition"
|
||||
),
|
||||
"priority": "high",
|
||||
}
|
||||
)
|
||||
|
||||
return suggestions
|
||||
|
||||
def get_node_performance(self, node_id: str) -> dict[str, Any]:
|
||||
"""Get performance metrics for a specific node across all runs."""
|
||||
run_ids = self.storage.get_runs_by_node(node_id)
|
||||
|
||||
total_decisions = 0
|
||||
successful_decisions = 0
|
||||
total_latency = 0
|
||||
total_tokens = 0
|
||||
decision_types: dict[str, int] = defaultdict(int)
|
||||
|
||||
for run_id in run_ids:
|
||||
run = self.storage.load_run(run_id)
|
||||
if run:
|
||||
for decision in run.decisions:
|
||||
if decision.node_id == node_id:
|
||||
total_decisions += 1
|
||||
if decision.was_successful:
|
||||
successful_decisions += 1
|
||||
if decision.outcome:
|
||||
total_latency += decision.outcome.latency_ms
|
||||
total_tokens += decision.outcome.tokens_used
|
||||
decision_types[decision.decision_type.value] += 1
|
||||
|
||||
return {
|
||||
"node_id": node_id,
|
||||
"total_decisions": total_decisions,
|
||||
"success_rate": successful_decisions / total_decisions if total_decisions > 0 else 0,
|
||||
"avg_latency_ms": total_latency / total_decisions if total_decisions > 0 else 0,
|
||||
"total_tokens": total_tokens,
|
||||
"decision_type_distribution": dict(decision_types),
|
||||
}
|
||||
|
||||
# === PRIVATE HELPERS ===
|
||||
|
||||
def _generate_suggestions(
|
||||
self,
|
||||
run: Run,
|
||||
failed_decisions: list[Decision],
|
||||
) -> list[str]:
|
||||
"""Generate suggestions based on failure analysis."""
|
||||
suggestions = []
|
||||
|
||||
for decision in failed_decisions:
|
||||
# Check if there were alternatives
|
||||
if len(decision.options) > 1:
|
||||
chosen = decision.chosen_option
|
||||
alternatives = [o for o in decision.options if o.id != decision.chosen_option_id]
|
||||
if alternatives:
|
||||
alt_desc = alternatives[0].description
|
||||
chosen_desc = chosen.description if chosen else "unknown"
|
||||
suggestions.append(
|
||||
f"Consider alternative: '{alt_desc}' instead of '{chosen_desc}'"
|
||||
)
|
||||
|
||||
# Check for missing context
|
||||
if not decision.input_context:
|
||||
suggestions.append(
|
||||
f"Decision '{decision.intent}' had no input context - "
|
||||
"ensure relevant data is passed"
|
||||
)
|
||||
|
||||
# Check for constraint issues
|
||||
if decision.active_constraints:
|
||||
constraints = ", ".join(decision.active_constraints)
|
||||
suggestions.append(f"Review constraints: {constraints} - may be too restrictive")
|
||||
|
||||
# Check for reported problems with suggestions
|
||||
for problem in run.problems:
|
||||
if problem.suggested_fix:
|
||||
suggestions.append(problem.suggested_fix)
|
||||
|
||||
return suggestions
|
||||
|
||||
def _analyze_decision_patterns(self, runs: list[Run]) -> dict[str, Any]:
|
||||
"""Analyze decision patterns across runs."""
|
||||
type_counts: dict[str, int] = defaultdict(int)
|
||||
option_counts: dict[str, dict[str, int]] = defaultdict(lambda: defaultdict(int))
|
||||
|
||||
for run in runs:
|
||||
for decision in run.decisions:
|
||||
type_counts[decision.decision_type.value] += 1
|
||||
|
||||
# Track which options are chosen for similar intents
|
||||
intent_key = decision.intent[:50] # Truncate for grouping
|
||||
if decision.chosen_option:
|
||||
option_counts[intent_key][decision.chosen_option.description] += 1
|
||||
|
||||
# Find most common choices per intent
|
||||
common_choices = {}
|
||||
for intent, choices in option_counts.items():
|
||||
if choices:
|
||||
most_common = max(choices.items(), key=lambda x: x[1])
|
||||
common_choices[intent] = {
|
||||
"choice": most_common[0],
|
||||
"count": most_common[1],
|
||||
"alternatives": len(choices) - 1,
|
||||
}
|
||||
|
||||
return {
|
||||
"decision_type_distribution": dict(type_counts),
|
||||
"common_choices": common_choices,
|
||||
}
|
||||
|
||||
def _find_differences(self, run1: Run, run2: Run) -> list[str]:
|
||||
"""Find key differences between two runs."""
|
||||
differences = []
|
||||
|
||||
# Status difference
|
||||
if run1.status != run2.status:
|
||||
differences.append(f"Status: {run1.status.value} vs {run2.status.value}")
|
||||
|
||||
# Decision count difference
|
||||
if len(run1.decisions) != len(run2.decisions):
|
||||
differences.append(f"Decision count: {len(run1.decisions)} vs {len(run2.decisions)}")
|
||||
|
||||
# Find first divergence point
|
||||
for i, (d1, d2) in enumerate(zip(run1.decisions, run2.decisions, strict=False)):
|
||||
if d1.chosen_option_id != d2.chosen_option_id:
|
||||
differences.append(
|
||||
f"Diverged at decision {i}: "
|
||||
f"chose '{d1.chosen_option_id}' vs '{d2.chosen_option_id}'"
|
||||
)
|
||||
break
|
||||
|
||||
# Node differences
|
||||
nodes1 = set(run1.metrics.nodes_executed)
|
||||
nodes2 = set(run2.metrics.nodes_executed)
|
||||
if nodes1 != nodes2:
|
||||
only_1 = nodes1 - nodes2
|
||||
only_2 = nodes2 - nodes1
|
||||
if only_1:
|
||||
differences.append(f"Nodes only in run 1: {only_1}")
|
||||
if only_2:
|
||||
differences.append(f"Nodes only in run 2: {only_2}")
|
||||
|
||||
return differences
|
||||
@@ -1,807 +0,0 @@
|
||||
"""
|
||||
GraphBuilder Workflow - Enforced incremental building with HITL approval.
|
||||
|
||||
The build process:
|
||||
1. Define Goal → APPROVE
|
||||
2. Add Node → VALIDATE → TEST → APPROVE
|
||||
3. Add Edge → VALIDATE → TEST → APPROVE
|
||||
4. Repeat until graph is complete
|
||||
5. Final integration test → APPROVE
|
||||
6. Export
|
||||
|
||||
Each step requires validation and human approval before proceeding.
|
||||
You cannot skip steps or bypass validation.
|
||||
"""
|
||||
|
||||
from collections.abc import Callable
|
||||
from datetime import datetime
|
||||
from enum import Enum
|
||||
from pathlib import Path
|
||||
from typing import Any
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from framework.graph.edge import EdgeCondition, EdgeSpec, GraphSpec
|
||||
from framework.graph.goal import Goal
|
||||
from framework.graph.node import NodeSpec
|
||||
|
||||
|
||||
class BuildPhase(str, Enum):
|
||||
"""Current phase of the build process."""
|
||||
|
||||
INIT = "init" # Just started
|
||||
GOAL_DRAFT = "goal_draft" # Drafting goal
|
||||
GOAL_APPROVED = "goal_approved" # Goal approved
|
||||
ADDING_NODES = "adding_nodes" # Adding nodes
|
||||
ADDING_EDGES = "adding_edges" # Adding edges
|
||||
TESTING = "testing" # Running tests
|
||||
APPROVED = "approved" # Fully approved
|
||||
EXPORTED = "exported" # Exported to file
|
||||
|
||||
|
||||
class ValidationResult(BaseModel):
|
||||
"""Result of a validation check."""
|
||||
|
||||
valid: bool
|
||||
errors: list[str] = Field(default_factory=list)
|
||||
warnings: list[str] = Field(default_factory=list)
|
||||
suggestions: list[str] = Field(default_factory=list)
|
||||
|
||||
|
||||
class TestCase(BaseModel):
|
||||
"""A test case for validating agent behavior."""
|
||||
|
||||
id: str
|
||||
description: str
|
||||
input: dict[str, Any]
|
||||
expected_output: Any = None # None means just check it doesn't error
|
||||
expected_contains: str | None = None
|
||||
|
||||
|
||||
class TestResult(BaseModel):
|
||||
"""Result of running a test case."""
|
||||
|
||||
test_id: str
|
||||
passed: bool
|
||||
actual_output: Any = None
|
||||
error: str | None = None
|
||||
execution_path: list[str] = Field(default_factory=list)
|
||||
|
||||
|
||||
class BuildSession(BaseModel):
|
||||
"""
|
||||
Persistent build session state.
|
||||
|
||||
Saved after each approved step so you can resume later.
|
||||
"""
|
||||
|
||||
id: str
|
||||
name: str
|
||||
phase: BuildPhase = BuildPhase.INIT
|
||||
created_at: datetime = Field(default_factory=datetime.now)
|
||||
updated_at: datetime = Field(default_factory=datetime.now)
|
||||
|
||||
# The artifacts being built
|
||||
goal: Goal | None = None
|
||||
nodes: list[NodeSpec] = Field(default_factory=list)
|
||||
edges: list[EdgeSpec] = Field(default_factory=list)
|
||||
|
||||
# Test cases
|
||||
test_cases: list[TestCase] = Field(default_factory=list)
|
||||
test_results: list[TestResult] = Field(default_factory=list)
|
||||
|
||||
# Approval history
|
||||
approvals: list[dict[str, Any]] = Field(default_factory=list)
|
||||
|
||||
# Tools (stored as dicts for serialization)
|
||||
tools: list[dict[str, Any]] = Field(default_factory=list)
|
||||
|
||||
model_config = {"extra": "allow"}
|
||||
|
||||
|
||||
class GraphBuilder:
|
||||
"""
|
||||
Enforced incremental graph building with HITL approval.
|
||||
|
||||
Usage:
|
||||
builder = GraphBuilder("my-agent")
|
||||
|
||||
# Step 1: Define and approve goal
|
||||
builder.set_goal(goal)
|
||||
builder.validate() # Must pass
|
||||
builder.approve("Goal looks good") # Human approval required
|
||||
|
||||
# Step 2: Add nodes one by one
|
||||
builder.add_node(node_spec)
|
||||
builder.validate() # Must pass
|
||||
builder.test(test_case) # Must pass
|
||||
builder.approve("Node works")
|
||||
|
||||
# Step 3: Add edges
|
||||
builder.add_edge(edge_spec)
|
||||
builder.validate()
|
||||
builder.approve("Edge correct")
|
||||
|
||||
# Step 4: Final approval
|
||||
builder.run_all_tests()
|
||||
builder.final_approve("Ready for production")
|
||||
|
||||
# Step 5: Export
|
||||
graph = builder.export()
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
name: str,
|
||||
storage_path: Path | str | None = None,
|
||||
session_id: str | None = None,
|
||||
):
|
||||
self.storage_path = Path(storage_path) if storage_path else Path.home() / ".core" / "builds"
|
||||
self.storage_path.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
if session_id:
|
||||
self.session = self._load_session(session_id)
|
||||
else:
|
||||
self.session = BuildSession(
|
||||
id=f"build_{datetime.now().strftime('%Y%m%d_%H%M%S')}",
|
||||
name=name,
|
||||
)
|
||||
|
||||
self._pending_validation: ValidationResult | None = None
|
||||
|
||||
# =========================================================================
|
||||
# PHASE 1: GOAL
|
||||
# =========================================================================
|
||||
|
||||
def set_goal(self, goal: Goal) -> ValidationResult:
|
||||
"""
|
||||
Set the goal for this agent.
|
||||
|
||||
Returns validation result. Must call approve() after validation passes.
|
||||
"""
|
||||
self._require_phase([BuildPhase.INIT, BuildPhase.GOAL_DRAFT])
|
||||
|
||||
self.session.goal = goal
|
||||
self.session.phase = BuildPhase.GOAL_DRAFT
|
||||
|
||||
validation = self._validate_goal(goal)
|
||||
self._pending_validation = validation
|
||||
self._save_session()
|
||||
|
||||
return validation
|
||||
|
||||
def _validate_goal(self, goal: Goal) -> ValidationResult:
|
||||
"""Validate a goal definition."""
|
||||
errors = []
|
||||
warnings = []
|
||||
suggestions = []
|
||||
|
||||
if not goal.id:
|
||||
errors.append("Goal must have an id")
|
||||
if not goal.name:
|
||||
errors.append("Goal must have a name")
|
||||
if not goal.description:
|
||||
errors.append("Goal must have a description")
|
||||
|
||||
if not goal.success_criteria:
|
||||
errors.append("Goal must have at least one success criterion")
|
||||
else:
|
||||
for sc in goal.success_criteria:
|
||||
if not sc.description:
|
||||
errors.append(f"Success criterion '{sc.id}' needs a description")
|
||||
|
||||
if not goal.constraints:
|
||||
warnings.append("Consider adding constraints to define boundaries")
|
||||
|
||||
if not goal.required_capabilities:
|
||||
suggestions.append("Specify required_capabilities (e.g., ['llm', 'tools'])")
|
||||
|
||||
return ValidationResult(
|
||||
valid=len(errors) == 0,
|
||||
errors=errors,
|
||||
warnings=warnings,
|
||||
suggestions=suggestions,
|
||||
)
|
||||
|
||||
# =========================================================================
|
||||
# PHASE 2: NODES
|
||||
# =========================================================================
|
||||
|
||||
def add_node(self, node: NodeSpec) -> ValidationResult:
|
||||
"""
|
||||
Add a node to the graph.
|
||||
|
||||
Returns validation result. Must call approve() after validation passes.
|
||||
"""
|
||||
self._require_phase([BuildPhase.GOAL_APPROVED, BuildPhase.ADDING_NODES])
|
||||
|
||||
# Check for duplicate
|
||||
if any(n.id == node.id for n in self.session.nodes):
|
||||
return ValidationResult(
|
||||
valid=False,
|
||||
errors=[f"Node with id '{node.id}' already exists"],
|
||||
)
|
||||
|
||||
self.session.nodes.append(node)
|
||||
self.session.phase = BuildPhase.ADDING_NODES
|
||||
|
||||
validation = self._validate_node(node)
|
||||
self._pending_validation = validation
|
||||
self._save_session()
|
||||
|
||||
return validation
|
||||
|
||||
def _validate_node(self, node: NodeSpec) -> ValidationResult:
|
||||
"""Validate a node definition."""
|
||||
errors = []
|
||||
warnings = []
|
||||
suggestions = []
|
||||
|
||||
if not node.id:
|
||||
errors.append("Node must have an id")
|
||||
if not node.name:
|
||||
errors.append("Node must have a name")
|
||||
if not node.description:
|
||||
warnings.append(f"Node '{node.id}' should have a description")
|
||||
|
||||
# Type-specific validation
|
||||
if node.node_type == "llm_tool_use":
|
||||
if not node.tools:
|
||||
errors.append(f"LLM tool node '{node.id}' must specify tools")
|
||||
if not node.system_prompt:
|
||||
warnings.append(f"LLM node '{node.id}' should have a system_prompt")
|
||||
|
||||
if node.node_type == "router":
|
||||
if not node.routes:
|
||||
errors.append(f"Router node '{node.id}' must specify routes")
|
||||
|
||||
if node.node_type == "function":
|
||||
if not node.function:
|
||||
errors.append(f"Function node '{node.id}' must specify function name")
|
||||
|
||||
# Check input/output keys
|
||||
if not node.input_keys:
|
||||
suggestions.append(f"Consider specifying input_keys for '{node.id}'")
|
||||
if not node.output_keys:
|
||||
suggestions.append(f"Consider specifying output_keys for '{node.id}'")
|
||||
|
||||
return ValidationResult(
|
||||
valid=len(errors) == 0,
|
||||
errors=errors,
|
||||
warnings=warnings,
|
||||
suggestions=suggestions,
|
||||
)
|
||||
|
||||
def update_node(self, node_id: str, **updates) -> ValidationResult:
|
||||
"""Update an existing node."""
|
||||
self._require_phase([BuildPhase.ADDING_NODES])
|
||||
|
||||
for i, node in enumerate(self.session.nodes):
|
||||
if node.id == node_id:
|
||||
node_dict = node.model_dump()
|
||||
node_dict.update(updates)
|
||||
updated_node = NodeSpec(**node_dict)
|
||||
self.session.nodes[i] = updated_node
|
||||
|
||||
validation = self._validate_node(updated_node)
|
||||
self._pending_validation = validation
|
||||
self._save_session()
|
||||
return validation
|
||||
|
||||
return ValidationResult(valid=False, errors=[f"Node '{node_id}' not found"])
|
||||
|
||||
def remove_node(self, node_id: str) -> ValidationResult:
|
||||
"""Remove a node (only if no edges reference it)."""
|
||||
self._require_phase([BuildPhase.ADDING_NODES])
|
||||
|
||||
# Check for edge references
|
||||
for edge in self.session.edges:
|
||||
if edge.source == node_id or edge.target == node_id:
|
||||
return ValidationResult(
|
||||
valid=False,
|
||||
errors=[f"Cannot remove node '{node_id}': referenced by edge '{edge.id}'"],
|
||||
)
|
||||
|
||||
self.session.nodes = [n for n in self.session.nodes if n.id != node_id]
|
||||
self._save_session()
|
||||
|
||||
return ValidationResult(valid=True)
|
||||
|
||||
# =========================================================================
|
||||
# PHASE 3: EDGES
|
||||
# =========================================================================
|
||||
|
||||
def add_edge(self, edge: EdgeSpec) -> ValidationResult:
|
||||
"""
|
||||
Add an edge to the graph.
|
||||
|
||||
Returns validation result. Must call approve() after validation passes.
|
||||
"""
|
||||
self._require_phase([BuildPhase.ADDING_NODES, BuildPhase.ADDING_EDGES])
|
||||
|
||||
# Check for duplicate
|
||||
if any(e.id == edge.id for e in self.session.edges):
|
||||
return ValidationResult(
|
||||
valid=False,
|
||||
errors=[f"Edge with id '{edge.id}' already exists"],
|
||||
)
|
||||
|
||||
self.session.edges.append(edge)
|
||||
self.session.phase = BuildPhase.ADDING_EDGES
|
||||
|
||||
validation = self._validate_edge(edge)
|
||||
self._pending_validation = validation
|
||||
self._save_session()
|
||||
|
||||
return validation
|
||||
|
||||
def _validate_edge(self, edge: EdgeSpec) -> ValidationResult:
|
||||
"""Validate an edge definition."""
|
||||
errors = []
|
||||
warnings = []
|
||||
|
||||
if not edge.id:
|
||||
errors.append("Edge must have an id")
|
||||
|
||||
# Check source exists
|
||||
if not any(n.id == edge.source for n in self.session.nodes):
|
||||
errors.append(f"Edge source '{edge.source}' not found in nodes")
|
||||
|
||||
# Check target exists
|
||||
if not any(n.id == edge.target for n in self.session.nodes):
|
||||
errors.append(f"Edge target '{edge.target}' not found in nodes")
|
||||
|
||||
# Warn about conditional edges without expressions
|
||||
if edge.condition == EdgeCondition.CONDITIONAL and not edge.condition_expr:
|
||||
warnings.append(f"Conditional edge '{edge.id}' has no condition_expr")
|
||||
|
||||
return ValidationResult(
|
||||
valid=len(errors) == 0,
|
||||
errors=errors,
|
||||
warnings=warnings,
|
||||
)
|
||||
|
||||
# =========================================================================
|
||||
# VALIDATION & TESTING
|
||||
# =========================================================================
|
||||
|
||||
def validate(self) -> ValidationResult:
|
||||
"""Validate the entire current graph state."""
|
||||
errors = []
|
||||
warnings = []
|
||||
|
||||
# Must have a goal
|
||||
if not self.session.goal:
|
||||
errors.append("No goal defined")
|
||||
return ValidationResult(valid=False, errors=errors)
|
||||
|
||||
# Must have at least one node
|
||||
if not self.session.nodes:
|
||||
errors.append("No nodes defined")
|
||||
|
||||
# Check for entry node
|
||||
entry_candidates = []
|
||||
for node in self.session.nodes:
|
||||
# A node is an entry candidate if no edges point to it
|
||||
if not any(e.target == node.id for e in self.session.edges):
|
||||
entry_candidates.append(node.id)
|
||||
|
||||
if len(entry_candidates) == 0 and self.session.nodes:
|
||||
errors.append("No entry node found (all nodes have incoming edges)")
|
||||
elif len(entry_candidates) > 1:
|
||||
warnings.append(f"Multiple entry candidates: {entry_candidates}. Specify one.")
|
||||
|
||||
# Check for terminal nodes
|
||||
terminal_candidates = []
|
||||
for node in self.session.nodes:
|
||||
if not any(e.source == node.id for e in self.session.edges):
|
||||
terminal_candidates.append(node.id)
|
||||
|
||||
if not terminal_candidates and self.session.nodes:
|
||||
warnings.append("No terminal nodes found (all nodes have outgoing edges)")
|
||||
|
||||
# Check reachability
|
||||
if entry_candidates and self.session.nodes:
|
||||
reachable = self._compute_reachable(entry_candidates[0])
|
||||
unreachable = [n.id for n in self.session.nodes if n.id not in reachable]
|
||||
if unreachable:
|
||||
errors.append(f"Unreachable nodes: {unreachable}")
|
||||
|
||||
validation = ValidationResult(
|
||||
valid=len(errors) == 0,
|
||||
errors=errors,
|
||||
warnings=warnings,
|
||||
)
|
||||
self._pending_validation = validation
|
||||
return validation
|
||||
|
||||
def _compute_reachable(self, start: str) -> set[str]:
|
||||
"""Compute all nodes reachable from start."""
|
||||
reachable = set()
|
||||
to_visit = [start]
|
||||
|
||||
while to_visit:
|
||||
current = to_visit.pop()
|
||||
if current in reachable:
|
||||
continue
|
||||
reachable.add(current)
|
||||
|
||||
for edge in self.session.edges:
|
||||
if edge.source == current:
|
||||
to_visit.append(edge.target)
|
||||
|
||||
# Also follow router routes
|
||||
for node in self.session.nodes:
|
||||
if node.id == current and node.routes:
|
||||
for target in node.routes.values():
|
||||
to_visit.append(target)
|
||||
|
||||
return reachable
|
||||
|
||||
def add_test(self, test: TestCase) -> None:
|
||||
"""Add a test case."""
|
||||
self.session.test_cases.append(test)
|
||||
self._save_session()
|
||||
|
||||
def run_test(
|
||||
self,
|
||||
test: TestCase,
|
||||
executor_factory: Callable,
|
||||
) -> TestResult:
|
||||
"""
|
||||
Run a single test case.
|
||||
|
||||
executor_factory should return a configured GraphExecutor.
|
||||
"""
|
||||
self._require_phase([BuildPhase.ADDING_NODES, BuildPhase.ADDING_EDGES, BuildPhase.TESTING])
|
||||
self.session.phase = BuildPhase.TESTING
|
||||
|
||||
try:
|
||||
# Build temporary graph for testing
|
||||
graph = self._build_graph()
|
||||
executor = executor_factory()
|
||||
|
||||
# Run the test
|
||||
import asyncio
|
||||
|
||||
result = asyncio.run(
|
||||
executor.execute(
|
||||
graph=graph,
|
||||
goal=self.session.goal,
|
||||
input_data=test.input,
|
||||
)
|
||||
)
|
||||
|
||||
# Check result
|
||||
passed = result.success
|
||||
if test.expected_output is not None:
|
||||
passed = passed and (result.output.get("result") == test.expected_output)
|
||||
if test.expected_contains:
|
||||
output_str = str(result.output)
|
||||
passed = passed and (test.expected_contains in output_str)
|
||||
|
||||
test_result = TestResult(
|
||||
test_id=test.id,
|
||||
passed=passed,
|
||||
actual_output=result.output,
|
||||
execution_path=result.path,
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
test_result = TestResult(
|
||||
test_id=test.id,
|
||||
passed=False,
|
||||
error=str(e),
|
||||
)
|
||||
|
||||
self.session.test_results.append(test_result)
|
||||
self._save_session()
|
||||
|
||||
return test_result
|
||||
|
||||
def run_all_tests(self, executor_factory: Callable) -> list[TestResult]:
|
||||
"""Run all test cases."""
|
||||
results = []
|
||||
for test in self.session.test_cases:
|
||||
result = self.run_test(test, executor_factory)
|
||||
results.append(result)
|
||||
return results
|
||||
|
||||
# =========================================================================
|
||||
# APPROVAL
|
||||
# =========================================================================
|
||||
|
||||
def approve(self, comment: str) -> bool:
|
||||
"""
|
||||
Approve the current pending change.
|
||||
|
||||
Must have a passing validation to approve.
|
||||
Returns True if approved, False if validation failed.
|
||||
"""
|
||||
if self._pending_validation is None:
|
||||
raise RuntimeError("Nothing to approve. Run validation first.")
|
||||
|
||||
if not self._pending_validation.valid:
|
||||
return False
|
||||
|
||||
self.session.approvals.append(
|
||||
{
|
||||
"phase": self.session.phase.value,
|
||||
"comment": comment,
|
||||
"timestamp": datetime.now().isoformat(),
|
||||
"validation": self._pending_validation.model_dump(),
|
||||
}
|
||||
)
|
||||
|
||||
# Advance phase if appropriate
|
||||
if self.session.phase == BuildPhase.GOAL_DRAFT:
|
||||
self.session.phase = BuildPhase.GOAL_APPROVED
|
||||
|
||||
self._pending_validation = None
|
||||
self._save_session()
|
||||
|
||||
return True
|
||||
|
||||
def final_approve(self, comment: str) -> bool:
|
||||
"""
|
||||
Final approval for the complete graph.
|
||||
|
||||
Requires all tests to pass.
|
||||
"""
|
||||
# Run final validation
|
||||
validation = self.validate()
|
||||
if not validation.valid:
|
||||
self._pending_validation = validation
|
||||
return False
|
||||
|
||||
# Check test results
|
||||
if self.session.test_cases:
|
||||
failed_tests = [t for t in self.session.test_results if not t.passed]
|
||||
if failed_tests:
|
||||
self._pending_validation = ValidationResult(
|
||||
valid=False,
|
||||
errors=[f"Failed tests: {[t.test_id for t in failed_tests]}"],
|
||||
)
|
||||
return False
|
||||
|
||||
self.session.phase = BuildPhase.APPROVED
|
||||
self.session.approvals.append(
|
||||
{
|
||||
"phase": "final",
|
||||
"comment": comment,
|
||||
"timestamp": datetime.now().isoformat(),
|
||||
}
|
||||
)
|
||||
|
||||
self._save_session()
|
||||
return True
|
||||
|
||||
# =========================================================================
|
||||
# EXPORT
|
||||
# =========================================================================
|
||||
|
||||
def export(self) -> GraphSpec:
|
||||
"""
|
||||
Export the approved graph.
|
||||
|
||||
Requires final approval.
|
||||
"""
|
||||
self._require_phase([BuildPhase.APPROVED])
|
||||
|
||||
graph = self._build_graph()
|
||||
|
||||
self.session.phase = BuildPhase.EXPORTED
|
||||
self._save_session()
|
||||
|
||||
return graph
|
||||
|
||||
def _build_graph(self) -> GraphSpec:
|
||||
"""Build a GraphSpec from current session."""
|
||||
# Determine entry node
|
||||
entry_node = None
|
||||
for node in self.session.nodes:
|
||||
if not any(e.target == node.id for e in self.session.edges):
|
||||
entry_node = node.id
|
||||
break
|
||||
|
||||
# Determine terminal nodes
|
||||
terminal_nodes = []
|
||||
for node in self.session.nodes:
|
||||
if not any(e.source == node.id for e in self.session.edges):
|
||||
terminal_nodes.append(node.id)
|
||||
|
||||
# Collect all memory keys
|
||||
memory_keys = set()
|
||||
for node in self.session.nodes:
|
||||
memory_keys.update(node.input_keys)
|
||||
memory_keys.update(node.output_keys)
|
||||
|
||||
return GraphSpec(
|
||||
id=f"{self.session.name}-graph",
|
||||
goal_id=self.session.goal.id if self.session.goal else "",
|
||||
entry_node=entry_node or "",
|
||||
terminal_nodes=terminal_nodes,
|
||||
nodes=self.session.nodes,
|
||||
edges=self.session.edges,
|
||||
memory_keys=list(memory_keys),
|
||||
)
|
||||
|
||||
def export_to_file(self, path: Path | str) -> None:
|
||||
"""Export the graph to a Python file."""
|
||||
self._require_phase([BuildPhase.APPROVED, BuildPhase.EXPORTED])
|
||||
|
||||
graph = self._build_graph()
|
||||
|
||||
# Generate Python code
|
||||
code = self._generate_code(graph)
|
||||
|
||||
Path(path).write_text(code)
|
||||
self.session.phase = BuildPhase.EXPORTED
|
||||
self._save_session()
|
||||
|
||||
def _generate_code(self, graph: GraphSpec) -> str:
|
||||
"""Generate Python code for the graph."""
|
||||
lines = [
|
||||
'"""',
|
||||
f"Generated agent: {self.session.name}",
|
||||
f"Generated at: {datetime.now().isoformat()}",
|
||||
'"""',
|
||||
"",
|
||||
"from framework.graph import (",
|
||||
" Goal, SuccessCriterion, Constraint,",
|
||||
" NodeSpec, EdgeSpec, EdgeCondition,",
|
||||
")",
|
||||
"from framework.graph.edge import GraphSpec",
|
||||
"from framework.graph.goal import GoalStatus",
|
||||
"",
|
||||
"",
|
||||
"# Goal",
|
||||
]
|
||||
|
||||
if self.session.goal:
|
||||
goal_json = self.session.goal.model_dump_json(indent=4)
|
||||
lines.append("GOAL = Goal.model_validate_json('''")
|
||||
lines.append(goal_json)
|
||||
lines.append("''')")
|
||||
else:
|
||||
lines.append("GOAL = None")
|
||||
|
||||
lines.extend(
|
||||
[
|
||||
"",
|
||||
"",
|
||||
"# Nodes",
|
||||
"NODES = [",
|
||||
]
|
||||
)
|
||||
|
||||
for node in self.session.nodes:
|
||||
node_json = node.model_dump_json(indent=4)
|
||||
lines.append(" NodeSpec.model_validate_json('''")
|
||||
lines.append(node_json)
|
||||
lines.append(" '''),")
|
||||
|
||||
lines.extend(
|
||||
[
|
||||
"]",
|
||||
"",
|
||||
"",
|
||||
"# Edges",
|
||||
"EDGES = [",
|
||||
]
|
||||
)
|
||||
|
||||
for edge in self.session.edges:
|
||||
edge_json = edge.model_dump_json(indent=4)
|
||||
lines.append(" EdgeSpec.model_validate_json('''")
|
||||
lines.append(edge_json)
|
||||
lines.append(" '''),")
|
||||
|
||||
lines.extend(
|
||||
[
|
||||
"]",
|
||||
"",
|
||||
"",
|
||||
"# Graph",
|
||||
]
|
||||
)
|
||||
|
||||
graph_json = graph.model_dump_json(indent=4)
|
||||
lines.append("GRAPH = GraphSpec.model_validate_json('''")
|
||||
lines.append(graph_json)
|
||||
lines.append("''')")
|
||||
|
||||
return "\n".join(lines)
|
||||
|
||||
# =========================================================================
|
||||
# SESSION MANAGEMENT
|
||||
# =========================================================================
|
||||
|
||||
def _require_phase(self, allowed: list[BuildPhase]) -> None:
|
||||
"""Ensure we're in an allowed phase."""
|
||||
if self.session.phase not in allowed:
|
||||
raise RuntimeError(
|
||||
f"Cannot perform this action in phase '{self.session.phase.value}'. "
|
||||
f"Allowed phases: {[p.value for p in allowed]}"
|
||||
)
|
||||
|
||||
def _save_session(self) -> None:
|
||||
"""Save session to disk."""
|
||||
self.session.updated_at = datetime.now()
|
||||
path = self.storage_path / f"{self.session.id}.json"
|
||||
path.write_text(self.session.model_dump_json(indent=2))
|
||||
|
||||
def _load_session(self, session_id: str) -> BuildSession:
|
||||
"""Load session from disk."""
|
||||
path = self.storage_path / f"{session_id}.json"
|
||||
if not path.exists():
|
||||
raise FileNotFoundError(f"Session not found: {session_id}")
|
||||
return BuildSession.model_validate_json(path.read_text())
|
||||
|
||||
@classmethod
|
||||
def list_sessions(cls, storage_path: Path | str | None = None) -> list[str]:
|
||||
"""List all saved sessions."""
|
||||
path = Path(storage_path) if storage_path else Path.home() / ".core" / "builds"
|
||||
if not path.exists():
|
||||
return []
|
||||
return [f.stem for f in path.glob("*.json")]
|
||||
|
||||
# =========================================================================
|
||||
# STATUS
|
||||
# =========================================================================
|
||||
|
||||
def status(self) -> dict[str, Any]:
|
||||
"""Get current build status."""
|
||||
return {
|
||||
"session_id": self.session.id,
|
||||
"name": self.session.name,
|
||||
"phase": self.session.phase.value,
|
||||
"goal": self.session.goal.name if self.session.goal else None,
|
||||
"nodes": len(self.session.nodes),
|
||||
"edges": len(self.session.edges),
|
||||
"tests": len(self.session.test_cases),
|
||||
"tests_passed": sum(1 for t in self.session.test_results if t.passed),
|
||||
"approvals": len(self.session.approvals),
|
||||
"pending_validation": self._pending_validation.model_dump()
|
||||
if self._pending_validation
|
||||
else None,
|
||||
}
|
||||
|
||||
def show(self) -> str:
|
||||
"""Show current graph as text."""
|
||||
lines = [
|
||||
f"=== Build: {self.session.name} ===",
|
||||
f"Phase: {self.session.phase.value}",
|
||||
"",
|
||||
]
|
||||
|
||||
if self.session.goal:
|
||||
lines.extend(
|
||||
[
|
||||
f"Goal: {self.session.goal.name}",
|
||||
f" {self.session.goal.description}",
|
||||
"",
|
||||
]
|
||||
)
|
||||
|
||||
if self.session.nodes:
|
||||
lines.append("Nodes:")
|
||||
for node in self.session.nodes:
|
||||
lines.append(f" [{node.id}] {node.name} ({node.node_type})")
|
||||
lines.append("")
|
||||
|
||||
if self.session.edges:
|
||||
lines.append("Edges:")
|
||||
for edge in self.session.edges:
|
||||
lines.append(f" {edge.source} --{edge.condition.value}--> {edge.target}")
|
||||
lines.append("")
|
||||
|
||||
if self._pending_validation:
|
||||
lines.append("Pending Validation:")
|
||||
lines.append(f" Valid: {self._pending_validation.valid}")
|
||||
for err in self._pending_validation.errors:
|
||||
lines.append(f" ERROR: {err}")
|
||||
for warn in self._pending_validation.warnings:
|
||||
lines.append(f" WARN: {warn}")
|
||||
|
||||
return "\n".join(lines)
|
||||
+17
-3
@@ -11,9 +11,9 @@ Usage:
|
||||
|
||||
Testing commands:
|
||||
hive test-run <agent_path> --goal <goal_id>
|
||||
hive test-debug <goal_id> <test_id>
|
||||
hive test-list <goal_id>
|
||||
hive test-stats <goal_id>
|
||||
hive test-debug <agent_path> <test_name>
|
||||
hive test-list <agent_path>
|
||||
hive test-stats <agent_path>
|
||||
"""
|
||||
|
||||
import argparse
|
||||
@@ -44,11 +44,25 @@ def _configure_paths():
|
||||
if exports_str not in sys.path:
|
||||
sys.path.insert(0, exports_str)
|
||||
|
||||
# Add examples/templates/ to sys.path so template agents are importable
|
||||
templates_dir = project_root / "examples" / "templates"
|
||||
if templates_dir.is_dir():
|
||||
templates_str = str(templates_dir)
|
||||
if templates_str not in sys.path:
|
||||
sys.path.insert(0, templates_str)
|
||||
|
||||
# Ensure core/ is also in sys.path (for non-editable-install scenarios)
|
||||
core_str = str(project_root / "core")
|
||||
if (project_root / "core").is_dir() and core_str not in sys.path:
|
||||
sys.path.insert(0, core_str)
|
||||
|
||||
# Add core/framework/agents/ so framework agents are importable as top-level packages
|
||||
framework_agents_dir = project_root / "core" / "framework" / "agents"
|
||||
if framework_agents_dir.is_dir():
|
||||
fa_str = str(framework_agents_dir)
|
||||
if fa_str not in sys.path:
|
||||
sys.path.insert(0, fa_str)
|
||||
|
||||
|
||||
def main():
|
||||
_configure_paths()
|
||||
|
||||
@@ -0,0 +1,204 @@
|
||||
"""Shared Hive configuration utilities.
|
||||
|
||||
Centralises reading of ~/.hive/configuration.json so that the runner
|
||||
and every agent template share one implementation instead of copy-pasting
|
||||
helper functions.
|
||||
"""
|
||||
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
from dataclasses import dataclass, field
|
||||
from pathlib import Path
|
||||
from typing import Any
|
||||
|
||||
from framework.graph.edge import DEFAULT_MAX_TOKENS
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Low-level config file access
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
HIVE_CONFIG_FILE = Path.home() / ".hive" / "configuration.json"
|
||||
|
||||
# Hive LLM router endpoint (Anthropic-compatible).
|
||||
# litellm's Anthropic handler appends /v1/messages, so this is just the base host.
|
||||
HIVE_LLM_ENDPOINT = "https://api.adenhq.com"
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def get_hive_config() -> dict[str, Any]:
|
||||
"""Load hive configuration from ~/.hive/configuration.json."""
|
||||
if not HIVE_CONFIG_FILE.exists():
|
||||
return {}
|
||||
try:
|
||||
with open(HIVE_CONFIG_FILE, encoding="utf-8-sig") as f:
|
||||
return json.load(f)
|
||||
except (json.JSONDecodeError, OSError) as e:
|
||||
logger.warning(
|
||||
"Failed to load Hive config %s: %s",
|
||||
HIVE_CONFIG_FILE,
|
||||
e,
|
||||
)
|
||||
return {}
|
||||
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Derived helpers
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
|
||||
def get_preferred_model() -> str:
|
||||
"""Return the user's preferred LLM model string (e.g. 'anthropic/claude-sonnet-4-20250514')."""
|
||||
llm = get_hive_config().get("llm", {})
|
||||
if llm.get("provider") and llm.get("model"):
|
||||
return f"{llm['provider']}/{llm['model']}"
|
||||
return "anthropic/claude-sonnet-4-20250514"
|
||||
|
||||
|
||||
def get_max_tokens() -> int:
|
||||
"""Return the configured max_tokens, falling back to DEFAULT_MAX_TOKENS."""
|
||||
return get_hive_config().get("llm", {}).get("max_tokens", DEFAULT_MAX_TOKENS)
|
||||
|
||||
|
||||
DEFAULT_MAX_CONTEXT_TOKENS = 32_000
|
||||
|
||||
|
||||
def get_max_context_tokens() -> int:
|
||||
"""Return the configured max_context_tokens, falling back to DEFAULT_MAX_CONTEXT_TOKENS."""
|
||||
return get_hive_config().get("llm", {}).get("max_context_tokens", DEFAULT_MAX_CONTEXT_TOKENS)
|
||||
|
||||
|
||||
def get_api_key() -> str | None:
|
||||
"""Return the API key, supporting env var, Claude Code subscription, Codex, and ZAI Code.
|
||||
|
||||
Priority:
|
||||
1. Claude Code subscription (``use_claude_code_subscription: true``)
|
||||
reads the OAuth token from ``~/.claude/.credentials.json``.
|
||||
2. Codex subscription (``use_codex_subscription: true``)
|
||||
reads the OAuth token from macOS Keychain or ``~/.codex/auth.json``.
|
||||
3. Environment variable named in ``api_key_env_var``.
|
||||
"""
|
||||
llm = get_hive_config().get("llm", {})
|
||||
|
||||
# Claude Code subscription: read OAuth token directly
|
||||
if llm.get("use_claude_code_subscription"):
|
||||
try:
|
||||
from framework.runner.runner import get_claude_code_token
|
||||
|
||||
token = get_claude_code_token()
|
||||
if token:
|
||||
return token
|
||||
except ImportError:
|
||||
pass
|
||||
|
||||
# Codex subscription: read OAuth token from Keychain / auth.json
|
||||
if llm.get("use_codex_subscription"):
|
||||
try:
|
||||
from framework.runner.runner import get_codex_token
|
||||
|
||||
token = get_codex_token()
|
||||
if token:
|
||||
return token
|
||||
except ImportError:
|
||||
pass
|
||||
|
||||
# Kimi Code subscription: read API key from ~/.kimi/config.toml
|
||||
if llm.get("use_kimi_code_subscription"):
|
||||
try:
|
||||
from framework.runner.runner import get_kimi_code_token
|
||||
|
||||
token = get_kimi_code_token()
|
||||
if token:
|
||||
return token
|
||||
except ImportError:
|
||||
pass
|
||||
|
||||
# Standard env-var path (covers ZAI Code and all API-key providers)
|
||||
api_key_env_var = llm.get("api_key_env_var")
|
||||
if api_key_env_var:
|
||||
return os.environ.get(api_key_env_var)
|
||||
return None
|
||||
|
||||
|
||||
def get_gcu_enabled() -> bool:
|
||||
"""Return whether GCU (browser automation) is enabled in user config."""
|
||||
return get_hive_config().get("gcu_enabled", True)
|
||||
|
||||
|
||||
def get_gcu_viewport_scale() -> float:
|
||||
"""Return GCU viewport scale factor (0.1-1.0), default 0.8."""
|
||||
scale = get_hive_config().get("gcu_viewport_scale", 0.8)
|
||||
if isinstance(scale, (int, float)) and 0.1 <= scale <= 1.0:
|
||||
return float(scale)
|
||||
return 0.8
|
||||
|
||||
|
||||
def get_api_base() -> str | None:
|
||||
"""Return the api_base URL for OpenAI-compatible endpoints, if configured."""
|
||||
llm = get_hive_config().get("llm", {})
|
||||
if llm.get("use_codex_subscription"):
|
||||
# Codex subscription routes through the ChatGPT backend, not api.openai.com.
|
||||
return "https://chatgpt.com/backend-api/codex"
|
||||
if llm.get("use_kimi_code_subscription"):
|
||||
# Kimi Code uses an Anthropic-compatible endpoint (no /v1 suffix).
|
||||
return "https://api.kimi.com/coding"
|
||||
return llm.get("api_base")
|
||||
|
||||
|
||||
def get_llm_extra_kwargs() -> dict[str, Any]:
|
||||
"""Return extra kwargs for LiteLLMProvider (e.g. OAuth headers).
|
||||
|
||||
When ``use_claude_code_subscription`` is enabled, returns
|
||||
``extra_headers`` with the OAuth Bearer token so that litellm's
|
||||
built-in Anthropic OAuth handler adds the required beta headers.
|
||||
|
||||
When ``use_codex_subscription`` is enabled, returns
|
||||
``extra_headers`` with the Bearer token, ``ChatGPT-Account-Id``,
|
||||
and ``store=False`` (required by the ChatGPT backend).
|
||||
"""
|
||||
llm = get_hive_config().get("llm", {})
|
||||
if llm.get("use_claude_code_subscription"):
|
||||
api_key = get_api_key()
|
||||
if api_key:
|
||||
return {
|
||||
"extra_headers": {"authorization": f"Bearer {api_key}"},
|
||||
}
|
||||
if llm.get("use_codex_subscription"):
|
||||
api_key = get_api_key()
|
||||
if api_key:
|
||||
headers: dict[str, str] = {
|
||||
"Authorization": f"Bearer {api_key}",
|
||||
"User-Agent": "CodexBar",
|
||||
}
|
||||
try:
|
||||
from framework.runner.runner import get_codex_account_id
|
||||
|
||||
account_id = get_codex_account_id()
|
||||
if account_id:
|
||||
headers["ChatGPT-Account-Id"] = account_id
|
||||
except ImportError:
|
||||
pass
|
||||
return {
|
||||
"extra_headers": headers,
|
||||
"store": False,
|
||||
"allowed_openai_params": ["store"],
|
||||
}
|
||||
return {}
|
||||
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# RuntimeConfig – shared across agent templates
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
|
||||
@dataclass
|
||||
class RuntimeConfig:
|
||||
"""Agent runtime configuration loaded from ~/.hive/configuration.json."""
|
||||
|
||||
model: str = field(default_factory=get_preferred_model)
|
||||
temperature: float = 0.7
|
||||
max_tokens: int = field(default_factory=get_max_tokens)
|
||||
max_context_tokens: int = field(default_factory=get_max_context_tokens)
|
||||
api_key: str | None = field(default_factory=get_api_key)
|
||||
api_base: str | None = field(default_factory=get_api_base)
|
||||
extra_kwargs: dict[str, Any] = field(default_factory=get_llm_extra_kwargs)
|
||||
@@ -6,7 +6,7 @@ This module provides secure credential storage with:
|
||||
- Template-based usage: {{cred.key}} patterns for injection
|
||||
- Bipartisan model: Store stores values, tools define usage
|
||||
- Provider system: Extensible lifecycle management (refresh, validate)
|
||||
- Multiple backends: Encrypted files, env vars, HashiCorp Vault
|
||||
- Multiple backends: Encrypted files, env vars
|
||||
|
||||
Quick Start:
|
||||
from core.framework.credentials import CredentialStore, CredentialObject
|
||||
@@ -38,10 +38,16 @@ For Aden server sync:
|
||||
AdenSyncProvider,
|
||||
)
|
||||
|
||||
For Vault integration:
|
||||
from core.framework.credentials.vault import HashiCorpVaultStorage
|
||||
"""
|
||||
|
||||
from .key_storage import (
|
||||
delete_aden_api_key,
|
||||
generate_and_save_credential_key,
|
||||
load_aden_api_key,
|
||||
load_credential_key,
|
||||
save_aden_api_key,
|
||||
save_credential_key,
|
||||
)
|
||||
from .models import (
|
||||
CredentialDecryptionError,
|
||||
CredentialError,
|
||||
@@ -59,6 +65,13 @@ from .provider import (
|
||||
CredentialProvider,
|
||||
StaticProvider,
|
||||
)
|
||||
from .setup import (
|
||||
CredentialSetupSession,
|
||||
MissingCredential,
|
||||
SetupResult,
|
||||
load_agent_nodes,
|
||||
run_credential_setup_cli,
|
||||
)
|
||||
from .storage import (
|
||||
CompositeStorage,
|
||||
CredentialStorage,
|
||||
@@ -68,6 +81,12 @@ from .storage import (
|
||||
)
|
||||
from .store import CredentialStore
|
||||
from .template import TemplateResolver
|
||||
from .validation import (
|
||||
CredentialStatus,
|
||||
CredentialValidationResult,
|
||||
ensure_credential_key_env,
|
||||
validate_agent_credentials,
|
||||
)
|
||||
|
||||
# Aden sync components (lazy import to avoid httpx dependency when not needed)
|
||||
# Usage: from core.framework.credentials.aden import AdenSyncProvider
|
||||
@@ -84,6 +103,14 @@ try:
|
||||
except ImportError:
|
||||
_ADEN_AVAILABLE = False
|
||||
|
||||
# Local credential registry (named API key accounts with identity metadata)
|
||||
try:
|
||||
from .local import LocalAccountInfo, LocalCredentialRegistry
|
||||
|
||||
_LOCAL_AVAILABLE = True
|
||||
except ImportError:
|
||||
_LOCAL_AVAILABLE = False
|
||||
|
||||
__all__ = [
|
||||
# Main store
|
||||
"CredentialStore",
|
||||
@@ -111,12 +138,34 @@ __all__ = [
|
||||
"CredentialRefreshError",
|
||||
"CredentialValidationError",
|
||||
"CredentialDecryptionError",
|
||||
# Key storage (bootstrap credentials)
|
||||
"load_credential_key",
|
||||
"save_credential_key",
|
||||
"generate_and_save_credential_key",
|
||||
"load_aden_api_key",
|
||||
"save_aden_api_key",
|
||||
"delete_aden_api_key",
|
||||
# Validation
|
||||
"ensure_credential_key_env",
|
||||
"validate_agent_credentials",
|
||||
"CredentialStatus",
|
||||
"CredentialValidationResult",
|
||||
# Interactive setup
|
||||
"CredentialSetupSession",
|
||||
"MissingCredential",
|
||||
"SetupResult",
|
||||
"load_agent_nodes",
|
||||
"run_credential_setup_cli",
|
||||
# Aden sync (optional - requires httpx)
|
||||
"AdenSyncProvider",
|
||||
"AdenCredentialClient",
|
||||
"AdenClientConfig",
|
||||
"AdenCachedStorage",
|
||||
# Local credential registry (optional - requires cryptography)
|
||||
"LocalCredentialRegistry",
|
||||
"LocalAccountInfo",
|
||||
]
|
||||
|
||||
# Track Aden availability for runtime checks
|
||||
ADEN_AVAILABLE = _ADEN_AVAILABLE
|
||||
LOCAL_AVAILABLE = _LOCAL_AVAILABLE
|
||||
|
||||
@@ -1,33 +1,36 @@
|
||||
"""
|
||||
Aden Credential Client.
|
||||
|
||||
HTTP client for communicating with the Aden authentication server.
|
||||
The Aden server handles OAuth2 authorization flows and token management.
|
||||
This client fetches tokens and delegates refresh operations to Aden.
|
||||
HTTP client for the Aden authentication server.
|
||||
Aden holds all OAuth secrets; agents receive only short-lived access tokens.
|
||||
|
||||
API (all endpoints authenticated with Bearer {api_key}):
|
||||
|
||||
GET /v1/credentials — list integrations
|
||||
GET /v1/credentials/{integration_id} — get access token (auto-refreshes)
|
||||
POST /v1/credentials/{integration_id}/refresh — force refresh
|
||||
GET /v1/credentials/{integration_id}/validate — check validity
|
||||
|
||||
Integration IDs are base64-encoded hashes assigned by the Aden platform
|
||||
(e.g. "Z29vZ2xlOlRpbW90aHk6MTYwNjc6MTM2ODQ"), NOT provider names.
|
||||
|
||||
Usage:
|
||||
# API key loaded from ADEN_API_KEY environment variable by default
|
||||
client = AdenCredentialClient(AdenClientConfig(
|
||||
base_url="https://api.adenhq.com",
|
||||
))
|
||||
|
||||
# Or explicitly provide the API key
|
||||
client = AdenCredentialClient(AdenClientConfig(
|
||||
base_url="https://api.adenhq.com",
|
||||
api_key="your-api-key",
|
||||
))
|
||||
# List what's connected
|
||||
for info in client.list_integrations():
|
||||
print(f"{info.provider}/{info.alias}: {info.status}")
|
||||
|
||||
# Fetch a credential
|
||||
response = client.get_credential("hubspot")
|
||||
if response:
|
||||
print(f"Token expires at: {response.expires_at}")
|
||||
|
||||
# Request a refresh
|
||||
refreshed = client.request_refresh("hubspot")
|
||||
# Get an access token
|
||||
cred = client.get_credential(info.integration_id)
|
||||
print(cred.access_token)
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import json as _json
|
||||
import logging
|
||||
import os
|
||||
import time
|
||||
@@ -88,8 +91,7 @@ class AdenClientConfig:
|
||||
"""Base URL of the Aden server (e.g., 'https://api.adenhq.com')."""
|
||||
|
||||
api_key: str | None = None
|
||||
"""Agent's API key for authenticating with Aden.
|
||||
If not provided, loaded from ADEN_API_KEY environment variable."""
|
||||
"""Agent API key. Loaded from ADEN_API_KEY env var if not provided."""
|
||||
|
||||
tenant_id: str | None = None
|
||||
"""Optional tenant ID for multi-tenant deployments."""
|
||||
@@ -104,7 +106,6 @@ class AdenClientConfig:
|
||||
"""Base delay between retries in seconds (exponential backoff)."""
|
||||
|
||||
def __post_init__(self) -> None:
|
||||
"""Load API key from environment if not provided."""
|
||||
if self.api_key is None:
|
||||
self.api_key = os.environ.get("ADEN_API_KEY")
|
||||
if not self.api_key:
|
||||
@@ -115,71 +116,124 @@ class AdenClientConfig:
|
||||
|
||||
|
||||
@dataclass
|
||||
class AdenCredentialResponse:
|
||||
"""Response from Aden server containing credential data."""
|
||||
class AdenIntegrationInfo:
|
||||
"""An integration from GET /v1/credentials.
|
||||
|
||||
Example response item::
|
||||
|
||||
{
|
||||
"integration_id": "Z29vZ2xlOlRpbW90aHk6MTYwNjc6MTM2ODQ",
|
||||
"provider": "google",
|
||||
"alias": "Timothy",
|
||||
"status": "active",
|
||||
"email": "timothy@acho.io",
|
||||
"expires_at": "2026-02-20T21:46:04.863Z"
|
||||
}
|
||||
"""
|
||||
|
||||
integration_id: str
|
||||
"""Unique identifier for the integration (e.g., 'hubspot')."""
|
||||
"""Base64-encoded hash ID assigned by Aden."""
|
||||
|
||||
integration_type: str
|
||||
"""Type of integration (e.g., 'hubspot', 'github', 'slack')."""
|
||||
provider: str
|
||||
"""Provider type (e.g. "google", "slack", "hubspot")."""
|
||||
|
||||
access_token: str
|
||||
"""The access token for API calls."""
|
||||
alias: str
|
||||
"""User-set alias on the Aden platform."""
|
||||
|
||||
token_type: str = "Bearer"
|
||||
"""Token type (usually 'Bearer')."""
|
||||
status: str
|
||||
"""Status: "active", "expired", "requires_reauth"."""
|
||||
|
||||
email: str = ""
|
||||
"""Email associated with this connection."""
|
||||
|
||||
expires_at: datetime | None = None
|
||||
"""When the access token expires (UTC)."""
|
||||
"""When the current access token expires."""
|
||||
|
||||
scopes: list[str] = field(default_factory=list)
|
||||
"""OAuth2 scopes granted to this token."""
|
||||
|
||||
metadata: dict[str, Any] = field(default_factory=dict)
|
||||
"""Additional integration-specific metadata."""
|
||||
# Backward compat — old code reads integration_type
|
||||
@property
|
||||
def integration_type(self) -> str:
|
||||
return self.provider
|
||||
|
||||
@classmethod
|
||||
def from_dict(
|
||||
cls, data: dict[str, Any], integration_id: str | None = None
|
||||
) -> AdenCredentialResponse:
|
||||
"""Create from API response dictionary."""
|
||||
def from_dict(cls, data: dict[str, Any]) -> AdenIntegrationInfo:
|
||||
expires_at = None
|
||||
if data.get("expires_at"):
|
||||
expires_at = datetime.fromisoformat(data["expires_at"].replace("Z", "+00:00"))
|
||||
|
||||
return cls(
|
||||
integration_id=integration_id or data.get("alias", data.get("provider", "")),
|
||||
integration_type=data.get("provider", ""),
|
||||
access_token=data["access_token"],
|
||||
token_type=data.get("token_type", "Bearer"),
|
||||
integration_id=data.get("integration_id", ""),
|
||||
provider=data.get("provider", ""),
|
||||
alias=data.get("alias", ""),
|
||||
status=data.get("status", "unknown"),
|
||||
email=data.get("email", ""),
|
||||
expires_at=expires_at,
|
||||
scopes=data.get("scopes", []),
|
||||
metadata={"email": data.get("email")} if data.get("email") else {},
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class AdenIntegrationInfo:
|
||||
"""Information about an available integration."""
|
||||
class AdenCredentialResponse:
|
||||
"""Response from GET /v1/credentials/{integration_id}.
|
||||
|
||||
Example::
|
||||
|
||||
{
|
||||
"access_token": "ya29.a0AfH6SM...",
|
||||
"token_type": "Bearer",
|
||||
"expires_at": "2026-02-20T12:00:00.000Z",
|
||||
"provider": "google",
|
||||
"alias": "Timothy",
|
||||
"email": "timothy@acho.io"
|
||||
}
|
||||
"""
|
||||
|
||||
integration_id: str
|
||||
integration_type: str
|
||||
status: str # "active", "requires_reauth", "expired"
|
||||
"""The integration_id used in the request."""
|
||||
|
||||
access_token: str
|
||||
"""Short-lived access token for API calls."""
|
||||
|
||||
token_type: str = "Bearer"
|
||||
|
||||
expires_at: datetime | None = None
|
||||
|
||||
provider: str = ""
|
||||
"""Provider type (e.g. "google")."""
|
||||
|
||||
alias: str = ""
|
||||
"""User-set alias."""
|
||||
|
||||
email: str = ""
|
||||
"""Email associated with this connection."""
|
||||
|
||||
scopes: list[str] = field(default_factory=list)
|
||||
metadata: dict[str, Any] = field(default_factory=dict)
|
||||
|
||||
# Backward compat
|
||||
@property
|
||||
def integration_type(self) -> str:
|
||||
return self.provider
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, data: dict[str, Any]) -> AdenIntegrationInfo:
|
||||
"""Create from API response dictionary."""
|
||||
def from_dict(cls, data: dict[str, Any], integration_id: str = "") -> AdenCredentialResponse:
|
||||
expires_at = None
|
||||
if data.get("expires_at"):
|
||||
expires_at = datetime.fromisoformat(data["expires_at"].replace("Z", "+00:00"))
|
||||
|
||||
# Build metadata from email if present
|
||||
metadata = data.get("metadata") or {}
|
||||
if not metadata and data.get("email"):
|
||||
metadata = {"email": data["email"]}
|
||||
|
||||
return cls(
|
||||
integration_id=data["integration_id"],
|
||||
integration_type=data.get("provider", data["integration_id"]),
|
||||
status=data.get("status", "unknown"),
|
||||
integration_id=integration_id or data.get("integration_id", ""),
|
||||
access_token=data["access_token"],
|
||||
token_type=data.get("token_type", "Bearer"),
|
||||
expires_at=expires_at,
|
||||
provider=data.get("provider", ""),
|
||||
alias=data.get("alias", ""),
|
||||
email=data.get("email", ""),
|
||||
scopes=data.get("scopes", []),
|
||||
metadata=metadata,
|
||||
)
|
||||
|
||||
|
||||
@@ -187,56 +241,38 @@ class AdenCredentialClient:
|
||||
"""
|
||||
HTTP client for Aden credential server.
|
||||
|
||||
Handles communication with the Aden authentication server,
|
||||
including fetching credentials, requesting refreshes, and
|
||||
reporting usage statistics.
|
||||
|
||||
The client automatically handles:
|
||||
- Retries with exponential backoff for transient failures
|
||||
- Proper error classification (auth, not found, rate limit, etc.)
|
||||
- Request headers for authentication and tenant isolation
|
||||
|
||||
Usage:
|
||||
# API key loaded from ADEN_API_KEY environment variable
|
||||
config = AdenClientConfig(
|
||||
client = AdenCredentialClient(AdenClientConfig(
|
||||
base_url="https://api.adenhq.com",
|
||||
)
|
||||
))
|
||||
|
||||
client = AdenCredentialClient(config)
|
||||
# List integrations
|
||||
for info in client.list_integrations():
|
||||
print(f"{info.provider}/{info.alias}: {info.status}")
|
||||
|
||||
# Fetch a credential
|
||||
cred = client.get_credential("hubspot")
|
||||
if cred:
|
||||
headers = {"Authorization": f"Bearer {cred.access_token}"}
|
||||
# Get access token (uses base64 integration_id, NOT provider name)
|
||||
cred = client.get_credential(info.integration_id)
|
||||
headers = {"Authorization": f"Bearer {cred.access_token}"}
|
||||
|
||||
# List all integrations
|
||||
integrations = client.list_integrations()
|
||||
for info in integrations:
|
||||
print(f"{info.integration_id}: {info.status}")
|
||||
|
||||
# Clean up
|
||||
client.close()
|
||||
"""
|
||||
|
||||
def __init__(self, config: AdenClientConfig):
|
||||
"""
|
||||
Initialize the Aden client.
|
||||
|
||||
Args:
|
||||
config: Client configuration including base URL and API key.
|
||||
"""
|
||||
self.config = config
|
||||
self._client: httpx.Client | None = None
|
||||
|
||||
@staticmethod
|
||||
def _parse_json(response: httpx.Response) -> Any:
|
||||
"""Parse JSON from response, tolerating UTF-8 BOM."""
|
||||
return _json.loads(response.content.decode("utf-8-sig"))
|
||||
|
||||
def _get_client(self) -> httpx.Client:
|
||||
"""Get or create the HTTP client."""
|
||||
if self._client is None:
|
||||
headers = {
|
||||
"Authorization": f"Bearer {self.config.api_key}",
|
||||
"Content-Type": "application/json",
|
||||
"User-Agent": "hive-credential-store/1.0",
|
||||
}
|
||||
|
||||
if self.config.tenant_id:
|
||||
headers["X-Tenant-ID"] = self.config.tenant_id
|
||||
|
||||
@@ -245,7 +281,6 @@ class AdenCredentialClient:
|
||||
timeout=self.config.timeout,
|
||||
headers=headers,
|
||||
)
|
||||
|
||||
return self._client
|
||||
|
||||
def _request_with_retry(
|
||||
@@ -262,10 +297,13 @@ class AdenCredentialClient:
|
||||
try:
|
||||
response = client.request(method, path, **kwargs)
|
||||
|
||||
# Handle specific error codes
|
||||
if response.status_code == 401:
|
||||
raise AdenAuthenticationError("Agent API key is invalid or revoked")
|
||||
|
||||
if response.status_code == 403:
|
||||
data = self._parse_json(response)
|
||||
raise AdenClientError(data.get("message", "Forbidden"))
|
||||
|
||||
if response.status_code == 404:
|
||||
raise AdenNotFoundError(f"Integration not found: {path}")
|
||||
|
||||
@@ -277,15 +315,16 @@ class AdenCredentialClient:
|
||||
)
|
||||
|
||||
if response.status_code == 400:
|
||||
data = response.json()
|
||||
if data.get("error") == "refresh_failed":
|
||||
data = self._parse_json(response)
|
||||
msg = data.get("message", "Bad request")
|
||||
if data.get("error") == "refresh_failed" or "refresh" in msg.lower():
|
||||
raise AdenRefreshError(
|
||||
data.get("message", "Token refresh failed"),
|
||||
msg,
|
||||
requires_reauthorization=data.get("requires_reauthorization", False),
|
||||
reauthorization_url=data.get("reauthorization_url"),
|
||||
)
|
||||
raise AdenClientError(f"Bad request: {msg}")
|
||||
|
||||
# Success or other error
|
||||
response.raise_for_status()
|
||||
return response
|
||||
|
||||
@@ -306,161 +345,96 @@ class AdenCredentialClient:
|
||||
AdenRefreshError,
|
||||
AdenRateLimitError,
|
||||
):
|
||||
# Don't retry these errors
|
||||
raise
|
||||
|
||||
# Should not reach here, but just in case
|
||||
raise AdenClientError(
|
||||
f"Request failed after {self.config.retry_attempts} attempts"
|
||||
) from last_error
|
||||
|
||||
def get_credential(self, integration_id: str) -> AdenCredentialResponse | None:
|
||||
def list_integrations(self) -> list[AdenIntegrationInfo]:
|
||||
"""
|
||||
Fetch the current credential for an integration.
|
||||
List all integrations for this agent's team.
|
||||
|
||||
The Aden server may refresh the token internally if it's expired
|
||||
before returning it.
|
||||
|
||||
Args:
|
||||
integration_id: The integration identifier (e.g., 'hubspot').
|
||||
GET /v1/credentials → {"integrations": [...]}
|
||||
|
||||
Returns:
|
||||
Credential response with access token, or None if not found.
|
||||
List of AdenIntegrationInfo with integration_id, provider,
|
||||
alias, status, email, expires_at.
|
||||
"""
|
||||
response = self._request_with_retry("GET", "/v1/credentials")
|
||||
data = self._parse_json(response)
|
||||
return [AdenIntegrationInfo.from_dict(item) for item in data.get("integrations", [])]
|
||||
|
||||
Raises:
|
||||
AdenAuthenticationError: If API key is invalid.
|
||||
AdenClientError: For connection failures.
|
||||
# Alias
|
||||
list_connections = list_integrations
|
||||
|
||||
def get_credential(self, integration_id: str) -> AdenCredentialResponse | None:
|
||||
"""
|
||||
Get access token for an integration. Auto-refreshes if near expiry.
|
||||
|
||||
GET /v1/credentials/{integration_id}
|
||||
|
||||
Args:
|
||||
integration_id: Base64 hash ID from list_integrations().
|
||||
|
||||
Returns:
|
||||
AdenCredentialResponse with access_token, or None if not found.
|
||||
"""
|
||||
try:
|
||||
response = self._request_with_retry("GET", f"/v1/credentials/{integration_id}")
|
||||
data = response.json()
|
||||
data = self._parse_json(response)
|
||||
return AdenCredentialResponse.from_dict(data, integration_id=integration_id)
|
||||
except AdenNotFoundError:
|
||||
return None
|
||||
|
||||
def request_refresh(self, integration_id: str) -> AdenCredentialResponse:
|
||||
"""
|
||||
Request the Aden server to refresh the token.
|
||||
Force refresh the access token.
|
||||
|
||||
Use this when the local store detects an expired or near-expiry token.
|
||||
The Aden server handles the actual OAuth2 refresh token flow.
|
||||
POST /v1/credentials/{integration_id}/refresh
|
||||
|
||||
Args:
|
||||
integration_id: The integration identifier.
|
||||
integration_id: Base64 hash ID.
|
||||
|
||||
Returns:
|
||||
Credential response with new access token.
|
||||
|
||||
Raises:
|
||||
AdenRefreshError: If refresh fails (may require re-authorization).
|
||||
AdenNotFoundError: If integration not found.
|
||||
AdenAuthenticationError: If API key is invalid.
|
||||
AdenRateLimitError: If rate limited.
|
||||
AdenCredentialResponse with new access_token.
|
||||
"""
|
||||
response = self._request_with_retry("POST", f"/v1/credentials/{integration_id}/refresh")
|
||||
data = response.json()
|
||||
data = self._parse_json(response)
|
||||
return AdenCredentialResponse.from_dict(data, integration_id=integration_id)
|
||||
|
||||
def list_integrations(self) -> list[AdenIntegrationInfo]:
|
||||
"""
|
||||
List all integrations available for this agent/tenant.
|
||||
|
||||
Returns:
|
||||
List of integration info objects.
|
||||
|
||||
Raises:
|
||||
AdenAuthenticationError: If API key is invalid.
|
||||
AdenClientError: For connection failures.
|
||||
"""
|
||||
response = self._request_with_retry("GET", "/v1/credentials")
|
||||
data = response.json()
|
||||
return [AdenIntegrationInfo.from_dict(item) for item in data.get("integrations", [])]
|
||||
|
||||
def validate_token(self, integration_id: str) -> dict[str, Any]:
|
||||
"""
|
||||
Check if a token is still valid without fetching it.
|
||||
Check if an integration's OAuth connection is valid.
|
||||
|
||||
Args:
|
||||
integration_id: The integration identifier.
|
||||
GET /v1/credentials/{integration_id}/validate
|
||||
|
||||
Returns:
|
||||
Dict with 'valid' bool and optional 'expires_at', 'reason',
|
||||
'requires_reauthorization', 'reauthorization_url'.
|
||||
|
||||
Raises:
|
||||
AdenNotFoundError: If integration not found.
|
||||
AdenAuthenticationError: If API key is invalid.
|
||||
{"valid": bool, "status": str, "expires_at": str, "error": str|null}
|
||||
"""
|
||||
response = self._request_with_retry("GET", f"/v1/credentials/{integration_id}/validate")
|
||||
return response.json()
|
||||
|
||||
def report_usage(
|
||||
self,
|
||||
integration_id: str,
|
||||
operation: str,
|
||||
status: str = "success",
|
||||
metadata: dict[str, Any] | None = None,
|
||||
) -> None:
|
||||
"""
|
||||
Report credential usage statistics to Aden.
|
||||
|
||||
This is optional and used for analytics/billing.
|
||||
|
||||
Args:
|
||||
integration_id: The integration identifier.
|
||||
operation: Operation name (e.g., 'api_call').
|
||||
status: Operation status ('success', 'error').
|
||||
metadata: Additional operation metadata.
|
||||
"""
|
||||
try:
|
||||
self._request_with_retry(
|
||||
"POST",
|
||||
f"/v1/credentials/{integration_id}/usage",
|
||||
json={
|
||||
"operation": operation,
|
||||
"status": status,
|
||||
"timestamp": datetime.utcnow().isoformat() + "Z",
|
||||
"metadata": metadata or {},
|
||||
},
|
||||
)
|
||||
except Exception as e:
|
||||
# Usage reporting is best-effort, don't fail on errors
|
||||
logger.warning(f"Failed to report usage for '{integration_id}': {e}")
|
||||
return self._parse_json(response)
|
||||
|
||||
def health_check(self) -> dict[str, Any]:
|
||||
"""
|
||||
Check Aden server health and connectivity.
|
||||
|
||||
Returns:
|
||||
Dict with 'status', 'version', 'timestamp', and optionally 'error'.
|
||||
"""
|
||||
"""Check Aden server health."""
|
||||
try:
|
||||
client = self._get_client()
|
||||
response = client.get("/health")
|
||||
if response.status_code == 200:
|
||||
data = response.json()
|
||||
data = self._parse_json(response)
|
||||
data["latency_ms"] = response.elapsed.total_seconds() * 1000
|
||||
return data
|
||||
return {
|
||||
"status": "degraded",
|
||||
"error": f"Unexpected status code: {response.status_code}",
|
||||
}
|
||||
return {"status": "degraded", "error": f"HTTP {response.status_code}"}
|
||||
except Exception as e:
|
||||
return {
|
||||
"status": "unhealthy",
|
||||
"error": str(e),
|
||||
}
|
||||
return {"status": "unhealthy", "error": str(e)}
|
||||
|
||||
def close(self) -> None:
|
||||
"""Close the HTTP client and release resources."""
|
||||
if self._client:
|
||||
self._client.close()
|
||||
self._client = None
|
||||
|
||||
def __enter__(self) -> AdenCredentialClient:
|
||||
"""Context manager entry."""
|
||||
return self
|
||||
|
||||
def __exit__(self, *args: Any) -> None:
|
||||
"""Context manager exit."""
|
||||
self.close()
|
||||
|
||||
@@ -282,8 +282,8 @@ class AdenSyncProvider(CredentialProvider):
|
||||
"""
|
||||
Sync all credentials from Aden server to local store.
|
||||
|
||||
Fetches the list of available integrations from Aden and
|
||||
populates the local credential store with current tokens.
|
||||
Calls GET /v1/credentials to list integrations, then fetches
|
||||
access tokens for each active one.
|
||||
|
||||
Args:
|
||||
store: The credential store to populate.
|
||||
@@ -298,9 +298,7 @@ class AdenSyncProvider(CredentialProvider):
|
||||
|
||||
for info in integrations:
|
||||
if info.status != "active":
|
||||
logger.warning(
|
||||
f"Skipping integration '{info.integration_id}': status={info.status}"
|
||||
)
|
||||
logger.warning(f"Skipping connection '{info.alias}': status={info.status}")
|
||||
continue
|
||||
|
||||
try:
|
||||
@@ -308,9 +306,9 @@ class AdenSyncProvider(CredentialProvider):
|
||||
if cred:
|
||||
store.save_credential(cred)
|
||||
synced += 1
|
||||
logger.info(f"Synced credential '{info.integration_id}' from Aden")
|
||||
logger.info(f"Synced credential '{info.alias}' from Aden")
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to sync '{info.integration_id}': {e}")
|
||||
logger.warning(f"Failed to sync '{info.alias}': {e}")
|
||||
|
||||
except AdenClientError as e:
|
||||
logger.error(f"Failed to list integrations from Aden: {e}")
|
||||
@@ -373,6 +371,21 @@ class AdenSyncProvider(CredentialProvider):
|
||||
value=SecretStr(aden_response.integration_type),
|
||||
)
|
||||
|
||||
# Store alias (user-set name from Aden platform)
|
||||
if aden_response.alias:
|
||||
credential.keys["_alias"] = CredentialKey(
|
||||
name="_alias",
|
||||
value=SecretStr(aden_response.alias),
|
||||
)
|
||||
|
||||
# Persist Aden metadata as identity keys
|
||||
for meta_key, meta_value in (aden_response.metadata or {}).items():
|
||||
if meta_value and isinstance(meta_value, str):
|
||||
credential.keys[f"_identity_{meta_key}"] = CredentialKey(
|
||||
name=f"_identity_{meta_key}",
|
||||
value=SecretStr(meta_value),
|
||||
)
|
||||
|
||||
# Update timestamps
|
||||
credential.last_refreshed = datetime.now(UTC)
|
||||
credential.provider_id = self.provider_id
|
||||
@@ -400,12 +413,27 @@ class AdenSyncProvider(CredentialProvider):
|
||||
),
|
||||
}
|
||||
|
||||
# Store alias (user-set name from Aden platform)
|
||||
if aden_response.alias:
|
||||
keys["_alias"] = CredentialKey(
|
||||
name="_alias",
|
||||
value=SecretStr(aden_response.alias),
|
||||
)
|
||||
|
||||
if aden_response.scopes:
|
||||
keys["scope"] = CredentialKey(
|
||||
name="scope",
|
||||
value=SecretStr(" ".join(aden_response.scopes)),
|
||||
)
|
||||
|
||||
# Persist Aden metadata as identity keys
|
||||
for meta_key, meta_value in (aden_response.metadata or {}).items():
|
||||
if meta_value and isinstance(meta_value, str):
|
||||
keys[f"_identity_{meta_key}"] = CredentialKey(
|
||||
name=f"_identity_{meta_key}",
|
||||
value=SecretStr(meta_value),
|
||||
)
|
||||
|
||||
return CredentialObject(
|
||||
id=aden_response.integration_id,
|
||||
credential_type=CredentialType.OAUTH2,
|
||||
|
||||
@@ -26,7 +26,7 @@ Usage:
|
||||
storage = AdenCachedStorage(
|
||||
local_storage=EncryptedFileStorage(),
|
||||
aden_provider=provider,
|
||||
cache_ttl_seconds=300, # Re-check Aden every 5 minutes
|
||||
cache_ttl_seconds=600, # Re-check Aden every 5 minutes
|
||||
)
|
||||
|
||||
# Create store
|
||||
@@ -64,6 +64,8 @@ class AdenCachedStorage(CredentialStorage):
|
||||
- **Reads**: Try local cache first, fallback to Aden if stale/missing
|
||||
- **Writes**: Always write to local cache
|
||||
- **Offline resilience**: Uses cached credentials when Aden is unreachable
|
||||
- **Provider-based lookup**: Match credentials by provider name (e.g., "hubspot")
|
||||
when direct ID lookup fails, since Aden uses hash-based IDs internally.
|
||||
|
||||
The cache TTL determines how long to trust local credentials before
|
||||
checking with the Aden server for updates. This balances:
|
||||
@@ -75,7 +77,7 @@ class AdenCachedStorage(CredentialStorage):
|
||||
storage = AdenCachedStorage(
|
||||
local_storage=EncryptedFileStorage(),
|
||||
aden_provider=provider,
|
||||
cache_ttl_seconds=300, # 5 minutes
|
||||
cache_ttl_seconds=00, # 5 minutes
|
||||
)
|
||||
|
||||
store = CredentialStore(
|
||||
@@ -85,6 +87,7 @@ class AdenCachedStorage(CredentialStorage):
|
||||
|
||||
# First access fetches from Aden
|
||||
# Subsequent accesses use cache until TTL expires
|
||||
# Can look up by provider name OR credential ID
|
||||
token = store.get_key("hubspot", "access_token")
|
||||
"""
|
||||
|
||||
@@ -111,21 +114,26 @@ class AdenCachedStorage(CredentialStorage):
|
||||
self._cache_ttl = timedelta(seconds=cache_ttl_seconds)
|
||||
self._prefer_local = prefer_local
|
||||
self._cache_timestamps: dict[str, datetime] = {}
|
||||
# Index: provider name (e.g., "hubspot") -> list of credential hash IDs
|
||||
self._provider_index: dict[str, list[str]] = {}
|
||||
# Index: "provider:alias" -> credential hash ID (for alias-based routing)
|
||||
self._alias_index: dict[str, str] = {}
|
||||
|
||||
def save(self, credential: CredentialObject) -> None:
|
||||
"""
|
||||
Save credential to local cache.
|
||||
Save credential to local cache and update provider index.
|
||||
|
||||
Args:
|
||||
credential: The credential to save.
|
||||
"""
|
||||
self._local.save(credential)
|
||||
self._cache_timestamps[credential.id] = datetime.now(UTC)
|
||||
self._index_provider(credential)
|
||||
logger.debug(f"Cached credential '{credential.id}'")
|
||||
|
||||
def load(self, credential_id: str) -> CredentialObject | None:
|
||||
"""
|
||||
Load credential from cache, with Aden fallback.
|
||||
Load credential from cache, with Aden fallback and provider-based lookup.
|
||||
|
||||
The loading strategy depends on the `prefer_local` setting:
|
||||
|
||||
@@ -141,8 +149,39 @@ class AdenCachedStorage(CredentialStorage):
|
||||
2. Update local cache with response
|
||||
3. Fall back to local cache only if Aden fails
|
||||
|
||||
Provider-based lookup:
|
||||
When a provider index mapping exists for the credential_id (e.g.,
|
||||
"hubspot" → hash ID), the Aden-synced credential is loaded first.
|
||||
This ensures fresh OAuth tokens from Aden take priority over stale
|
||||
local credentials (env vars, old encrypted files).
|
||||
|
||||
Args:
|
||||
credential_id: The credential identifier.
|
||||
credential_id: The credential identifier or provider name.
|
||||
|
||||
Returns:
|
||||
CredentialObject if found, None otherwise.
|
||||
"""
|
||||
# Check provider index first — Aden-synced credentials take priority
|
||||
resolved_ids = self._provider_index.get(credential_id)
|
||||
if resolved_ids:
|
||||
for rid in resolved_ids:
|
||||
if rid != credential_id:
|
||||
result = self._load_by_id(rid)
|
||||
if result is not None:
|
||||
logger.info(
|
||||
f"Loaded credential '{credential_id}' via provider index (id='{rid}')"
|
||||
)
|
||||
return result
|
||||
|
||||
# Direct lookup (exact credential_id match)
|
||||
return self._load_by_id(credential_id)
|
||||
|
||||
def _load_by_id(self, credential_id: str) -> CredentialObject | None:
|
||||
"""
|
||||
Load credential by exact ID from cache, with Aden fallback.
|
||||
|
||||
Args:
|
||||
credential_id: The exact credential identifier.
|
||||
|
||||
Returns:
|
||||
CredentialObject if found, None otherwise.
|
||||
@@ -154,25 +193,42 @@ class AdenCachedStorage(CredentialStorage):
|
||||
logger.debug(f"Using cached credential '{credential_id}'")
|
||||
return local_cred
|
||||
|
||||
# Try to fetch from Aden
|
||||
# If nothing local, there's nothing to refresh from Aden.
|
||||
# sync_all() already fetched all available credentials — anything
|
||||
# not in local storage doesn't exist on the Aden server.
|
||||
if local_cred is None:
|
||||
return None
|
||||
|
||||
# Try to refresh stale local credential from Aden
|
||||
try:
|
||||
aden_cred = self._aden_provider.fetch_from_aden(credential_id)
|
||||
if aden_cred:
|
||||
# Update local cache
|
||||
self.save(aden_cred)
|
||||
logger.debug(f"Fetched credential '{credential_id}' from Aden")
|
||||
return aden_cred
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to fetch '{credential_id}' from Aden: {e}")
|
||||
logger.info(f"Using stale cached credential '{credential_id}'")
|
||||
return local_cred
|
||||
|
||||
# Fall back to local cache if Aden fails
|
||||
if local_cred:
|
||||
logger.info(f"Using stale cached credential '{credential_id}'")
|
||||
return local_cred
|
||||
|
||||
# Return local credential if it exists (may be None)
|
||||
return local_cred
|
||||
|
||||
def load_all_for_provider(self, provider_name: str) -> list[CredentialObject]:
|
||||
"""Load all credentials for a given provider type.
|
||||
|
||||
Args:
|
||||
provider_name: Provider name (e.g. "google", "slack").
|
||||
|
||||
Returns:
|
||||
List of CredentialObjects for all accounts of this provider.
|
||||
"""
|
||||
results: list[CredentialObject] = []
|
||||
for cid in self._provider_index.get(provider_name, []):
|
||||
cred = self._load_by_id(cid)
|
||||
if cred:
|
||||
results.append(cred)
|
||||
return results
|
||||
|
||||
def delete(self, credential_id: str) -> bool:
|
||||
"""
|
||||
Delete credential from local cache.
|
||||
@@ -200,15 +256,23 @@ class AdenCachedStorage(CredentialStorage):
|
||||
|
||||
def exists(self, credential_id: str) -> bool:
|
||||
"""
|
||||
Check if credential exists in local cache.
|
||||
Check if credential exists in local cache (by ID or provider name).
|
||||
|
||||
Args:
|
||||
credential_id: The credential identifier.
|
||||
credential_id: The credential identifier or provider name.
|
||||
|
||||
Returns:
|
||||
True if credential exists locally.
|
||||
"""
|
||||
return self._local.exists(credential_id)
|
||||
if self._local.exists(credential_id):
|
||||
return True
|
||||
# Check provider index
|
||||
resolved_ids = self._provider_index.get(credential_id)
|
||||
if resolved_ids:
|
||||
for rid in resolved_ids:
|
||||
if rid != credential_id and self._local.exists(rid):
|
||||
return True
|
||||
return False
|
||||
|
||||
def _is_cache_fresh(self, credential_id: str) -> bool:
|
||||
"""
|
||||
@@ -242,12 +306,81 @@ class AdenCachedStorage(CredentialStorage):
|
||||
self._cache_timestamps.clear()
|
||||
logger.debug("Invalidated all cache entries")
|
||||
|
||||
def _index_provider(self, credential: CredentialObject) -> None:
|
||||
"""
|
||||
Index a credential by its provider/integration type and alias.
|
||||
|
||||
Aden credentials carry an ``_integration_type`` key whose value is
|
||||
the provider name (e.g., ``hubspot``). This method maps that
|
||||
provider name to the credential's hash ID so that subsequent
|
||||
``load("hubspot")`` calls resolve to the correct credential.
|
||||
|
||||
Also indexes by ``_alias`` for alias-based multi-account routing.
|
||||
|
||||
Args:
|
||||
credential: The credential to index.
|
||||
"""
|
||||
integration_type_key = credential.keys.get("_integration_type")
|
||||
if integration_type_key is None:
|
||||
return
|
||||
provider_name = integration_type_key.value.get_secret_value()
|
||||
if provider_name:
|
||||
if provider_name not in self._provider_index:
|
||||
self._provider_index[provider_name] = []
|
||||
if credential.id not in self._provider_index[provider_name]:
|
||||
self._provider_index[provider_name].append(credential.id)
|
||||
logger.debug(f"Indexed provider '{provider_name}' -> '{credential.id}'")
|
||||
|
||||
# Index by alias for multi-account routing
|
||||
alias_key = credential.keys.get("_alias")
|
||||
if alias_key:
|
||||
alias = alias_key.value.get_secret_value()
|
||||
if alias:
|
||||
self._alias_index[f"{provider_name}:{alias}"] = credential.id
|
||||
|
||||
def load_by_alias(self, provider_name: str, alias: str) -> CredentialObject | None:
|
||||
"""Load a credential by provider name and alias.
|
||||
|
||||
Args:
|
||||
provider_name: Provider type (e.g. "google", "slack").
|
||||
alias: User-set alias from the Aden platform.
|
||||
|
||||
Returns:
|
||||
CredentialObject if found, None otherwise.
|
||||
"""
|
||||
cred_id = self._alias_index.get(f"{provider_name}:{alias}")
|
||||
if cred_id:
|
||||
return self._load_by_id(cred_id)
|
||||
return None
|
||||
|
||||
def rebuild_provider_index(self) -> int:
|
||||
"""
|
||||
Rebuild the provider and alias indexes from all locally cached credentials.
|
||||
|
||||
Useful after loading from disk when the in-memory indexes are empty.
|
||||
|
||||
Returns:
|
||||
Number of provider mappings indexed.
|
||||
"""
|
||||
self._provider_index.clear()
|
||||
self._alias_index.clear()
|
||||
indexed = 0
|
||||
for cred_id in self._local.list_all():
|
||||
cred = self._local.load(cred_id)
|
||||
if cred:
|
||||
before = len(self._provider_index)
|
||||
self._index_provider(cred)
|
||||
if len(self._provider_index) > before:
|
||||
indexed += 1
|
||||
logger.debug(f"Rebuilt provider index with {indexed} mappings")
|
||||
return indexed
|
||||
|
||||
def sync_all_from_aden(self) -> int:
|
||||
"""
|
||||
Sync all credentials from Aden server to local cache.
|
||||
|
||||
Fetches the list of available integrations from Aden and
|
||||
updates the local cache with current tokens.
|
||||
Calls GET /v1/credentials to list active integrations,
|
||||
then fetches tokens for each.
|
||||
|
||||
Returns:
|
||||
Number of credentials synced.
|
||||
@@ -259,9 +392,7 @@ class AdenCachedStorage(CredentialStorage):
|
||||
|
||||
for info in integrations:
|
||||
if info.status != "active":
|
||||
logger.warning(
|
||||
f"Skipping integration '{info.integration_id}': status={info.status}"
|
||||
)
|
||||
logger.warning(f"Skipping integration '{info.alias}': status={info.status}")
|
||||
continue
|
||||
|
||||
try:
|
||||
@@ -269,9 +400,9 @@ class AdenCachedStorage(CredentialStorage):
|
||||
if cred:
|
||||
self.save(cred)
|
||||
synced += 1
|
||||
logger.info(f"Synced credential '{info.integration_id}' from Aden")
|
||||
logger.info(f"Synced credential '{info.alias}' from Aden")
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to sync '{info.integration_id}': {e}")
|
||||
logger.warning(f"Failed to sync '{info.alias}': {e}")
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to list integrations from Aden: {e}")
|
||||
|
||||
@@ -61,11 +61,13 @@ def mock_client(aden_config):
|
||||
def aden_response():
|
||||
"""Create a sample Aden credential response."""
|
||||
return AdenCredentialResponse(
|
||||
integration_id="hubspot",
|
||||
integration_type="hubspot",
|
||||
integration_id="aHVic3BvdDp0ZXN0OjEzNjExOjExNTI1",
|
||||
access_token="test-access-token",
|
||||
token_type="Bearer",
|
||||
expires_at=datetime.now(UTC) + timedelta(hours=1),
|
||||
provider="hubspot",
|
||||
alias="My HubSpot",
|
||||
email="test@example.com",
|
||||
scopes=["crm.objects.contacts.read", "crm.objects.contacts.write"],
|
||||
metadata={"portal_id": "12345"},
|
||||
)
|
||||
@@ -108,18 +110,20 @@ class TestAdenCredentialResponse:
|
||||
"""Tests for AdenCredentialResponse dataclass."""
|
||||
|
||||
def test_from_dict_basic(self):
|
||||
"""Test creating response from dict."""
|
||||
"""Test creating response from dict (real get-token format)."""
|
||||
data = {
|
||||
"integration_id": "github",
|
||||
"integration_type": "github",
|
||||
"access_token": "ghp_xxxxx",
|
||||
"token_type": "Bearer",
|
||||
"provider": "github",
|
||||
"alias": "Work",
|
||||
}
|
||||
|
||||
response = AdenCredentialResponse.from_dict(data)
|
||||
response = AdenCredentialResponse.from_dict(data, integration_id="Z2l0aHViOldvcms6MTIzNDU")
|
||||
|
||||
assert response.integration_id == "github"
|
||||
assert response.integration_type == "github"
|
||||
assert response.integration_id == "Z2l0aHViOldvcms6MTIzNDU"
|
||||
assert response.access_token == "ghp_xxxxx"
|
||||
assert response.provider == "github"
|
||||
assert response.integration_type == "github" # backward compat property
|
||||
assert response.token_type == "Bearer"
|
||||
assert response.expires_at is None
|
||||
assert response.scopes == []
|
||||
@@ -127,19 +131,23 @@ class TestAdenCredentialResponse:
|
||||
def test_from_dict_full(self):
|
||||
"""Test creating response with all fields."""
|
||||
data = {
|
||||
"integration_id": "hubspot",
|
||||
"integration_type": "hubspot",
|
||||
"access_token": "token123",
|
||||
"token_type": "Bearer",
|
||||
"expires_at": "2026-01-28T15:30:00Z",
|
||||
"provider": "hubspot",
|
||||
"alias": "My HubSpot",
|
||||
"email": "test@example.com",
|
||||
"scopes": ["read", "write"],
|
||||
"metadata": {"key": "value"},
|
||||
}
|
||||
|
||||
response = AdenCredentialResponse.from_dict(data)
|
||||
response = AdenCredentialResponse.from_dict(data, integration_id="aHVic3BvdDp0ZXN0")
|
||||
|
||||
assert response.integration_id == "hubspot"
|
||||
assert response.integration_id == "aHVic3BvdDp0ZXN0"
|
||||
assert response.access_token == "token123"
|
||||
assert response.provider == "hubspot"
|
||||
assert response.alias == "My HubSpot"
|
||||
assert response.email == "test@example.com"
|
||||
assert response.expires_at is not None
|
||||
assert response.scopes == ["read", "write"]
|
||||
assert response.metadata == {"key": "value"}
|
||||
@@ -149,21 +157,44 @@ class TestAdenIntegrationInfo:
|
||||
"""Tests for AdenIntegrationInfo dataclass."""
|
||||
|
||||
def test_from_dict(self):
|
||||
"""Test creating integration info from dict."""
|
||||
"""Test creating integration info from real API format."""
|
||||
data = {
|
||||
"integration_id": "slack",
|
||||
"integration_type": "slack",
|
||||
"integration_id": "c2xhY2s6V29yayBTbGFjazoxMjM0NQ",
|
||||
"provider": "slack",
|
||||
"alias": "Work Slack",
|
||||
"status": "active",
|
||||
"expires_at": "2026-02-01T00:00:00Z",
|
||||
"email": "user@example.com",
|
||||
"expires_at": "2026-02-20T21:46:04.863Z",
|
||||
}
|
||||
|
||||
info = AdenIntegrationInfo.from_dict(data)
|
||||
|
||||
assert info.integration_id == "slack"
|
||||
assert info.integration_type == "slack"
|
||||
assert info.integration_id == "c2xhY2s6V29yayBTbGFjazoxMjM0NQ"
|
||||
assert info.provider == "slack"
|
||||
assert info.integration_type == "slack" # backward compat property
|
||||
assert info.alias == "Work Slack"
|
||||
assert info.email == "user@example.com"
|
||||
assert info.status == "active"
|
||||
assert info.expires_at is not None
|
||||
|
||||
def test_from_dict_minimal(self):
|
||||
"""Test creating integration info with minimal fields."""
|
||||
data = {
|
||||
"integration_id": "Z29vZ2xlOlRpbW90aHk6MTYwNjc",
|
||||
"provider": "google",
|
||||
"alias": "Timothy",
|
||||
"status": "requires_reauth",
|
||||
}
|
||||
|
||||
info = AdenIntegrationInfo.from_dict(data)
|
||||
|
||||
assert info.integration_id == "Z29vZ2xlOlRpbW90aHk6MTYwNjc"
|
||||
assert info.provider == "google"
|
||||
assert info.alias == "Timothy"
|
||||
assert info.status == "requires_reauth"
|
||||
assert info.email == ""
|
||||
assert info.expires_at is None
|
||||
|
||||
|
||||
# =============================================================================
|
||||
# AdenSyncProvider Tests
|
||||
@@ -220,10 +251,11 @@ class TestAdenSyncProvider:
|
||||
|
||||
def test_refresh_success(self, provider, mock_client, aden_response):
|
||||
"""Test successful credential refresh."""
|
||||
hash_id = "aHVic3BvdDp0ZXN0OjEzNjExOjExNTI1"
|
||||
mock_client.request_refresh.return_value = aden_response
|
||||
|
||||
cred = CredentialObject(
|
||||
id="hubspot",
|
||||
id=hash_id,
|
||||
credential_type=CredentialType.OAUTH2,
|
||||
keys={
|
||||
"access_token": CredentialKey(
|
||||
@@ -239,7 +271,7 @@ class TestAdenSyncProvider:
|
||||
assert refreshed.keys["access_token"].value.get_secret_value() == "test-access-token"
|
||||
assert refreshed.keys["_aden_managed"].value.get_secret_value() == "true"
|
||||
assert refreshed.last_refreshed is not None
|
||||
mock_client.request_refresh.assert_called_once_with("hubspot")
|
||||
mock_client.request_refresh.assert_called_once_with(hash_id)
|
||||
|
||||
def test_refresh_requires_reauth(self, provider, mock_client):
|
||||
"""Test refresh that requires re-authorization."""
|
||||
@@ -339,12 +371,13 @@ class TestAdenSyncProvider:
|
||||
|
||||
def test_fetch_from_aden(self, provider, mock_client, aden_response):
|
||||
"""Test fetching credential from Aden."""
|
||||
hash_id = "aHVic3BvdDp0ZXN0OjEzNjExOjExNTI1"
|
||||
mock_client.get_credential.return_value = aden_response
|
||||
|
||||
cred = provider.fetch_from_aden("hubspot")
|
||||
cred = provider.fetch_from_aden(hash_id)
|
||||
|
||||
assert cred is not None
|
||||
assert cred.id == "hubspot"
|
||||
assert cred.id == hash_id
|
||||
assert cred.keys["access_token"].value.get_secret_value() == "test-access-token"
|
||||
assert cred.auto_refresh is True
|
||||
|
||||
@@ -360,13 +393,15 @@ class TestAdenSyncProvider:
|
||||
"""Test syncing all credentials."""
|
||||
mock_client.list_integrations.return_value = [
|
||||
AdenIntegrationInfo(
|
||||
integration_id="hubspot",
|
||||
integration_type="hubspot",
|
||||
integration_id="aHVic3BvdDp0ZXN0OjEzNjExOjExNTI1",
|
||||
provider="hubspot",
|
||||
alias="My HubSpot",
|
||||
status="active",
|
||||
),
|
||||
AdenIntegrationInfo(
|
||||
integration_id="github",
|
||||
integration_type="github",
|
||||
integration_id="Z2l0aHViOnRlc3Q6OTk5",
|
||||
provider="github",
|
||||
alias="Work GitHub",
|
||||
status="requires_reauth", # Should be skipped
|
||||
),
|
||||
]
|
||||
@@ -376,7 +411,7 @@ class TestAdenSyncProvider:
|
||||
synced = provider.sync_all(store)
|
||||
|
||||
assert synced == 1 # Only active one was synced
|
||||
assert store.get_credential("hubspot") is not None
|
||||
assert store.get_credential("aHVic3BvdDp0ZXN0OjEzNjExOjExNTI1") is not None
|
||||
|
||||
def test_validate_via_aden(self, provider, mock_client):
|
||||
"""Test validation via Aden introspection."""
|
||||
@@ -589,6 +624,149 @@ class TestAdenCachedStorage:
|
||||
assert info["stale"]["is_fresh"] is False
|
||||
assert info["stale"]["ttl_remaining_seconds"] == 0
|
||||
|
||||
def test_save_indexes_provider(self, cached_storage):
|
||||
"""Test save builds the provider index from _integration_type key."""
|
||||
cred = CredentialObject(
|
||||
id="aHVic3BvdDp0ZXN0OjEzNjExOjExNTI1",
|
||||
credential_type=CredentialType.OAUTH2,
|
||||
keys={
|
||||
"access_token": CredentialKey(
|
||||
name="access_token",
|
||||
value=SecretStr("token-value"),
|
||||
),
|
||||
"_integration_type": CredentialKey(
|
||||
name="_integration_type",
|
||||
value=SecretStr("hubspot"),
|
||||
),
|
||||
},
|
||||
)
|
||||
|
||||
cached_storage.save(cred)
|
||||
|
||||
assert cached_storage._provider_index["hubspot"] == ["aHVic3BvdDp0ZXN0OjEzNjExOjExNTI1"]
|
||||
|
||||
def test_load_by_provider_name(self, cached_storage):
|
||||
"""Test load resolves provider name to hash-based credential ID."""
|
||||
hash_id = "aHVic3BvdDp0ZXN0OjEzNjExOjExNTI1"
|
||||
cred = CredentialObject(
|
||||
id=hash_id,
|
||||
credential_type=CredentialType.OAUTH2,
|
||||
keys={
|
||||
"access_token": CredentialKey(
|
||||
name="access_token",
|
||||
value=SecretStr("hubspot-token"),
|
||||
),
|
||||
"_integration_type": CredentialKey(
|
||||
name="_integration_type",
|
||||
value=SecretStr("hubspot"),
|
||||
),
|
||||
},
|
||||
)
|
||||
|
||||
# Save builds the index
|
||||
cached_storage.save(cred)
|
||||
|
||||
# Load by provider name should resolve to the hash ID
|
||||
loaded = cached_storage.load("hubspot")
|
||||
|
||||
assert loaded is not None
|
||||
assert loaded.id == hash_id
|
||||
assert loaded.keys["access_token"].value.get_secret_value() == "hubspot-token"
|
||||
|
||||
def test_load_by_direct_id_still_works(self, cached_storage):
|
||||
"""Test load by direct hash ID still works as before."""
|
||||
hash_id = "aHVic3BvdDp0ZXN0OjEzNjExOjExNTI1"
|
||||
cred = CredentialObject(
|
||||
id=hash_id,
|
||||
credential_type=CredentialType.OAUTH2,
|
||||
keys={
|
||||
"access_token": CredentialKey(
|
||||
name="access_token",
|
||||
value=SecretStr("token"),
|
||||
),
|
||||
"_integration_type": CredentialKey(
|
||||
name="_integration_type",
|
||||
value=SecretStr("hubspot"),
|
||||
),
|
||||
},
|
||||
)
|
||||
|
||||
cached_storage.save(cred)
|
||||
|
||||
# Direct ID lookup should still work
|
||||
loaded = cached_storage.load(hash_id)
|
||||
|
||||
assert loaded is not None
|
||||
assert loaded.id == hash_id
|
||||
|
||||
def test_exists_by_provider_name(self, cached_storage):
|
||||
"""Test exists resolves provider name to hash-based credential ID."""
|
||||
hash_id = "c2xhY2s6dGVzdDo5OTk="
|
||||
cred = CredentialObject(
|
||||
id=hash_id,
|
||||
credential_type=CredentialType.OAUTH2,
|
||||
keys={
|
||||
"access_token": CredentialKey(
|
||||
name="access_token",
|
||||
value=SecretStr("slack-token"),
|
||||
),
|
||||
"_integration_type": CredentialKey(
|
||||
name="_integration_type",
|
||||
value=SecretStr("slack"),
|
||||
),
|
||||
},
|
||||
)
|
||||
|
||||
cached_storage.save(cred)
|
||||
|
||||
assert cached_storage.exists("slack") is True
|
||||
assert cached_storage.exists(hash_id) is True
|
||||
assert cached_storage.exists("nonexistent") is False
|
||||
|
||||
def test_rebuild_provider_index(self, cached_storage, local_storage):
|
||||
"""Test rebuild_provider_index reconstructs from local storage."""
|
||||
# Manually save credentials to local storage (bypassing cached_storage.save)
|
||||
for provider_name, hash_id in [("hubspot", "hash_hub"), ("slack", "hash_slack")]:
|
||||
cred = CredentialObject(
|
||||
id=hash_id,
|
||||
credential_type=CredentialType.OAUTH2,
|
||||
keys={
|
||||
"_integration_type": CredentialKey(
|
||||
name="_integration_type",
|
||||
value=SecretStr(provider_name),
|
||||
),
|
||||
},
|
||||
)
|
||||
local_storage.save(cred)
|
||||
|
||||
# Index should be empty (we bypassed save)
|
||||
assert len(cached_storage._provider_index) == 0
|
||||
|
||||
# Rebuild
|
||||
indexed = cached_storage.rebuild_provider_index()
|
||||
|
||||
assert indexed == 2
|
||||
assert cached_storage._provider_index["hubspot"] == ["hash_hub"]
|
||||
assert cached_storage._provider_index["slack"] == ["hash_slack"]
|
||||
|
||||
def test_save_without_integration_type_no_index(self, cached_storage):
|
||||
"""Test save does not index credentials without _integration_type key."""
|
||||
cred = CredentialObject(
|
||||
id="plain-cred",
|
||||
credential_type=CredentialType.API_KEY,
|
||||
keys={
|
||||
"api_key": CredentialKey(
|
||||
name="api_key",
|
||||
value=SecretStr("key-value"),
|
||||
),
|
||||
},
|
||||
)
|
||||
|
||||
cached_storage.save(cred)
|
||||
|
||||
assert "plain-cred" not in cached_storage._provider_index
|
||||
assert len(cached_storage._provider_index) == 0
|
||||
|
||||
|
||||
# =============================================================================
|
||||
# Integration Tests
|
||||
@@ -600,19 +778,23 @@ class TestAdenIntegration:
|
||||
|
||||
def test_full_workflow(self, mock_client, aden_response):
|
||||
"""Test full workflow: sync, get, refresh."""
|
||||
hash_id = "aHVic3BvdDp0ZXN0OjEzNjExOjExNTI1"
|
||||
|
||||
# Setup
|
||||
mock_client.list_integrations.return_value = [
|
||||
AdenIntegrationInfo(
|
||||
integration_id="hubspot",
|
||||
integration_type="hubspot",
|
||||
integration_id=hash_id,
|
||||
provider="hubspot",
|
||||
alias="My HubSpot",
|
||||
status="active",
|
||||
),
|
||||
]
|
||||
mock_client.get_credential.return_value = aden_response
|
||||
mock_client.request_refresh.return_value = AdenCredentialResponse(
|
||||
integration_id="hubspot",
|
||||
integration_type="hubspot",
|
||||
integration_id=hash_id,
|
||||
access_token="refreshed-token",
|
||||
provider="hubspot",
|
||||
alias="My HubSpot",
|
||||
expires_at=datetime.now(UTC) + timedelta(hours=2),
|
||||
scopes=[],
|
||||
)
|
||||
@@ -629,8 +811,8 @@ class TestAdenIntegration:
|
||||
synced = provider.sync_all(store)
|
||||
assert synced == 1
|
||||
|
||||
# Get credential
|
||||
cred = store.get_credential("hubspot")
|
||||
# Get credential by hash ID
|
||||
cred = store.get_credential(hash_id)
|
||||
assert cred is not None
|
||||
assert cred.keys["access_token"].value.get_secret_value() == "test-access-token"
|
||||
|
||||
|
||||
@@ -0,0 +1,219 @@
|
||||
"""
|
||||
Dedicated file-based storage for bootstrap credentials.
|
||||
|
||||
HIVE_CREDENTIAL_KEY -> ~/.hive/secrets/credential_key (plain text, chmod 600)
|
||||
ADEN_API_KEY -> ~/.hive/credentials/ (encrypted via EncryptedFileStorage)
|
||||
|
||||
Boot order:
|
||||
1. load_credential_key() -- reads/generates the Fernet key, sets os.environ
|
||||
2. load_aden_api_key() -- uses the encrypted store (which needs the key from step 1)
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import logging
|
||||
import os
|
||||
import stat
|
||||
from pathlib import Path
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
CREDENTIAL_KEY_PATH = Path.home() / ".hive" / "secrets" / "credential_key"
|
||||
CREDENTIAL_KEY_ENV_VAR = "HIVE_CREDENTIAL_KEY"
|
||||
ADEN_CREDENTIAL_ID = "aden_api_key"
|
||||
ADEN_ENV_VAR = "ADEN_API_KEY"
|
||||
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# HIVE_CREDENTIAL_KEY
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
|
||||
def load_credential_key() -> str | None:
|
||||
"""Load HIVE_CREDENTIAL_KEY with priority: env > file > shell config.
|
||||
|
||||
Sets ``os.environ["HIVE_CREDENTIAL_KEY"]`` as a side-effect when found.
|
||||
Returns the key string, or ``None`` if unavailable everywhere.
|
||||
"""
|
||||
# 1. Already in environment (set by parent process, CI, Windows Registry, etc.)
|
||||
key = os.environ.get(CREDENTIAL_KEY_ENV_VAR)
|
||||
if key:
|
||||
return key
|
||||
|
||||
# 2. Dedicated secrets file
|
||||
key = _read_credential_key_file()
|
||||
if key:
|
||||
os.environ[CREDENTIAL_KEY_ENV_VAR] = key
|
||||
return key
|
||||
|
||||
# 3. Shell config fallback (backward compat for old installs)
|
||||
key = _read_from_shell_config(CREDENTIAL_KEY_ENV_VAR)
|
||||
if key:
|
||||
os.environ[CREDENTIAL_KEY_ENV_VAR] = key
|
||||
return key
|
||||
|
||||
return None
|
||||
|
||||
|
||||
def save_credential_key(key: str) -> Path:
|
||||
"""Save HIVE_CREDENTIAL_KEY to ``~/.hive/secrets/credential_key``.
|
||||
|
||||
Creates parent dirs with mode 700, writes the file with mode 600.
|
||||
Also sets ``os.environ["HIVE_CREDENTIAL_KEY"]``.
|
||||
|
||||
Returns:
|
||||
The path that was written.
|
||||
"""
|
||||
path = CREDENTIAL_KEY_PATH
|
||||
path.parent.mkdir(parents=True, exist_ok=True)
|
||||
# Restrict the secrets directory itself
|
||||
path.parent.chmod(stat.S_IRWXU) # 0o700
|
||||
|
||||
path.write_text(key, encoding="utf-8")
|
||||
path.chmod(stat.S_IRUSR | stat.S_IWUSR) # 0o600
|
||||
|
||||
os.environ[CREDENTIAL_KEY_ENV_VAR] = key
|
||||
return path
|
||||
|
||||
|
||||
def generate_and_save_credential_key() -> str:
|
||||
"""Generate a new Fernet key and persist it to ``~/.hive/secrets/credential_key``.
|
||||
|
||||
Returns:
|
||||
The generated key string.
|
||||
"""
|
||||
from cryptography.fernet import Fernet
|
||||
|
||||
key = Fernet.generate_key().decode()
|
||||
save_credential_key(key)
|
||||
return key
|
||||
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# ADEN_API_KEY
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
|
||||
def load_aden_api_key() -> str | None:
|
||||
"""Load ADEN_API_KEY with priority: env > encrypted store > shell config.
|
||||
|
||||
**Must** be called after ``load_credential_key()`` because the encrypted
|
||||
store depends on HIVE_CREDENTIAL_KEY.
|
||||
|
||||
Sets ``os.environ["ADEN_API_KEY"]`` as a side-effect when found.
|
||||
Returns the key string, or ``None`` if unavailable everywhere.
|
||||
"""
|
||||
# 1. Already in environment
|
||||
key = os.environ.get(ADEN_ENV_VAR)
|
||||
if key:
|
||||
return key
|
||||
|
||||
# 2. Encrypted credential store
|
||||
key = _read_aden_from_encrypted_store()
|
||||
if key:
|
||||
os.environ[ADEN_ENV_VAR] = key
|
||||
return key
|
||||
|
||||
# 3. Shell config fallback (backward compat)
|
||||
key = _read_from_shell_config(ADEN_ENV_VAR)
|
||||
if key:
|
||||
os.environ[ADEN_ENV_VAR] = key
|
||||
return key
|
||||
|
||||
return None
|
||||
|
||||
|
||||
def save_aden_api_key(key: str) -> None:
|
||||
"""Save ADEN_API_KEY to the encrypted credential store.
|
||||
|
||||
Also sets ``os.environ["ADEN_API_KEY"]``.
|
||||
"""
|
||||
from pydantic import SecretStr
|
||||
|
||||
from .models import CredentialKey, CredentialObject
|
||||
from .storage import EncryptedFileStorage
|
||||
|
||||
storage = EncryptedFileStorage()
|
||||
cred = CredentialObject(
|
||||
id=ADEN_CREDENTIAL_ID,
|
||||
keys={"api_key": CredentialKey(name="api_key", value=SecretStr(key))},
|
||||
)
|
||||
storage.save(cred)
|
||||
os.environ[ADEN_ENV_VAR] = key
|
||||
|
||||
|
||||
def delete_aden_api_key() -> bool:
|
||||
"""Remove ADEN_API_KEY from the encrypted store and ``os.environ``.
|
||||
|
||||
Returns True if the key existed and was deleted, False otherwise.
|
||||
"""
|
||||
deleted = False
|
||||
try:
|
||||
from .storage import EncryptedFileStorage
|
||||
|
||||
storage = EncryptedFileStorage()
|
||||
deleted = storage.delete(ADEN_CREDENTIAL_ID)
|
||||
except (FileNotFoundError, PermissionError) as e:
|
||||
logger.debug("Could not delete %s from encrypted store: %s", ADEN_CREDENTIAL_ID, e)
|
||||
except Exception:
|
||||
logger.warning(
|
||||
"Unexpected error deleting %s from encrypted store",
|
||||
ADEN_CREDENTIAL_ID,
|
||||
exc_info=True,
|
||||
)
|
||||
os.environ.pop(ADEN_ENV_VAR, None)
|
||||
return deleted
|
||||
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Internal helpers
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
|
||||
def _read_credential_key_file() -> str | None:
|
||||
"""Read the credential key from ``~/.hive/secrets/credential_key``."""
|
||||
try:
|
||||
if CREDENTIAL_KEY_PATH.is_file():
|
||||
value = CREDENTIAL_KEY_PATH.read_text(encoding="utf-8").strip()
|
||||
if value:
|
||||
return value
|
||||
except (FileNotFoundError, PermissionError) as e:
|
||||
logger.debug("Could not read %s: %s", CREDENTIAL_KEY_PATH, e)
|
||||
except Exception:
|
||||
logger.warning("Unexpected error reading %s", CREDENTIAL_KEY_PATH, exc_info=True)
|
||||
return None
|
||||
|
||||
|
||||
def _read_from_shell_config(env_var: str) -> str | None:
|
||||
"""Fallback: read an env var from ~/.zshrc or ~/.bashrc."""
|
||||
try:
|
||||
from aden_tools.credentials.shell_config import check_env_var_in_shell_config
|
||||
|
||||
found, value = check_env_var_in_shell_config(env_var)
|
||||
if found and value:
|
||||
return value
|
||||
except ImportError:
|
||||
pass
|
||||
return None
|
||||
|
||||
|
||||
def _read_aden_from_encrypted_store() -> str | None:
|
||||
"""Try to load ADEN_API_KEY from the encrypted credential store."""
|
||||
if not os.environ.get(CREDENTIAL_KEY_ENV_VAR):
|
||||
return None
|
||||
try:
|
||||
from .storage import EncryptedFileStorage
|
||||
|
||||
storage = EncryptedFileStorage()
|
||||
cred = storage.load(ADEN_CREDENTIAL_ID)
|
||||
if cred:
|
||||
return cred.get_key("api_key")
|
||||
except (FileNotFoundError, PermissionError, KeyError) as e:
|
||||
logger.debug("Could not load %s from encrypted store: %s", ADEN_CREDENTIAL_ID, e)
|
||||
except Exception:
|
||||
logger.warning(
|
||||
"Unexpected error loading %s from encrypted store",
|
||||
ADEN_CREDENTIAL_ID,
|
||||
exc_info=True,
|
||||
)
|
||||
return None
|
||||
@@ -0,0 +1,31 @@
|
||||
"""
|
||||
Local credential registry — named API key accounts with identity metadata.
|
||||
|
||||
Provides feature parity with Aden OAuth credentials for locally-stored API keys:
|
||||
aliases, identity metadata, status tracking, CRUD, and health validation.
|
||||
|
||||
Usage:
|
||||
from framework.credentials.local import LocalCredentialRegistry, LocalAccountInfo
|
||||
|
||||
registry = LocalCredentialRegistry.default()
|
||||
|
||||
# Add a named account
|
||||
info, health = registry.save_account("brave_search", "work", "BSA-xxx")
|
||||
|
||||
# List all stored local accounts
|
||||
for account in registry.list_accounts():
|
||||
print(f"{account.credential_id}/{account.alias}: {account.status}")
|
||||
if account.identity.is_known:
|
||||
print(f" Identity: {account.identity.label}")
|
||||
|
||||
# Re-validate a stored account
|
||||
result = registry.validate_account("github", "personal")
|
||||
"""
|
||||
|
||||
from .models import LocalAccountInfo
|
||||
from .registry import LocalCredentialRegistry
|
||||
|
||||
__all__ = [
|
||||
"LocalAccountInfo",
|
||||
"LocalCredentialRegistry",
|
||||
]
|
||||
@@ -0,0 +1,58 @@
|
||||
"""
|
||||
Data models for the local credential registry.
|
||||
|
||||
LocalAccountInfo mirrors AdenIntegrationInfo, giving local API key credentials
|
||||
the same identity/status metadata as Aden OAuth credentials.
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from datetime import datetime
|
||||
|
||||
from framework.credentials.models import CredentialIdentity
|
||||
|
||||
|
||||
@dataclass
|
||||
class LocalAccountInfo:
|
||||
"""
|
||||
A locally-stored named credential account.
|
||||
|
||||
Mirrors AdenIntegrationInfo so local and Aden accounts can be treated
|
||||
uniformly in the credential tester and account selection UI.
|
||||
|
||||
Attributes:
|
||||
credential_id: The logical credential name (e.g. "brave_search", "github")
|
||||
alias: User-provided name for this account (e.g. "work", "personal")
|
||||
status: "active" | "failed" | "unknown"
|
||||
identity: Email, username, workspace, or account_id extracted from health check
|
||||
last_validated: When the key was last verified against the live API
|
||||
created_at: When this account was first stored
|
||||
"""
|
||||
|
||||
credential_id: str
|
||||
alias: str
|
||||
status: str = "unknown"
|
||||
identity: CredentialIdentity = field(default_factory=CredentialIdentity)
|
||||
last_validated: datetime | None = None
|
||||
created_at: datetime = field(default_factory=datetime.utcnow)
|
||||
|
||||
@property
|
||||
def storage_id(self) -> str:
|
||||
"""The key used in EncryptedFileStorage: '{credential_id}/{alias}'."""
|
||||
return f"{self.credential_id}/{self.alias}"
|
||||
|
||||
def to_account_dict(self) -> dict:
|
||||
"""
|
||||
Format compatible with AccountSelectionScreen and configure_for_account().
|
||||
|
||||
Same shape as Aden account dicts, with source='local' added.
|
||||
"""
|
||||
return {
|
||||
"provider": self.credential_id,
|
||||
"alias": self.alias,
|
||||
"identity": self.identity.to_dict(),
|
||||
"integration_id": None,
|
||||
"source": "local",
|
||||
"status": self.status,
|
||||
}
|
||||
@@ -0,0 +1,326 @@
|
||||
"""
|
||||
Local Credential Registry.
|
||||
|
||||
Manages named local API key accounts stored in EncryptedFileStorage.
|
||||
Mirrors the Aden integration model so local credentials have feature parity:
|
||||
aliases, identity metadata, status tracking, CRUD, and health validation.
|
||||
|
||||
Storage convention:
|
||||
{credential_id}/{alias} → CredentialObject
|
||||
e.g. "brave_search/work" → { api_key: "BSA-xxx", _alias: "work",
|
||||
_integration_type: "brave_search",
|
||||
_status: "active",
|
||||
_identity_username: "acme", ... }
|
||||
|
||||
Usage:
|
||||
registry = LocalCredentialRegistry.default()
|
||||
|
||||
# Add a new account
|
||||
info, health = registry.save_account("brave_search", "work", "BSA-xxx")
|
||||
print(info.status, info.identity.label)
|
||||
|
||||
# List all accounts
|
||||
for account in registry.list_accounts():
|
||||
print(f"{account.credential_id}/{account.alias}: {account.status}")
|
||||
|
||||
# Get the raw API key for a specific account
|
||||
key = registry.get_key("github", "personal")
|
||||
|
||||
# Re-validate a stored account
|
||||
result = registry.validate_account("github", "personal")
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import logging
|
||||
from datetime import UTC, datetime
|
||||
from pathlib import Path
|
||||
from typing import TYPE_CHECKING, Any
|
||||
|
||||
from framework.credentials.models import CredentialIdentity, CredentialObject
|
||||
from framework.credentials.storage import EncryptedFileStorage
|
||||
|
||||
from .models import LocalAccountInfo
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from aden_tools.credentials.health_check import HealthCheckResult
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
_SEPARATOR = "/"
|
||||
|
||||
|
||||
class LocalCredentialRegistry:
|
||||
"""
|
||||
Named local API key account store backed by EncryptedFileStorage.
|
||||
|
||||
Provides the same list/save/get/delete/validate surface as the Aden
|
||||
client, but for locally-stored API keys.
|
||||
"""
|
||||
|
||||
def __init__(self, storage: EncryptedFileStorage) -> None:
|
||||
self._storage = storage
|
||||
|
||||
# ------------------------------------------------------------------
|
||||
# Listing
|
||||
# ------------------------------------------------------------------
|
||||
|
||||
def list_accounts(self, credential_id: str | None = None) -> list[LocalAccountInfo]:
|
||||
"""
|
||||
List all stored local accounts.
|
||||
|
||||
Args:
|
||||
credential_id: If given, filter to this credential type only.
|
||||
|
||||
Returns:
|
||||
List of LocalAccountInfo sorted by credential_id then alias.
|
||||
"""
|
||||
all_ids = self._storage.list_all()
|
||||
accounts: list[LocalAccountInfo] = []
|
||||
|
||||
for storage_id in all_ids:
|
||||
if _SEPARATOR not in storage_id:
|
||||
continue # Skip legacy un-aliased entries
|
||||
|
||||
try:
|
||||
cred_obj = self._storage.load(storage_id)
|
||||
except Exception as exc:
|
||||
logger.debug("Skipping unreadable credential %s: %s", storage_id, exc)
|
||||
continue
|
||||
|
||||
if cred_obj is None:
|
||||
continue
|
||||
|
||||
info = self._to_account_info(cred_obj)
|
||||
if info is None:
|
||||
continue
|
||||
|
||||
if credential_id and info.credential_id != credential_id:
|
||||
continue
|
||||
|
||||
accounts.append(info)
|
||||
|
||||
return sorted(accounts, key=lambda a: (a.credential_id, a.alias))
|
||||
|
||||
# ------------------------------------------------------------------
|
||||
# Save / add
|
||||
# ------------------------------------------------------------------
|
||||
|
||||
def save_account(
|
||||
self,
|
||||
credential_id: str,
|
||||
alias: str,
|
||||
api_key: str,
|
||||
run_health_check: bool = True,
|
||||
extra_keys: dict[str, str] | None = None,
|
||||
) -> tuple[LocalAccountInfo, HealthCheckResult | None]:
|
||||
"""
|
||||
Store a named account, optionally validating it first.
|
||||
|
||||
Args:
|
||||
credential_id: Logical credential name (e.g. "brave_search").
|
||||
alias: User-chosen name (e.g. "work"). Defaults to "default".
|
||||
api_key: The raw API key / token value.
|
||||
run_health_check: If True, verify the key against the live API
|
||||
and extract identity metadata. Failure still saves with
|
||||
status="failed" so the user can re-validate later.
|
||||
extra_keys: Additional key/value pairs to store (e.g.
|
||||
cse_id for google_custom_search).
|
||||
|
||||
Returns:
|
||||
(LocalAccountInfo, HealthCheckResult | None)
|
||||
"""
|
||||
alias = alias or "default"
|
||||
health_result: HealthCheckResult | None = None
|
||||
identity: dict[str, str] = {}
|
||||
status = "active"
|
||||
|
||||
if run_health_check:
|
||||
try:
|
||||
from aden_tools.credentials.health_check import check_credential_health
|
||||
|
||||
kwargs: dict[str, Any] = {}
|
||||
if extra_keys and "cse_id" in extra_keys:
|
||||
kwargs["cse_id"] = extra_keys["cse_id"]
|
||||
|
||||
health_result = check_credential_health(credential_id, api_key, **kwargs)
|
||||
status = "active" if health_result.valid else "failed"
|
||||
identity = health_result.details.get("identity", {})
|
||||
except Exception as exc:
|
||||
logger.warning("Health check failed for %s/%s: %s", credential_id, alias, exc)
|
||||
status = "unknown"
|
||||
|
||||
storage_id = f"{credential_id}{_SEPARATOR}{alias}"
|
||||
now = datetime.now(UTC)
|
||||
|
||||
cred_obj = CredentialObject(id=storage_id)
|
||||
cred_obj.set_key("api_key", api_key)
|
||||
cred_obj.set_key("_alias", alias)
|
||||
cred_obj.set_key("_integration_type", credential_id)
|
||||
cred_obj.set_key("_status", status)
|
||||
|
||||
if extra_keys:
|
||||
for k, v in extra_keys.items():
|
||||
cred_obj.set_key(k, v)
|
||||
|
||||
if identity:
|
||||
valid_fields = set(CredentialIdentity.model_fields)
|
||||
filtered = {k: v for k, v in identity.items() if k in valid_fields}
|
||||
if filtered:
|
||||
cred_obj.set_identity(**filtered)
|
||||
|
||||
cred_obj.last_refreshed = now if run_health_check else None
|
||||
self._storage.save(cred_obj)
|
||||
|
||||
account_info = LocalAccountInfo(
|
||||
credential_id=credential_id,
|
||||
alias=alias,
|
||||
status=status,
|
||||
identity=cred_obj.identity,
|
||||
last_validated=cred_obj.last_refreshed,
|
||||
created_at=cred_obj.created_at,
|
||||
)
|
||||
return account_info, health_result
|
||||
|
||||
# ------------------------------------------------------------------
|
||||
# Get
|
||||
# ------------------------------------------------------------------
|
||||
|
||||
def get_account(self, credential_id: str, alias: str) -> CredentialObject | None:
|
||||
"""Load the raw CredentialObject for a specific account."""
|
||||
return self._storage.load(f"{credential_id}{_SEPARATOR}{alias}")
|
||||
|
||||
def get_key(self, credential_id: str, alias: str, key_name: str = "api_key") -> str | None:
|
||||
"""
|
||||
Return the stored secret value for a specific account.
|
||||
|
||||
Args:
|
||||
credential_id: Logical credential name (e.g. "brave_search").
|
||||
alias: Account alias (e.g. "work").
|
||||
key_name: Key within the credential (default "api_key").
|
||||
|
||||
Returns:
|
||||
The secret value, or None if not found.
|
||||
"""
|
||||
cred = self.get_account(credential_id, alias)
|
||||
if cred is None:
|
||||
return None
|
||||
return cred.get_key(key_name)
|
||||
|
||||
def get_account_info(self, credential_id: str, alias: str) -> LocalAccountInfo | None:
|
||||
"""Load a LocalAccountInfo for a specific account."""
|
||||
cred = self.get_account(credential_id, alias)
|
||||
if cred is None:
|
||||
return None
|
||||
return self._to_account_info(cred)
|
||||
|
||||
# ------------------------------------------------------------------
|
||||
# Delete
|
||||
# ------------------------------------------------------------------
|
||||
|
||||
def delete_account(self, credential_id: str, alias: str) -> bool:
|
||||
"""
|
||||
Remove a stored account.
|
||||
|
||||
Returns:
|
||||
True if the account existed and was deleted, False otherwise.
|
||||
"""
|
||||
return self._storage.delete(f"{credential_id}{_SEPARATOR}{alias}")
|
||||
|
||||
# ------------------------------------------------------------------
|
||||
# Validate
|
||||
# ------------------------------------------------------------------
|
||||
|
||||
def validate_account(self, credential_id: str, alias: str) -> HealthCheckResult:
|
||||
"""
|
||||
Re-run health check for a stored account and update its status.
|
||||
|
||||
Args:
|
||||
credential_id: Logical credential name.
|
||||
alias: Account alias.
|
||||
|
||||
Returns:
|
||||
HealthCheckResult from the live API check.
|
||||
|
||||
Raises:
|
||||
KeyError: If the account doesn't exist.
|
||||
"""
|
||||
from aden_tools.credentials.health_check import HealthCheckResult, check_credential_health
|
||||
|
||||
cred = self.get_account(credential_id, alias)
|
||||
if cred is None:
|
||||
raise KeyError(f"No local account found: {credential_id}/{alias}")
|
||||
|
||||
api_key = cred.get_key("api_key")
|
||||
if not api_key:
|
||||
return HealthCheckResult(valid=False, message="No api_key stored for this account")
|
||||
|
||||
try:
|
||||
kwargs: dict[str, Any] = {}
|
||||
cse_id = cred.get_key("cse_id")
|
||||
if cse_id:
|
||||
kwargs["cse_id"] = cse_id
|
||||
|
||||
result = check_credential_health(credential_id, api_key, **kwargs)
|
||||
except Exception as exc:
|
||||
result = HealthCheckResult(
|
||||
valid=False,
|
||||
message=f"Health check error: {exc}",
|
||||
details={"error": str(exc)},
|
||||
)
|
||||
|
||||
# Update status and timestamp in-place
|
||||
new_status = "active" if result.valid else "failed"
|
||||
cred.set_key("_status", new_status)
|
||||
cred.last_refreshed = datetime.now(UTC)
|
||||
|
||||
# Re-extract identity if available
|
||||
identity = result.details.get("identity", {})
|
||||
if identity:
|
||||
valid_fields = set(CredentialIdentity.model_fields)
|
||||
filtered = {k: v for k, v in identity.items() if k in valid_fields}
|
||||
if filtered:
|
||||
cred.set_identity(**filtered)
|
||||
|
||||
self._storage.save(cred)
|
||||
return result
|
||||
|
||||
# ------------------------------------------------------------------
|
||||
# Factory
|
||||
# ------------------------------------------------------------------
|
||||
|
||||
@classmethod
|
||||
def default(cls) -> LocalCredentialRegistry:
|
||||
"""Create a registry using the default encrypted storage at ~/.hive/credentials."""
|
||||
return cls(EncryptedFileStorage())
|
||||
|
||||
@classmethod
|
||||
def at_path(cls, path: str | Path) -> LocalCredentialRegistry:
|
||||
"""Create a registry using a custom storage path."""
|
||||
return cls(EncryptedFileStorage(base_path=path))
|
||||
|
||||
# ------------------------------------------------------------------
|
||||
# Internals
|
||||
# ------------------------------------------------------------------
|
||||
|
||||
def _to_account_info(self, cred_obj: CredentialObject) -> LocalAccountInfo | None:
|
||||
"""Build LocalAccountInfo from a CredentialObject."""
|
||||
cred_type_key = cred_obj.keys.get("_integration_type")
|
||||
if cred_type_key is None:
|
||||
return None
|
||||
cred_id = cred_type_key.get_secret_value()
|
||||
|
||||
alias_key = cred_obj.keys.get("_alias")
|
||||
alias = alias_key.get_secret_value() if alias_key else cred_obj.id.split(_SEPARATOR, 1)[-1]
|
||||
|
||||
status_key = cred_obj.keys.get("_status")
|
||||
status = status_key.get_secret_value() if status_key else "unknown"
|
||||
|
||||
return LocalAccountInfo(
|
||||
credential_id=cred_id,
|
||||
alias=alias,
|
||||
status=status,
|
||||
identity=cred_obj.identity,
|
||||
last_validated=cred_obj.last_refreshed,
|
||||
created_at=cred_obj.created_at,
|
||||
)
|
||||
@@ -8,7 +8,7 @@ containing one or more keys (e.g., api_key, access_token, refresh_token).
|
||||
from __future__ import annotations
|
||||
|
||||
from datetime import UTC, datetime
|
||||
from enum import Enum
|
||||
from enum import StrEnum
|
||||
from typing import Any
|
||||
|
||||
from pydantic import BaseModel, Field, SecretStr
|
||||
@@ -19,7 +19,7 @@ def _utc_now() -> datetime:
|
||||
return datetime.now(UTC)
|
||||
|
||||
|
||||
class CredentialType(str, Enum):
|
||||
class CredentialType(StrEnum):
|
||||
"""Types of credentials the store can manage."""
|
||||
|
||||
API_KEY = "api_key"
|
||||
@@ -70,6 +70,29 @@ class CredentialKey(BaseModel):
|
||||
return self.value.get_secret_value()
|
||||
|
||||
|
||||
class CredentialIdentity(BaseModel):
|
||||
"""Identity information for a credential (whose account is this?)."""
|
||||
|
||||
email: str | None = None
|
||||
username: str | None = None
|
||||
workspace: str | None = None
|
||||
account_id: str | None = None
|
||||
|
||||
@property
|
||||
def label(self) -> str:
|
||||
"""Best human-readable identifier for display."""
|
||||
return self.email or self.username or self.workspace or self.account_id or "unknown"
|
||||
|
||||
@property
|
||||
def is_known(self) -> bool:
|
||||
"""Whether any identity field is populated."""
|
||||
return bool(self.email or self.username or self.workspace or self.account_id)
|
||||
|
||||
def to_dict(self) -> dict[str, str]:
|
||||
"""Return only non-None identity fields."""
|
||||
return {k: v for k, v in self.model_dump().items() if v is not None}
|
||||
|
||||
|
||||
class CredentialObject(BaseModel):
|
||||
"""
|
||||
A credential object containing one or more keys.
|
||||
@@ -202,6 +225,35 @@ class CredentialObject(BaseModel):
|
||||
|
||||
return None
|
||||
|
||||
@property
|
||||
def identity(self) -> CredentialIdentity:
|
||||
"""Extract identity from ``_identity_*`` keys in the vault."""
|
||||
fields = {}
|
||||
for key_name, key_obj in self.keys.items():
|
||||
if key_name.startswith("_identity_"):
|
||||
field_name = key_name[len("_identity_") :]
|
||||
if field_name in CredentialIdentity.model_fields:
|
||||
fields[field_name] = key_obj.value.get_secret_value()
|
||||
return CredentialIdentity(**fields)
|
||||
|
||||
@property
|
||||
def provider_type(self) -> str | None:
|
||||
"""Return the integration/provider type (e.g. 'google', 'slack')."""
|
||||
key = self.keys.get("_integration_type")
|
||||
return key.value.get_secret_value() if key else None
|
||||
|
||||
@property
|
||||
def alias(self) -> str | None:
|
||||
"""Return the user-set alias from the Aden platform."""
|
||||
key = self.keys.get("_alias")
|
||||
return key.value.get_secret_value() if key else None
|
||||
|
||||
def set_identity(self, **fields: str) -> None:
|
||||
"""Persist identity fields as ``_identity_*`` keys."""
|
||||
for field_name, value in fields.items():
|
||||
if value:
|
||||
self.set_key(f"_identity_{field_name}", value)
|
||||
|
||||
|
||||
class CredentialUsageSpec(BaseModel):
|
||||
"""
|
||||
|
||||
@@ -73,6 +73,7 @@ from .provider import (
|
||||
TokenExpiredError,
|
||||
TokenPlacement,
|
||||
)
|
||||
from .zoho_provider import ZohoOAuth2Provider
|
||||
|
||||
__all__ = [
|
||||
# Types
|
||||
@@ -82,6 +83,7 @@ __all__ = [
|
||||
# Providers
|
||||
"BaseOAuth2Provider",
|
||||
"HubSpotOAuth2Provider",
|
||||
"ZohoOAuth2Provider",
|
||||
# Lifecycle
|
||||
"TokenLifecycleManager",
|
||||
"TokenRefreshResult",
|
||||
|
||||
@@ -96,7 +96,7 @@ class BaseOAuth2Provider(CredentialProvider):
|
||||
self._client = httpx.Client(timeout=self.config.request_timeout)
|
||||
except ImportError as e:
|
||||
raise ImportError(
|
||||
"OAuth2 provider requires 'httpx'. Install with: pip install httpx"
|
||||
"OAuth2 provider requires 'httpx'. Install with: uv pip install httpx"
|
||||
) from e
|
||||
return self._client
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user